") 基于LLAMA的魔改部署
基于LLAMA的魔改部署
借著熱點(diǎn),簡單聊聊大模型的部署方案,作為一個(gè)只搞過CV部署的算法工程師,在最近LLM逐漸改變生活的大背景下,猛然意識到LLM部署也是很重要的。大模型很火,而且確實(shí)有用(很多垂類場景可以針對去訓(xùn)練),并且和Vision結(jié)合的大模型也逐漸多了起來。所以怎么部署大模型是一個(gè)超級重要的工程問題,很多公司也在緊鑼密鼓的搞著。
目前效果最好討論最多的開源實(shí)現(xiàn)就是LLAMA,所以我這里討論的也是基于LLAMA的魔改部署。
基于LLAMA的finetune模型有很多,比如效果開源最好的vicuna-13b和較早開始基于llama做實(shí)驗(yàn)的alpaca-13b,大家可以看:
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard 開源LLM
https://lmsys.org/blog/2023-05-03-arena/ 基于llama的開源對比
https://github.com/camenduru/text-generation-webui-colab 一些開源LLM的notebook
至于為啥要選LLAMA,因?yàn)楫?dāng)前基于LLAMA的模型很多,基礎(chǔ)的llama的效果也不錯(cuò),當(dāng)然RWKV也很不錯(cuò),我也一直在看。
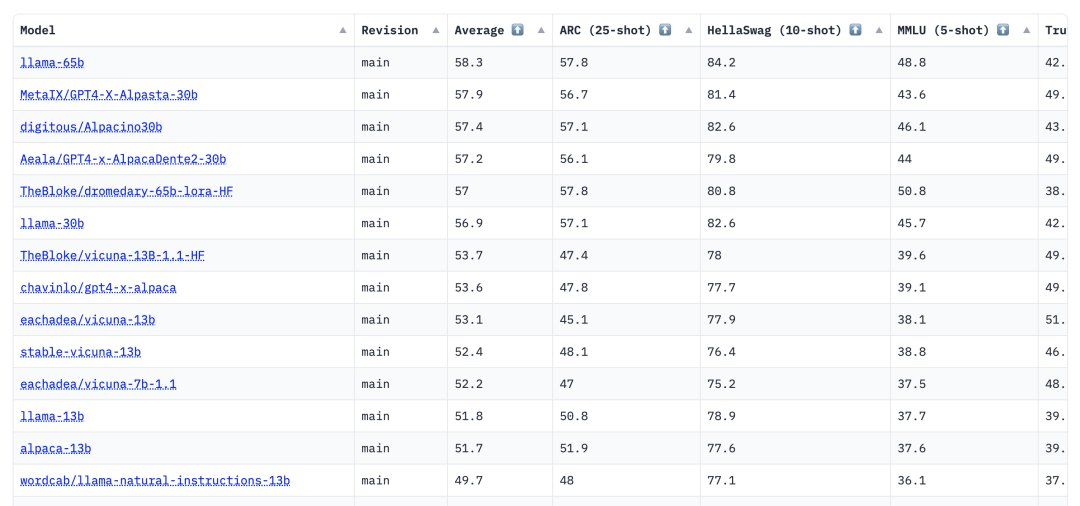
具體的可以看這里,https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
Github上較多的是實(shí)現(xiàn)是直接python推理然后基于gradio的網(wǎng)頁端展示,還不能被當(dāng)成服務(wù)調(diào)用(或者說不大優(yōu)雅),一般來說作為服務(wù):
響應(yīng)速度要快,每秒的tokens越多越好
穩(wěn)定性,出現(xiàn)core了不會影響推理或者可以及時(shí)恢復(fù)
支持各種形式,http、sse、grpc等形式
其實(shí)最重要的一點(diǎn)還是要快,其次必須要量化,因?yàn)榇竽P偷臋?quán)重往往很大,量化可以有效減小權(quán)重(省顯卡),是非常必要的。要做成服務(wù)的話,需要稍稍花一點(diǎn)功夫和魔改一下,幸運(yùn)的是網(wǎng)上已經(jīng)有不錯(cuò)的demo實(shí)現(xiàn)供我們嘗試,這篇文章主要是總結(jié)下以LLAMA為例的LLM部署方案,希望能拋磚引玉。
PS:我們常用的ChatGPT據(jù)說是居于Python服務(wù)搭建的,相比模型的耗時(shí),python環(huán)境的開銷可以忽略不計(jì)。
以LLAMA為例
LLM很大,比如GPT3-175B的大模型,700GB的參數(shù)以及運(yùn)行過程中600GB的激活值,1.3TB總共,正常來說,得32個(gè)A100-40GB才能放的下。
但實(shí)際應(yīng)用中,消費(fèi)級顯卡要比專業(yè)顯卡便宜的多(比如3090相比A10,同樣都是24G顯存),所以用消費(fèi)級顯卡部署LLM也很有錢途。一張卡放不下那就放兩張,如果沒有nvlink,那么PCIE的也湊合用。
