") Transformer模型的多模態(tài)學(xué)習(xí)應(yīng)用
Transformer模型的多模態(tài)學(xué)習(xí)應(yīng)用

導(dǎo)讀
隨著Transformer在視覺中的崛起,Transformer在多模態(tài)中應(yīng)用也是合情合理的事情,甚至以后可能會(huì)有更多的類似的paper。先來解釋一下什么多模態(tài),模態(tài)譯作modality,多模態(tài)譯作multimodel。多模態(tài)學(xué)習(xí)主要有一下幾個(gè)方向:表征、轉(zhuǎn)化、對齊、融合和協(xié)同學(xué)習(xí)。人就是生活在一個(gè)多模態(tài)的世界里面,文字、視覺、語言都是不同的模態(tài),當(dāng)我們能夠同時(shí)從視覺、聽覺、嗅覺等等來識別當(dāng)前發(fā)生的事情,實(shí)際上我們就是在做了多模態(tài)的融合。而Transformer is All You Need這篇論文(從Attention is All You Need開始大家都成了標(biāo)題黨,X is All You Need)是屬于協(xié)同學(xué)習(xí)(Co-learning)的范疇,將多個(gè)不同的tasks一起訓(xùn)練,共享模型參數(shù)。

背景介紹
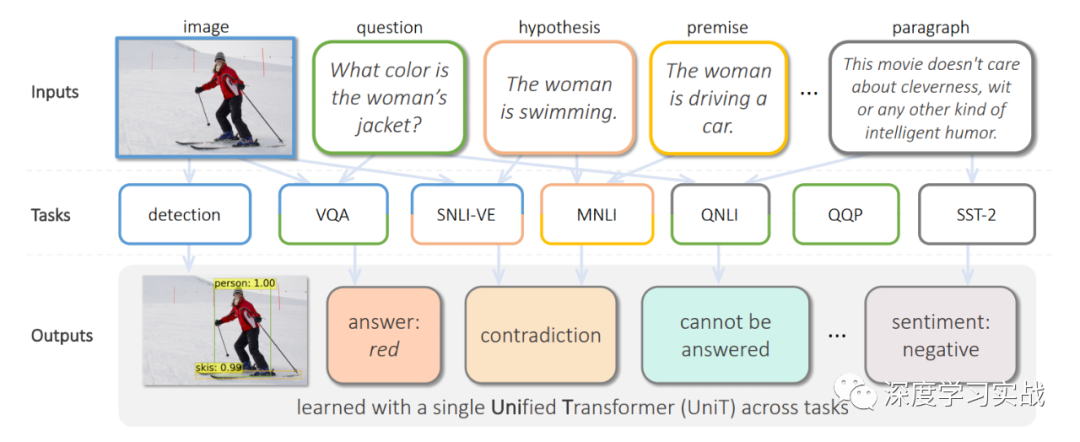
這篇論文出自Facebook AI Research,文章提出了UniT,Unified Transformer model,用一個(gè)Transformer模型去同時(shí)學(xué)習(xí)多個(gè)不同的tasks,甚至這些tasks的領(lǐng)域都可能不同,從目標(biāo)檢測到語言理解,一共訓(xùn)練了7個(gè)tasks8個(gè)datasets,但是各個(gè)beachmark上都取得了不錯(cuò)的成績。Transformer在各種不同的領(lǐng)域中都取得了極大的成功,例如NLP、images、video和audio,不僅在以上領(lǐng)域表現(xiàn)出色,甚至在一些vision-and-language reasoning的tasks上,比如VQA(visual question answering)也有很強(qiáng)的表現(xiàn)。但是現(xiàn)有的一些多模態(tài)的模型基本都是關(guān)注某一個(gè)領(lǐng)域的不同task或者就是用將近N倍的參數(shù)去處理N個(gè)不同的領(lǐng)域問題。在17年谷歌提出的《One Model To Learn Them All》[1]中也使用了Transformer encoder-decoder的架構(gòu),但是不同的是,它對于每個(gè)task都需要一個(gè)與之對應(yīng)的decoder,如下圖。類似的還有MT-DNN[2]和VILBERT-MT[3]等等。
UniT: One transformer to learn them all
