 Chiplet協議UCIe標準確定
Chiplet協議UCIe標準確定
編者按
Chiplet形成標準的UCIe協議,這為多個“芯片”互聯成更大的“宏芯片”掃清了最后的障礙。當前,很多芯片的設計規模和板級多芯片協同的功能劃分,都是基于現有工藝下的面積和晶體管規模約束而形成的。當Chiplet成為主流,很多芯片的功能范疇將發生質的變化。
CPU、GPU和DPU是數據中心的三大主流芯片,相互協同也相互影響,隨著UCIe協議的確定,三者之間的界限變得模糊,未來的服務器芯片將走向何方?是走向更多核集成的平行擴展,還是把CPU、GPU和DPU的功能垂直集成到超異構計算單芯片?
接下來,我們詳細見解。
參考文獻:
1.UCIe白皮書,Universal Chiplet Interconnect Express (UCIe): Building an open chiplet ecosystem,https://www.uciexpress.org/_files/ugd/0c1418_c5970a68ab214ffc97fab16d11581449.pdf
2.https://www.eet-china.com/news/202203031041.html,英特爾、臺積電、Arm、AMD等9大廠成立“UCIe產業聯盟”,為Chiplet互聯定制新標準
3.https://mp.weixin.qq.com/s/vdaujWZY0beoprxfGKUgpA,UCIe白皮書:打造Chiplet開放生態,半導體行業觀察
1Chiplet協議UCIe標準確定
英特爾、AMD、ARM、高通、三星、臺積電、日月光等大廠,以及Google Cloud、Meta、微軟于3月2日宣布了一項新技術標準UCIe(Universal Chiplet Interconnect Express)。UCIe是一個開放的行業互連標準,可以實現小芯片之間的封裝級互連,具有高帶寬、低延遲、經濟節能的優點。
