") MQ怎么保障消息可靠性?
MQ怎么保障消息可靠性?
面試官:在MQ的整個(gè)消息生產(chǎn)消費(fèi)過程中,如何保障消息100%被消費(fèi)?
候選人:MQ有個(gè)ACK機(jī)制,確保消息100%被消費(fèi)。
面試官:好吧,可以回去等通知了……
這道面試題在考察MQ組件時(shí)算是老生常談了,不知道你是如何回答的?
我們平時(shí)都在使用MQ,但使用技術(shù)框架只是第一步,去弄明白它的底層原理、深挖技術(shù)真相,才是每一位IT從業(yè)者的基操。
這里說明一點(diǎn),想要回答好面試官的問題,最好還是要有金字塔思維——金字塔思維就是從不同維度上來思考問題的一種方式,不重不漏,集體窮盡。
MQ作為異步通訊的消息中間件,其功能除了解耦生產(chǎn)者與消費(fèi)者,還能用于大流量的削峰填谷,解決業(yè)務(wù)的最終一致性問題,那么消息的“可靠性”就顯得尤為重要了,比如說商品出庫(kù)后的庫(kù)存數(shù)據(jù)通過MQ同步到財(cái)務(wù)系統(tǒng),如果消息的可靠性沒有保障,那財(cái)務(wù)系統(tǒng)的存貨成本分析數(shù)據(jù)就無(wú)法有效支撐財(cái)務(wù)團(tuán)隊(duì)。
準(zhǔn)確來說,我們需要保障MQ消息的可靠性,需要從三個(gè)層面/維度解決:生產(chǎn)者100%投遞、MQ持久化、消費(fèi)者100%消費(fèi),這里的100%消費(fèi)指的是消息不少消費(fèi),也不多消費(fèi)。
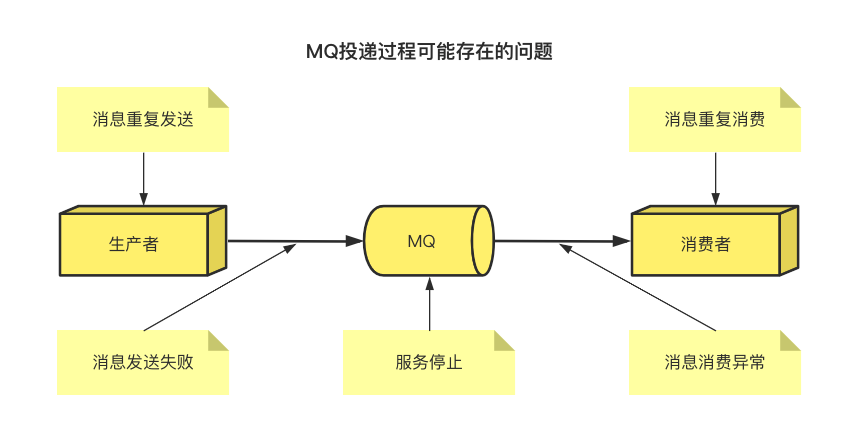
由于MQ是基礎(chǔ)網(wǎng)絡(luò)通訊的中間件,網(wǎng)絡(luò)通訊必然因丟包、網(wǎng)絡(luò)抖動(dòng)等原因產(chǎn)生數(shù)據(jù)丟失,MQ組件本身也會(huì)由于宕機(jī)或軟件崩潰而中止服務(wù),從而造成數(shù)據(jù)丟失,那么我們就需要從這兩個(gè)根本原因著手補(bǔ)償,這里科普一下RabbitMQ和Kafka是怎么解決的。
RabbitMQ
這里我必須先提一提RabbitMQ的消息協(xié)議——AMQP(Advanced Message Queuing Protocol,高級(jí)消息隊(duì)列協(xié)議),在面試時(shí)我經(jīng)常問候選人一個(gè)問題:RabbitMQ用的是什么消息協(xié)議?大部分候選人是回答不出來AMQP的,更不用說AMQP模型是如何設(shè)計(jì)的了。 在服務(wù)器中,三個(gè)主要功能模塊連接成一個(gè)處理鏈完成預(yù)期的功能:
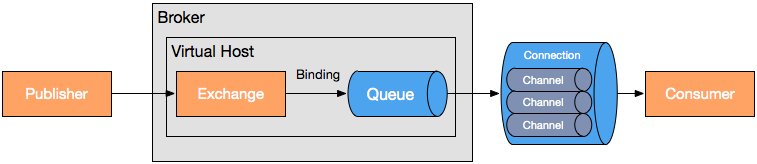
Exchange:接收發(fā)布應(yīng)用程序發(fā)送的消息,并根據(jù)一定的規(guī)則將這些消息路由到消息隊(duì)列
Queue:存儲(chǔ)消息,直到這些消息被消費(fèi)者安全處理完為止
Binding:定義了exchange和queue之間的關(guān)聯(lián),提供路由規(guī)則
使用這個(gè)模型我們可以很容易地模擬出存儲(chǔ)轉(zhuǎn)發(fā)隊(duì)列和主題訂閱這些典型的消息中間件概念。 接下來我們看看RabbitMQ的消息確認(rèn)機(jī)制是如何保障消息可靠性的。一、生產(chǎn)者端
