") 實時互動下視頻QoE端到端輕量化網(wǎng)絡建模
實時互動下視頻QoE端到端輕量化網(wǎng)絡建模
在實時視頻互動中,影響觀眾對視頻體驗的有較多且復雜的因素,包括:畫質、流暢度以及與其耦合的觀看設備等。傳統(tǒng)客觀算法會利用網(wǎng)絡傳輸或編解碼參數(shù)擬合接收端人的感知體驗,或者使用圖像質量結合其他相關參數(shù)擬合實時視頻質量。由于缺少除畫質外的量化指標且沒有直接衡量視頻感知體驗,所以當前QoE算法有一定局限性。目前端到端的QoE模型可以有效解決上述面臨的難題,但同時也面臨著主觀實驗復雜、數(shù)據(jù)依賴與模型運算量大等問題。LiveVideoStackCon 2022北京站邀請到鄭林儒老師為我們介紹視頻體驗數(shù)據(jù)庫的建立、視頻畫質評估建模及其端上輕量優(yōu)化。
大家好,我是來自聲網(wǎng)的視頻算法工程師鄭林儒,今天給大家分享的是實時互動下視頻QoE端到端輕量化網(wǎng)絡建模。

今天將從影響視頻主觀體驗的因素、針對這些影響因素現(xiàn)階段建立的一些數(shù)據(jù)庫、對于視頻畫質評估做了一個端到端建模、考慮模型端上運行的實時性介紹了當前主流的深度學習模型加速方法和對視頻QoE的展望五個部分展開介紹。
-01-
QoE介紹
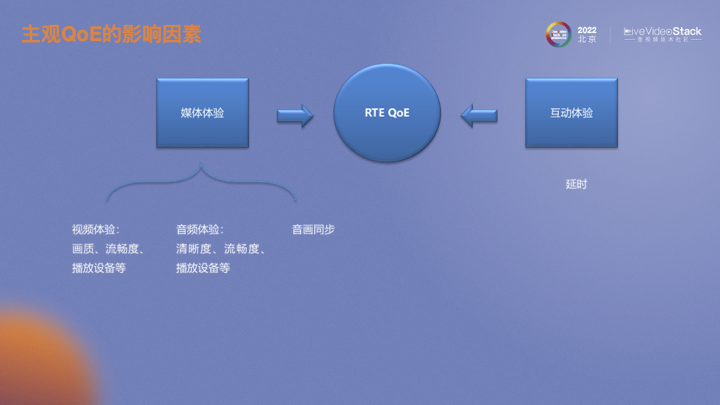
視頻或者實時互動場景下QoE體驗的影響因素主要有媒體體驗和互動體驗。媒體體驗分為視頻體驗和音頻體驗。視頻體驗包括畫質、流暢度、播放設備等。音頻體驗則包括清晰度、流暢度、播放設備。除此之外還有連接視頻和音頻的音畫同步。互動體驗目前主要定義為延遲。
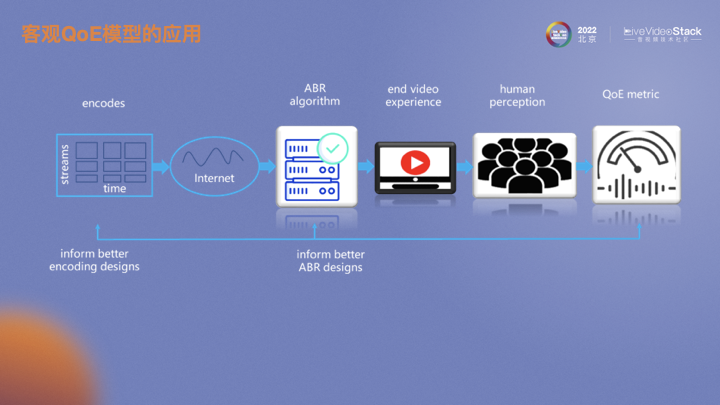