UCIe能夠滿足幾乎所有計算領域,包括云端、邊緣端、企業、5G、汽車、高性能計算和移動設備等,對算力、內存、存儲和互連不斷增長的需求。UCIe 具有封裝集成不同Die的能力,這些Die可以來自不同的晶圓廠、采用不同的設計和封裝方式。
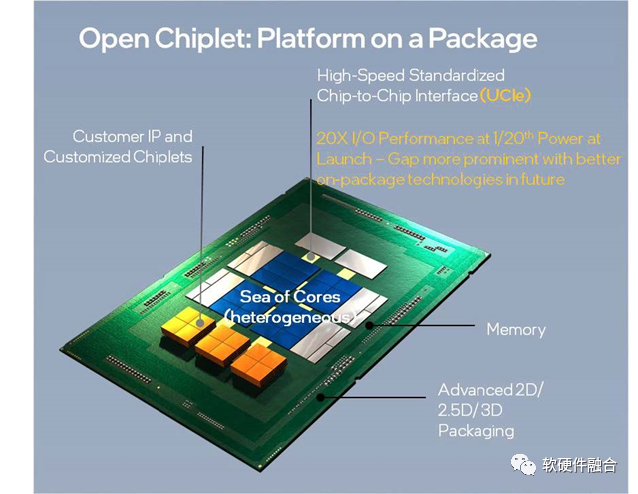
圖1 UCIe開啟開放式封裝級生態系統交付平臺
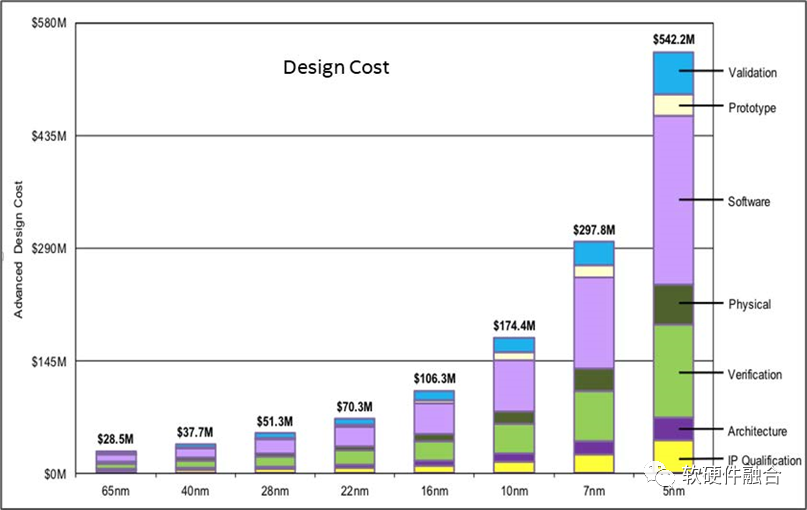
圖2 不同工藝節點的設計成本
Chiplets封裝集成的價值有很多:
首先是面積的影響。為了滿足不斷增長的性能需求,芯片面積增加,有些設計甚至會超出掩模版面積的限制。即使不超過面積限制,改用多個小芯片也更有利于提升良率。另外,多個相同Die的集成封裝能夠適用于更大規模的場景。
另一個價值體現在降低成本。例如,圖1所示的處理器核心可以采用先進的工藝,用更高的成本換取極致的性能,而內存和I/O控制器則可以復用非先進工藝。如圖 2 所示,隨著工藝節點的進步,成本增長非常迅速。若采用多Die集成模式,有些Die的功能不變,我們不必對其采用先進工藝,可在節省成本的同時快速搶占市場。Chiplet封裝集成模式還可以使用戶能夠自主選擇Die的數量和類型。例如,用戶可以根據需求挑選任意數量的計算、內存和I/O Die,并無需進行Die的定制設計,可降低產品的SKU成本。
允許廠商能夠以快速且經濟的方式提供定制解決方案。如圖1所示,不同的應用場景可能需要不同的計算加速能力,但可以使用同一種核心、內存和I/O。Chiplet方式允許廠商根據功能需求對不同的功能單元應用不同的工藝節點,并實現共同封裝。相比板級互連,封裝級互連具有線長更短、布線更緊密的優點。
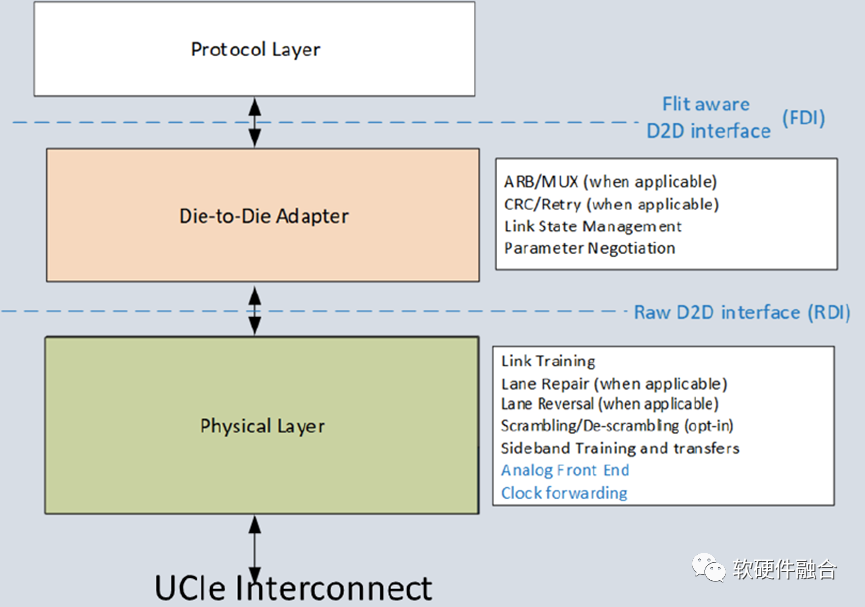
圖 UCIe分層
UCIe 是一種分層協議,分為物理層、Die-to-Die適配器和協議層,如上圖所示:
Die-to-Die適配器則為chiplet提供鏈路狀態管理和參數調整。通過CRC和鏈路級重傳機制保證數據的可靠傳輸。Die-to-Die適配器配備了底層仲裁機制用于支持多種協議,以及通過數據寬度為256字節的微片(FLIT)進行數據傳輸的底層傳輸機制。
