 開發或者運維中的性能優化建議
開發或者運維中的性能優化建議
寫到這里,本書已經快接近尾聲了。在本書前面幾章的內容里,我們深入地討論了很多內核網絡模塊相關的問題。正和庖丁一樣,從今日往后我們看到的也不再是整個的 Linux (整頭牛)了,而是內核的內部各個模塊(筋?肌理)。我們也理解了內核各個模塊是如何有機協作來幫我們完成任務的。
那么具備了這些深刻的理解之后,我們在性能方面有哪些優化手段可用呢?我在本章中給出一些開發或者運維中的性能優化建議。注意,我用的字眼是建議,而不是原則之類的。每一種性能優化方法都有它適用或者不適用的應用場景。你應當根據你當前的項目現狀靈活來選擇用或者不用。
1 網絡請求優化
建議1:盡量減少不必要的網絡 IO
我要給出的第一個建議就是不必要用網絡 IO 的盡量不用。
是的,網絡在現代的互聯網世界里承載了很重要的角色。用戶通過網絡請求線上服務、服務器通過網絡讀取數據庫中數據,通過網絡構建能力無比強大分布式系統。網絡很好,能降低模塊的開發難度,也能用它搭建出更強大的系統。但是這不是你濫用它的理由!
我曾經見過有的同學在自己開發的接口里要請求幾個第三方的服務。這些服務提供了一個 C 或者 Java 語言的SDK,說是 SDK 其實就是簡單的一次 UPD 或者 TCP 請求的封裝而已。這個同學呢,不熟悉 C 和 Java 語言的代碼,為了省事就直接在本機上把這些 SDK 部署上來,然后自己再通過本機網絡 IO 調用這些 SDK。我們接手這個項目以后,分析了一下這幾個 SDK 的實現,其實調用和協議解析都很簡單。我們在自己的服務進程里實現了一遍,干掉了這些本機網絡 IO 。效果是該項目 CPU 整體核數削減了 20 % +。另外除了性能以外,項目的部署難度,可維護性也都得到了極大的提升。
原因我們在本書第 5 章的內容里說過,即使是本機網絡 IO 開銷仍然是很大的。先說發送一個網絡包,首先得從用戶態切換到內核態,花費一次系統調用的開銷。進入到內核以后,又得經過冗長的協議棧,這會花費不少的 CPU周期,最后進入環回設備的“驅動程序”。接收端呢,軟中斷花費不少的 CPU 周期又得經過接收協議棧的處理,最后喚醒或者通知用戶進程來處理。當服務端處理完以后,還得把結果再發過來。又得來這么一遍,最后你的進程才能收到結果。你說麻煩不麻煩。另外還有個問題就是多個進程協作來完成一項工作就必然會引入更多的進程上下文切
換開銷,這些開銷從開發視角來看,做的其實都是無用功。
上面我們還分析的只是本機網絡 IO,如果是跨機器的還得會有雙方網卡的 DMA 拷貝過程,以及兩端之間的網絡RTT 耗時延遲。所以,網絡雖好,但也不能隨意濫用!
建議2:盡量合并網絡請求
在可能的情況下,盡可能地把多次的網絡請求合并到一次,這樣既節約了雙端的 CPU 開銷,也能降低多次 RTT 導致的耗時。
我們舉個實踐中的例子可能更好理解。假如有一個 redis,里面存了每一個 App 的信息(應用名、包名、版本、截圖等等)。你現在需要根據用戶安裝應用列表來查詢數據庫中有哪些應用比用戶的版本更新,如果有則提醒用戶更新。
那么最好不要寫出如下的代碼:
get(包名)...}
上面這段代碼功能上實現上沒問題,問題在于性能。據我們統計現代用戶平均安裝 App 的數量在 60 個左右。那這段代碼在運行的時候,每當用戶來請求一次,你的服務器就需要和 redis 進行 60 次網絡請求。總耗時最少是 60個 RTT 起。更好的方法是應該使用 redis 中提供的批量獲取命令,如 hmget、pipeline等,經過一次網絡 IO 就獲取到所有想要的數據,如圖 1.1。
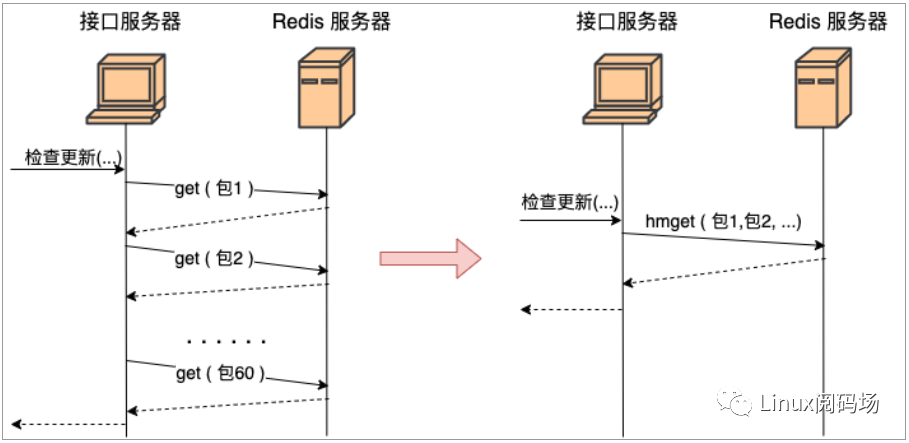
圖1.1 網絡請求合并
建議3:調用者與被調用機器盡可能部署的近一些
在前面的章節中我們看到在握手一切正常的情況下, TCP 握手的時間基本取決于兩臺機器之間的 RTT 耗時。雖然我們沒辦法徹底去掉這個耗時,但是我們卻有辦法把 RTT 降低,那就是把客戶端和服務器放的足夠地近一些。盡量把每個機房內部的數據請求都在本地機房解決,減少跨地網絡傳輸。
舉例,假如你的服務是部署在北京機房的,你調用的 mysql、redis最好都位于北京機房內部。盡量不要跨過千里萬里跑到廣東機房去請求數據,即使你有專線,耗時也會大大增加!在機房內部的服務器之間的 RTT 延遲大概只有零點幾毫秒,同地區的不同機房之間大約是 1 ms 多一些。但如果從北京跨到廣東的話,延遲將是 30 - 40 ms 左右,幾十倍的上漲!