通過API將信道(channel)設(shè)置為confirm模式,則每條消息會(huì)被分配一個(gè)唯—ID
如果消息投遞成功,也就是說消息已經(jīng)到達(dá)broker了,信道會(huì)發(fā)送ack給生產(chǎn)者,回調(diào)ConfirmCallback接口,帶上唯一ID
如果發(fā)生錯(cuò)誤導(dǎo)致消息丟失,比如通過某個(gè)RoutingKey無(wú)法路由到某個(gè)Queue,則會(huì)發(fā)送nack給生產(chǎn)者,回調(diào)ReturnCallback接口,并帶上唯一ID和異常信息
ack和nack只有一個(gè)被觸發(fā),只觸發(fā)一次,而且是異步執(zhí)行,意味著生產(chǎn)者不需要等待,可以繼續(xù)發(fā)送新消息
二、消費(fèi)者端
聲明隊(duì)列時(shí),指定noack=false, 表示消費(fèi)者不會(huì)自動(dòng)提交ack,broker會(huì)等待消費(fèi)者手動(dòng)返回ack、才會(huì)刪除消息,否則立刻刪除
broker的ack沒有超時(shí)機(jī)制,只會(huì)判斷鏈接是否斷開,如果斷開了(比如消費(fèi)者處理消息過程中宕機(jī)),消息會(huì)被重新發(fā)送,所以消費(fèi)者要做好消息冪等性處理
此外,RabbitMQ除了消息確認(rèn)機(jī)制,還有另一種方式——使用事務(wù)消息:消息生產(chǎn)端發(fā)送commit命令,MQ同步返回commit ok命令,這種方式由于需要同步阻塞等待MQ返回是否投遞成功,才能執(zhí)行別的操作,性能較差,因此不推薦使用。三、MQ本身通常來說,消息是在內(nèi)存中存儲(chǔ)通訊的,而基于內(nèi)存的都是會(huì)有數(shù)據(jù)丟失的問題產(chǎn)生,服務(wù)一重啟,數(shù)據(jù)就隨之銷毀。 在RabbitMQ中對(duì)數(shù)據(jù)的持久化有三方面:交換機(jī)持久化、隊(duì)列持久化、消息持久化。
交換機(jī)持久化:exchange_declare創(chuàng)建交換機(jī)時(shí)通過參數(shù)durable=true指定,如:channel.exchangeDeclare(exchangeName, “direct/topic/header/fanout”,true);第三個(gè)參數(shù)就是設(shè)置durable值
隊(duì)列持久化:queue_declare創(chuàng)建隊(duì)列時(shí)通過參數(shù)durable=true指定,如:channel.queueDeclare("queue.persistent.name",true, false, false, null),第二個(gè)參數(shù)就是設(shè)置durable值
消息持久化:new AMPQMessage創(chuàng)建消息時(shí)通過參數(shù)指定,如:channel.basicPublish("exchange.persistent", "persistent",MessageProperties.PERSISTENT_TEXT_PLAIN, "persistent_test_message".getBytes()),或者設(shè)置參數(shù)deliveryMode=2來指定:AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();builder.deliveryMode(2);