為什么要建立一套端到端的QoE評估體系呢?上圖是視頻從編碼傳輸?shù)奖挥脩舾兄牧鞒獭?a href="http://www.asorrir.com/tags/編碼器/" target="_blank">編碼器將視頻編成碼流,經過復雜的網(wǎng)絡環(huán)境會有各種碼率自適應算法去感知當前網(wǎng)絡變化或根據(jù)客戶端播放情況自動做出合理的碼率調整,以最大化用戶在線觀看視頻的體驗。一個端到端的QoE指標可以提供相對于PSNR、SSIM更貼合主觀的畫質指標。從而基于這個指標可以指導編碼器選擇最優(yōu)編碼參數(shù),進而在不影響用戶感知畫質情況下實現(xiàn)碼率節(jié)省。類似的,它也可作為ABR算法的參考指標。
-02-
QoE建庫
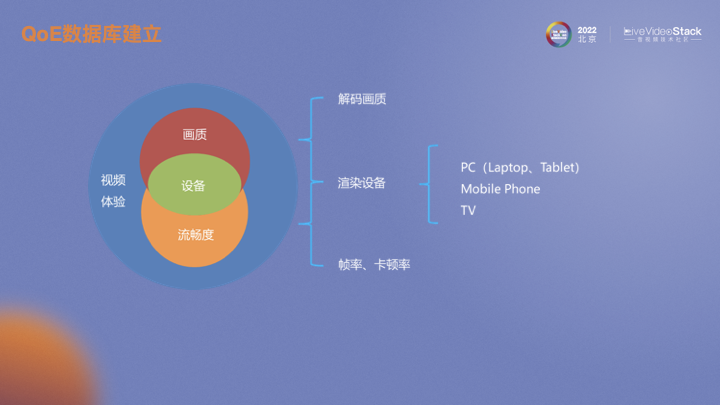
當前我們所建立的數(shù)據(jù)庫主要針對視頻體驗。首先考慮的是解碼端視頻畫質,這里畫質包括了清晰度、亮度、對比度、色彩等等方面。在畫質基礎上增加了畫面流暢度的評估維度,刻畫流暢度的客觀指標主要是幀率和卡頓率,但也和畫面、應用場景有關。可以看到無論是解碼端畫質還是流暢度都會收到觀看設備的影響,比如屏幕ppi會影響畫質體驗、刷新率會影響流暢度體驗。這里我們將設備大致歸為3類,分別為電腦、手機以及電視。

首先建立了一個畫質主觀評估數(shù)據(jù)庫,通過內部視頻軟件收集了一些數(shù)據(jù)。隨后對收集數(shù)據(jù)進行處理,通過我們開發(fā)的打分軟件,按照ITU標準進行主觀評估,得到每個視頻的MOS。
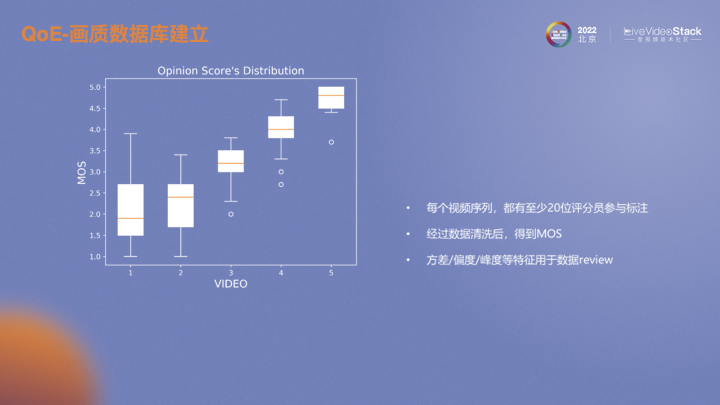