建議4:內網調用不要用外網域名
假如說你所在負責的服務需要調用兄弟部門的一個搜索接口,假設接口是:"http://www.sogou.com/wq?key=開發內功修煉"。
那既然是兄弟部門,那很可能這個接口和你的服務是部署在一個機房的。即使沒有部署在一個機房,一般也是有專線可達的。所以不要直接請求 www.sogou.com, 而是應該使用該服務在公司對應的內網域名。在我們公司內部,每一個外網服務都會配置一個對應的內網域名,我相信你們公司也有。
為什么要這么做,原因有以下幾點
1)外網接口慢。本來內網可能過個交換機就能達到兄弟部門的機器,非得上外網兜一圈再回來,時間上肯定會慢。
2)帶寬成本高。在互聯網服務里,除了機器以外,另外一塊很大的成本就是 IDC 機房的出入口帶寬成本。兩臺機器在內網不管如何通信都不涉及到帶寬的計算。但是一旦你去外網兜了一圈回來,行了,一進一出全部要繳帶寬費,你說虧不虧!!
3)NAT 單點瓶頸。一般的服務器都沒有外網 IP,所以要想請求外網的資源,必須要經過 NAT 服務器。但是一個公司的機房里幾千臺服務器中,承擔 NAT 角色的可能就那么幾臺。它很容易成為瓶頸。我們的業務就遇到過好幾次 NAT 故障導致外網請求失敗的情形。NAT 機器掛了,你的服務可能也就掛了,故障率大大增加。
2 接收過程優化
建議1:調整網卡 RingBuffer 大小
當網線中的數據幀到達網卡后,第一站就是 RingBu??er。網卡在 RingBuffer 中尋找可用的內存位置,找到后 DMA引擎會把數據 DMA 到 RingBuffer 內存里。因此我們第一個要監控和調優的就是網卡的 RingBuffer,我們使用ethtool 來來查看一下 Ringbuffer 的大小。
#ethtool-geth0Ringparametersforeth0:Pre-setmaximums:RX:4096RXMini:0RXJumbo:0TX:4096Currenthardwaresettings:RX:512RXMini:0RXJumbo:0TX: 512
這里看到我手頭的網卡設置 RingBuffer 最大允許設置到 4096 ,目前的實際設置是 512。
這里有一個小細節,ethtool查看到的是實際是Rx bd的大小。Rx bd位于網卡中,相當于一個指針。
RingBu??er在內存中,Rx bd指向RingBuffer。Rx bd和RingBuffer中的元素是一一對應的關系。在網卡啟
動的時候,內核會為網卡的Rx bd在內存中分配RingBu??er,并設置好對應關系。
在 Linux 的整個網絡棧中,RingBuffer 起到一個任務的收發中轉站的角色。對于接收過程來講,網卡負責往RingBuffer 中寫入收到的數據幀,ksoftirqd 內核線程負責從中取走處理。只要 ksoftirqd 線程工作的足夠快,RingBuffer 這個中轉站就不會出現問題。但是我們設想一下,假如某一時刻,瞬間來了特別多的包,而 ksoftirqd處理不過來了,會發生什么?這時 RingBuffer 可能瞬間就被填滿了,后面再來的包網卡直接就會丟棄,不做任何處理!
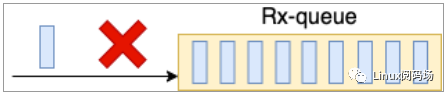
圖2.1RingBuffer 溢出
那我們怎么樣能看一下,我們的服務器上是否有因為這個原因導致的丟包呢?前面我們介紹的四個工具都可以查看
這個丟包統計,拿 ethtool 來舉例:
#ethtool-Seth0......rx_fifo_errors:0tx_fifo_errors: 0
rx_fifo_errors 如果不為 0 的話(在 ifconfig 中體現為 overruns 指標增長),就表示有包因為 RingBuffer 裝不下而被丟棄了。那么怎么解決這個問題呢?很自然首先我們想到的是,加大 RingBuffer 這個“中轉倉庫”的大小,如圖2.2通過 ethtool 就可以修改。
# ethtool -G eth1 rx 4096 tx 4096

圖2.2RingBuffer 擴容
這樣網卡會被分配更大一點的”中轉站“,可以解決偶發的瞬時的丟包。不過這種方法有個小副作用,那就是排隊的包過多會增加處理網絡包的延時。所以應該讓內核處理網絡包的速度更快一些更好,而不是讓網絡包傻傻地在RingBuffer 中排隊。我們后面會再介紹到 RSS ,它可以讓更多的核來參與網絡包接收。
建議2:多隊列網卡 RSS 調優
硬中斷的情況可以通過內核提供的偽文件 /proc/interrupts 來進行查看。拿飛哥手頭的一臺虛機來舉例:
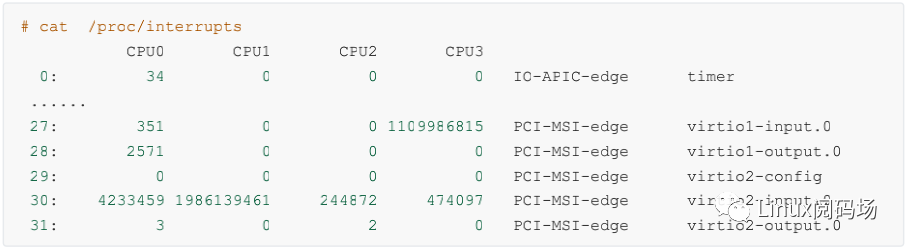
上述結果是我手頭的一臺虛機的輸出結果。上面包含了非常豐富的信息。網卡的輸入隊列 virtio1-input.0 的中斷號是 27,總的中斷次數是 1109986815,并且 27 號中斷都是由 CPU3 來處理的。
