 BTF 實踐指南[譯]
BTF 實踐指南[譯]
BPF 是 Linux 內核中基于寄存器的虛擬機,可安全、高效和事件驅動的方式執行加載至內核的字節碼。與內核模塊不同,BPF 程序經過驗證以確保它們終止并且不包含任何可能鎖定內核的循環。BPF 程序允許調用的內核函數也受到限制,以確保最大的安全性以防止非法的訪問。
盡管 BPF 為編寫事件驅動的內核空間代碼提供了一種有效的解決方案,但開發人員的體驗仍無法與其他編程語言或框架相提并論。BPF 開發的兩個最重要的問題是缺乏簡單的調試和可移植性。
為了緩解這些問題,我們轉向 BTF[1]。BTF 是針對 BPF 程序的類型信息進行編碼文件格式,通過 BPF 程序的類型信息進行編碼,為程序提供更好的內省(introspection)和可見性。本文我們將介紹 BPF 的典型局限性以及如何使用 BTF 來克服。
請注意,本文使用術語 BPF 來表示 eBPF[2](擴展的 Berkeley 數據包過濾器),eBPF 擴展 “ 經典 ” cBPF。
1. BPF 的常見限制
在 BPF 程序的開發和運行過程中,我們會經常會面臨調試限制和可移植性問題,如前所述。
1.1 調試限制
幾乎所有現代編程語言都有對應的調試器,通過調試器可以幫助我們更好了解正在運行的程序。例如,GDB[3] 是 C 和 C++ 的常用調試器,除其他外,基于 GDB 我們可以打印正在運行的程序中的變量值。
 圖 GDB 變量打印
圖 GDB 變量打印但是很不幸,BPF 程序并沒有類似的這樣的工具。盡管檢查數據只是調試的一小部分,但為 BPF 實現類似的結果可以為未來的廣泛調試工具打開一扇門。為了實現這一點,BPF 需要知道關于程序的相關的部分元數據。
這類關于類型信息的元數據,正是 BTF 封裝的內容。
1.2 可移植性
BPF 程序在內核空間中運行,可以訪問內部內核狀態和數據結構。但是,并沒有辦法保證內核數據結構和類型在不同內核版本是相同的,甚至相同內核版本的不同機器之間也可能不同(這可能取決于內核編譯選項)。這意味著在一臺機器上編譯的 BPF 程序并不能保證在另一臺機器上正確運行。
假設 BPF 程序正在從內核結構中讀取一個字段,該字段位于距結構開頭的偏移量 8 處。現在在更高版本的內核中,在該變量之前添加了其他字段,導致訪問的字段的偏移量變成了 24,這會導致 BPF 程序在偏移量 8 讀取的數據可能為垃圾數據。類似情況,也可能會發生某些字段最終得到在后續內核版本中的重命名。例如,在內核版本 4.6 和 4.7 之間,thread_struct 的 fs 字段可能會重命名為 fsbase 。最后,還可能是因為配置禁用了某些功能并編譯了部分結構,導致可能 BPF 程序在不同的內核配置上運行。
所有上述這些場景的存在,意味著你不能在當前機器上編譯 BPF 程序并將二進制文件分發到其他系統。
一個標準的解決方案是使用 BPF Compiler Collection (BCC)[4]。使用 BCC,你通常將 BPF 程序作為純字符串嵌入到用戶空間程序(例如,Python 程序)中。在目標機器上執行期間,BCC 使用其嵌入式 Clang/LLVM 組合并使用本地安裝的內核頭文件動態編譯程序。
然而,這種方法引入了更多問題。首先,Clang/LLVM 組合非常龐大,將其嵌入到應用程序中會導致二進制文件大小過大。它還占用大量資源,并且會在編譯期間耗盡大量資源。最后,這種方法需要在目標機器上安裝內核頭文件,但情況可能并非總是如此。
解決方案是 BPF CO-RE(一次編譯 —— 隨處運行)。使用 BTF,我們可以消除在目標機器上安裝內核頭文件或將 Clang/LLVM 嵌入應用程序并在目標機器上編譯的需要。