上面只是說了API層的實(shí)現(xiàn),那RabbitMQ底層又是怎么做消息持久化的呢?如果指定了持久化參數(shù),它們會(huì)以append的方式寫文件,會(huì)根據(jù)文件大小(默認(rèn)16M)自動(dòng)切割,生成新的文件,RabbitMQ啟動(dòng)時(shí)會(huì)創(chuàng)建兩個(gè)進(jìn)程,一個(gè)負(fù)責(zé)持久化消息的存儲(chǔ),另一個(gè)負(fù)責(zé)非持久化消息的存儲(chǔ)(當(dāng)內(nèi)存不夠時(shí)會(huì)用到)。 消息存儲(chǔ)時(shí),會(huì)在一個(gè)叫ets的表中記錄消息在文件中的映射以及相關(guān)信息(包括ID、偏移量、有效數(shù)據(jù)、左邊文件、右邊文件),消息讀取時(shí)根據(jù)該信息到文件中讀取,同時(shí)更新信息。 消息刪除時(shí)只從ets刪除,變?yōu)槔鴶?shù)據(jù),當(dāng)垃圾數(shù)據(jù)超出比例(默認(rèn)50%),并且文件數(shù)達(dá)到3個(gè),就會(huì)觸發(fā)垃圾回收:鎖定左右兩個(gè)文件,整理左邊文件有效數(shù)據(jù)、將左邊文件有效數(shù)據(jù)寫入左邊,更新文件信息,刪除右邊,完成合并;當(dāng)一個(gè)文件的有效數(shù)據(jù)等于0時(shí),刪除該文件。 寫入文件前先寫入buffer緩沖區(qū),如果buffer已滿,則寫入文件,注意,此時(shí)只是操作系統(tǒng)的頁(yè)存,還沒落盤。 每隔25ms刷一次磁盤(比如Linux中的fsync命令),不管buffer(fd的讀、寫緩存區(qū))滿沒滿,都將buffer和頁(yè)存中的數(shù)據(jù)落盤。 還有另外一種落盤機(jī)制:每次消息寫入后,如果沒有后續(xù)寫入請(qǐng)求,則直接刷盤。 KafkaKafka在MQ領(lǐng)域以性能高、吞吐能力強(qiáng)、消息堆積能力強(qiáng)等等優(yōu)勢(shì)稱著,常常用于日志收集、消息系統(tǒng)、用戶活動(dòng)跟蹤、運(yùn)營(yíng)指標(biāo)、流式處理等等場(chǎng)景,講之前先簡(jiǎn)單聊聊Kafka的架構(gòu)設(shè)計(jì):
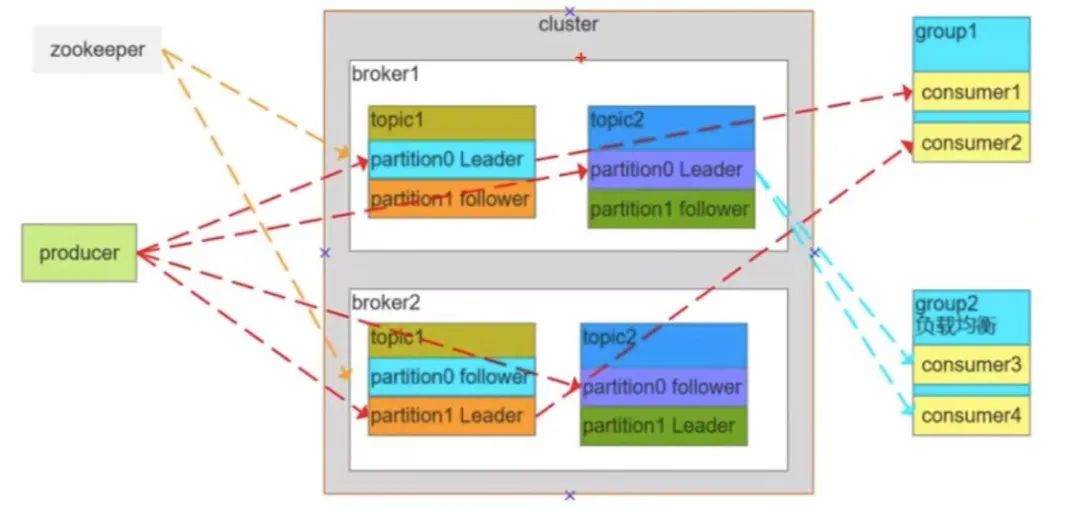
Consumer Group:消費(fèi)者組,消費(fèi)者組內(nèi)每個(gè)消費(fèi)者負(fù)責(zé)消費(fèi)不同分區(qū)的數(shù)據(jù),提高消費(fèi)能力,這是邏輯上的一個(gè)訂閱者。
Topic:可以理解為一個(gè)隊(duì)列,Topic將消息分類,生產(chǎn)者和消費(fèi)者面向的是同一個(gè)Topic。
Partition:為了實(shí)現(xiàn)擴(kuò)展性,提高并發(fā)能力,一個(gè)Topic以多個(gè)Partition的方式分布到多個(gè)Broker上,每個(gè)Partition是一個(gè)有序的隊(duì)列,一個(gè)Topic的每個(gè)Partition都有若干個(gè)副本(Replica),一個(gè)Leader和若干個(gè)Follower;生產(chǎn)者發(fā)送數(shù)據(jù)的對(duì)象,以及消費(fèi)者消費(fèi)數(shù)據(jù)的對(duì)象,都是通過Leader,F(xiàn)ollower負(fù)責(zé)實(shí)時(shí)從Leader中同步數(shù)據(jù),保持和Leader數(shù)據(jù)的同步;當(dāng)Leader發(fā)生故障時(shí),某個(gè)Follower還會(huì)成為新的Leader。