那么為什么這個輸入隊列的中斷都在 CPU3 上呢?這是因為內核的一個中斷親和性配置,在我機器的偽文件系統中可以查看到。
#cat/proc/irq/27/smp_affinity8
smp_affinity 里是CPU的親和性的綁定,8 是二進制的 1000, 第4位為 1。代表的就是當前的第 27 號中斷的都由第 4 個 CPU 核心 - CPU3 來處理。
現在的主流網卡基本上都是支持多隊列的。通過 ethtool 工具可以查看網卡的隊列情況。
#ethtool-leth0Channelparametersforeth0:Pre-setmaximums:RX:0TX:0Other:1Combined:63Currenthardwaresettings:RX:0TX:0Other:1Combined: 8
上述結果表示當前網卡支持的最大隊列數是 63 ,當前開啟的隊列數是 8 。這樣當有數據到達的時候,可以將接收進來的包分散到多個隊列里。另外每一個隊列都有自己的中斷號。比如我手頭另外一臺多隊列的機器上看到結果(為了方便展示我刪除了部分不相關內容):
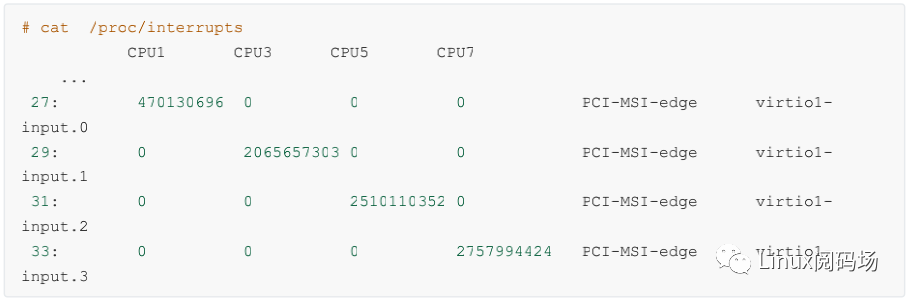
這臺機器上 virtio 這塊虛擬網卡上有四個輸入隊列,其硬中斷號分別是 27、29、31 和 33。有獨立的中斷號就可以獨立向某個 CPU 核心發起硬中斷請求,讓對應 CPU 來 poll 包。中斷和 CPU 的對應關系還是通過 cat/proc/irq/{中斷號}/smp_affinity 來查看。通過將不同隊列的 CPU 親和性打散到多個 CPU 核上,就可以讓多核同時并行處理接收到的包了。這個特性叫做 RSS(Receive Side Scaling,接收端擴展),如圖 2.3。這是加快 Linux內核處理網絡包的速度非常有用的一個優化手段。
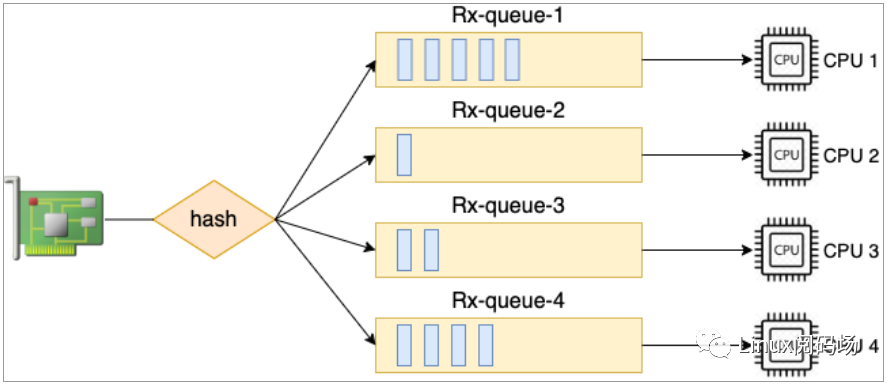
圖2.3多隊列網卡
在網卡支持多隊列的服務器上,想提高內核收包的能力,直接簡單加大隊列數就可以了,這比加大 RingBuffer 更為有用。因為加大 RingBuffer 只是給個更大的空間讓網絡幀能繼續排隊,而加大隊列數則能讓包更早地被內核處理。ethtool 修改隊列數量方法如下:
#ethtool -L eth0 combined 32
不過在一般情況下,由一個叫隊列中斷號和 CPU 之間的親和性并不需要手工維護,有一個 irqbalance的服務來自動管理。通過 ps 命令可以查看到這個進程。
#ps-ef|grepirqbroot 29805 1 0 18:57 ? 0000 /usr/sbin/irqbalance --foreground
Irqbalance 會根據系統中斷負載的情況,自動維護和遷移各個中斷的 CPU 親和性,以保持各個 CPU 之間的中斷開銷均衡。如果有必要,irqbalance 也會自動把中斷從一個 CPU 遷移到另一個 CPU 上。如果確實想自己維護親和性,那得先關掉 irqbalance,然后再修改中斷號對應的 smp_affinity。
#serviceirqbalancestop# echo 2 > /proc/irq/30/smp_affinity
建議3:硬中斷合并
在第 1 章中我們看到,當網絡包接收到 RingBuffer 后,接下來通過硬中斷通知 CPU。那么你覺得從整體效率上來講,是有包到達就發起中斷好呢,還是攢一些數據包再通知 CPU 更好。
先允許我來引用一個實際工作中的例子,假如你是一位開發同學,和你對口的產品經理一天有10 個小需求需要讓你幫忙來處理。她對你有兩種中斷方式:
第一種:產品經理想到一個需求,就過來找你,和你描述需求細節,然后讓你幫你來改。
第二種:產品經理想到需求后,不來打擾你,等攢夠 5 個來找你一次,你集中處理。
我們現在不考慮及時性,只考慮你的工作整體效率,你覺得那種方案下你的工作效率會高呢?或者換句話說,你更喜歡哪一種工作狀態呢?只要你真的有過工作經驗,一定都會覺得第二種方案更好。對人腦來講,頻繁的中斷會打亂你的計劃,你腦子里剛才剛想到一半技術方案可能也就廢了。當產品經理走了以后,你再想撿起來剛被中斷之的工作的時候,很可能得花點時間回憶一會兒才能繼續工作。
對于CPU來講也是一樣,CPU要做一件新的事情之前,要加載該進程的地址空間,load進程代碼,讀取進程數據,各級別 cache 要慢慢熱身。因此如果能適當降低中斷的頻率,多攢幾個包一起發出中斷,對提升 CPU 的整體工作效率是有幫助的。所以,網卡允許我們對硬中斷進行合并。
現在我們來看一下網卡的硬中斷合并配置。
#ethtool-ceth0Coalesceparametersforeth0:AdaptiveRX:offTX:off......rx-usecs:1rx-frames:0rx-usecs-irq:0rx-frames-irq:0......
