") 進(jìn)行RTL代碼設(shè)計(jì)需要考慮時(shí)序收斂的問(wèn)題
進(jìn)行RTL代碼設(shè)計(jì)需要考慮時(shí)序收斂的問(wèn)題
引言
硬件描述語(yǔ)言(verilog,systemVerilog,VHDL等)不同于軟件語(yǔ)言(C,C++等)的一點(diǎn)就是,代碼對(duì)應(yīng)于硬件實(shí)現(xiàn),不同的代碼風(fēng)格影響硬件的實(shí)現(xiàn)效果。好的代碼風(fēng)格能讓硬件“跑得更快”,而一個(gè)壞的代碼風(fēng)格則給后續(xù)時(shí)序收斂造成很大負(fù)擔(dān)。你可能要花費(fèi)很長(zhǎng)時(shí)間去優(yōu)化時(shí)序,保證時(shí)序收斂。拆解你的代碼,添加寄存器,修改走線,最后讓你原來(lái)的代碼“遍體鱗傷”。這一篇基于賽靈思的器件來(lái)介紹一下如何在開(kāi)始碼代碼的時(shí)候就考慮時(shí)序收斂的問(wèn)題,寫(xiě)出一手良好的代碼。
1. Counter結(jié)構(gòu)
計(jì)數(shù)器是在FPGA設(shè)計(jì)中經(jīng)常要用到的結(jié)構(gòu),比如在AXI總線中對(duì)接收數(shù)據(jù)量的計(jì)算,用計(jì)數(shù)器來(lái)產(chǎn)生地址和last等信號(hào)。在計(jì)數(shù)器中需要用到進(jìn)位鏈,進(jìn)位鏈?zhǔn)怯绊憰r(shí)序的主要因素。如果進(jìn)位鏈越長(zhǎng),那么組合邏輯的級(jí)數(shù)就越高,組合邏輯延遲越大,能夠支持的最大時(shí)鐘頻率就會(huì)越低。在一個(gè)CLB中通常會(huì)含有一個(gè)進(jìn)位鏈結(jié)構(gòu),比如在ultrascale中是CARRY8,在zynq7系列中是CARRY4,CARRY4可以實(shí)現(xiàn)4bit進(jìn)位。如果是一個(gè)48bit計(jì)數(shù)器就需要12個(gè)這樣的進(jìn)位結(jié)構(gòu)。一個(gè)CARRY4輸出有兩種CO和O,CO是進(jìn)位bit,用于級(jí)聯(lián)到下一級(jí)的CARRY4的CI,O是結(jié)果輸出。因此我們可以看到在計(jì)數(shù)器中最下的進(jìn)位結(jié)構(gòu)是CARRY4,如果直接讓多個(gè)進(jìn)位結(jié)構(gòu)級(jí)聯(lián),那么組合邏輯就會(huì)變大,時(shí)序延遲就會(huì)增大。如果可以將計(jì)數(shù)器拆分成小的計(jì)數(shù)器,那么時(shí)序就可以得到改善。
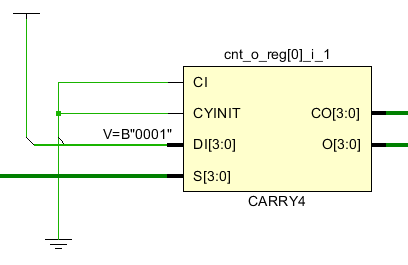
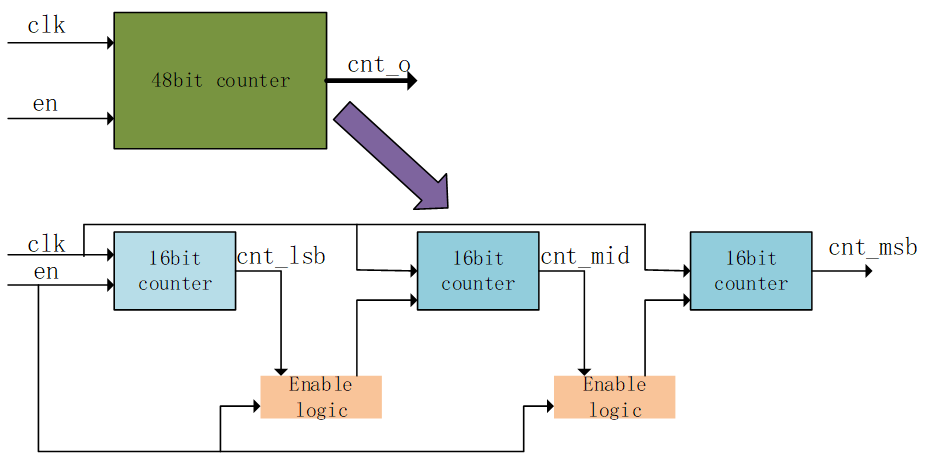
