") 基于端到端的自動駕駛系統(tǒng)只能做demo嗎
基于端到端的自動駕駛系統(tǒng)只能做demo嗎
劍橋大學工程系團隊創(chuàng)辦的Wayve憑借機器學習算法,只需要使用攝像頭和基本的衛(wèi)星導航就可以實現(xiàn)自動駕駛汽車在陌生的道路上行駛。
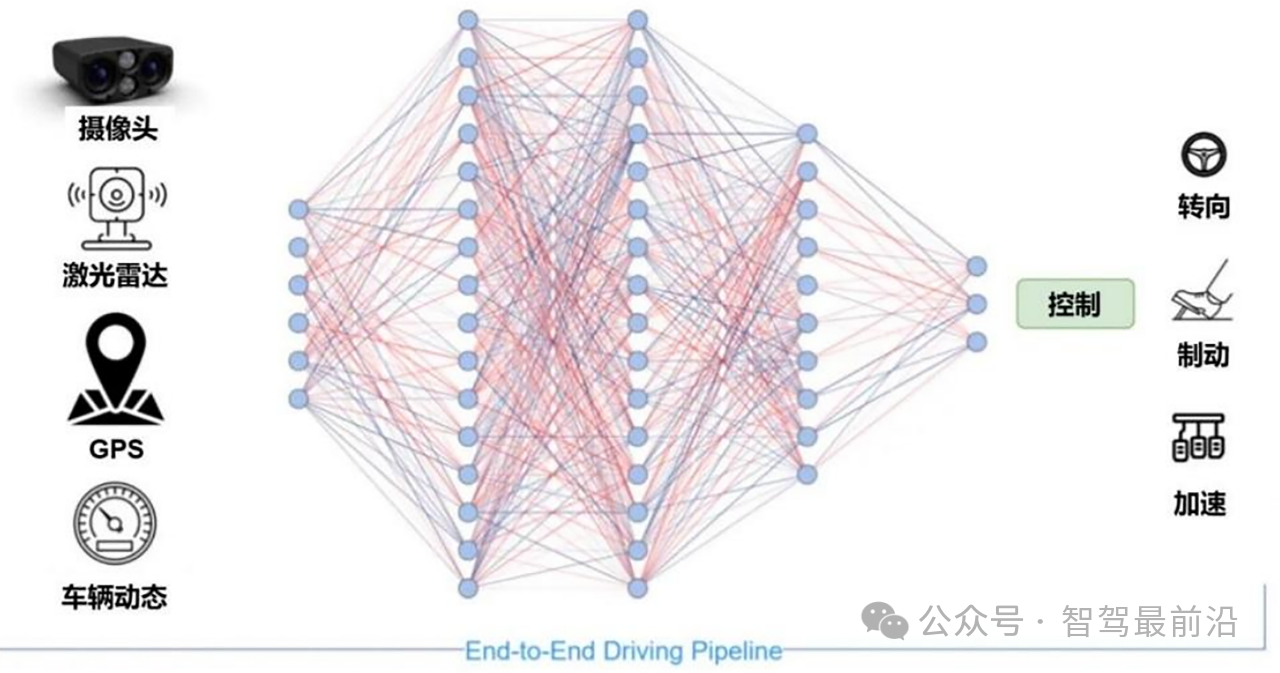
自從2016年,英偉達公開了用于自動駕駛汽車的端到端深度學習技術之后,已經(jīng)有不計其數(shù)的公司、單位甚至愛好者用此技術做出自動駕駛的demo。簡單網(wǎng)絡結構,可以實現(xiàn)攝像頭輸入到剎車油門方向盤輸出的直接映射。然而這種低門檻也注定了它可以解決的問題并不多,很難應對具體駕駛環(huán)境上的復雜性。有專家甚至認為端到端不適合開發(fā)實用無人駕駛系統(tǒng),可以做demo,大規(guī)模商用可能非常困難。
端到端只配做demo嗎?由劍橋大學團隊創(chuàng)辦的Wayve無人駕駛軟件公司卻不這么認為。他們沒有用高精地圖,也沒有用激光雷達等昂貴的傳感器,當然也沒有給汽車手工輸入規(guī)則,只訓練20小時數(shù)據(jù),就可以在從未跑過的道路上駕駛。
Wayve 研發(fā)團隊認為既然是自動駕駛,就不需要手工編碼一些規(guī)定,要充分的展現(xiàn)其智能的特性。團隊采用了當下大熱的深度學習強化學習算法,建立了一個可以像人類一樣慢慢學習駕駛的自動駕駛系統(tǒng)。
經(jīng)過探索、優(yōu)化和評估三個步驟進行迭代,采用深度確定性策略梯度(Deep deterministic policy gradients,DDPG),來解決車道保持問題。
現(xiàn)有技術的圖像分類體系結構具有數(shù)百萬個參數(shù),而Wayve團隊的網(wǎng)絡構架是一個深度網(wǎng)絡,有4個卷積層和3個完全連接層,總共只有不到1萬個參數(shù),所有處理都在汽車GPU上執(zhí)行。
在強化學習仿真測試中,通過隨機生成曲線車道,以及道路紋理和車道標記,然后根據(jù)收集的數(shù)據(jù)優(yōu)化策略,再不斷重復。
結合了圖像翻譯和行為克隆的端到端零鏡頭框架
大多數(shù)自駕車公司使用模擬來驗證他們的系統(tǒng),而Wayve讓自動駕駛汽車在仿真中廣泛學習如何處理罕見的邊緣情況。Wayve訓練汽車進行模擬駕駛,并將學到的知識轉化到現(xiàn)實世界。
Wayve沒有將模擬和現(xiàn)實世界視為兩個不同的領域,而是設計了一個框架,將兩者結合起來,既可以在模擬中訓練轉向決策,又可以在現(xiàn)實世界中展現(xiàn)出類似的行為而無需進行真正的演示。