對于每個視頻序列我們都至少有20位評估人員參與打分以保證數(shù)據(jù)清洗后的有效人數(shù)。根據(jù)ITU推薦的方法,計算每個人與整體打分的相關性,再排除相關性較低的參與者。實驗中我們通過設置錨點發(fā)現(xiàn)了設備不同ppi對畫質評估影響很大,在像素密度較高屏幕素質越好的設備上給出的分也相對較高。同時錨點的設置也可以作為數(shù)據(jù)篩選的依據(jù)。
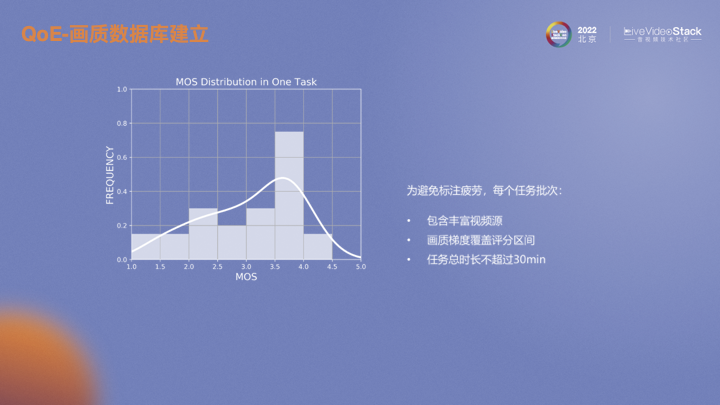
設置合理的視頻序列也是需要考慮的。為了避免長時間單調標注過程中產生疲勞而導致數(shù)據(jù)失真,每個批次盡量差異化視頻內容,并且在畫質層面最大化覆蓋評分區(qū)間,每個評估人員每次打分的時長不超過30分鐘。
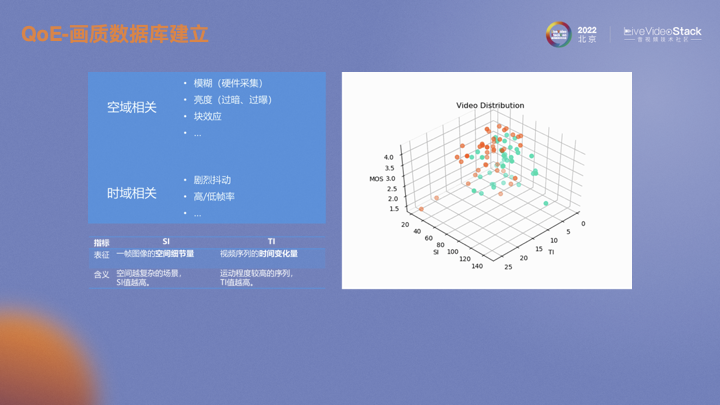
如何在視頻失真類型以及視頻特征上最大化多樣性呢?首先考慮空域失真即畫面失真,一般會因為視頻采集時聚焦不準而導致模糊,會由于背光等光照不均勻時出現(xiàn)過暗或過曝。視頻傳輸前會通過編碼器編成碼流,由于有量化操作所以在解碼后會有塊效應,還有其他很多類型的失真。時域相關的失真一般會有畫面卡頓以及不同的視頻幀率。從特征層面去表述或者區(qū)分的話,用經典的視頻特征SI和TI表述。SI表示視頻的空間細節(jié)程度,越復雜的場景SI越高;TI表示視頻在時域上的畫面變化程度,運動越劇烈的場景TI越高。
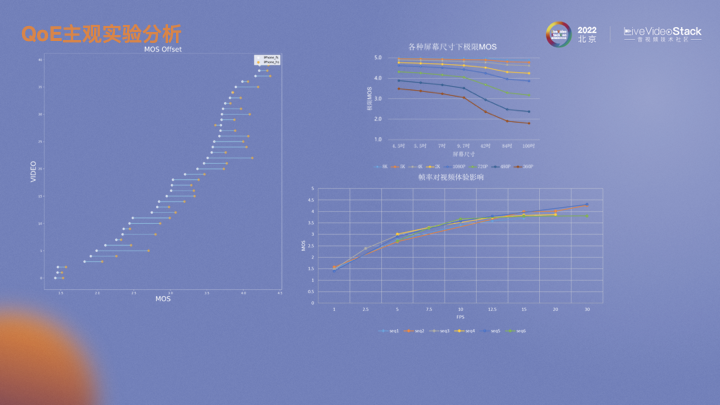
左圖是幾十個視頻在iPhone上全屏和半屏觀看時畫質MOS分變化趨勢圖。可以看到,相對于hs,fs大部分情況下畫質都有所降低。建模的目的就是為了找出相同畫質范圍內的偏移。右上角的圖來自華為的白皮書,表示不同分辨率視頻在不同尺寸設備上的極限MOS。越小分辨率的視頻在更大尺寸的設備上播放衰減越嚴重。右下角是我們做的一個實驗。對六個原視頻進行不同幀率的MOS評估,發(fā)現(xiàn)不同視頻,隨著幀率的上升,MOS會有所提升。但不同視頻內容導致的變化趨勢也略有不同,與視頻畫面會有很大關系,當運動劇烈時則需要更高的幀率支持,反之則不需要浪費更多的幀率資源。