我們來說一下上述結果的大致含義
Adaptive RX::自適應中斷合并,網卡驅動自己判斷啥時候該合并啥時候不合并
rx-usecs:當過這么長時間過后,一個 RX interrupt 就會被產生
rx-frames:當累計接收到這么多個幀后,一個 RX interrupt 就會被產生
如果你想好了修改其中的某一個參數了的話,直接使用 ethtool -C 就可以,例如:
# ethtool -C eth0 adaptive-rx on
不過需要注意的是,減少中斷數量雖然能使得 Linux 整體網絡包吞吐更高,不過一些包的延遲也會增大,所以用的時候得適當注意。
建議4:軟中斷 budget 調整
再舉個日常工作相關的例子,不知道你有沒有聽說過番茄工作法這種高效工作方法。它的大致意思就是你在工作的時候,要有一整段的不被打擾的時間,集中精力處理某一項工作。這一整段時間時長被建議是 25 分鐘。對于我們的Linux的處理軟中斷的 ksoftirqd 來說,它也和番茄工作法思路類似。一旦它被硬中斷觸發開始了工作,它會集中精力處理一波兒網絡包(絕不只是1個),然后再去做別的事情。
我們說的處理一波兒是多少呢,策略略復雜。我們只說其中一個比較容易理解的,那就是net.core.netdev_budget 內核參數。
#sysctl-a|grepnet.core.netdev_budget = 300
這個的意思說的是,ksoftirqd 一次最多處理300個包,處理夠了就會把 CPU 主動讓出來,以便 Linux 上其它的任務可以得到處理。那么假如說,我們現在就是想提高內核處理網絡包的效率。那就可以讓 ksoftirqd 進程多干一會兒網絡包的接收,再讓出 CPU。至于怎么提高,直接修改這個參數的值就好了。
#sysctl -w net.core.netdev_budget=600
如果要保證重啟仍然生效,需要將這個配置寫到/etc/sysctl.conf
建議5:接收處理合并
硬中斷合并是指的攢一堆數據包后再通知一次 CPU,不過數據包仍然是分開的。Lro(Large Receive Offload) /Gro(Generic Receive Offload) 還能把數據包合并起來后再往上層傳遞。
如果應用中是大文件的傳輸,大部分包都是一段數據,不用 LRO / GRO 的話,會每次都將一個小包傳送到協議棧(IP接收函數、TCP接收)函數中進行處理。開啟了的話,內核或者網卡會進行包的合并,之后將一個大包傳給協議處理函數,如圖 2.4。這樣 CPU 的效率也就提高了。
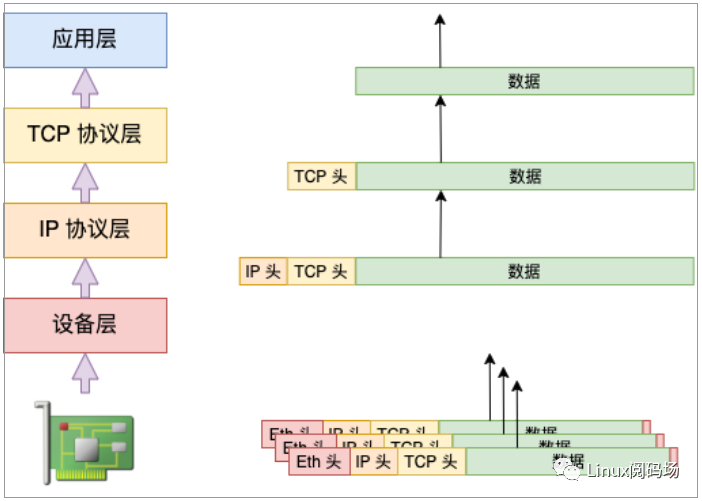
圖2.4 接收處理合并
Lro 和 Gro 的區別是合并包的位置不同。Lro 是在網卡上就把合并的事情給做了,因此要求網卡硬件必須支持才行。而 Gso 是在內核源碼中用軟件的方式實現的,更加通用,不依賴硬件。
那么如何查看你的系統內是否打開了 LRO / GRO 呢?
#ethtool-keth0generic-receive-offload:onlarge-receive-offload:on...
