 AMD助力HyperAccel開發全新AI推理服務器
AMD助力HyperAccel開發全新AI推理服務器
HyperAccel 是一家成立于 2023 年 1 月的韓國初創企業,致力于開發 AI 推理專用型半導體器件和硬件,最大限度提升推理工作負載的存儲器帶寬使用,并通過將此解決方案應用于大型語言模型來提高成本效率。HyperAccel 針對新興的生成式 AI 應用提供超級加速的芯片 IP/解決方案。HyperAccel 已經打造出一個快速、高效且低成本的推理系統,加速了基于轉換器的大型語言模型( LLM )的推理,此類模型通常具有數十億個參數,例如 OpenAI 的 ChatGPT 和 Meta 的 Llama 3 等 Llama LLM。其 AI 芯片名為時延處理單元( LPU ),是專門用于 LLM 端到端推理的硬件加速器。
項目挑戰
隨著 LLM 應用的擴展,對高效、快速和具成本效益的推理解決方案的需求不斷上升。對于云服務提供商而言,快速且成本效益高的推理硬件對于托管高性能的生成式 AI 應用并降低總擁有成本( TCO )至關重要。對于 AI 企業來說,一個直觀的軟件堆棧平臺是實現其應用或模型無縫部署的必備條件。對于服務業務,提供全面的端到端解決方案也是必要的,有利于將最先進的 AI 技術集成到更有效和先進的服務中。
解決方案
HyperAccel 提出通過開發名為“Orion”的服務器來解決成本和性能問題,該服務器搭載了一個為 LLM 推理量身定制的專用處理器,基于多個高性能 AMD FPGA部署。Orion 充分利用每個 FPGA 的存儲器帶寬和硬件資源以獲得最高水平的性能。這種可擴展的架構支持最新的 LLM,此類模型通常包含數十億個參數。
Orion 擁有 16 個時延處理單元( LPU ),它們分布在兩個 2U 機架中,提供總共 7.36TB/s 的 HBM 帶寬和 14.4 萬個 DSP。LPU 能加速內存和計算都非常密集的超大規模生成式 AI 工作負載。Orion 及其 256GB 的 HBM 容量支持多達千億參數的最先進 LLM。上圖展示了兩個 2U 機箱之一,配有 8 個 LPU。
下圖顯示了 LPU 架構,其中矢量執行引擎由 AMD Alveo U55C 高性能計算卡支持。Alveo U55C 卡具有高帶寬存儲器( HBM2 ),解決了提供低時延AI 的最關鍵性能瓶頸——存儲器帶寬。此外,它們能夠將 200 Gbps的高速網絡集成到單個小型板卡中,并且經過精心設計可在任何服務器中部署。
反過來,每個 Alveo 加速卡都由 FPGA 架構驅動。鑒于 FPGA 的大規模硬件并行性和靈活應變的存儲器層次結構,FPGA 固有的低時延特性非常適合 LLM 所需的實時 AI 服務。Alveo 卡采用了強大的 Virtex XCU55P UltraScale+ FPGA,可提供高達 38 TOPS 的 DSP 計算性能,有助于 AI 推理優化,包括用于定點與浮點計算的 INT8。這款 FPGA 能夠根據客戶反饋調整其處理器( LPU )的架構,例如,根據要求在Llama模型中實現一些非標準的處理,進而提供靈活的解決方案,能夠適應不斷變化的市場和 LLM 參數條件。
設計成效
Orion 的高性能和可擴展性是通過 LPU 實現的,由 AMD Alveo 加速卡和相關的 FPGA 以及HyperAccel 的可擴展同步鏈路( ESL )技術提供支持。這些技術最大限度提升了 P2P 傳輸中的存儲器帶寬使用,有利于靈活處理,同時消除了 P2P 計算的同步開銷 ESL 屬于為 LLM 推理中的數據傳輸優化的通信鏈路。值得注意的是,Orion 在支持標準 FP16 數據精度的硬件上保持了卓越的準確性。
HyperAccel Orion
的性能
針對時延進行優化的 HyperAccel Orion 與基于轉換器的 LLM(如 GPT、Llama 和 OPT)無縫集成,能夠在 1.3B 模型上每秒生成超過 520 個令牌,在 7B 模型上每秒生成 175 個令牌。除了卓越的性能外,Orion 還展示了出色的能源效率,在 66B 模型上生成單個令牌只需 24 毫秒,而功耗僅為 600W。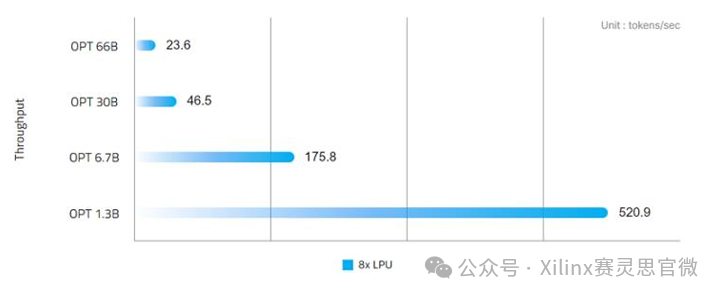
HyperAccel LPU 的性能(來源:https://www.hyperaccel.ai)
HyperAccel Orion
—— 工作負載多樣性
Orion 提供端到端的解決方案服務,可作為云端服務部署。對于擁有專有 LLM 的AI 企業或存在內部數據隱私與安全需求的專業部門,Orion 也能夠以本地解決方案的形式進行安裝。Orion 能夠處理以下工作負載/應用:
客戶服務:通過虛擬聊天機器人和虛擬助手實時處理查詢,因此人工客服將有時間處理更復雜的問題。
人機界面:在自助服務終端、機器人和其它設備中支持與語言相關的功能,以增強客戶互動體驗。
文本生成:協助生產、總結和精煉復雜的文本內容,為用戶提供便利。
語言翻譯:翻譯客戶查詢和回復信息,打破語言障礙,擴大企業的全球影響力。
問答:根據大量數據以及此前的互動和偏好記錄,定制針對個別客戶的回復,以提高客戶滿意度。
進一步了解AMD Virtex UltraScale+ FPGA和Alveo U55C 加速卡,請訪問產品專區。
-
FPGA
+關注
關注
1643文章
21967瀏覽量
614268 -
amd
+關注
關注
25文章
5565瀏覽量
135907 -
服務器
+關注
關注
13文章
9699瀏覽量
87308 -
AI
+關注
關注
87文章
34274瀏覽量
275461
原文標題:HyperAccel 借助 AMD 加速卡與 FPGA 打造全新 AI 推理服務器
文章出處:【微信號:賽靈思,微信公眾號:Xilinx賽靈思官微】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
RAKsmart服務器如何助力企業破解AI轉型的難題
基于RAKsmart云服務器的AI大模型實時推理方案設計
RAKsmart服務器如何賦能AI開發與部署
AI 推理服務器都有什么?2025年服務器品牌排行TOP10與選購技巧

RAKsmart服務器如何重塑AI高并發算力格局
國產推理服務器如何選擇?深度解析選型指南與華頡科技實戰案例

NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺







 工商網監
工商網監
評論