一、生產(chǎn)者端Kafka消息發(fā)送端有個(gè)ACK機(jī)制。
設(shè)置ack參數(shù):ack=0,表示不重試,Kafka不需要返回ack,極有可能各種原因造成丟失;ack=1,表示Leader寫入成功就返回ack了,F(xiàn)ollower不一定同步成功;ack=all或ack=-1,表示ISR列表中的所有Follower同步完成再返回ack。
設(shè)置參數(shù)unclean.leader.election.enable: false,禁止選舉ISR以外的Follower為L(zhǎng)eader,只能從ISR列表中的節(jié)點(diǎn)中選舉Leader;可能會(huì)犧牲Kafka的可用性,但是能夠提高消息的可靠性。
重試機(jī)制,設(shè)置tries > 1,表示消息重發(fā)次數(shù)。
設(shè)置最小同步副本數(shù)min.insync.replicas > 1,沒滿足該值前,Kafka不提供讀寫服務(wù),寫操作會(huì)異常。
通過設(shè)置最小同步副本數(shù)和ACK機(jī)制,可以讓MQ在性能與可靠性上達(dá)到平衡。二、消費(fèi)者端手工提交offset(偏移量):Kafka消費(fèi)者在拉取消息后,默認(rèn)會(huì)自動(dòng)提交offset,由于消費(fèi)者每次都會(huì)根據(jù)offset來消費(fèi)消息的,如果消費(fèi)者處理業(yè)務(wù)失敗,實(shí)際上我們是要重新消費(fèi)的,所以我們要在消息處理成功后再手工提交offset,確認(rèn)消息能夠成功消費(fèi)。 同樣地,消費(fèi)者的業(yè)務(wù)代碼也要做好冪等性校驗(yàn)。三、MQ本身很簡(jiǎn)單,通過減小broker刷盤間隔來實(shí)現(xiàn)高可靠。 要深究其原理,得從Kafka的持久化機(jī)制來看。
磁盤的順序讀寫:與RabbitMQ不同,Kafka是基于磁盤讀寫的,那為什么Kafka的吞吐量還這么大呢?原因是Kafka的讀寫是用順序讀寫的,不需要尋址隨機(jī)讀寫,而由于是用磁盤來寫數(shù)據(jù),消息堆積能力必然比內(nèi)存型的RabbitMQ更強(qiáng)
利用了操作系統(tǒng)的零拷貝技術(shù):避免CPU將數(shù)據(jù)從一塊存儲(chǔ)拷貝到另外一塊存儲(chǔ),關(guān)于零拷貝這里不詳述,與Java應(yīng)用不同,Kafka的消息不需要在用戶緩沖區(qū)處理磁盤數(shù)據(jù)再返回,所以才能用零拷貝技術(shù)
分區(qū)分段+索引:Kafka的消息實(shí)際上分布存儲(chǔ)在一個(gè)一個(gè)小的segment中的,每次文件讀寫也是直接操作segment,為了進(jìn)一步優(yōu)化查詢,Kafka又默認(rèn)為分段后的數(shù)據(jù)文件建立了索引文件(就是文件系統(tǒng)上的.index文件),這種分區(qū)分段+索引的設(shè)計(jì),不僅提升了數(shù)據(jù)讀取的效率,同時(shí)也提高了數(shù)據(jù)操作的并行度(類似ConcurrentHashMap的分段鎖機(jī)制)。
