") 如何使用PyCaret + RAPIDS簡化模型構(gòu)建
如何使用PyCaret + RAPIDS簡化模型構(gòu)建
PyCaret是一個(gè)低代碼 Python 機(jī)器學(xué)習(xí)庫,基于流行的 R Caret 庫。它自動化了從數(shù)據(jù)預(yù)處理到 i NSight 的數(shù)據(jù)科學(xué)過程,因此短代碼行可以用最少的人工完成每個(gè)步驟。此外,使用簡單的命令比較和調(diào)整許多模型的能力可以簡化效率和生產(chǎn)效率,同時(shí)減少創(chuàng)建有用模型的時(shí)間。
PyCaret 團(tuán)隊(duì)在 2 . 2 版中添加了 NVIDIA GPU 支持,包括RAPIDS中所有最新和最偉大的版本。使用 GPU 加速, PyCaret 建模時(shí)間可以快 2 到 200 倍,具體取決于工作負(fù)載。
這篇文章將介紹如何在 GPU 上使用 PyCaret 以節(jié)省大量的開發(fā)和計(jì)算成本。
所有基準(zhǔn)測試都是在一臺 32 核 CPU 和四個(gè) NVIDIA Tesla T4 的機(jī)器上運(yùn)行的,代碼幾乎相同。為簡單起見, GPU 代碼編寫為在單個(gè) GPU 上運(yùn)行。
PyCaret 入門
使用 PyCaret 與導(dǎo)入庫和執(zhí)行 setup 語句一樣簡單。setup()功能創(chuàng)建環(huán)境,并提供一系列預(yù)處理功能,一氣呵成。
from pycaret.regression import * exp_reg = setup(data = df, target = ‘Year’, session_id = 123, normalize = True)
在一個(gè)簡單的設(shè)置之后,數(shù)據(jù)科學(xué)家可以開發(fā)其管道的其余部分,包括數(shù)據(jù)預(yù)處理/準(zhǔn)備、模型訓(xùn)練、集成、分析和部署。在準(zhǔn)備好數(shù)據(jù)后,最好從比較模型開始。
與 PyCaret 的簡約精神一樣,我們可以通過一行代碼來比較一系列標(biāo)準(zhǔn)模型,看看哪些模型最適合我們的數(shù)據(jù)。 compare _ models 命令使用默認(rèn)超參數(shù)訓(xùn)練 PyCaret 模型庫中的所有模型,并使用交叉驗(yàn)證評估性能指標(biāo)。然后,數(shù)據(jù)科學(xué)家可以根據(jù)這些信息選擇他們想要使用的模型、調(diào)整和集成。
top3 = compare_models(exclude = [‘ransac’], n_select=3)
比較模型
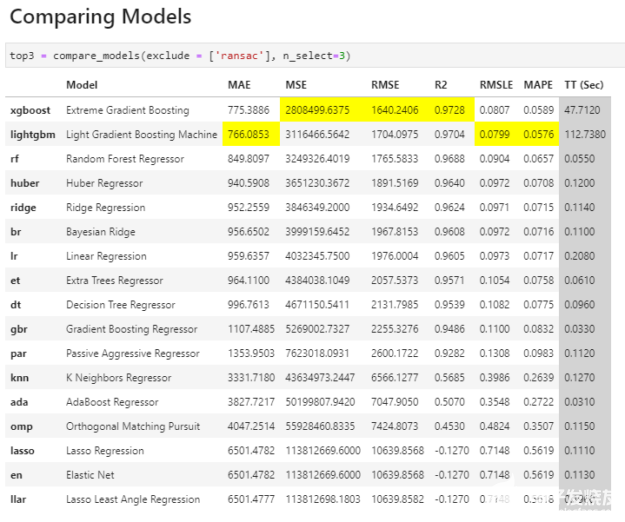
圖 1 : PyCaret 中 compare _ models 命令的輸出。
**模型從最佳到最差排序, PyCaret 突出顯示了每個(gè)度量類別中的最佳結(jié)果,以便于使用。
用 RAPIDS cuML 加速 PyCaret
PyCaret 對于任何數(shù)據(jù)科學(xué)家來說都是一個(gè)很好的工具,因?yàn)樗喕四P蜆?gòu)建并使運(yùn)行許多模型變得簡單。使用 GPU s , PyCaret 可以做得更好。由于 PyCaret 在幕后做了大量工作,因此看似簡單的命令可能需要很長時(shí)間。例如,我們在一個(gè)具有大約 50 萬個(gè)實(shí)例和 90 多個(gè)屬性(加州大學(xué)歐文分校的年度預(yù)測 MSD 數(shù)據(jù)集)的數(shù)據(jù)集上運(yùn)行了前面的命令。在 CPU 上,花費(fèi)了 3 個(gè)多小時(shí)。在 GPU 上,只花了不到一半的時(shí)間。
在過去,在 GPU 上使用 PyCaret 需要許多手動編碼,但謝天謝地, PyCaret 團(tuán)隊(duì)集成了 RAPIDS 機(jī)器學(xué)習(xí)庫( cuML ),這意味著您可以使用使 PyCaret 如此有效的相同簡單 API ,同時(shí)還可以使用 GPU 的計(jì)算能力。