-03-
QoE建模
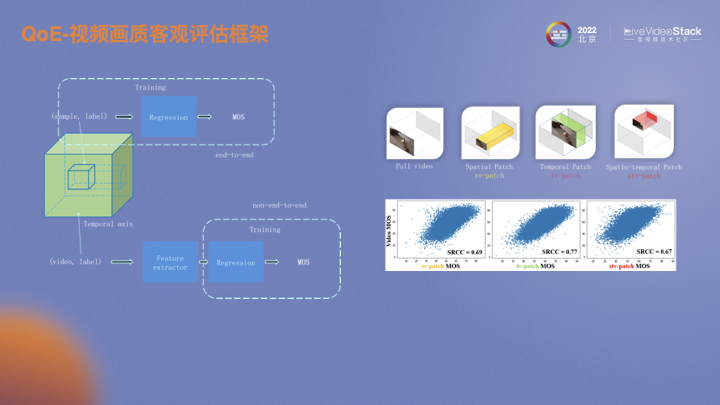
首先考慮的是視頻解碼端畫質的建模。業(yè)內目前主要有兩種方式。一種是端到端的訓練方式,另一種是非端到端的訓練方式。端到端是對一組視頻直接采樣,然后回歸MOS。采集的數(shù)據(jù)在分辨率和幀率大概率是不一樣的,需要通過采樣統(tǒng)一size。非端到端利用特征提取器,將原始視頻通過特征提取器提取到同一個維度,然后再回歸。右邊的圖是不同的采樣方式。第一個是空域采樣,保證了所有時域上的幀數(shù)。還有時域采樣和時空域采樣。下面的圖表示不同采樣方式MOS和原始視頻MOS的相關性。在空域進行時域采樣時相關性最高,時域信息沒有空域信息重要。線上推理完整的size則需要消耗更多資源。評估視頻的畫質不僅僅是空域上的失真,如果僅有空域的失真,直接用IQA擬合VQA即可,但目前該類方案的擬合效果都不佳。所以時域的影響不能消除。
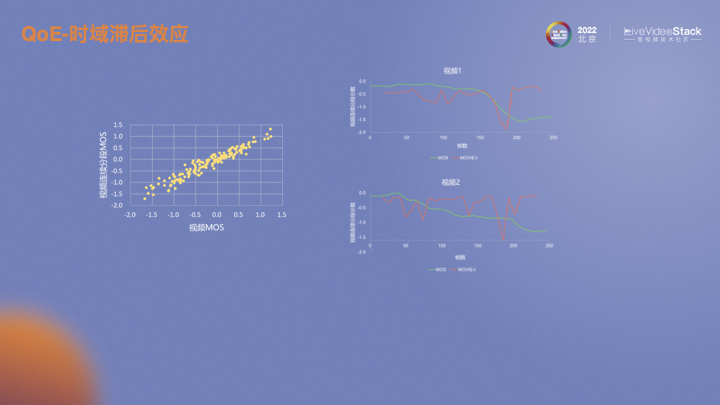
假設現(xiàn)在有一個十秒的視頻,每一秒都有一個MOS。每一秒MOS的均值和整個視頻的MOS有強相關性,基本可以認為互等。在這樣的前提下,滯后效應可以描述為當視頻的畫質下降時,MOS也會立即下降。但當畫質恢復時,由于人的主觀對之前的損失有記憶,提升是一個緩慢的過程。視頻2反映的趨勢也是如此。畫質不斷波動,畫質差的印象會一直在人的印象中,主觀MOS很難提升。
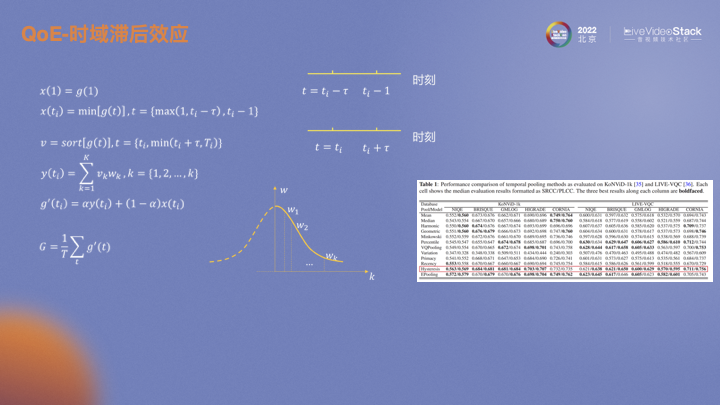
