 Flex Logix InferX X1M邊緣推理加速器
Flex Logix InferX X1M邊緣推理加速器
每種類型的邊緣 AI 都有三個硬性和快速的技術要求:低功耗、小尺寸和高性能。當然,“小型”、“節能”或“高性能”的構成因用例而異,可以描述從小型微控制器到邊緣服務器的所有內容,但通常您必須至少犧牲一個才能獲得其他。
但是,一種可以解決從邊緣云到端點的所有問題而無需犧牲的解決方案是 FPGA。
幾十年來,FPGA 一直用于提供低功耗、高性能的設計靈活性,無論應用程序或外形尺寸如何,但它們并不完全是用戶友好的——復雜的 AI 模型和算法的不斷發展加劇了這一事實。然而,在有挑戰的地方通常也有機會,對于工業自動化、智慧城市、交通、醫療保健、農業和其他市場中的邊緣人工智能用例,以及其他快速采用計算機視覺等功能的市場,機會以FlexLogix X1M 人工智能加速器。
Flex Logix X1M AI 加速器針對實時、高分辨率計算機視覺用例,這些用例運行基于 Yolov3、Yolov4 和 Yolov5 等模型的小批量深度學習工作負載。為了以比 NVIDIA Tesla T4、Xavier NX 或 Jetson TX2 等設備更高的每美元吞吐量提供視覺邊緣推理,新的 X1M M.2 模塊利用 Flex Logix 的 InferX X1 架構,將 4K INT8 MAC 內核組合成 64 個8 MB SRAM 和 4 GB 16 MTps LPDDR4X DRAM 支持 x 64 張量處理器陣列。
鑒于板載內存,X1M AI 加速器本身支持 PCI Express Gen 3 或 4 的 x2 通道作為主機總線協議。PCIe 支持不僅促進了張量陣列與內存和存儲中的數據或模型之間的高速數據傳輸,還能夠符合 M.2 2280 B+M 關鍵外形規格規格,尺寸為 22 mm (W) x 80 毫米(長)x 17 毫米深(包括散熱器)。
X1M AI 加速器的大小與口香糖差不多,消耗的功率也比時鐘收音機多一點,它真正占據了技術功率-性能尺寸維恩圖的中心。
InferX X1M 邊緣推理加速器正在運行
該平臺的張量陣列使其能夠處理具有數百層、數十個并行通道和多種算子類型的深度神經網絡,與 GPU 不同,它可以應用于批量小至 1 的百萬像素圖像。
盡管展示了 ASIC 的性能特征,但 InferX X1M 擁有 FPGA 獨有的能力。其中包括可重新配置的數據路徑,允許設備硬件適應新的和不同的模型技術,即使在現場部署之后也是如此。從本質上講,這使這些設備能夠面向未來。
重要的是,用戶無需了解硬件開發語言或手動重新編程 FPGA 比特流即可訪問這些功能以及控制邏輯等其他功能。這要歸功于為用戶提供對低級平臺控制功能和監控功能的內部訪問以及可用于應用程序配置或模型部署的外部訪問的 API。
此外,開放神經網絡交換 (ONNX) 格式的兼容性允許 InferX X1M 工具以最佳方式自動將框架中表示的任何模型映射到 X1 加速器。
該解決方案支持在 Windows 和 Linux 操作環境中進行開發。
Flex Logix InferX X1M 加速器入門
除了上面列出的好處之外,InferX X1M 加速器的最大優勢可能在于它使邊緣 AI 和計算機視覺 OEM 和系統集成商不必設計自己的定制板。這些 M.2 模塊設計用于在 0oC 至 50oC 的溫度范圍和 10% 至 90% 的相對非冷凝濕度范圍內可靠地運行,所有這些都具有競爭力的成本。
審核編輯:郭婷
-
asic
+關注
關注
34文章
1242瀏覽量
121978 -
神經網絡
+關注
關注
42文章
4807瀏覽量
102755 -
AI
+關注
關注
87文章
34173瀏覽量
275333
發布評論請先 登錄
MAX7800X AI 微控制器開發人員資源

【幸狐Omni3576邊緣計算套件試用體驗】RKNN 推理測試與圖像識別
小型加速器中子源監測系統解決方案

AN207 GD32G5x3三角函數加速器TMU的使用說明

EE-436:使用ADSP-SC59x/2159x高性能FIR/IIR加速器
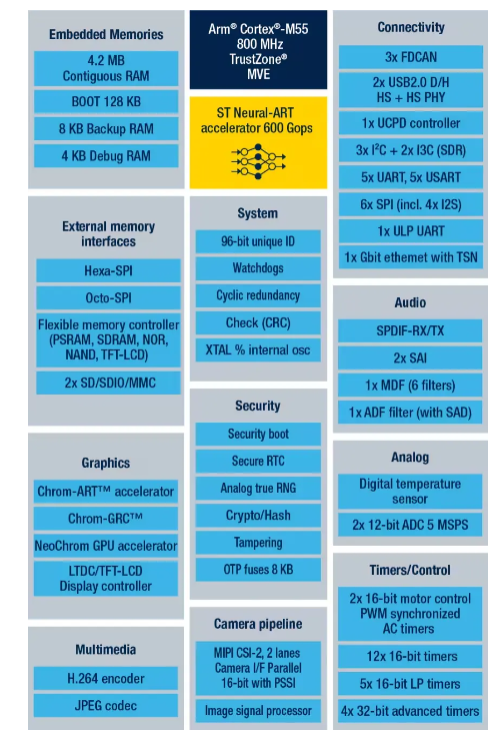
STM32N647X0 高性能 Arm Cortex-M55 MCU、800MHz、4.2MB SRAM、Neural-ART 加速器 600 GOPS、NeoChrom GPU

IBM與AMD攜手部署MI300X加速器,強化AI與HPC能力
IBM將在云平臺部署AMD加速器
IBM與AMD攜手將在IBM云上部署AMD Instinct MI300X加速器
ADI收購Flex Logix,強化數字產品組合
今日看點丨ADI收購eFPGA公司Flex Logix;業界首款!湖北發布高性能車規級芯片DF30
AMD助力HyperAccel開發全新AI推理服務器






 工商網監
工商網監
評論