回到LLAMA模型,有7B、13B、30B、65B的版本,當(dāng)然是越大的版本效果最好,相應(yīng)的也需要更多的顯存(其實(shí)放到內(nèi)存或者SSD也是可以的,但是速度相比權(quán)重全放到顯存里頭,肯定要慢)。
LLAMA的實(shí)現(xiàn)很多,簡單列幾個(gè)我看過的,都可以參考:
https://github.com/juncongmoo/pyllama 原始llama的實(shí)現(xiàn)方式
https://github.com/qwopqwop200/GPTQ-for-LLaMa 支持量化,INT4、INT8量化的llama
https://github.com/tpoisonooo/llama.onnx.git 以O(shè)NNX的方式運(yùn)行l(wèi)lama
量化和精度
對于消費(fèi)級顯卡,直接FP32肯定放不下,一般最基本的是FP16(llama的7B,F(xiàn)P16需要14G的顯存,大多數(shù)的消費(fèi)級顯卡已經(jīng)說拜拜了),而INT8和INT4量化則就很有用了,舉幾個(gè)例子:
對于3080顯卡,10G顯存,那么13B的INT4就很有性價(jià)比,精度比7B-FP16要高很多
對于3090顯卡,24G顯存,那么30B的INT4可以在單個(gè)3090顯卡部署,精度更高
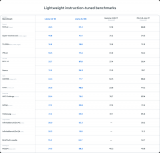
可以看下圖,列舉了目前多種開源預(yù)訓(xùn)練模型在各種數(shù)據(jù)集上的分?jǐn)?shù)和量化精度的關(guān)系:
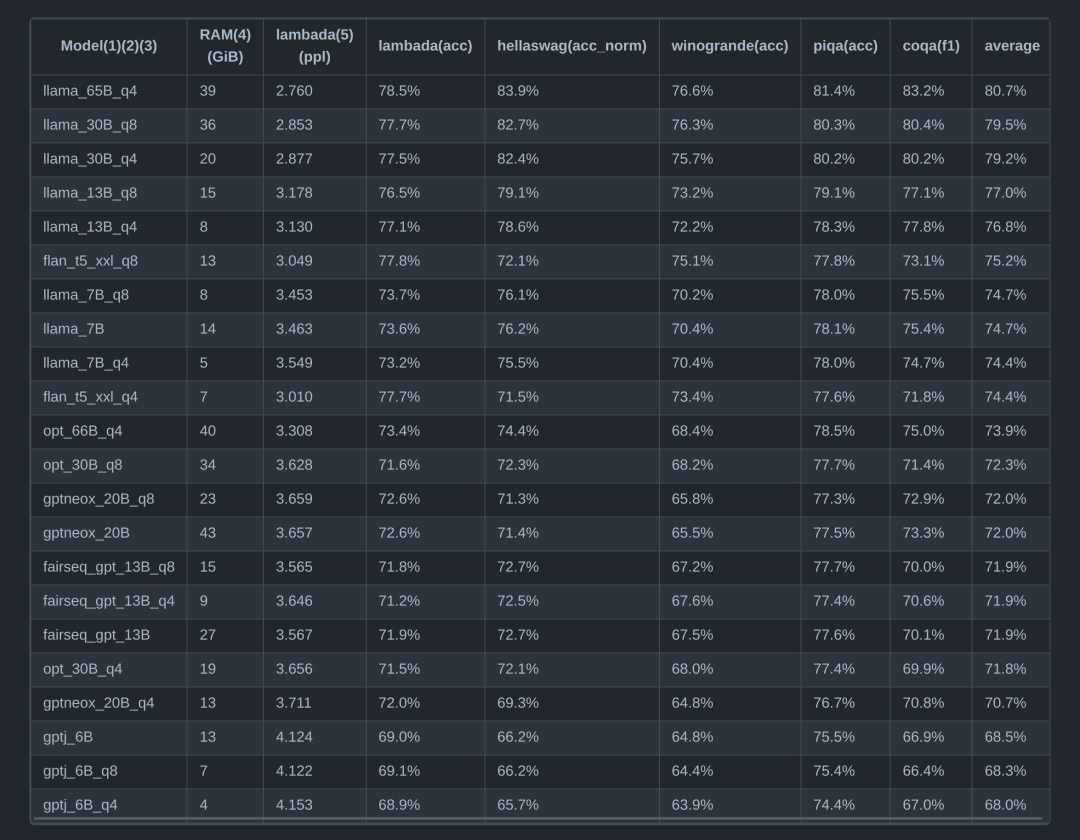
我自己也測試了幾個(gè)模型,我使用的是A6000顯卡,48G的顯存,基于GPTQ-for-LLAMA測試了各種不同規(guī)格模型的PPL精度和需要的顯存大小。
執(zhí)行以下命令CUDA_VISIBLE_DEVICES=0 python llama.py ${MODEL_DIR} c4 --wbits 4 --groupsize 128 --load llama7b-4bit-128g.pt --benchmark 2048 --check測試不同量化精度不同規(guī)格模型的指標(biāo):
#7B-FP16 Median:0.03220057487487793 PPL:5.227280139923096 maxmemory(MiB):13948.7333984375 #7B-INT8 Median:0.13523507118225098 PPL:5.235021114349365 maxmemory(MiB):7875.92529296875 #7B-INT4 Median:0.038548946380615234 PPL:5.268043041229248 maxmemory(MiB):4850.73095703125 #13B-FP16 Median:0.039263248443603516 PPL:4.999974727630615 maxmemory(MiB):26634.0205078125 #13B-INT8 Median:0.18153250217437744 PPL:5.039003849029541 maxmemory(MiB):14491.73095703125 #13B-INT4 Median:0.06513667106628418 PPL:5.046994209289551 maxmemory(MiB):8677.134765625 #30B-FP16 OOM #30B-INT8 Median:0.2696110010147095 PPL:4.5508503913879395 maxmemory(MiB):34745.9384765625 #30B-INT4 Median:0.1333252191543579 PPL:4.526902675628662 maxmemory(MiB):20070.197265625