如果你的網卡驅動沒有打開 GRO 的話,可以通過如下方式打開。
#ethtool-Keth0groon# ethtool -K eth0 lro on
3 發送過程優化
建議1:控制數據包大小
在第四章中我們看到,在發送協議棧執行的過程中到了 IP 層如果要發送的數據大于 MTU 的話,會被分片。這個分片會有哪些影響呢?首先就是在分片的過程中我們看到多了一次的內存拷貝。其次就是分片越多,在網絡傳輸的過程中出現丟包的風險也越大。當丟包重傳出現的時候,重傳定時器的工作時間單位是秒,也就是說最快 1 秒以后才能開始重傳。所以,如果在你的應用程序里可能的話,可以嘗試將數據大小控制在一個 MTU 內部來極致地提高性能。我所知道的是在早期的 QQ 后臺服務中應用過這個技巧,不知道現在還有沒有在用。
建議2:減少內存拷貝
假如你要發送一個文件給另外一臺機器上,那么比較基礎的做法是先調用 read 把文件讀出來,再調用 send 把數據把數據發出去。這樣數據需要頻繁地在內核態內存和用戶態內存之間拷貝,如圖 3.1。
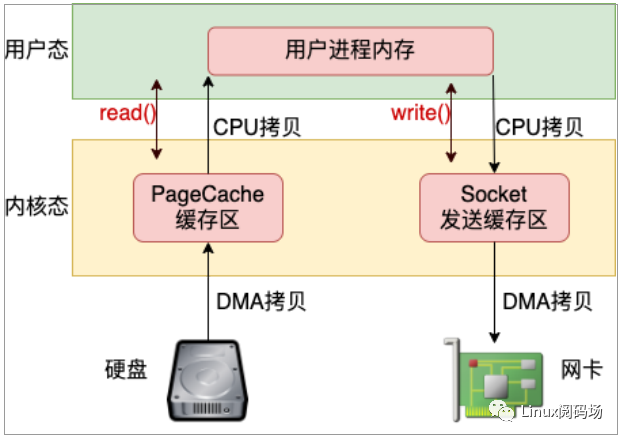
圖3.1 read + write 發送文件
目前減少內存拷貝主要有兩種方法,分別是使用 mmap 和 sendfile 兩個系統調用。使用 mmap 系統調用的話,映射進來的這段地址空間的內存在用戶態和內核態都是可以使用的。如果你發送數據是發的是 mmap 映射進來的數據,則內核直接就可以從地址空間中讀取,如圖 3.2,這樣就節約了一次從內核態到用戶態的拷貝過程。
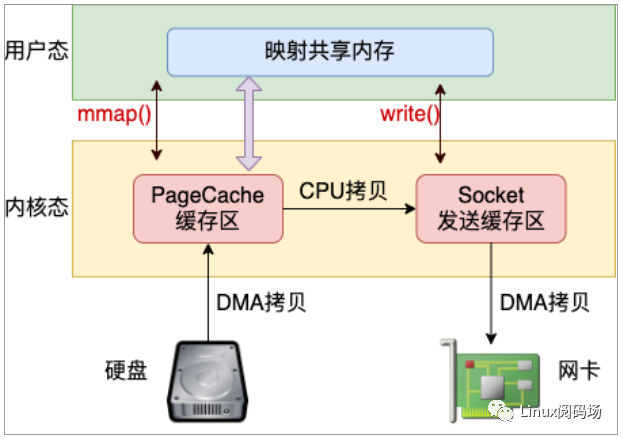
圖3.2 mmap + write 發送文件
不過在 mmap 發送文件的方式里,系統調用的開銷并沒有減少,還是發生兩次內核態和用戶態的上下文切換。如果你只是想把一個文件發送出去,而不關心它的內容,則可以調用另外一個做的更極致的系統調用 - sendfile。在這個系統調用里,徹底把讀文件和發送文件給合并起來了,系統調用的開銷又省了一次。再配合絕大多數網卡都支持的"分散-收集"(Scatter-gather)DMA 功能。可以直接從 PageCache 緩存區中 DMA 拷貝到網卡中,如圖3.3。這樣絕大部分的 CPU 拷貝操作就都省去了。
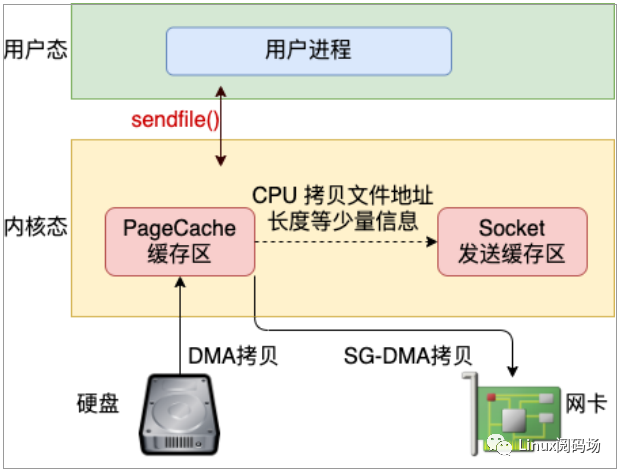
圖3.3 sendfile 發送文件
建議3:發送處理合并
在建議 1 中我們說到過發送過程在 IP 層如果要發送的數據大于 MTU 的話,會被分片。但其實是有一個例外情況,那就是開啟了 TSO(TCP Segmentation Offload)/ GSO(Generic Segmentation Offload)。我們來回顧和跟進
一下發送過程中的相關源碼:
//file:net/ipv4/ip_output.cstaticintip_finish_output(structsk_buff*skb){......//大于mtu的話就要進行分片了if(skb->len>ip_skb_dst_mtu(skb)&&!skb_is_gso(skb))returnip_fragment(skb,ip_finish_output2)?elsereturnip_finish_output2(skb)?}
ip_finish_output 是協議層中的函數。skb_is_gso 判斷是否使用 gso,如果使用了的話,就可以把分片過程推遲到更下面的設備層去做。
//file:net/core/dev.cintdev_hard_start_xmit(structsk_buff*skb,structnet_device*dev,structnetdev_queue*txq){......if(netif_needs_gso(skb,features)){if(unlikely(dev_gso_segment(skb,features)))gotoout_kfree_skb?if(skb->next)gotogso?}}
dev_hard_start_xmit 位于設備層,和物理網卡離得更近了。netif_needs_gso 來判斷是否需要進行 GSO 切分。在這個函數里會判斷網卡硬件是不是支持 TSO,如果支持則不進行 GSO 切分,將大包直接傳給網卡驅動,切分工作推遲到網卡硬件中去做。如果硬件不支持,則調用 dev_gso_segment 開始切分。
推遲分片的好處是可以省去大量包的協議頭的計算工作量,減輕 CPU 的負擔。
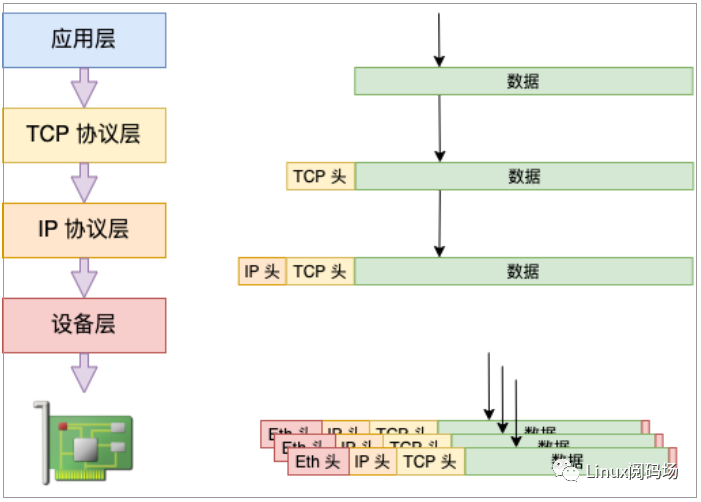
圖3.4 發送處理合并
使用 ethtool 工具可以查看當前 tso 和 gso 的開啟狀況。
#ethtool-keth0tcp-segmentation-offload:ontx-tcp-segmentation:ontx-tcp-ecn-segmentation:off[fixed]tx-tcp6-segmentation:onudp-fragmentation-offload:off[fixed]generic-segmentation-offload: off