通過建模可以非常直觀的反映該效應。充分考慮前ti時刻和后ti時刻的影響。前ti時刻類比快速下降,對前ti時刻每一時刻的預測值取最小值,可以體現(xiàn)MOS快速下降的行為;而對后ti時刻的每一時刻預測值進行升序排序,對預測值較高的賦更低的權重,這一操作體現(xiàn)了緩慢提升的思想。將兩段時刻加權求和,作為最終的MOS。右下圖紅框就是效果展示。兩個數(shù)據(jù)集上以及不同的客觀指標上都有比較明顯的提升。但簡單的求平均,類似單幀IQA平均VQA,效果較差。
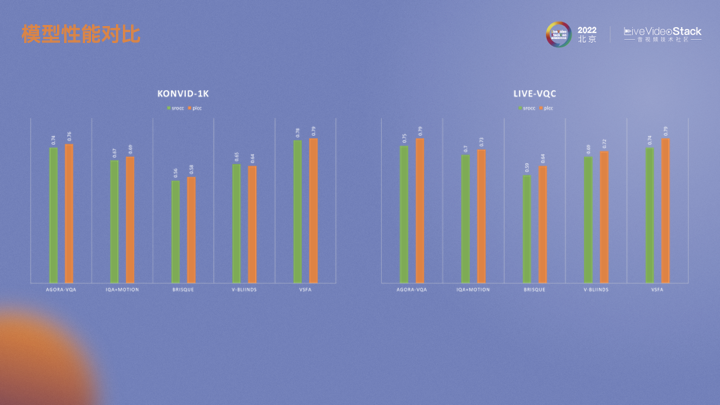
我們也同時在兩個數(shù)據(jù)集上做了實驗。AGORA-VQA是目前采用的方法。IQA+MOTION是基于深度學習的IQA算法。BRISQUE是傳統(tǒng)IQA算法。V-BINDS是傳統(tǒng)視頻的算法。VSFA是視頻的深度學習算法。
-04-
模型加速

基于深度學習算法落地時避免不了的一個問題就是運算量與性能的平衡。怎么在減小模型參數(shù)和運算量的同時保持甚至提高性能,業(yè)內一些小模型的設計給我們提供了一些思路。第一張圖是一個標準卷積過程,輸入3通道圖片經過一個4通道卷積層。MobileNet中對標準卷積進行了拆解,拆解成一個個深度卷積和逐點卷積。深度卷積的參數(shù)量和運算量有相同的關系,均為輸出通道1/N,而逐點卷積為卷積核大小平方分之一,通常在較深的網(wǎng)絡中N遠大于K,所以也可以看出這種結構下運算量主要來自于逐點卷積。
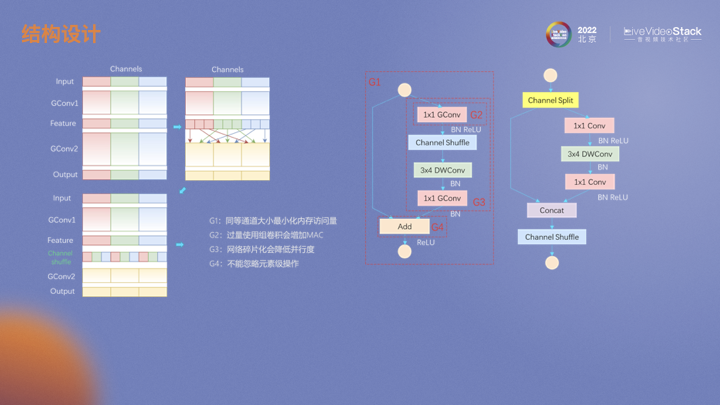
為了減少運算量同時增加通道間的信息流通,ShuffleNet中對分組卷積中不同通道進行重排,這樣下面的分組卷積中不同組的輸入就實現(xiàn)了特征融合。在模型落地的過程中也發(fā)現(xiàn)了一些問題。在V1模型中,如果采用ResNet瓶頸結構,輸入和輸出通道會不一樣,會增加內存的存取,即MAC。