2. BTF 是什么?
如前所述,BTF 是編碼 BPF 程序和 map 結構等相關的調試信息的元數據格式。BTF 可以將元數據數據類型、函數信息和行信息編碼成一種緊湊的格式。
在非 BPF 程序中,這些元數據通常使用 DWARF[5] 格式存儲。但是,DWARF 格式的實現還是相當復雜和冗長,并且由于其在大小方面的開銷,使其不適合包含在內核中。而 BTF 是一種緊湊而簡單的格式,讓其可以包含在內核鏡像中。
BTF 使用少數類型描述[6] 符之一表示每種數據類型:
- BTF_KIND_INT
- BTF_KIND_PTR
- BTF_KIND_ARRAY
- BTF_KIND_STRUCT
- 等等
類型信息存儲在生成的 ELF 的 .BTF 部分中。除了類型描述符之外,此部分還對字符串進行編碼。函數和行信息存儲在 .BTF.ext 部分中。
關于 BTF 的詳細說明,可以查看 Linux Kernel 文檔[7]。
3. BTF 快速入門
3.1 BPF 快速入門
現在讓我們通過使用 BTF 漂亮地打印[8] BPF map 的教程進行更多實踐,從而顯著改進調試。
要開始,我們需要在啟用 CONFIG_DEBUG_INFO_BTF 選項的情況下編譯 Linux 內核。大多數發行版都啟用了此選項,但你可以通過運行以下命令進行檢查:
$zgrepCONFIG_DEBUG_INFO_BTF=y/proc/config.gz
#可選:grep CONFIG_DEBUG_INFO_BTF=y /boot/config*
當然,我們還需要在計算機上安裝 Clang 和 LLVM[9]。
由于我們需要將編寫 XDP[10] 程序來處理網絡設備上的數據包,因此創建一個虛擬網絡接口[11] 是個好主意,這樣就不會最終失去物理接口中的互聯網連接。設置虛擬接口的最簡單方法是使用此 repo[12]。
克隆 repo 并設置一個名為 test1 的虛擬接口:
$gitclone[email protected]:xdp-project/xdp-tutorial.git
$cdxdp-tutorial/testenv
$sudo./testenv.shsetup--name=test1--legacy-ip
現在編寫一個 BPF 程序來計算接口上接收到的 IPv4 和 IPv6 數據包的數量。文件 xdp_count.c 的文件內容如下:
#include
在前面的代碼中,名為 cnt 的 BPF map 存儲數據包的數量。cnt 是兩個元素的數組。IPv6 數據包的數量存儲在 key 0 中,IPv4 數據包的數量存儲在 key 1 中。
使用 Clang 編譯代碼:
$clang-O2-Wall-g-targetbpf-cxdp_count.c-oxdp_count.o
接下來,使用 bpftool 加載程序:
$sudobpftoolprogloadxdp_count.o/sys/fs/bpf/xdp_counttypexdp
運行以下命令并記下我們剛加載的程序的 ID 和程序正在使用的 map 的 ID:
$sudobpftoolproglist
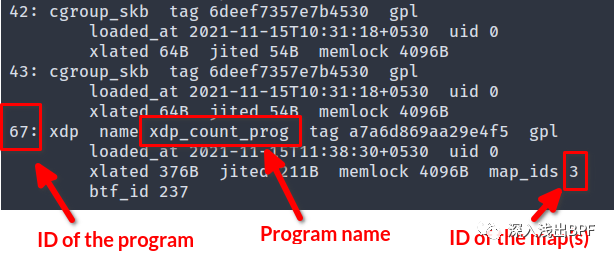 圖 bpftool prog 列表的輸出
圖 bpftool prog 列表的輸出我們還可以通過運行 sudo bpftool map list 來獲取 map ID。
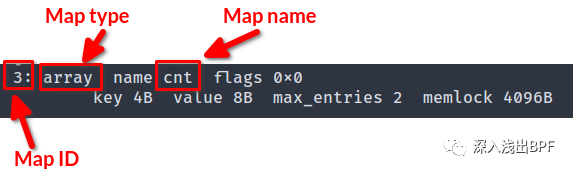
此命令為我們提供 map 的名稱、類型、鍵大小、值大小和最大條目數。
現在,將 BPF 程序附加到網絡設備。
$sudobpftoolnetattachxdpgenericiddevtest1
將 program_id 替換為程序的 ID,并將 device_name 替換為程序附加到的網絡設備的名稱(例如 enp34s0)。
現在,向該設備發送一些數據包。測試環境腳本已經提供了一個方便的 ping 命令來執行此操作:
$sudo./testenv.shping#ForIPv6
$sudo./testenv.shping--legacy-ip#ForIPv4
打印 map 并檢查處理的數據包情況:
$sudobpftoolmapdumpid

如圖所示,map 中有兩個預期的元素。這些值采用十六進制格式,并且還取決于運行機器的字節順序。在截圖中,它是小端格式,這意味著已經處理了 22 個 IPv6 和 4 個 IPv4 數據包。
很明顯,結果是十六進制的,小端格式,一看就不好調試。因此,我們需要使用 BTF 對 map 進行注釋,以便更好地展示。
如下更改 cnt 的聲明并將新代碼保存在 xdp_count_btf.c 中 -
...
struct{
__uint(type,BPF_MAP_TYPE_ARRAY);
__type(key,__u32);
__type(value,long);
__uint(max_entries,2);
}cntSEC(".maps");
...