如果沒有開啟,可以使用 ethtool 打開。
#ethtool-Keth0tsoon# ethtool -K eth0 gso on
建議4:多隊列網卡 XPS 調優
在第四章的發送過程中 4.4.5 小節,我們看到在 __netdev_pick_tx 函數中,要選擇一個發送隊列出來。如果存在XPS (Transmit Packet Steering)配置,就以 XPS 配置為準。過程是根據當前 CPU 的 id 號去到 XPS 中查看是要用哪個發送隊列,來看下源碼。
//file:net/core/flow_dissector.cstatic inline int get_xps_queue(struct net_device *dev, struct sk_buff *skb){//獲取xps配置dev_maps=rcu_dereference(dev->xps_maps)?if(dev_maps){map=rcu_dereference(map=rcu_dereference(//raw_smp_processor_id()是獲取當前cpuiddev_maps->cpu_map[raw_smp_processor_id()])?if(map){if(map->len==1)queue_index=map->queues[0]?...}
源碼中 raw_smp_processor_id 是在獲取當前執行的 CPU id。用該 CPU 號查看對應的 CPU 核是否有配置。XPS配置在 /sys/class/net//queues/tx-/xps_cpus 這個偽文件里。例如對于我手頭的一臺服務器來說,配置是這樣的。
#cat/sys/class/net/eth0/queues/tx-0/xps_cpus00000001#cat/sys/class/net/eth0/queues/tx-1/xps_cpus00000002#cat/sys/class/net/eth0/queues/tx-2/xps_cpus00000004#cat/sys/class/net/eth0/queues/tx-3/xps_cpus00000008......
上述結果中 xps_cpus 是一個 CPU 掩碼,表示當前隊列對應的 CPU 號。從上面輸出看對于 eth0 網卡 下的 tx-0 隊列來說,是和 CPU0 綁定的。00000001 表示 CPU0,00000002 表示 CPU1,...,以此類推。假如當前 CPU 核是CPU0,那么找到的隊列就是 eth0 網卡 下的 tx-0。
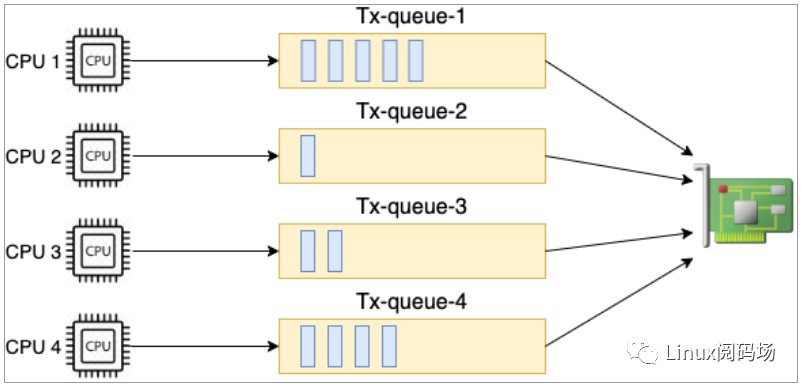
圖3.5多隊列網卡發送
那么通過 XPS 指定了當前 CPU 要使用的發送隊列有什么好處呢。好處大致是有兩個:
第一,因為更少的 CPU 爭用同一個隊列,所以設備隊列鎖上的沖突大大減少。如果進一步配置成每個 CPU都有自己獨立的隊列用,則會完全消除隊列鎖的開銷。
第二,CPU 和發送隊列一對一綁定以后能提高傳輸結構的局部性,從而進一步提升效率。
關于RSS、RPS、RFS、aRFS、XPS等網絡包收發過程中的優化手段可用參考源碼中
Documentation/networking/scaling.txt這個文檔。里面有關于這些技術的詳細官方說明。
建議5:使用 eBPF 繞開協議棧的本機 IO
如果你的業務中涉及到大量的本機網絡 IO 可以考慮這個優化方案。
在第 5 章中我們看到,本機網絡 IO 和跨機 IO 比較起來,確實是節約了驅動上的一些開銷。發送數據不需要進RingBuffer 的驅動隊列,直接把 skb 傳給接收協議棧(經過軟中斷)。但是在內核其它組件上,可是一點都沒少,系統調用、協議棧(傳輸層、網絡層等)、設備子系統整個走 了一個遍。連“驅動”程序都走了(雖然對于回環設備來說這個驅動只是一個純軟件的虛擬出來的東東)。
如果想用本機網絡 IO,但是又不想頻繁地在協議棧中繞來繞去。那么你可以試試 eBPF。使用 eBPF 的 sockmap和 sk redirect 可以繞過 TCP/IP 協議棧,而被直接發送給接收端的 socket,業界已經有公司在這么做了。
4 內核與進程協作優化
建議1:盡量少用 recvfrom 等進程阻塞的方式
在 3.3 節我們看到,在使用了 recvfrom 阻塞方式來接收 socket 上數據的時候。每次一個進程專?為了等一個socket 上的數據就得被從 CPU 上拿下來。然后再換上另一個 進程。等到數據 ready 了,睡眠的進程又會被喚醒。總共兩次進程上下文切換開銷。如果我們服務器上需要有大量的用戶請求需要處理,那就需要有很多的進程存在,而且不停地切換來切換去。這樣的缺點有如下這么幾個:
因為每個進程只能同時等待一條連接,所以需要大量的進程。
進程之間互相切換的時候需要消耗很多 CPU 周期,一次切換大約是 3 - 5 us 左右。
頻繁的切換導致 L1、L2、L3 等高速緩存的效果大打折扣
大家可能以為這種網絡 IO 模型很少見了。但其實在很多傳統的客戶端 SDK 中,比如 mysql、redis 和 kafka 仍然是沿用了這種方式。