用單個(gè)模型去訓(xùn)練跨模態(tài)的任務(wù),UniT包括對于不同的task對于的encoder,因?yàn)椴煌B(tài)的數(shù)據(jù)需要經(jīng)過處理才能放到同一個(gè)網(wǎng)絡(luò),就和人獲得不同模態(tài)的信息需要不同的器官一樣。然后這些信息會(huì)經(jīng)過一個(gè)共享decoder,最后各個(gè)task會(huì)有對應(yīng)的簡單的head進(jìn)行最后的輸出。UniT有兩種不同模態(tài)的輸入:圖像和文本。也就是說只需要兩個(gè)對應(yīng)的encoder就可以訓(xùn)練7種不同的任務(wù),可以形象地比喻這個(gè)網(wǎng)絡(luò)有兩個(gè)不同的器官(Image encoder和Text encoder)。
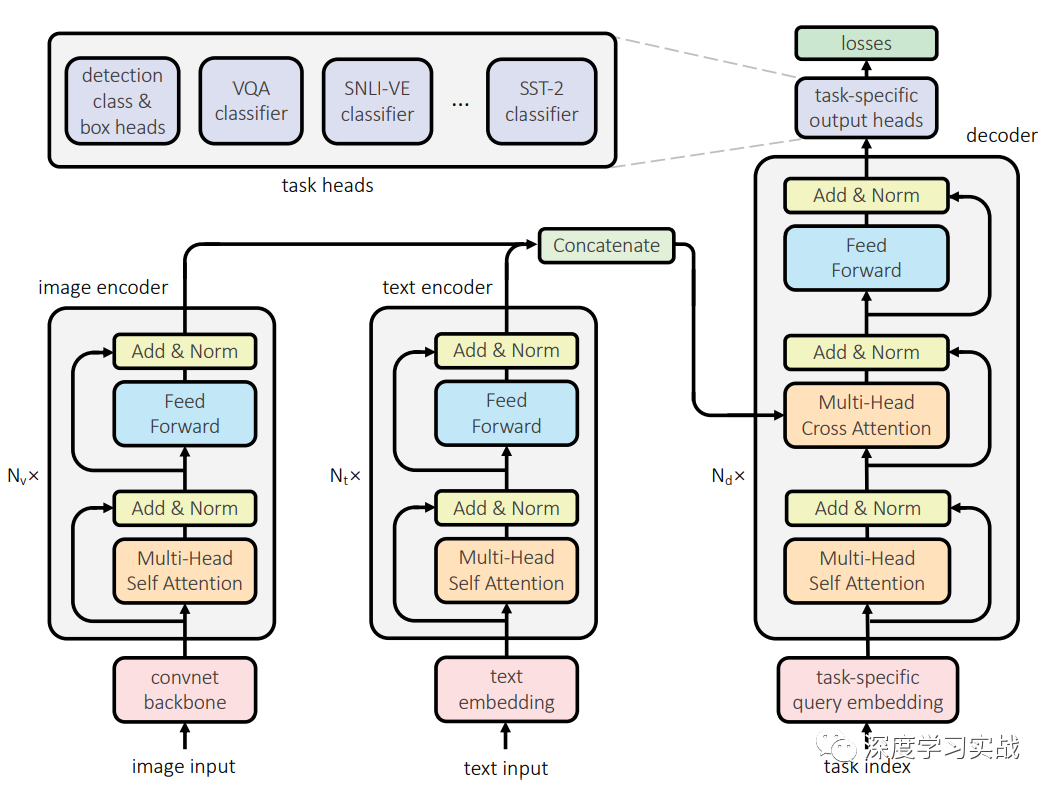
Image encoder一些視覺相關(guān)的task,比如目標(biāo)檢測、視覺問答等都需要處理圖像,在UniT中,圖像先經(jīng)過一個(gè)卷積的backbone,然后再用transformer對特征進(jìn)行編碼,進(jìn)一步得到編碼后的向量。圖像的處理與DETR[4]類似。xv=B(I),xv是經(jīng)過卷積神經(jīng)網(wǎng)絡(luò)B得到的特征圖,B采用了ResNet-50,并在C5中使用了空洞卷積。再用encoder Ev得到圖像編碼的向量,這里使用encoder進(jìn)行編碼時(shí)為了區(qū)別不同的task加入了task embedding以進(jìn)行區(qū)分,和IPT中的作法類似,因?yàn)椴煌膖ask它可能關(guān)注的點(diǎn)不一樣。
Text encoder對于文本的輸入,采用BERT來進(jìn)行編碼,BERT是一個(gè)在大規(guī)模語料庫上預(yù)訓(xùn)練好的模型。給定輸入的文本,和BERT處理一樣,先將文本編碼成tokens的序列{w1, · · · , wS},和image encoder一樣,還需要加入一個(gè)wtask來區(qū)分不同的task。在實(shí)現(xiàn)中,采用了embedding維度是768,12層的BERT。
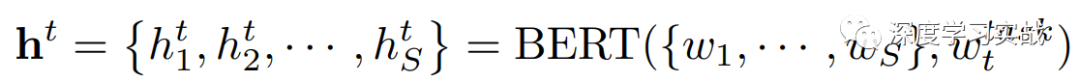
Domain-agnostic UniT decoder領(lǐng)域不可知的解碼器,和image和text encoder不一樣的是encoder是針對某一特定領(lǐng)域的,但是encoder的輸入可以是來自與image encoder或者是text encoder,所以是領(lǐng)域不可知。對于純視覺、純文本和視覺文本混合的task,encoder的輸入是不一樣的,純視覺和純文本的task的情況下,decoder的輸入就是它們各自encoder的輸出,但是對于視覺文本的task,decoder的輸入是兩個(gè)encoder輸出的拼接,這很好理解,因?yàn)樾枰猇QA這種同時(shí)會(huì)有image和text的輸入。