UCIe通過在協議層本地端提供PCIe和CXL協議映射,可以將已部署成功的SoC構建、鏈路管理和安全解決方案直接遷移到UCIe。通過PCIe/CXL.io(CXL子協議,下文中的Cache.Mem和Cache.cache同屬此列)解決直接內存訪問的數據傳輸、軟件發現、錯誤處理等問題;主機內存則通過CXL.Mem訪問;對緩存有特殊要求的加速器等應用程序可以使用 CXL.cache對主機內存進行高效的緩存。UCIe 還定義了一種“流協議”,可用于映射任何其他協議。此外,隨著使用模型的發展,UCIe聯盟可以通過不斷創新來對Chiplet互連技術進行優化。
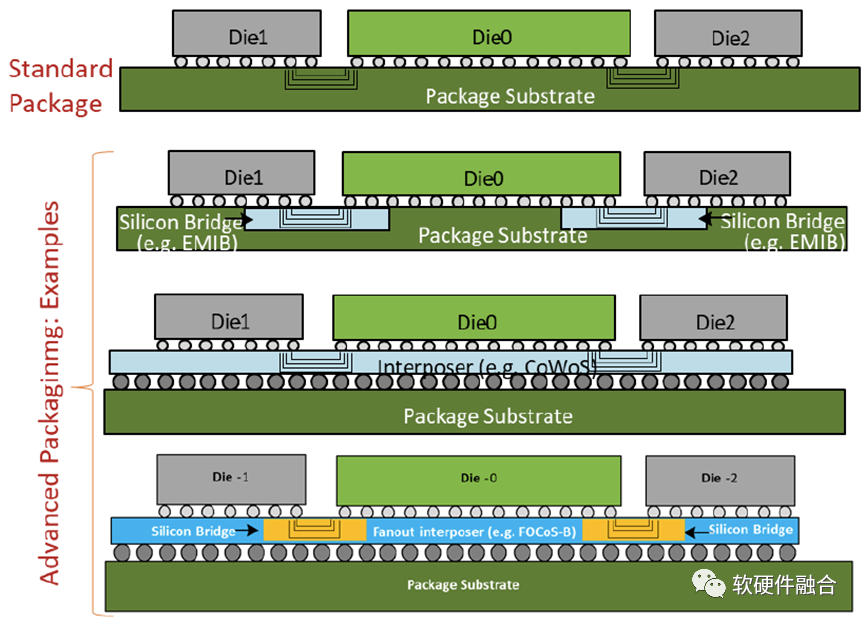
圖 封裝選項:2D或2.5D
UCIe 1.0定義了兩種類型的封裝,如上圖所示。其中標準封裝(2D)成本效益更高,而更先進的封裝(2.5D)則是為了追求同功率下更高的性能。實際設計中,有多種商用的封裝方式可供選擇,圖表中僅展示其中一部分。UCIe規范支持所有這些類型的封裝選擇。
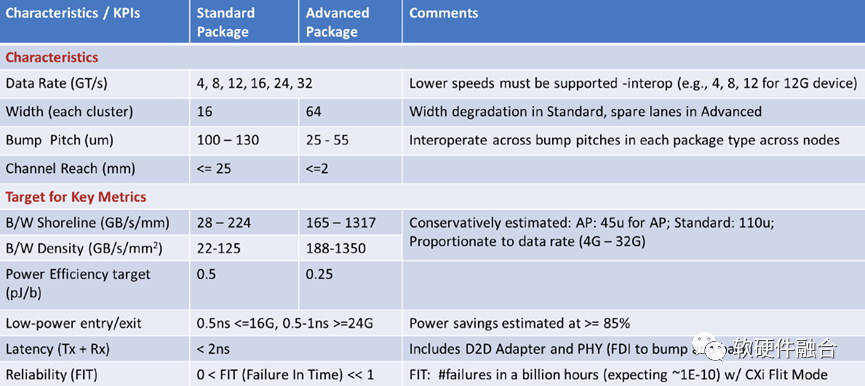
UCIe支持不同的數據傳輸速率、位寬、凸點間隔、還有通道,來保證最廣泛的可行的互用性,詳細描述如上表所示。
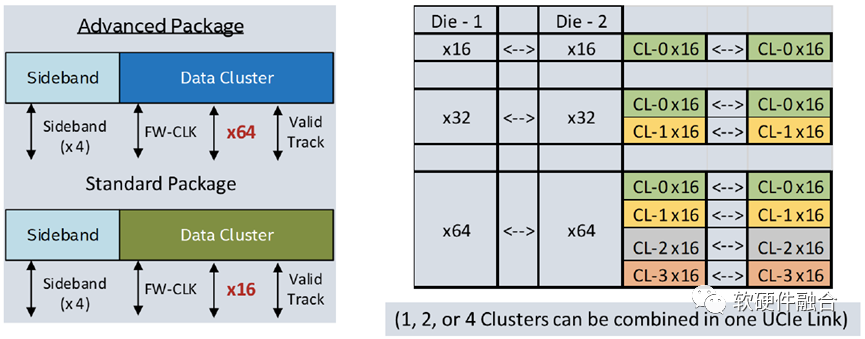
UCIe互聯的單簇的組成單元是包含了N條單端、單向、全雙工的數據線(標準封裝選項中N=16,高級封裝選項中N=64),一條單端的數據線用作有效信號,一條線用于追蹤,每個方向都有一個差分的發送時鐘,還有每個方向的兩條線用于邊帶信號(單端,一條是800MHz的時鐘,一條是數據線)。多簇的UCIe 互聯可以組合起來,在每條連接鏈路上提供更優的性能,如上圖所示。
2 CPU、GPU和DPU三國殺
我們的世界中有三顆太陽,它們在相互引力的作用下,做著無法預測的三體運動:
當我們的行星圍繞著其中的一顆太陽做穩定運行時,就是恒紀元;
當另外一顆或兩顆太陽運行到一定距離內,其引力會將行星從它圍繞的太陽邊奪走,使其在三顆太陽的引力范圍內游移不定時,就是亂紀元;
一段不確定的時間后,我們的行星再次被某一顆太陽捕獲,暫時建立穩定的軌道,恒紀元就又開始了。
劉慈欣,《三體》第一部15章
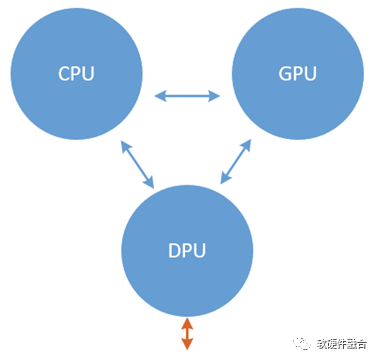
如三體一樣,CPU、GPU和DPU,既相互協作,又相互競爭。隨著Chiplet UCIe協議的確定,單芯片可以做到的設計規模突然增加了很多倍,這樣,勢必會引起CPU、GPU和DPU的功能的相互滲透甚至相互集成,直到最終形成新的穩定狀態。
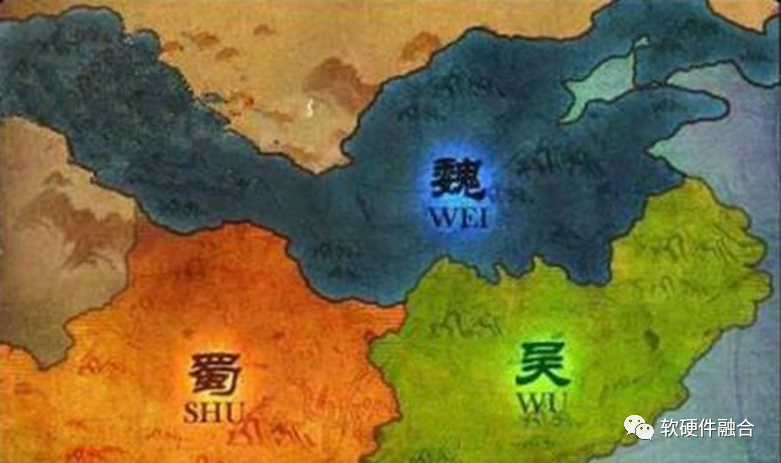
也有點像三國時代:魏蜀吳三國正在混戰,突然神奇的一幕發生,三個國家各自的人口、資源、財富都統統增加十倍,然后依靠山川、大河的天險所形成的邊界,突然都變成了平地。這個時候,兩兩之間的混戰就變得不可避免。
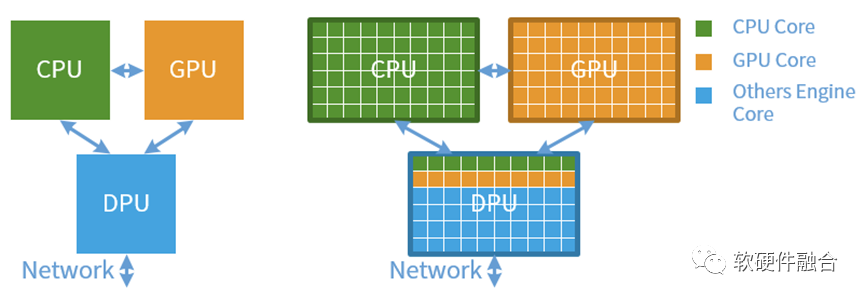
一些基本的定位分析:
獨立的DPU定位在基礎設施處理器,主要是硬件加速;
獨立的GPU主要做應用層的彈性計算加速;
而CPU主要負責低計算密度高價值密度的應用層的工作。
我們做一些假設:
一個面積單位剛剛是一個計算核;
如上圖所示:CPU有60個面積單位,共計60個CPU核;GPU有60個面積單位,共計60個GPU Core(差不多對應流式多核處理器SM);而DPU則由10個CPU核、10個GPU核以及40個其他加速引擎核組成。
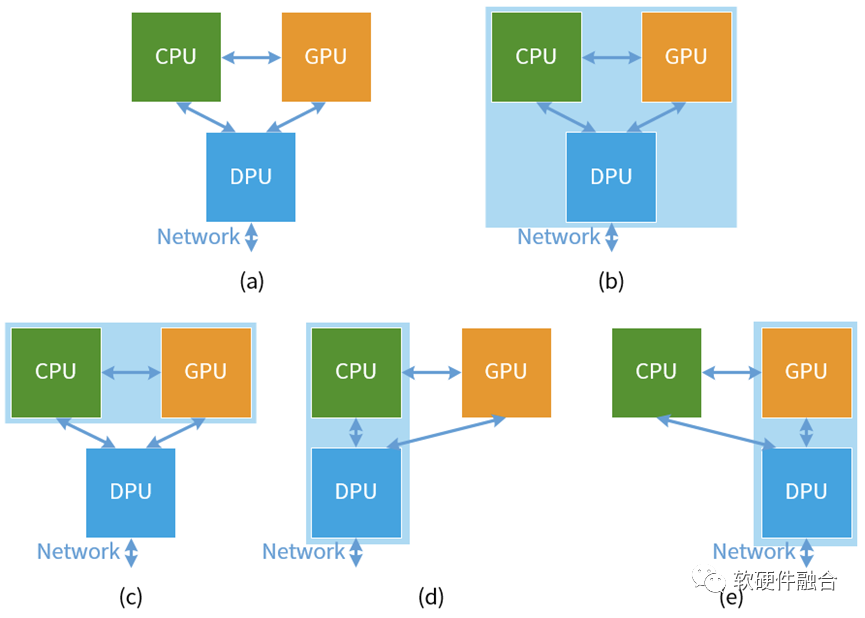
我們可以做如下分析,可以是平行擴展和垂直整合:
方向一:如上圖(a),平行擴展。CPU、GPU和DPU均平行擴展N倍。這樣,CPU則具有60*N個CPU核,GPU則具有60*N個GPU核,DPU則具有10*N個CPU核、10*N個GPU核以及40*N個其他加速引擎核。