30B的FP16和65B的爆顯存了,還沒搞自己的多卡環(huán)境,之后會補(bǔ)充結(jié)果到這里。
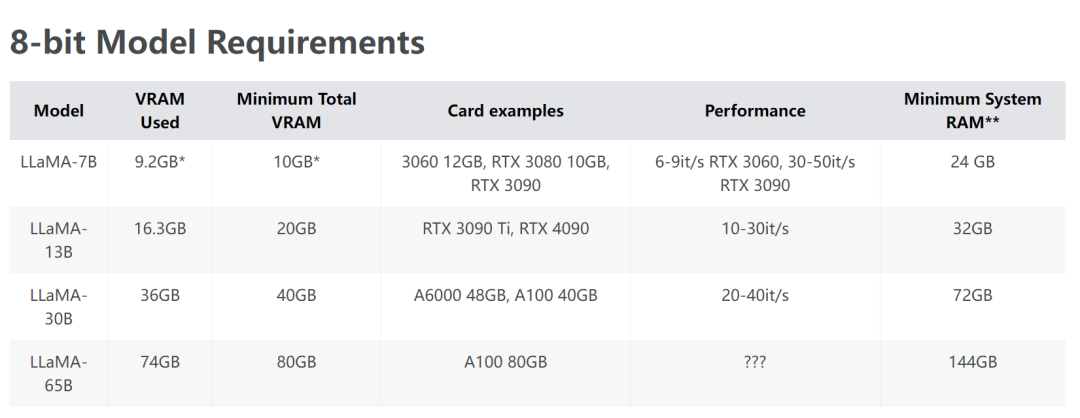
可以先看看其他大佬的測試結(jié)果,大概有個(gè)預(yù)期,65B模型的話,INT4在兩張3090上是可以放得下的:
速度測試
我這邊也測試了llama在huggingface中Python庫的實(shí)現(xiàn)速度、以及基于GPTQ的量化、多卡的速度,其中stream模式參考了text-generation-webui中的Stream實(shí)現(xiàn)。
其中FP16就是直接調(diào)用GPTQ-for-LLaMa/llama_inference.py中未量化的FP16推理,調(diào)用方式為model.generate,model來自:
model=LlamaForCausalLM.from_pretrained(model,torch_dtype='auto', #load_in_8bit=True,device_map='auto' )
而量化版本的模型:
INT8模型調(diào)用方式同F(xiàn)P16,參數(shù)load_in_8bit設(shè)置為True,直接利用hugglingface的transformer庫INT8的實(shí)現(xiàn)
INT4的模型使用GPTQ的方式進(jìn)行量化,具體代碼通過triton語言(區(qū)別于我之前提到的triton inference server)進(jìn)行加速
| 模型 | 平臺 | 精度 | 顯存 | 速度 | 備注 |
|---|---|---|---|---|---|
| llama-7B | A4000 | FP16 | 13.6g |
Output generated in 1.74 seconds (28.74 tokens/s, 50 tokens) Output generated in 9.63 seconds (25.97 tokens/s, 250 tokens) |
GPTQ-for-LLaMa/llama_inference.py 測試包含模型前后處理 利用率99% |
| A4000 | 4-bit | 5g | Output generated in 2.89 seconds (17.51 tokens/s, 50 tokens) | ||
| A4000 | 4-bit | 5g | Output generated in 2.93 seconds (17.11 tokens/s, 50 tokens) |
stream模式 一次輸出1個(gè)token |
|
| A4000 | 4-bit | 3.4+2.3g | Output generated in 2.91 seconds (17.31 tokens/s, 50 tokens) |
多卡測試雙A4000 兩張卡利用率 20-30左右 |
|
| A4000 | INT8 | 8.3g |