建議2:使用成熟的網絡庫
使用 epoll 可以高效地管理海量的 socket。在服務器端。我們有各種成熟的網絡庫進行使用。這些網絡庫都對epoll 使用了不同程度的封裝。
首先第一個要給大家參考的是 Redis。老版本的 Redis 里單進程高效地使用 epoll 就能支持每秒數萬 QPS 的高性能。如果你的服務是單進程的,可以參考 Redis 在網絡 IO 這塊的源碼。
如果是多線程的,線程之間的分工有很多種模式。那么哪個線程負責等待讀 IO 事件,那個線程負責處理用戶請求,哪個線程又負責給用戶寫返回。根據分工的不同,又衍生出單 Reactor、多 Reactor、以及 Proactor 等多種模式。大家也不必頭疼,只要理解了這些原理之后選擇一個性能不錯的網絡庫就可以了。比如 PHP 中的 Swoole、Golang 的 net 包、Java 中的 netty 、C++ 中的 Sogou Workflow 都封裝的非常的不錯。
建議3:使用 Kernel-ByPass 新技術
如果你的服務對網絡要求確實特別特特別的高,而且各種優化措施也都用過了,那么現在還有終極優化大招 --Kernel-ByPass 技術。在本書我們看到了內核在接收網絡包的時候要經過很?的收發路徑。在這期間牽涉到很多內核組件之間的協同、協議棧的處理、以及內核態和用戶態的拷貝和切換。Kernel-ByPass 這類的技術方案就是繞開內核協議棧,自己在用戶態來實現網絡包的收發。這樣不但避開了繁雜的內核協議棧處理,也減少了頻繁了內核態用戶態之間的拷貝和切換,性能將發揮到極致!
目前我所知道的方案有 SOLARFLARE 的軟硬件方案、DPDK 等等。如果大家感興趣,可以多去了解一下!
5 握手揮手過程優化
建議1:配置充足的端口范圍
客戶端在調用 connect 系統調用發起連接的時候,需要先選擇一個可用的端口。內核在選用端口的時候,是采用從可用端口范圍中某一個隨機位置開始遍歷的方式。如果端口不充足的話,內核可能需要循環撞很多次才能選上一個可用的。這也會導致花費更多的 CPU 周期在內部的哈希表查找以及可能的自旋鎖等待上。因此不要等到端口用盡報錯了才開始加大端口范圍,而且應該一開始的時候就保持一個比較充足的值。
#vi/etc/sysctl.confnet.ipv4.ip_local_port_range=500065000# sysctl -p //使配置生效
如果端口加大了仍然不夠用,那么可以考慮開啟端口 reuse 和 recycle。這樣端口在連接斷開的時候就不需要等待2MSL 的時間了,可以快速回收。開啟這個參數之前需要保證 tcp_timestamps 是開啟的。
#vi/etc/sysctl.confnet.ipv4.tcp_timestamps=1net.ipv4.tcp_tw_reuse=1net.ipv4.tw_recycle=1# sysctl -p
建議2:客戶端最好不要使用 bind
如果不是業務有要求,建議客戶端不要使用 bind。因為我們在 6.3 節看到過,connect 系統調用在選擇端口的時候,即使一個端口已經被用過了,只要和已經有的連接四元組不完全一致,那這個端口仍然可以被用于建立新連接。但是 bind 函數會破壞 connect 的這段端口選擇邏輯,直接綁定一個端口,而且一個端口只能被綁定一次。如果使用了 bind,則一個端口只能用于發起一條連接上。總體上來看,你的機器的最大并發連接數就真的受限于65535 了。
建議3:小心連接隊列溢出
服務器端使用了兩個連接隊列來響應來自客戶端的握手請求。這兩個隊列的長度是在服務器 listen 的時候就確定好了的。如果發生溢出,很可能會丟包。所以如果你的業務使用的是短連接且流量比較大,那么一定得學會觀察這兩個隊列是否存在溢出的情況。因為一旦出現因為連接隊列導致的握手問題,那么 TCP 連接耗時都是秒級以上了。
對于半連接隊列, 有個簡單的辦法。那就是只要保證 tcp_syncookies 這個內核參數是 1 就能保證不會有因為半連接隊列滿而發生的丟包。對于全連接隊列來說,可以通過 netstat -s 來觀察。netstat -s 可查看到當前系統全連接隊列滿導致的丟包統計。但該數字記錄的是總丟包數,所以你需要再借助 watch 命令動態監控。
#watch'netstat--s|grepoverflowed'160 times the listen queue of a socket overflowed //全連接隊列滿導致的丟包
如果輸出的數字在你監控的過程中變了,那說明當前服務器有因為全連接隊列滿而產生的丟包。你就需要加大你的全連接隊列的?度了。全連接隊列是應用程序調用 listen時傳入的 backlog 以及內核參數 net.core.somaxconn 二者之中較小的那個。如果需要加大,可能兩個參數都需要改。如果你手頭并沒有服務器的權限,只是發現自己的客戶端機連接某個 server 出現耗時長,想定位一下是否是因為握手隊列的問題。那也有間接的辦法,可以 tcpdump 抓包查看是否有 SYN 的 TCP Retransmission。如果有偶發的 TCP Retransmission, 那就說明對應的服務端連接隊列可能有問題了。