Task-specific output heads每個(gè)task可能最后的輸出差別很大,因此最后使用對應(yīng)的prediction head來進(jìn)行最后的預(yù)測。對于檢測任務(wù)來說,最后decoder產(chǎn)生的每個(gè)向量都會(huì)produce一個(gè)輸出,輸出包括類別和bounding box。當(dāng)然,對于不同的task,decoder輸入的query是不同的。
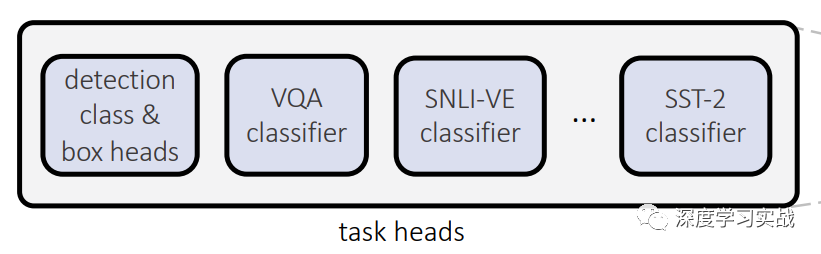
Experiments
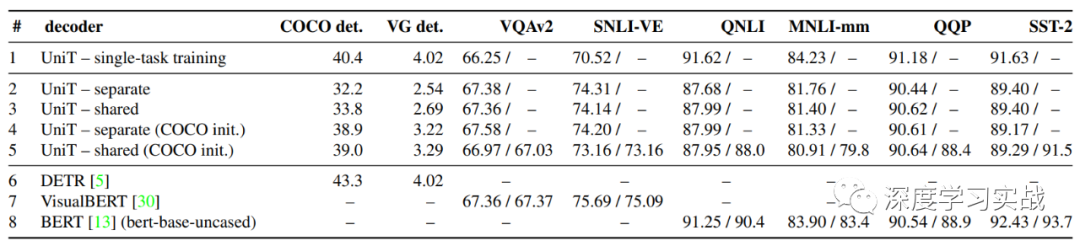
下圖是所用到的8個(gè)不同的數(shù)據(jù)集以及上面的測試結(jié)果,可以看到不同任務(wù)的區(qū)別還是很大的。
根據(jù)下圖的對比,其實(shí)UniT有些task離SOTA還是差的有點(diǎn)遠(yuǎn),所以這個(gè)領(lǐng)域還是有很大的挖掘的空間的。
Conclusion
在這篇論文中,我們可以看到,Transformer確實(shí)是可以來處理不同的領(lǐng)域的,跨領(lǐng)域?qū)W習(xí)確實(shí)是個(gè)很大的難題,那么Transformer能否成為多模態(tài)領(lǐng)域發(fā)展的一個(gè)跳板呢?我們拭目以待。
Reference論文鏈接:https://arxiv.org/abs/2102.10772
編輯:lyn
-
視覺
+關(guān)注
關(guān)注
1文章
163瀏覽量
24361 -
paper
+關(guān)注
關(guān)注
0文章
7瀏覽量
3819 -
Transformer
+關(guān)注
關(guān)注
0文章
151瀏覽量
6513
原文標(biāo)題:Facebook提出UniT:Transformer is All You Need
文章出處:【微信號:gh_a204797f977b,微信公眾號:深度學(xué)習(xí)實(shí)戰(zhàn)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
商湯日日新SenseNova融合模態(tài)大模型 國內(nèi)首家獲得最高評級的大模型
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態(tài)大模型

海康威視發(fā)布多模態(tài)大模型AI融合巡檢超腦
海康威視發(fā)布多模態(tài)大模型文搜存儲系列產(chǎn)品
2025年Next Token Prediction范式會(huì)統(tǒng)一多模態(tài)嗎

商湯日日新多模態(tài)大模型權(quán)威評測第一
一文理解多模態(tài)大語言模型——下

一文理解多模態(tài)大語言模型——上

利用OpenVINO部署Qwen2多模態(tài)模型
云知聲山海多模態(tài)大模型UniGPT-mMed登頂MMMU測評榜首






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論