批量壓縮&批量讀寫:多條消息一起壓縮進(jìn)行傳輸(比如gzip格式)與讀寫,節(jié)省帶寬
直接操作page cache:雖然Kafka是Java寫的,也基于JVM運(yùn)行,但Kafka的消息讀寫是直接操作操作系統(tǒng)頁(yè)存的,而不是在JVM的堆內(nèi)存,這樣就避免JVM的GC耗時(shí)及對(duì)象創(chuàng)建耗時(shí),且讀寫速度更高,JVM進(jìn)程重啟緩存也不會(huì)丟失
理解了Kafka的持久化機(jī)制是直接讀寫頁(yè)存+定時(shí)刷盤的方式,我們只需要設(shè)置刷盤策略即可在性能與可靠性上權(quán)衡。 Kafka提供3個(gè)參數(shù)來優(yōu)化刷盤機(jī)制:
log.flush.interval.messages //多少條消息刷盤1次
log.flush.interval.ms //隔多長(zhǎng)時(shí)間刷盤1次
log.flush.scheduler.interval.ms //周期性的刷盤。
總結(jié)一下關(guān)于框架類的面試題,最重要是得掌握技術(shù)框架的底層實(shí)現(xiàn)原理、適用場(chǎng)景,基本上回答出這兩方面就OK了,其它奇奇怪怪的細(xì)節(jié)問題要是答不出來,咱就引導(dǎo)面試官說出自己對(duì)框架的理解即可,畢竟細(xì)節(jié)的問題太多了。那怎么才算掌握呢?起碼能通過框架的特性,根據(jù)需要實(shí)現(xiàn)一個(gè)簡(jiǎn)易版本,比如說自己實(shí)現(xiàn)一個(gè)Spring框架、實(shí)現(xiàn)一個(gè)MQ組件等等。
由淺入深,化難為易。
審核編輯 :李倩
-
模型
+關(guān)注
關(guān)注
1文章
3486瀏覽量
49990 -
消息
+關(guān)注
關(guān)注
0文章
29瀏覽量
12958 -
網(wǎng)絡(luò)通訊
+關(guān)注
關(guān)注
0文章
77瀏覽量
11501
原文標(biāo)題:面試基操:MQ 怎么保障消息可靠性?
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
可靠性測(cè)試包括哪些測(cè)試和設(shè)備?

電子元器件可靠性檢測(cè)項(xiàng)目有哪些?

提供半導(dǎo)體工藝可靠性測(cè)試-WLR晶圓可靠性測(cè)試
電機(jī)微機(jī)控制系統(tǒng)可靠性分析
IGBT的應(yīng)用可靠性與失效分析

保障汽車安全:PCBA可靠性提升的關(guān)鍵要素
電路可靠性設(shè)計(jì)與工程計(jì)算技能概述

半導(dǎo)體集成電路的可靠性評(píng)價(jià)
一文讀懂芯片可靠性試驗(yàn)項(xiàng)目

霍爾元件的可靠性測(cè)試步驟
PCB高可靠性化要求與發(fā)展——PCB高可靠性的影響因素(上)
針對(duì)高可靠性應(yīng)用的電壓轉(zhuǎn)換

基于可靠性設(shè)計(jì)感知的EDA解決方案

汽車功能安全與可靠性的關(guān)系






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論