方向二:如上圖(b),完成垂直整合。CPU+GPU+DPU合并成一個超異構的單芯片。那么這個單芯片是70個CPU核、70個GPU核以及40個其他加速處理引擎組成。
介于兩者之間的則是兩兩合并:
方向三,如上圖(c),CPU和GPU整合,獨立DPU。
方向四,如上圖(d),CPU和DPU整合,獨立GPU。
方向五,如上圖(e),GPU和DPU整合成獨立加速平臺,獨立CPU。
3 未來的趨勢:超異構計算
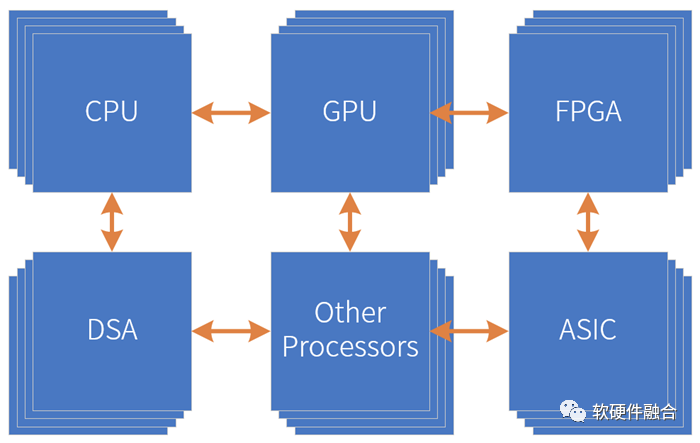
芯片工藝以及Chiplet極致帶來的資源規模越來越大,所能支撐的設計規模也越來越大,這給架構創新提供了非常堅實的基礎。我們可以采用多種處理引擎共存,“專業的人做專業的事情”,來共同協作的完成復雜系統的計算任務。并且,CPU、GPU、FPGA、一些特定的算法引擎,都可以作為IP,被集成到更大的系統中。這樣,構建一個更大規模的芯片設計成為了可能。這里,我們稱之為“超異構計算”。如上圖所示,超異構指的是由CPU、GPU、FPGA、DSA、ASIC以及其他各種形態的處理器引擎共同組成的超大規模的復雜芯片系統。
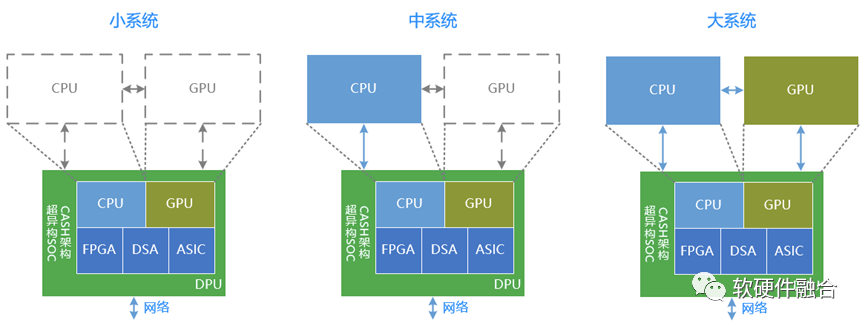
數據中心的超異構計算大致有三種類型:
DPU小系統。DPU已經明確是要整合嵌入式的CPU、GPU、FPGA、DSA以及ASIC等各種不同類型處理器引擎在一起的超異構混合計算架構的宏SOC。
CPU+DPU中系統。如果我們把芯片的界限去掉,這樣獨立CPU+DPU可以理解成:獨立CPU+嵌入式CPU+嵌入式GPU+其他嵌入式處理器引擎,依然是超異構計算架構。
CPU+GPU+CPU大系統。同樣的,無視芯片的物理界限,整個系統是由:獨立CPU+獨立GPU+嵌入式CPU + 嵌入式GPU + 嵌入式其他處理器引擎,架構依然沒有本質變化,依然是超異構計算架構。
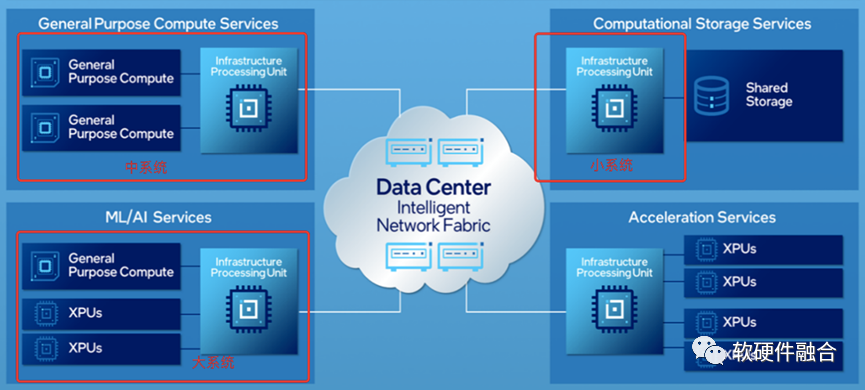
上圖是Intel對未來幾年數據中心架構的基本看法。可以看到,不管是小系統、中系統還是大系統,本質上都是超異構計算架構。
