") 以transformers框架實現(xiàn)中文OFA模型的訓練和推理
以transformers框架實現(xiàn)中文OFA模型的訓練和推理
OFA是阿里巴巴發(fā)布的多模態(tài)統(tǒng)一預訓練模型,基于官方的開源項目,筆者對OFA在中文任務上進行了更好的適配以及簡化,并且在中文的Image Caption任務上進行了實踐驗證,取得了非常不錯的效果。本文將對上述工作進行分享。
01
模型簡介
OFA是由阿里達摩院發(fā)布的多模態(tài)預訓練模型,OFA將各種模態(tài)任務統(tǒng)一于Seq2Seq框架中。如下圖所示,OFA支持的下游任務包括但不限于Image Caption、Image Classification、 Image genaration、Language Understanding等等。
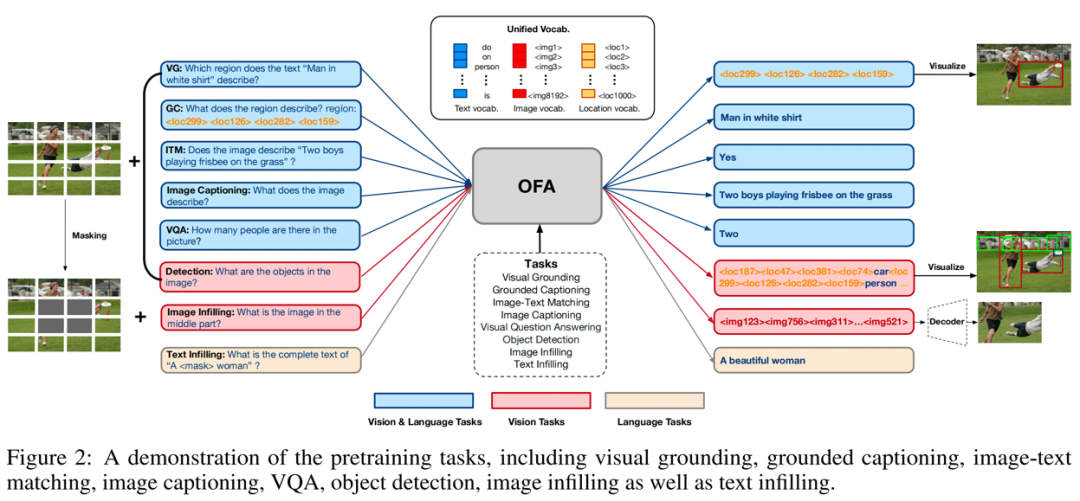
02
項目介紹
項目動機 & 主要工作
本項目旨在以HuggingFace的transformers框架,實現(xiàn)中文OFA模型的訓練和推理。并且希望將官方開源的fairseq版本的中文預訓練權重,轉(zhuǎn)化為transformers版本,以便用于下游任務進行finetune。
在OFA官方項目中,同時實現(xiàn)了fairseq和transformers兩套框架的模型結構,并且分別開源了中文和英文的模型權重。基于下列原因,筆者開發(fā)了本項目:
由于筆者對transformers框架更熟悉,所以希望基于transformers框架,使用域內(nèi)中文數(shù)據(jù)對OFA模型進行finetune,但OFA的中文預訓練權重只有fairseq版本,沒有transformers版本。
如何將fairseq版本的OFA預訓練權重轉(zhuǎn)換為transformers版本,從而便于下游任務進行finetune。
官方代碼庫中,由于需要兼容各種實驗配置,所以代碼也比較復雜冗余。筆者希望能夠?qū)⒑诵倪壿媱冸x出來,簡化使用方式。
基于上述動機,筆者的主要工作如下:
閱讀分析OFA官方代碼庫,剝離出核心邏輯,包括訓練邏輯、model、tokenizer等,以transformers框架進行下游任務的訓練和推理,簡化使用方式。
將官方的fairseq版本的中文預訓練權重,轉(zhuǎn)化為transformers版本,用于下游任務進行finetune。
基于本項目,使用中文多模態(tài)MUGE數(shù)據(jù)集中的Image Caption數(shù)據(jù)集,以LiT-tuning的方式對模型進行finetune,驗證了本項目的有效性。
開源五個transformers版本的中文OFA模型權重,包括由官方權重轉(zhuǎn)化而來的四個權重,以及筆者使用MUGE數(shù)據(jù)集finetune得到的權重。
訓練細節(jié)
筆者使用MUGE數(shù)據(jù)集中的Image Caption數(shù)據(jù),將其中的訓練集與驗證集進行合并,作為本項目的訓練集。其中圖片共5.5w張,每張圖片包含10個caption,最終構成55w個圖文對訓練數(shù)據(jù)。關于MUGE數(shù)據(jù)集的說明詳見官方網(wǎng)站。
caption數(shù)據(jù),jsonl格式:
{"image_id": "007c720f1d8c04104096aeece425b2d5", "text": ["性感名媛蕾絲裙,盡顯優(yōu)雅撩人氣質(zhì)", "衣千億,時尚氣質(zhì)名媛范", "80后穿唯美蕾絲裙,綻放優(yōu)雅與性感", "修身連衣裙,女人就該如此優(yōu)雅和美麗", "千億包臀連衣裙,顯出曼妙身姿", "衣千億包臀連衣裙,穿的像仙女一樣美", "衣千億連衣裙,令人奪目光彩", "奔四女人穿氣質(zhì)連衣裙,高雅名媛范", "V領包臀連衣裙,青春少女感", "衣千億包臀連衣裙,穿出曼妙身姿提升氣質(zhì)"]}