在 GPU 上運(yùn)行 PyCaret 往往要快得多,這意味著您可以充分利用 PyCaret 提供的一切,而無需平衡時(shí)間成本。使用剛才提到的同一個(gè)數(shù)據(jù)集,我們在 CPU 和 GPU 上測試了 PyCaret ML 功能,包括比較、創(chuàng)建、調(diào)優(yōu)和集成模型。切換到 GPU 很簡單;我們在設(shè)置函數(shù)中將use_gpu設(shè)置為True:
exp_reg = setup(data = df, target = ‘Year’, session_id = 123, normalize = True, use_gpu = True)
PyCaret 設(shè)置為在 GPU 上運(yùn)行,它使用 cuML 來訓(xùn)練以下所有型號:
對數(shù)幾率回歸
脊分類器
隨機(jī)森林
K 鄰域分類器
K 鄰域回歸器
支持向量機(jī)
線性回歸
嶺回歸
套索回歸
群集分析
基于密度的空間聚類
僅在 GPU 上運(yùn)行相同的compare_models代碼的速度是 GPU 的2.5倍多。
對于流行但計(jì)算昂貴的模型,在模型基礎(chǔ)上的影響更大。例如, K 鄰域回歸器在 GPU 上的速度是其 265 倍。
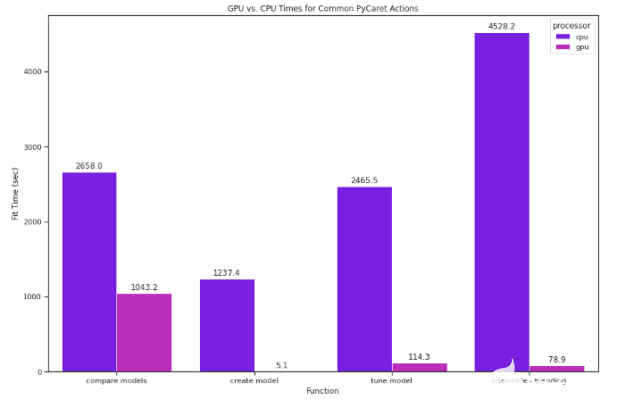
圖 2 : CPU 和 GPU 上運(yùn)行的常見 PyCaret 操作的比較。
影響
PyCaret API 的簡單性釋放了原本用于編碼的時(shí)間,因此數(shù)據(jù)科學(xué)家可以做更多的實(shí)驗(yàn)并對實(shí)驗(yàn)進(jìn)行微調(diào)。當(dāng)與 GPU 配合使用時(shí),這種影響甚至更大,因?yàn)槌浞掷?PyCaret 的評估和比較工具套件的計(jì)算成本顯著降低。
結(jié)論
廣泛的比較和評估模型有助于提高結(jié)果的質(zhì)量,而 PyCaret 正是為了這樣做。 GPU 上的 PyCaret 抵消了大量處理所帶來的時(shí)間成本。
RAPIDS 的目標(biāo)是加速您的數(shù)據(jù)科學(xué), PyCaret 是越來越多的庫之一,它們與 RAPIDS 套件的兼容性有助于為您的機(jī)器學(xué)習(xí)追求帶來新的效率。
PyCaret CPU vs. GPU Benchmarking
Import Libraries
import pycaret
import pandas as pd
import numpy as np
import time
from pycaret.utils import version
version()
Timing
import json
import time
class Timer:
def __enter__(self, *args, **kwargs):
self.tick = time.time()
return self
def __exit__(self, *args, **kwargs):
self.elapsed = time.time() - self.tick
benchmark_list = []
dataset = pd.read_csv('YearPredictionMSd.txt')
#fixing attribute labels
names = ['Year']
for x in range(1,13):
names.append('t_avg_' + str(x)) #these attributes are timbre averages
for x in range(1,79):
names.append('t_cov_' + str(x)) #these attributes are timbre covariances
dataset.columns = names
dataset.head()
Withhold a sample of 600 records from the original dataset to be used for predictions (not to be confused with train/test split).