4 超異構面臨的挑戰
4.1 性能和靈活性的矛盾
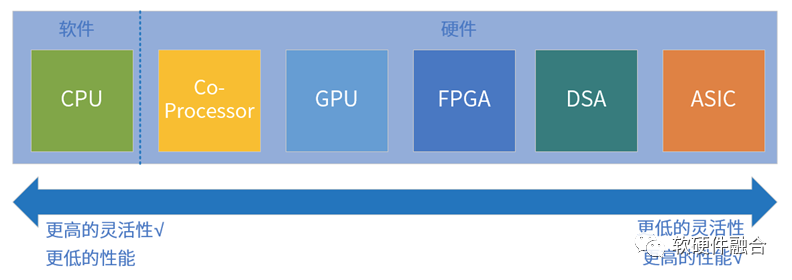
指令是軟件和硬件的媒介,指令的復雜度(單位計算密度)決定了系統的軟硬件解耦程度。按照指令的復雜度,典型的處理器平臺大致分為CPU、協處理器、GPU、FPGA、DSA、ASIC。任務在CPU運行,則定義為軟件運行;任務在協處理器、GPU、FPGA、DSA或ASIC運行,則定義為硬件加速運行。
魚和熊掌不可兼得,指令復雜度和編程靈活性是兩個互反的特征:指令越簡單,編程靈活性越高,因此我們才說軟件有更高的靈活性;指令越復雜,性能越高,因此而受到的限制越多,只能用于特定場景的應用,其軟件靈活性越差。
4.2 如何駕馭大系統
超異構計算本質上是系統芯片SOC(System on Chip),但準確的定義應該是宏系統芯片MSOC(Macro-System on Chip)。站在系統的角度,傳統SOC是單系統,而超異構宏系統,即多個系統整合到一起的大系統。
傳統的SOC,有一個基于CPU的核心控制程序,來驅動CPU、GPU、外圍其他模塊以及接口數據IO等的工作,整個系統的運行是集中式管理和控制的。量變到質變,當CPU所要控制的設備越來越多,各自之間的數據和控制交互也越來越多的時候。再加上CPU的性能已經瓶頸,這樣,作為負責控制和計算核心的CPU,就成為整個系統里最脆弱的那一個。傳統的以CPU控制為中心的架構,變得越來越無法適應以數據計算為中心的算力需求。
超異構計算,由于其規模和復雜度,每個子系統其實就是一個傳統SOC級別的系統。需要多個子系統解耦,然后再集成,整個宏系統呈現出分布式系統的特點。這樣,不同系統并行不悖的運行,以及系統間如何高效的自適應交互,就成為了挑戰。
4.3 如何構建超異構生態