建議4:減少握手重試
在 6.5 節我們看到如果握手發生異常,客戶端或者服務端就會啟動超時重傳機制。這個超時重試的時間間隔是翻倍地增長的,1 秒、3 秒、7 秒、15 秒、31 秒、63 秒 ......。對于我們提供給用戶直接訪問的接口來說,重試第一次耗時 1 秒多已經是嚴重影響用戶體驗了。如果重試到第三次以后,很有可能某一個環節已經報錯返回 504 了。所以在這種應用場景下,維護這么多的超時次數其實沒有任何意義。倒不如把他們設置的小一些,盡早放棄。其中客戶端的 syn 重傳次數由 tcp_syn_retries 控制,服務器半連接隊列中的超時次數是由 tcp_synack_retries 來控制。把它們兩個調成你想要的值。
建議5:打開 TFO( TCP Fast Open)
我們第 6 章的時候沒有介紹一個細節,那就是 fastopen 功能。在客戶端和服務器端都支持該功能的前提下,客戶端的第三次握手 ack 包就可以攜帶要發送給服務器的數據。這樣就會節約一個 RTT 的時間開銷。如果支持,可以嘗試啟用。
#vi/etc/sysctl.confnet.ipv4.tcp_fastopen=3//服務器和客戶端兩種角色都啟用#sysctl--p
建議6:保持充足的文件描述符上限
在 Linux 下一切皆是文件,包括我們網絡連接中的 socket。如果你的服務進程需要支持海量的并發連接。那么調整和加大文件描述符上限是很關鍵的。否則你的線上服務將會收到 “Too many open files”這個錯誤。
相關的限制機制請參考 8.2 節,這里我們給出一套推薦的修改方法。例如你的服務需要在單進程支持 100 W 條并發,那么建議:
#vi/etc/sysctl.conffs.file-max=1100000//系統級別設置成110W,多留點buffer。fs.nr_open=1100000//進程級別也設置成110W,因為要保證比hardnofile大#sysctl--p#vi/etc/security/limits.conf//用戶進程級別都設置成100W*softnofile1000000* hard nofile 1000000
建議7:如果請求頻繁,請棄用短連接改用長連接
如果你的服務器頻繁請求某個 server,比如 redis 緩存。和建議 1 比起來,一個更好一點的方法是使用長連接。這樣的好處有
1)節約了握手開銷。短連接中每次請求都需要服務和緩存之間進行握手,這樣每次都得讓用戶多等一個握手的時間開銷。
2)規避了隊列滿的問題。前面我們看到當全連接或者半連接隊列溢出的時候,服務器直接丟包。而客戶端呢并不知情,所以傻傻地等 3 秒才會重試。要知道 tcp 本身并不是專門為互聯網服務設計的。這個 3 秒的超時對于互聯網用戶的體驗影響是致命的。
3)端口數不容易出問題。端連接中,在釋放連接的時候,客戶端使用的端口需要進入 TIME_WAIT 狀態,等待 2MSL的時間才能釋放。所以如果連接頻繁,端口數量很容易不夠用。而長連接就固定使用那么幾十上百個端口就夠用了。
建議8:TIME_WAIT 的優化
很多線上服務如果使用了短連接的情況下,就會出現大量的 TIME_WAIT。
首先,我想說的是沒有必要見到兩三萬個 TIME_WAIT 就恐慌的不行。從內存的?度來考慮,一條 TIME_WAIT 狀態的連接僅僅是 0.5 KB 的內存而已。從端口占用的角度來說,確實是消耗掉了一個端口。但假如你下次再連接的是不同的 Server 的話,該端口仍然可以使用。只有在所有 TIME_WAIT 都聚集在和一個 Server 的連接上的時候才會有問題。
那怎么解決呢? 其實辦法有很多。第一個辦法是按上面建議 1 中的開啟端口 reuse 和 recycle。第二個辦法是限制TIME_WAIT 狀態的連接的最大數量。
#vi/etc/sysctl.confnet.ipv4.tcp_max_tw_buckets=32768# sysctl --p
如果再徹底一些,也可以干脆采用建議 7 ,直接用?連接代替頻繁的短連接。連接頻率大大降低以后,自然也就沒有 TIME_WAIT 的問題了。
原文標題:深入理解Linux網絡之網絡性能優化建議
文章出處:【微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
-
cpu
+關注
關注
68文章
11033瀏覽量
215978 -
數據庫
+關注
關注
7文章
3900瀏覽量
65771
原文標題:深入理解Linux網絡之網絡性能優化建議
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
學習Linux運維發展方向
Linux運維都要會哪些shell技能
開啟運維新時代:WOT2016互聯網運維與開發者峰會內容回顧
云計算運維管理的優化與改進

制氫機遠程監控運維方案
光伏電站智能運維管理系統三大核心功能
Acrel-1200安科瑞光伏運維平臺






 工商網監
工商網監
評論