Output generated in 10.20 seconds (5.8 tokens/s, 50 tokens) int8 實(shí)現(xiàn)用的huggingface的實(shí)現(xiàn) |
利用率25% |
我這邊拿我的A4000測了下,測試從tokenizer編碼后開始,到tokenizer解碼后結(jié)束。
大概的結(jié)論:
FP16速度最快,因?yàn)镮NT4和INT8的量化沒有優(yōu)化好(理論上INT8和INT4比FP16要快不少),而INT4的triton優(yōu)化明顯比huggingface中INT8的實(shí)現(xiàn)要好,建議使用INT4量化
stream模式和普通模型的速度似乎差不多
A6000的懶得測試了,補(bǔ)充一個(gè)網(wǎng)上搜到的指標(biāo),A6000相比A4000相當(dāng)于類似于3090和3070的性能差距吧...

LLM和普通小模型在部署方面的區(qū)別
在我以往的任務(wù)中,都是處理CV相關(guān)的模型,檢測、分類、識別、關(guān)鍵點(diǎn)啥的,最大模型可能也只有2、3G的樣子。平時(shí)的檢測模型,大點(diǎn)的也就300多M,在FP16或者INT8量化后則更小了,所以一般來說沒有顯存焦慮(當(dāng)然有特殊情況,有時(shí)候可能會在一張卡上部署很多個(gè)模型,比如自動駕駛場景或者其他工業(yè)場景,這時(shí)候也是需要合理分配模型的顯存占用)。
但部署LLM這種大模型就不一樣了,隨便一個(gè)6、7B的模型,動不動就20多G的權(quán)重;65B、175B的模型更是有幾百G,模型變得異常大,因?yàn)檫@個(gè)原因,原來的部署方式都要發(fā)生一些變化。
模型方面的區(qū)別
首先模型很大,大模型導(dǎo)出ONNX有一些問題,ONNX保存大模型的權(quán)重存在一些限制
LLM模型中一般包含很多if-else分支,比如是否采用kv-cache,對轉(zhuǎn)換一些個(gè)別結(jié)構(gòu)的模型(比如tensorrt)不是很友好
我們之前都是單GPU運(yùn)行,多GPU的話,很多常用的runtime都不支持,onnxruntime或者tensorrt(tensorrt有內(nèi)測多GPU的支持)默認(rèn)都不支持多GPU
對于大模型來說,量化是必要的,因?yàn)镕P16或者FP32的模型需要的顯存太大,都是錢啊。量化起來也不容易,QAT代價(jià)太大,PTQ校準(zhǔn)的時(shí)候也需要很大的內(nèi)存和顯存,會用INT8和INT4量化
網(wǎng)上對于這類模型的加速kernel不是很多,可以參考的較少,很多需要自己手寫
服務(wù)方式的區(qū)別
對于小模型來說,推理速度一般不會太慢,基本都在500ms以內(nèi),稍微等待下就得到結(jié)果了,也即是普通的http請求,一次請求得到一次結(jié)果。
而LLM因?yàn)槭且粋€(gè)一個(gè)token產(chǎn)出來的,如果等全部token都出來再返回,那么用戶等待時(shí)間就挺長的,體驗(yàn)不好,所以一般都是使用stream模式,就是出一點(diǎn)返回一點(diǎn),類似于打字機(jī)的趕腳。
部署方案討論
這部分是本篇文章主要想說的地方,也是想和大家討論,一起想想方案,拋磚引玉。
對于部署像LLAMA這種的大語言模型,我之前也沒有經(jīng)驗(yàn),瀏覽了一些開源的倉庫和資料,大概也有些思路,簡單總結(jié)總結(jié),有那么幾個(gè)方案:
依賴Python實(shí)現(xiàn)的方案
和普通的CV模型一樣,python實(shí)現(xiàn)肯定是最簡單也是實(shí)現(xiàn)最多的,我們可以基于現(xiàn)有的開源實(shí)現(xiàn)直接包一層服務(wù)框架,類似于flask的服務(wù)即可,但是也需要有一定的可靠性。
所以這里可以選擇triton-inference-server的python后端,自己包一層前后處理,可以支持stream模式(使用grpc)。
這個(gè)實(shí)現(xiàn)起來比較簡單,多注意輸入輸出即可,相對于CV來說,我們的輸入可以是text或者是input_ids,要和圖像的unchar區(qū)別開,加速部分只能依賴python實(shí)現(xiàn),同時(shí)也依賴python環(huán)境。

fastertransformer_backend方案
對于生產(chǎn)環(huán)境的部署,可以使用triton inference server,然后基于tritonserver有fastertransformer-backend。fastertransformer-backend是一個(gè)支持多個(gè)LLM模型的backend,手工實(shí)現(xiàn)了很多高性能的針對transformer的算子,每個(gè)模型都是手寫cuda搭建起來的,性能相比使用庫要高一檔。不過代價(jià)就是比較難支持新的模型框架,需要修改大量的源碼。
NVIDIA Triton introduces Multi-GPU Multi-node inference. It uses model parallelism techniques below to split a large model across multiple GPUs and nodes:
Pipeline (Inter-Layer) Parallelism that splits contiguous sets of layers across multiple GPUs. This maximizes GPU utilization in single-node.
Tensor (Intra-Layer) Parallelism that splits individual layers across multiple GPUs. This minimizes latency in single-node
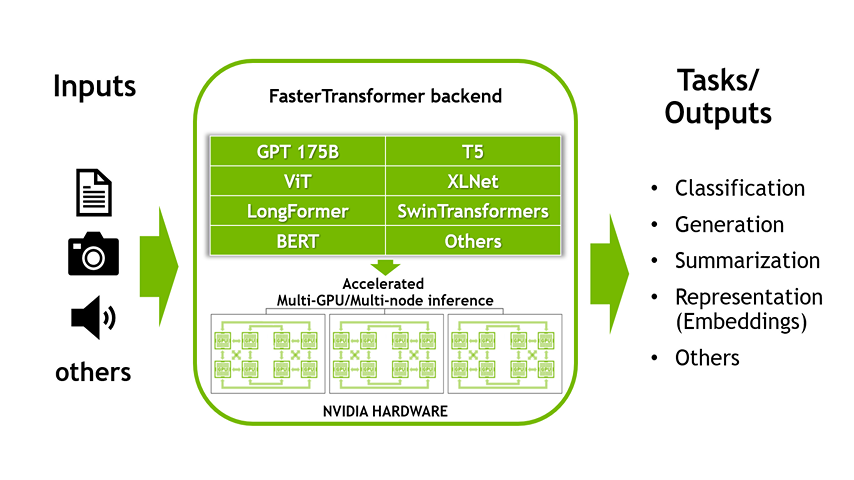
所幸開源社區(qū)的大佬很多,近期的非官方PR也支持了LLAMA。我自己嘗試跑了下速度要比第一個(gè)huggingface的實(shí)現(xiàn)要快20%,這個(gè)精度基于FP16,支持多卡,目前暫時(shí)未支持INT8和INT4。
利用加速庫分而治之的方案
我們知道LLAMA的7B模型包含32個(gè)結(jié)構(gòu)相同的decoder:
#transformers/src/transformers/models/llama/modeling_llama.py self.layers=nn.ModuleList([LlamaDecoderLayer(config)for_inrange(config.num_hidden_layers)])