CPU通過標準化的指令集,使得CPU平臺的硬件實現和軟件編程完全解耦。軟件工程師,不需要關注硬件細節,聚焦于軟件開發。軟件沒有了硬件的“約束”,逐漸發展成了一個超級生態。從各種數百萬使用者的高級編程語言/編譯器,到廣泛使用在云計算數據中心、PC機、手機等終端的操作系統以及各種系統框架/開發庫,再到各種專業的數據庫、中間件,以及云計算基礎的虛擬化、容器等。上述這些軟件都是基礎的支撐軟件,是軟件的“冰山一角”,而更多的則是各種應用級的軟件。系統級和應用級的軟件,共同組成了基于CPU的軟件超級生態。基于CPU已經構建非常龐大的生態。
基于GPGPU的并行計算編程一直是一件非常復雜的事情。但在NVIDIA的努力以及行業的變化下,GPGPU的生態逐漸發展了起來:
一方面,NVIDIA堅持多年,CUDA逐漸變得強大、穩定而易用,集成了眾多開發庫和強大的工具鏈,降低了編程的門檻;
另一方面,隨著AI等算力需求強勁的場景變得越來越多,GPU并行計算的價值凸顯,也使得GPU越來越成為AI、數據分析、HPC等場景的首先計算平臺。
以AI場景為例,AI-DSA嚴格來說,目前還沒有形成具有“統治力”的平臺和生態。開發特定“架構”的AI芯片,再配合特定的驅動,再需要有配套的AI工具鏈,把算法模型和應用“半自動,半手動”的映射到自己特定架構的AI芯片。如果算法模型發生變化。則需要重新映射,整個過程耗時甚至會超過模型更新的時間。
超異構面臨的問題,則更是難上加難。因為超異構本來就是這些處理引擎的集合。超異構可以當做是CPU+GPU+N*(DSA/ASIC)的集合,則所有單處理器引擎遇到的問題,這里都會遇到,工作量和復雜度等挑戰都成數量級的提升。
5 軟件人員輕松駕馭的算力:基于軟硬件融合的超異構計算
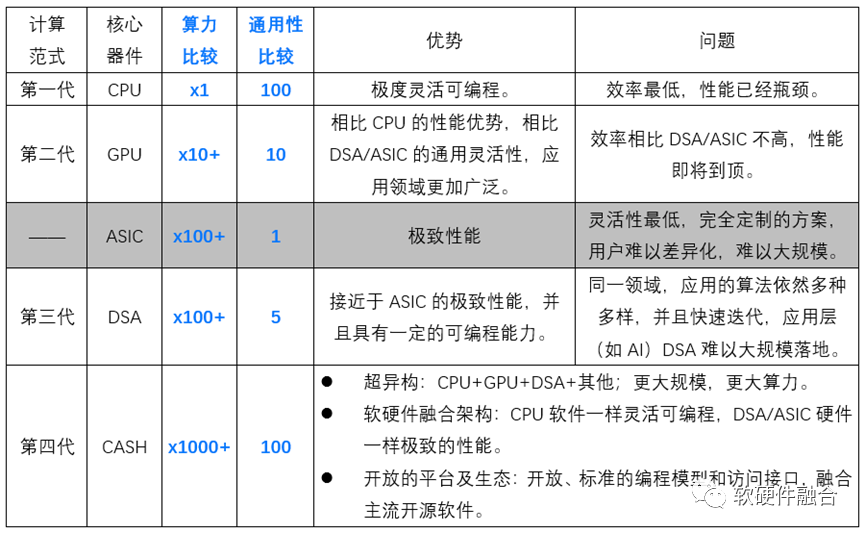
經過上述各種分析之后,我們給出面向未來十年的新一代計算架構的一些設計目標——基于軟硬件融合架構(CASH,Converged Architecture of Software and Hardware)的超異構計算:
性能。讓摩爾定律繼續,性能持續不斷地提升。相比GPGPU,性能再提升100+倍;相比DSA,性能再提升10+倍。