請注意,部分名稱現在為 .maps,并且地圖本身已使用啟用 BTF 的宏 __uint 和 __type 進行了注釋。
使用 Clang 編譯代碼:
clang-O2-Wall-g-targetbpf-cxdp_count_btf.c-oxdp_count_btf.o
使用 -g 標志將創建調試信息并生成 BTF。請注意,之前也使用了 -g 標志,因為 libbpf需要它[13] 來加載程序;然而,以前 map 沒有被 BTF 注釋,所以 bpftool 不能夠優雅地進行打印。
驗證 BTF 部分是否存在于生成的目標文件中。
$llvm-objdump-hxdp_count_btf.o
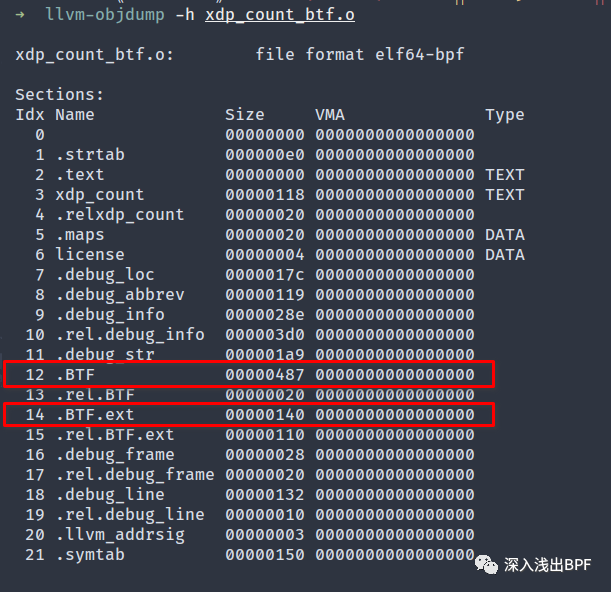
如前所述,.BTF 部分包含類型和字符串數據,.BTF.ext 部分對 func_info 和 line_info 數據進行編碼。
首先,卸載前面的 BPF 程序。
$sudobpftoolnetdetachxdpgenericdevtest1
然后按照類似的過程加載新程序并將其附加到接口,然后對接口發送一些數據:
$sudobpftoolprogloadxdp_count_btf.o/sys/fs/bpf/xdp_count_btftypexdp
$sudobpftoolproglist
$sudobpftoolnetattachxdpgenericiddevtest1
$sudo./testenv.shping
$sudo./testenv.shping--legacy-ip
最后,打印新程序對應的 map 。如果一切順利,這一次的輸出會有很大的不同。

它不僅以 JSON 格式打印得很漂亮,而且值也是十進制的,使其更具可讀性和易懂性。
3.1 BTF 和 CO-RE
如前所述,BTF 可以啟用 CO-RE 使 BPF 程序可移植到不同的內核版本或用戶配置。我們也可以通過生成內核本身的 BTF 信息來消除對本地內核頭文件的需求:
$bpftoolbtfdumpfile/sys/kernel/btf/vmlinuxformatc>vmlinux.h
上述命令將創建一個巨大的 vmlinux.h 文件,其中包含所有內核類型,包括作為 UAPI 的一部分公開的類型、內部類型和通過 kernel-devel 可用的類型,以及一些其他地方不可用的更多內部類型。在 BPF 程序中,我們可以只 #include "vmlinux.h" 并刪除其他內核頭文件,如
擺脫內核頭文件依賴性只是 BTF 可以實現的目標的冰山一角。如需 BTF 和 CO-RE 的詳盡解釋,可以閱讀這篇文章[14]。
4. 結論
BTF 是一個非常強大的工具,可以使 BPF 程序更易于調試和移植。由于它是一項相對較新的技術,因此開發仍在進行中,你可以期待在未來看到大量改進。
本文讓你大致了解 BTF 可以實現什么。你可能已經了解了 BPF 的缺點、BPF 是什么以及如何使用 BTF 注解 map 和打印 map 結構。最后,你還了解了 BTF 如何充當通過 CO-RE 增強可移植性的起點。
審核編輯 :李倩
-
寄存器
+關注
關注
31文章
5423瀏覽量
123442 -
編程語言
+關注
關注
10文章
1955瀏覽量
36160 -
虛擬機
+關注
關注
1文章
962瀏覽量
29084
原文標題:BTF 實踐指南[譯]
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄






 工商網監
工商網監
評論