Wayve的模型由一對最初用于圖像轉換的卷積變分自動編碼器式的網(wǎng)絡組成,用于圖像翻譯,即無監(jiān)督圖像到圖像的翻譯網(wǎng)絡(Unsupervised Image-to-Image Translation Networks, UNIT))。在兩個域之間沒有任何已知的對齊或對應關系的情況下,模型能夠在它們之間進行轉換。下圖是一個捕捉場景主要布局的例子。值得注意的是,模擬器的視覺保真度在學習駕駛時并不是最重要的,他們的模擬世界就像卡通一樣,依舊可以很好的完成仿真模擬。Wayve研究稱,內(nèi)容保真度比視覺保真度更重要。但是,有效地模擬其他交通參與者的行為仍然是一個巨大的挑戰(zhàn)。
基于真實世界的駕駛數(shù)據(jù)和精心設計的邊緣案例來模擬場景
汽車由基于模型的深層強化學習系統(tǒng)驅動,該算法從離線收集的真實數(shù)據(jù)中學習預測模型。這讓模型學習并使用預測模型所想象的新場景數(shù)據(jù)來訓練駕駛。
Wayve致力于開發(fā)更豐富,更強大的時態(tài)預測模型,并相信這是構建智能安全自動駕駛汽車的關鍵。
目前,該系統(tǒng)已經(jīng)部署在 JaguarI-PACE 車上。這輛車贏得了2019年度歐洲年度車型的稱號,未來將在整個英國和歐洲大陸收集數(shù)據(jù)。當下,讓數(shù)據(jù)逐漸積累,其驅動算法可能達到人類駕駛員質量的95%,能夠處理交通燈,環(huán)形交叉路口,十字路口等。
盡管有人會覺得端到端的自動駕駛系統(tǒng),既不聰明也不靈活,發(fā)生問題難以解釋,然而Wayve在用其強大的算法證明這種深度學習的技術不只可以做demo,未來也可以保證安全,也可以商用。
審核編輯 黃昊宇
-
機器人
+關注
關注
213文章
29489瀏覽量
211558 -
自動駕駛
+關注
關注
788文章
14198瀏覽量
169531
發(fā)布評論請先 登錄
一文帶你厘清自動駕駛端到端架構差異
自動駕駛中基于規(guī)則的決策和端到端大模型有何區(qū)別?
東風汽車推出端到端自動駕駛開源數(shù)據(jù)集
技術分享 |多模態(tài)自動駕駛混合渲染HRMAD:將NeRF和3DGS進行感知驗證和端到端AD測試

動量感知規(guī)劃的端到端自動駕駛框架MomAD解析
DiffusionDrive首次在端到端自動駕駛中引入擴散模型

端到端自動駕駛技術研究與分析
端到端在自動泊車的應用
連接視覺語言大模型與端到端自動駕駛

Waymo利用谷歌Gemini大模型,研發(fā)端到端自動駕駛系統(tǒng)

實現(xiàn)自動駕駛,唯有端到端?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論