資源效率。實現單位晶體管資源消耗下的最極致的性能,極限接近于DSA/ASIC架構的資源效率。
靈活性。給開發者呈現出的,是極限接近于CPU的靈活性、通用性及軟件可編程性。
設計規模。通過軟硬件融合的設計理念和系統架構,駕馭10+倍并且仍持續擴大的更大規模設計。
架構。基于軟硬件融合的超異構計算:CPU + GPU + DSA + 其他各類可能的處理引擎。
生態。開放的平臺及生態,開放、標準的編程模型和訪問接口,融合主流開源軟件。
與CPU芯片、GPU芯片、DSA芯片的比較如下表:
責任編輯:lq
-
處理器
+關注
關注
68文章
19830瀏覽量
233875 -
cpu
+關注
關注
68文章
11052瀏覽量
216242 -
UCIe
+關注
關注
0文章
49瀏覽量
1810
原文標題:Chiplet UCIe協議已定,CPU、GPU、DPU混戰開啟,未來路在何方?
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
技術資訊 I 完整的 UCIe 信號完整性分析流程和異構集成合規性檢查

倍加福激光測距傳感器實現起重機準確定位
新思科技與英特爾攜手完成UCIe互操作性測試
乾瞻科技UCIe IP設計定案,實現高速傳輸技術突破
乾瞻科技宣布最新UCIe IP設計定案,推動高速傳輸技術突破
解鎖Chiplet潛力:封裝技術是關鍵

PCIe 6.0 互操作性PHY驗證測試方案
晟聯科UCIe+SerDes方案塑造高性能計算(HPC)新未來
奇異摩爾32GT/s Kiwi Link Die-to-Die IP全面上市

最新Chiplet互聯案例解析 UCIe 2.0最新標準解讀

UCIe規范引領Chiplet技術革新,新思科技發布40G UCIe IP解決方案
IMEC組建汽車Chiplet聯盟

新思科技發布40G UCIe IP,加速多芯片系統設計
Alphawave推出業界首款支持臺積電CoWoS封裝的3nm UCIe IP
是德科技推出PCIe和UCIe仿真解決方案





 工商網監
工商網監
評論