比如一個(gè)48bit計(jì)數(shù)器拆分成3個(gè)16bit計(jì)數(shù)器,那么CARRY4的級(jí)聯(lián)級(jí)別就從原來(lái)的12個(gè)降低到4個(gè)。每4個(gè)之間增加了FF來(lái)進(jìn)行時(shí)序改善。
always @(posedge clk)begin
if(rst)
cnt_o <= 0;
else
cnt_o <= cnt_o + 1;
end
拆分后代碼為:
genvar i;
generate
for(i=0;i<3;i=i+1)begin: CNT_LOOP
wire trigger_nxt, trigger_pre;
if(i == 0)begin
always @(posedge clk)begin
if(rst)
cnt_o[i*16 +: 16] <= 0;
else
cnt_o[i*16 +: 16] <= cnt_o[i*16 +: 16] + 1;
end
assign trigger_nxt = (cnt_o[i*16 +: 16] == 16'hFFFF) ? 1 : 0;
end//if
else begin
assign trigger_pre = CNT_LOOP[i-1].trigger_nxt;
always @(posedge clk)begin
if(rst)
cnt_o[i*16 +: 16] <= 0;
else if(trigger_pre)
cnt_o[i*16 +: 16] <= cnt_o[i*16 +: 16] + 1;
end
assign trigger_nxt = CNT_LOOP[i-1].trigger_nxt && (cnt_o[i*16 +: 16] == 16'hFFFF);
end//else
end//for
endgenerate
綜合后我們就可以看到它的schematic每4個(gè)CARRY4都被FF隔開(kāi)了,可以降低邏輯延時(shí)。但是代價(jià)是增加了LUT的數(shù)量,這些LUT是用來(lái)判斷前一個(gè)16bit計(jì)數(shù)器的數(shù)值的,從而驅(qū)動(dòng)后邊16bit寄存器計(jì)數(shù)。
2. 邏輯拆分
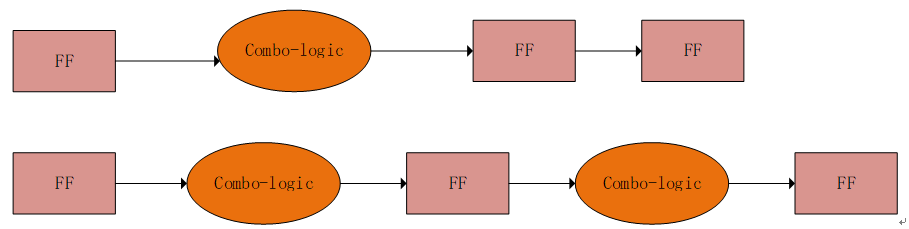
在上一節(jié)中拆解計(jì)數(shù)器本質(zhì)上就是在拆分組合邏輯。當(dāng)一個(gè)組合邏輯過(guò)大的時(shí)候,延時(shí)較大。將其拆解成兩個(gè)或者兩個(gè)以上邏輯,中間增加寄存器可以來(lái)提高能跑得時(shí)鐘頻率。比如下圖有一個(gè)較大的組合邏輯,前邊有一個(gè)FF,后邊連續(xù)接2個(gè)FF。組合邏輯的延時(shí)就成為了整體時(shí)鐘頻率的一個(gè)關(guān)鍵路徑。如果我們可以將其拆分成兩個(gè),中間用一級(jí)寄存器連接,這樣總共的時(shí)鐘周期還是3個(gè),但是時(shí)鐘頻率明顯會(huì)好于前一種。