{"image_id": "00809abd7059eeb94888fa48d9b0a9d8", "text": ["藕粉色的顏色搭配柔軟舒適的冰絲面料,滿滿的時尚感,大領設計也超級好看,露出性感鎖骨線條,搭配寬腰帶設計,優(yōu)雅溫柔又有氣質(zhì)", "傳承歐洲文化精品女鞋,引領風尚潮流設計", "歐洲站風格女鞋,演繹個性時尚裝扮", "高品質(zhì)原創(chuàng)涼鞋,氣質(zhì)與華麗引領春夏", "歐洲風格站艾莎女鞋經(jīng)典款式重新演繹打造新一輪原創(chuàng)單品優(yōu)雅鞋型盡顯女人的柔美,十分知性大方。隨意休閑很顯瘦,不僅顯高挑還展現(xiàn)纖細修長的腿型,休閑又非常潮流有范。上腳舒適又百搭。", "陽春顯高穿搭,氣質(zhì)單鞋不可缺少", "冰絲連衣裙,通勤優(yōu)雅范", "一身粉色穿搭,夢幻迷人", "艾莎女性,浪漫摩登,演繹角色轉(zhuǎn)換", "超時尚夏季涼鞋,一直“走”在時尚的前沿"]}
圖片數(shù)據(jù),tsv格式(img_id, ' ', img_content)(base64編碼):
007c720f1d8c04104096aeece425b2d5 /9j/4AAQSkZJRgABAgAAAQA... 00809abd7059eeb94888fa48d9b0a9d8 /9j/2wCEAAEBAQEBAQEBAQE...
訓練時,筆者使用LiT-tuning(Locked-image Text tuning)策略,也就是將encoder的權重進行凍結,僅對decoder的權重進行訓練。加載ofa-cn-base預訓練權重,使用55w的中文圖文對, batch size=128,開啟混合精度訓練,warmup step為3000步,學習率為5e-5,使用cosine衰減策略,訓練10個epoch,大約42500個step,最終訓練loss降到0.47左右。
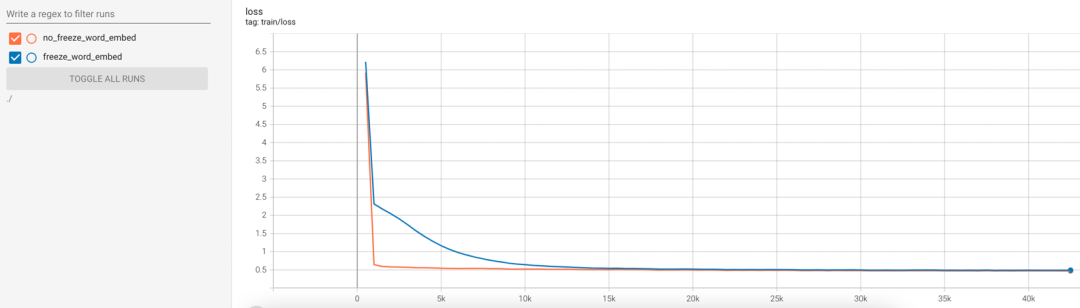
由于encoder與decoder共享詞向量權重,筆者還分別嘗試了凍結與不凍結詞向量兩種訓練方式,兩者的訓練loss的變化趨勢如下圖所示。可以看到,訓練時不凍結詞向量權重,模型的收斂速度提升非常顯著, 但相應地也需要更多顯存。在訓練時凍結詞向量權重,可以節(jié)省顯存并加快訓練速度,將freeze_word_embed設為true即可。
使用方法
模型的使用方法非常簡單,首先將項目clone到本地機器上,并且安裝相關依賴包。
gitclonehttps://github.com/yangjianxin1/OFA-Chinese.git pip install -r requirements.txt
使用如下代碼,即可加載筆者分享的模型權重(代碼會將模型權重自動下載到本地),根據(jù)圖片生成對應的文本描述。
from component.ofa.modeling_ofa import OFAModelForCaption from torchvision import transforms from PIL import Image from transformers import BertTokenizerFast model_name_or_path = 'YeungNLP/ofa-cn-base-muge-v2' image_file = './images/test/lipstick.jpg' # 加載預訓練模型權重 model = OFAModelForCaption.from_pretrained(model_name_or_path) tokenizer = BertTokenizerFast.from_pretrained(model_name_or_path) # 定義圖片預處理邏輯 mean, std = [0.5, 0.5, 0.5], [0.5, 0.5, 0.5] resolution = 256 patch_resize_transform = transforms.Compose([ lambda image: image.convert("RGB"), transforms.Resize((resolution, resolution), interpolation=Image.BICUBIC), transforms.ToTensor(), transforms.Normalize(mean=mean, std=std) ]) txt = '圖片描述了什么?' inputs = tokenizer([txt], return_tensors="pt").input_ids # 加載圖片,并且預處理 img = Image.open(image_file) patch_img = patch_resize_transform(img).unsqueeze(0) # 生成caption gen = model.generate(inputs, patch_images=patch_img, num_beams=5, no_repeat_ngram_size=3) print(tokenizer.batch_decode(gen, skip_special_tokens=True))
在項目中,筆者還上傳了模型訓練、推理、權重轉(zhuǎn)化等腳本,更多細節(jié)可參考項目代碼。
03
效果展示
下列測試圖片均為從電商網(wǎng)站中隨機下載的,并且測試了不同模型權重的生成效果。
從生成效果來看,總結如下:
ofa-cn-base-muge是筆者將由官方fairseq版本的OFA-CN-Base-MUGE權重轉(zhuǎn)換而來的,其生成效果非常不錯。證明了fairseq權重轉(zhuǎn)換為transformers權重的邏輯的有效性。
ofa-cn-base-muge-v2是筆者使用ofa-cn-base進行finetune得到的,其效果遠遠優(yōu)于ofa-cn-base,并且與ofa-cn-base-muge旗鼓相當,證明了本項目的訓練邏輯的有效性。
04
結語
在本文中,筆者分享了關于中文OFA的項目實踐,實現(xiàn)了將fairseq版本的OFA權重轉(zhuǎn)換為transformers權重,并且基于MUGE數(shù)據(jù)集進行了項目驗證,在電商的Image Caption任務上取得了非常不錯的效果。
就Image Caption任務而言,借助OFA模型強大的預訓練能力,如果有足夠豐富且高質(zhì)量的域內(nèi)圖文對數(shù)據(jù),例如電商領域的<圖片,商品賣點文本>數(shù)據(jù),能夠訓練得到一個高質(zhì)量的賣點生成模型,在實際的應用場景中發(fā)揮作用。
筆者還分享了5個transformers版本的中文OFA權重,讀者可以基于該預訓練權重,在下游的多模態(tài)任務中進行finetune,相信可以取得非常不錯的效果。
審核編輯:劉清
-
OFAF
+關注
關注
0文章
2瀏覽量
2052
原文標題:OFA-Chinese:中文多模態(tài)統(tǒng)一預訓練模型
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
使用基于Transformers的API在CPU上實現(xiàn)LLM高效推理
Pytorch模型訓練實用PDF教程【中文】
分詞工具Hanlp基于感知機的中文分詞框架
以Python撰寫 AI模型框架(Framework)
用tflite接口調(diào)用tensorflow模型進行推理
EIQ onnx模型轉(zhuǎn)換為tf-lite失敗怎么解決?
如何提高YOLOv4模型的推理性能?
超大Transformer語言模型的分布式訓練框架

探究超大Transformer語言模型的分布式訓練框架
三種主流模型部署框架YOLOv8推理演示
深度學習框架區(qū)分訓練還是推理嗎
視覺深度學習遷移學習訓練框架Torchvision介紹

主流大模型推理框架盤點解析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論