另外,分組卷積也會增加MAC。不同分支上的碎片化操作會降低并行度,例如channel shuffle。ReLU、add、shuffle這類元素級操作的運算量雖然比較低但是也會帶來MAC。針對這些問題,V2進行了一定的優(yōu)化。
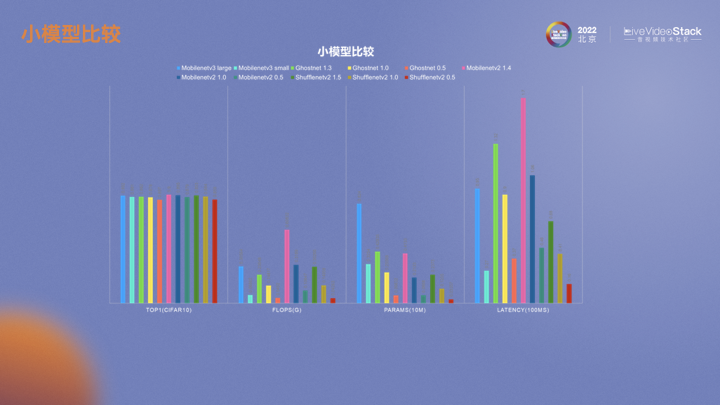
這張圖展示了不同小模型的性能。ShuffleNet的運算量、參數(shù)量還是線上推理延遲都比較小。在落地算法模型時,更為關注的是延遲,特別是RTE的場景下。
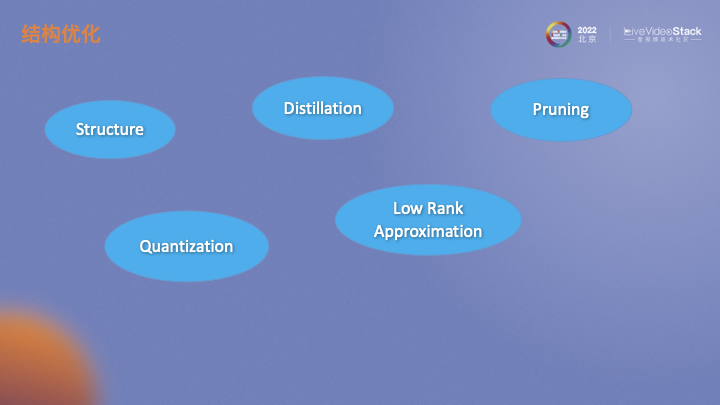
對于模型加速,選取一個合理的,對硬件友好的結構是基礎。基于模型結構基礎上,還可以通過一些方法對模型做進一步的壓縮。模型蒸餾類似于一個遷移學習,將一個大模型的輸出作為監(jiān)督信息指導小模型的訓練。模型剪枝主要是通過評估不同結構、不同通道的重要性對其進行剪枝。模型量化通常訓練的權重是float32,我們通過對其量化成float16甚至int8,也可以加速運算。低秩分解認為深度學習模型權重矩陣非常大,可以將其近似分解成多個低秩矩陣來降低模型運算量。
剪枝分為結構剪枝和非結構剪枝。非結構剪枝對硬件不友好,在實際應用中少見。結構化剪枝有一點需要注意,如果是在硬件上實時去跑,通道不是8、16、32的倍數(shù)的話,后續(xù)也需要通道對齊的處理,此時效果不一定會好。經過模型選擇、優(yōu)化、加速處理后,我們的模型與當前大模型相比,在性能相同的情況下參數(shù)量和運算量遠低于大模型。
-05-
QoE展望