3. 改善扇出
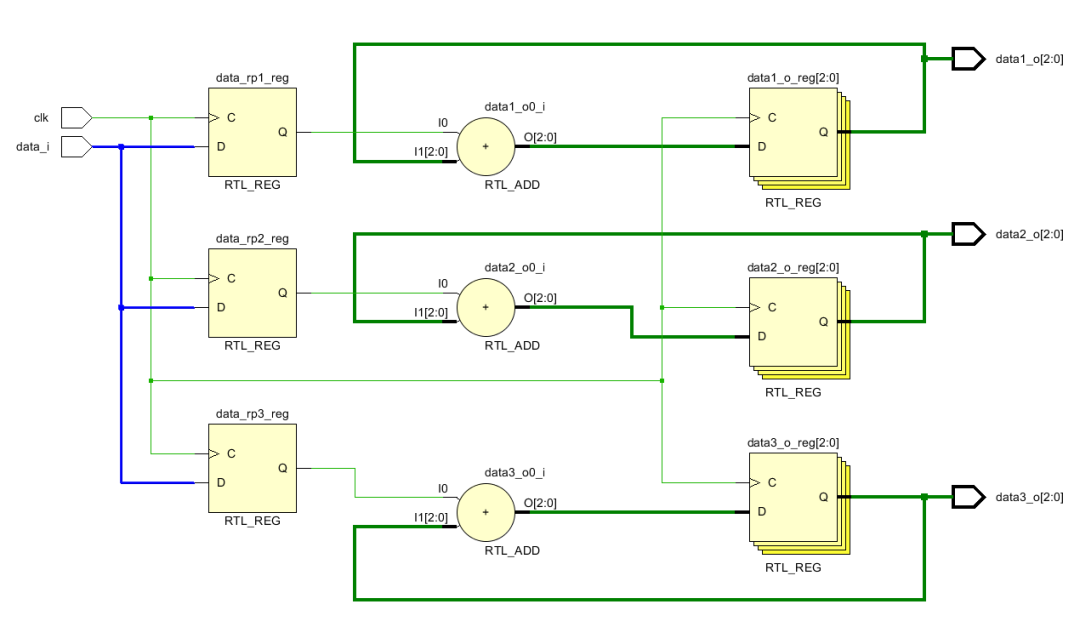
扇出是指某個(gè)信號(hào)驅(qū)動(dòng)的信號(hào)的數(shù)量。驅(qū)動(dòng)的信號(hào)越多,那么要求其產(chǎn)生的電流越大。學(xué)過(guò)數(shù)字電路就會(huì)知道,當(dāng)一個(gè)信號(hào)輸出連接的越多的時(shí)候,其輸出負(fù)載就會(huì)越小,那么輸出電壓就會(huì)減小。所以如果信號(hào)扇出過(guò)大就會(huì)影響到高低電平,最終就會(huì)導(dǎo)致時(shí)序不收斂。另外一個(gè)原因是如果信號(hào)扇出過(guò)大,那么由于FPGA上走線路徑的差異,就可能造成這個(gè)信號(hào)到達(dá)不同地址的延遲不同,造成時(shí)序不同步。一種解決辦法是復(fù)制,將扇出較大的信號(hào)復(fù)制幾份,這樣就可以減小扇出。比如一個(gè)輸入d_i需要和3個(gè)數(shù)進(jìn)行求和。那么這個(gè)信號(hào)扇出就是3.如果將其復(fù)制3份,給每個(gè)數(shù)輸送一份,那么扇出就變?yōu)?。
always @(posedge clk)begin
data1_o <= data_i + data1_o;
data2_o <= data_i + data2_o;
data3_o <= data_i + data3_o;
end
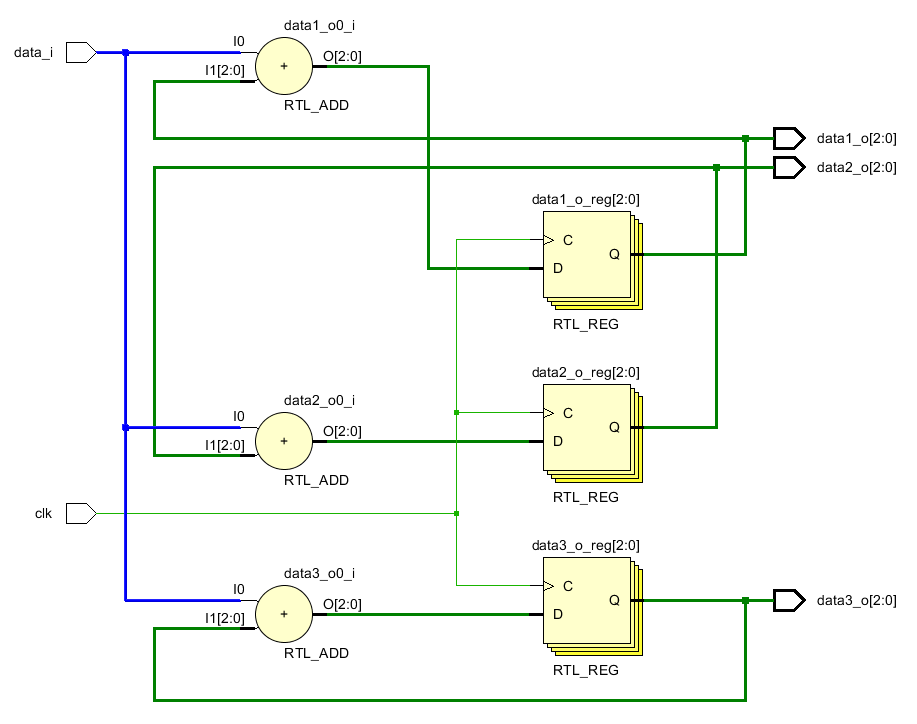
如果我們復(fù)制輸入數(shù)據(jù),如下圖,從中可以看出輸入信號(hào)復(fù)制了三份,分別接給三個(gè)加法器。
(* keep = "true" *)reg data_rp1;
(* keep = "true" *)reg data_rp2;
(* keep = "true" *)reg data_rp3;
always @(posedge clk)begin
data_rp1 <= data_i;
data_rp2 <= data_i;
data_rp3 <= data_i;
data1_o <= data_rp1 + data1_o;
data2_o <= data_rp2 + data2_o;
data3_o <= data_rp3 + data3_o;
end
4. URAM和BRAM使用
Xilinx器件中BRAM的大小是36Kbit,如果不使用校驗(yàn)位,可以配置成1-32bit位寬的存儲(chǔ)。比如32x1K。在RTL代碼中使用存儲(chǔ)的時(shí)候,需要適配BRAM大小,這樣可以不浪費(fèi)BRAM存儲(chǔ)空間。比如你需要使用一個(gè)FIFO,那么這個(gè)FIFO位寬32bit,那么它的深度512和1024配置,都消耗了一個(gè)BRAM。