#gpu data
df = dataset[:463716]
unseen_df = dataset[463716:515346]
unseen_df.reset_index(drop=True, inplace=True)
print('Data for Modeling: ' + str(df.shape))
print('Unseen Data For Predictions: ' + str(unseen_df.shape))
Set up Environment in PyCaret
To record CPU times, keepuse_gpu=False, and to record GPU times, set it toTrue. Be sure to update the labels in the timing module at the end of each cell to match what's being recorded.
from pycaret.regression import *
exp_reg = setup(data = df, target = 'Year', session_id = 123, normalize = True, use_gpu=False)
Compare All Models
Not all models can be run on GPU, so even whenuse_gpu=True, those that cannot be run on GPU will automatically be run on CPU. To compare the times of only those models that can be run on GPU,exclude = ['ransac', 'huber', 'par', 'ada', 'omp', 'llar'].
with Timer() as elapsed:
best_models = compare_models(exclude = ['ransac'], n_select = 3)
benchmark_payload = {}
benchmark_payload["function"] = "compare models"
benchmark_payload["model"] = "all"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Create Models
Here we can time the fitting of an individual model. Linear regression is used for example.
with Timer() as elapsed:
lr = create_model('lr', fold = 5)
benchmark_payload = {}
benchmark_payload["function"] = "create model"
benchmark_payload["model"] = "lr"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Tune Models
Here we can time the tuning of a model we've created.
with Timer() as elasped:
tuned_lr = tune_model(lr)
benchmark_payload = {}
benchmark_payload["function"] = "tune model"
benchmark_payload["model"] = "lr"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Ensemble a Model
Blending
with Timer() as elapsed:
#train individual models to blend
xgboost = create_model('xgboost', verbose = False)
lr = create_model('lr', verbose = False)
knn = create_model('knn', verbose = False)
#blend individual models
blender = blend_models(estimator_list = [xgboost, lr, knn])
benchmark_payload = {}
benchmark_payload["function"] = "ensemble - blending"
benchmark_payload["model"] = "xgboost, lr, knn"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Stacking
with Timer() as elapsed:
stacker = stack_models(best_models)
benchmark_payload = {}
benchmark_payload["function"] = "ensemble - stacking"
benchmark_payload["model"] = "best_models cpu"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Plot Error
plot_model(blender, plot = 'error')
plot_model(stacker, plot = 'error')
Predict on Hold-Out Sample
with Timer() as elapsed:
predict_model(stacker);
benchmark_payload = {}
benchmark_payload["function"] = "predict model"
benchmark_payload["model"] = "stacker"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Finalize Model
with Timer() as elapsed:
final_stacker = finalize_model(stacker)
benchmark_payload = {}
benchmark_payload["function"] = "finalize model"
benchmark_payload["model"] = "stacker"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
with Timer() as elapsed:
predict_model(final_stacker);
benchmark_payload = {}
benchmark_payload["function"] = "predict model"
benchmark_payload["model"] = "final stacker"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Predict on Unseen Data
with Timer() as elapsed:
unseen_predictions = predict_model(final_stacker, data=data_unseen)
unseen_predictions.head()
benchmark_payload = {}
benchmark_payload["function"] = "predict on unseen"
benchmark_payload["model"] = "final stacker"
benchmark_payload["processor"] = "cpu"
benchmark_payload["fit_time"] = elapsed.elapsed
benchmark_list.append(benchmark_payload)
Write Times to File
outpath = "pycaret_benchmarksCPU.json"
with open(outpath, "a") as fh:
fh.write(json.dumps(benchmark_list))
fh.write("\n")
關(guān)于作者
Sofia Sayyah 是 NVIDIA 的數(shù)據(jù)工程實(shí)習(xí)生。
審核編輯:郭婷
-
gpu
+關(guān)注
關(guān)注
28文章
4916瀏覽量
130733 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8493瀏覽量
134170
發(fā)布評論請先 登錄
瑞芯微模型量化文件構(gòu)建
碳化硅襯底厚度測量中探頭溫漂的熱傳導(dǎo)模型與實(shí)驗(yàn)驗(yàn)證
請問NanoEdge AI數(shù)據(jù)集該如何構(gòu)建?
構(gòu)建開源OpenVINO?工具套件后,模型優(yōu)化器位于何處呢?
OpenAI簡化大模型選擇:薩姆·奧特曼制定路線圖
小白學(xué)大模型:構(gòu)建LLM的關(guān)鍵步驟

RAPIDS cuDF將pandas提速近150倍

如何使用Python構(gòu)建LSTM神經(jīng)網(wǎng)絡(luò)模型
為THS3001構(gòu)建一個(gè)簡單的SPICE模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論