因此我們也可以將這32個(gè)子模型分別使用我們常用的加速庫部署起來,比如7B的大模型,拆分成子模型每個(gè)模型300多M,使用TensorRT可以輕松轉(zhuǎn)換,也有大佬已經(jīng)在做了:
https://github.com/tpoisonooo/llama.onnx
7B的llama模型轉(zhuǎn)成ONNX大概是這些:
decoder-merge-0.onnx
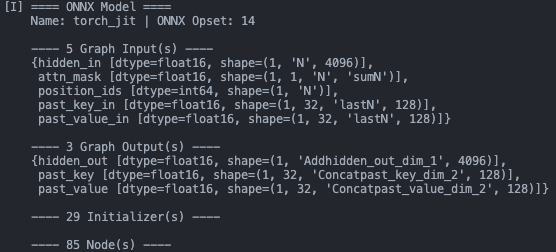
embed.onnx
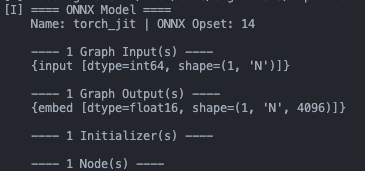
head.onnx
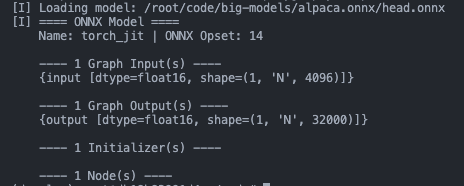
norm.onnx
串起來的話,可以把這些模型放到不同的顯卡上也是可以的,比如兩張顯卡,第一張卡放15個(gè)子模型,第二張卡放剩余17個(gè)子模型,組成pipeline parallelism也是可以的。
有幾點(diǎn)需要注意:
加速庫可以使用不限于TensorRT,比如TVM、AItemplate啥的
需要一個(gè)后端將所有子模型串起來,最好C++實(shí)現(xiàn)
對于kv-cache,怎么存放需要考慮下
可以使用triton-inference-server去組pipeline,不同子模型的instance可以放到不同的gpu上。
后記
暫時(shí)先說這些,這篇文章之后也會隨時(shí)更新。目前只是簡單列了列我自己的想法,大家如果有好的想法也歡迎跟老潘一起交流。
每天出的新東西新技術(shù)太多了,看不過來,這篇文章也拖了好久,上述的這三種方案我自己都嘗試過了,都是可行的,大家感興趣可以試試,不過有個(gè)消息是TensorRT已經(jīng)在默默支持多卡推理了,最快可能下個(gè)月(6月)就會出來(可能是對外release),不知道TensorRT大模型版本怎么樣?

-
顯存
+關(guān)注
關(guān)注
0文章
111瀏覽量
13852 -
開源
+關(guān)注
關(guān)注
3文章
3587瀏覽量
43472 -
模型
+關(guān)注
關(guān)注
1文章
3486瀏覽量
49989
原文標(biāo)題:參考鏈接
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
[技術(shù)] 【飛凌嵌入式OK3576-C開發(fā)板體驗(yàn)】llama2.c部署
魔聲耳機(jī)INSPIRATION是浮夸的高富帥還是低調(diào)的經(jīng)濟(jì)適用男
為什么魔聲耳機(jī)火了?
【微信精選】如此魔改樹莓派?工程師的腦洞不服不行!
如何對rvv intrinsic的代碼進(jìn)行魔改?
魔改CPU技術(shù)有什么優(yōu)缺點(diǎn)
新一代iPhone 12“不香”了,魔改iPhone 12忽悠不了人
LLaMA 2是什么?LLaMA 2背后的研究工作
Llama 3 王者歸來,Airbox 率先支持部署

【AIBOX上手指南】快速部署Llama3

如何將Llama3.1模型部署在英特爾酷睿Ultra處理器

使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型
用Ollama輕松搞定Llama 3.2 Vision模型本地部署






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論