BRAM輸出中最好用register,不要直接接組合邏輯,這樣會(huì)增加延時(shí)。BRAM中含有register,如果代碼中輸出有用到register,那么這個(gè)register在綜合時(shí)會(huì)被移到BRAM內(nèi)部。如果BRAM外要連接組合邏輯,最好在BRAM的register的外部在添加一個(gè)register,這樣有更好的時(shí)序。
當(dāng)我們需要的存儲(chǔ)空間和位寬都超過(guò)了一個(gè)BRAM的時(shí)候,就涉及到多個(gè)BRAM的級(jí)聯(lián)問(wèn)題。如何選擇單個(gè)BRAM的位寬拼接和級(jí)聯(lián)BRAM的個(gè)數(shù)呢?比如我們要一個(gè)32bit位寬,深度為2**15大小的存儲(chǔ)。有兩種極限方式來(lái)配置BRAM。一種是將每個(gè)BRAM配置為1x32K,那么32個(gè)拼接組成32x32K的存儲(chǔ)。另外一種是將每個(gè)BRAM設(shè)置為32x1K,那么32個(gè)級(jí)聯(lián)形成32K深度。前一種不需要多余邏輯來(lái)對(duì)不同BRAM進(jìn)行選擇操作,但是32個(gè)BRAM同時(shí)讀寫(xiě),這樣會(huì)增加power。而后一種32個(gè)BRAM級(jí)聯(lián)在一起造成延時(shí)路徑較長(zhǎng),同時(shí)需要增加組合邏輯來(lái)選擇不同BRAM。但是每次只讀寫(xiě)一個(gè)BRAM,power較低。可以選擇這兩個(gè)極限的中間值來(lái)即降低power也不會(huì)有太長(zhǎng)的邏輯延時(shí)。可以通過(guò)約束條件來(lái)進(jìn)行設(shè)置。如下圖。級(jí)聯(lián)設(shè)置為4,這樣每次只有8個(gè)BRAM同時(shí)使能。
(* ram_style = "block", cascade_height = 4 *) reg [31:0] mem[2**15-1:0]; reg [14:0] addr_reg; always @(posedge clk)begin addr_reg <= addr; dout <= mem[addr_reg]; if(we) mem[addr_reg] <= din; end
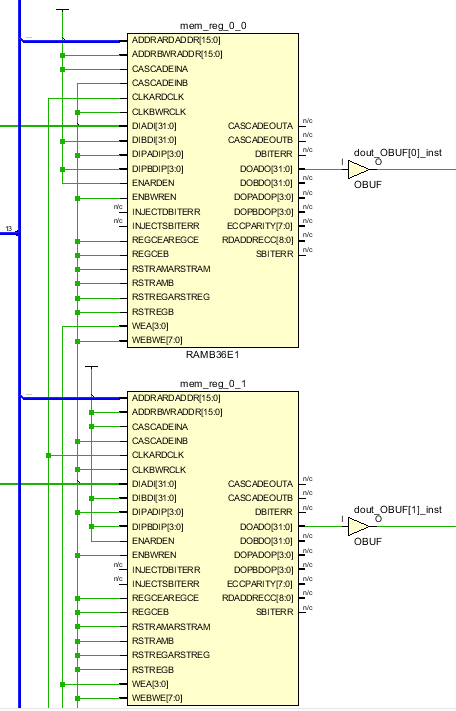
URAM的使用方式類(lèi)似,只不過(guò)URAM存儲(chǔ)空間比BRAM大,其可以配置為72x64K大小。
5. 其它
1) 進(jìn)行條件判定的時(shí)候,如果條件過(guò)多,盡量減少if-else語(yǔ)句的使用,盡可能用case替代。因?yàn)閕f-else是有優(yōu)先級(jí)的,而case條件判斷的平等的。前者會(huì)用掉更多邏輯;