目前這些QoE指標仍在內部打磨中,后續(xù)會開放給開發(fā)者和用戶。后續(xù)階段還要對端到端RTE-QoE指標進行完善,包括適配場景的增加、整合流暢度、延遲和音頻MOS。在對這些指標建模后還需要一個完備可靠的算法驗收確保其在線上線下表現(xiàn)一致。最后,基于畫面的QoE算法隨著視頻分辨率的上升其運算量也會相應提高。畫面剪切也會損失模型性能,怎么平衡模型準確率與不同分辨率下運算量也是需要考慮的。
審核編輯 :李倩
-
算法
+關注
關注
23文章
4698瀏覽量
94735 -
建模
+關注
關注
1文章
315瀏覽量
61432 -
網(wǎng)絡傳輸
+關注
關注
0文章
143瀏覽量
17890
原文標題:實時互動下視頻 QoE 端到端輕量化網(wǎng)絡建模
文章出處:【微信號:livevideostack,微信公眾號:LiveVideoStack】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
樹莓派做一個網(wǎng)絡攝像頭上傳實時視頻到云服務器,云服務器推流到客戶端可以實現(xiàn)嗎
輕量化神經網(wǎng)絡的相關資料下載
汽車輕量化采用3D打印
基于紫光同創(chuàng)FPGA的多路視頻采集與AI輕量化加速的實時目標檢測系統(tǒng)
基于WiMAX接入技術的端到端網(wǎng)絡架構
端到端實時控制系統(tǒng)解決方案
常見的輕量化材料的分類與汽車輕量化材料的應用

山東首個基于端到端5G網(wǎng)絡的專業(yè)無人機測試飛行
端到端駕駛模型的發(fā)展歷程
我國正式啟動了5G網(wǎng)絡切片端到端總體架構標準研制工作
基于深度神經網(wǎng)絡的端到端圖像壓縮方法

如何實現(xiàn)端到端網(wǎng)絡切片?
基于矢量化場景表征的端到端自動駕駛算法框架

端到端InfiniBand網(wǎng)絡解決LLM訓練瓶頸






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論