2) 在一個(gè)always塊中盡量對(duì)一個(gè)信號(hào)賦值,不要對(duì)具有不同判斷條件的信號(hào)同時(shí)賦值,這樣可以減少不必要的邏輯;
3) 盡量使用時(shí)鐘同步復(fù)位,不要使用異步復(fù)位。即要用:
always @(posedge clk)begin
If(rst)
End
而不是
always @(posedge clk or posedge rst)
4) 在使用乘法較多的時(shí)候,使用DSP原語(yǔ)是最好的。一個(gè)DSP除了有乘法功能外,還有前加法器和后加法器,這兩個(gè)是經(jīng)常用到的,可以用來(lái)計(jì)算很多功能。DSP的具體使用可以參考DSP的手冊(cè)。
總結(jié)
以上總結(jié)了幾點(diǎn)在進(jìn)行RTL代碼設(shè)計(jì)時(shí),最需要考慮的幾種情況。這些對(duì)時(shí)序影響很大,需要注意。另外從整體來(lái)講,如何選擇一個(gè)好的算法,然后設(shè)計(jì)出一個(gè)簡(jiǎn)潔的架構(gòu)更加重要。因?yàn)檫@些是從整體讓你的設(shè)計(jì)有更多靈活的空間。
-
FPGA
+關(guān)注
關(guān)注
1643文章
21957瀏覽量
614026 -
寄存器
+關(guān)注
關(guān)注
31文章
5421瀏覽量
123315 -
RTL
+關(guān)注
關(guān)注
1文章
388瀏覽量
60662 -
AXI總線
+關(guān)注
關(guān)注
0文章
66瀏覽量
14499
發(fā)布評(píng)論請(qǐng)先 登錄
利用AMD VERSAL自適應(yīng)SoC的設(shè)計(jì)基線策略
TDengine 發(fā)布時(shí)序數(shù)據(jù)分析 AI 智能體 TDgpt,核心代碼開(kāi)源
一文詳解Vivado時(shí)序約束
ADS1675進(jìn)行高速采集的程序,看時(shí)序圖應(yīng)該會(huì)使用PLL進(jìn)行3倍頻,但是這個(gè)PLL需要配置嗎?
選擇貼片電感型號(hào)時(shí)需要考慮什么參數(shù)?

如何創(chuàng)建虛擬時(shí)鐘
使用IBIS模型進(jìn)行時(shí)序分析

高速ADC與FPGA的LVDS數(shù)據(jù)接口中避免時(shí)序誤差的設(shè)計(jì)考慮
使用MXO58示波器輕松進(jìn)行電源時(shí)序分析
RTL8187L和802.11n
優(yōu)化 FPGA HLS 設(shè)計(jì)
聚徽觸控-選擇工控機(jī)需要考慮的問(wèn)題都有哪些
FPGA的學(xué)習(xí)筆記---FPGA的開(kāi)發(fā)流程
FPGA 高級(jí)設(shè)計(jì):時(shí)序分析和收斂
PCB電源設(shè)計(jì)需要考慮的九大因素!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論