") 如何利用衛(wèi)星圖像對(duì)儲(chǔ)油罐的體積進(jìn)行估計(jì)
如何利用衛(wèi)星圖像對(duì)儲(chǔ)油罐的體積進(jìn)行估計(jì)
在1957年以前,地球上只有一顆天然衛(wèi)星:月球。1957年10月4日,蘇聯(lián)發(fā)射了世界上第一顆人造衛(wèi)星,從那時(shí)起,來(lái)自40多個(gè)國(guó)家大約有8900顆衛(wèi)星發(fā)射升空。
這些衛(wèi)星可以幫助我們進(jìn)行監(jiān)視、通信、導(dǎo)航等等。國(guó)家可以利用衛(wèi)星監(jiān)視另一個(gè)國(guó)家的土地及其動(dòng)向,估計(jì)其經(jīng)濟(jì)和實(shí)力,然而所有的國(guó)家都互相隱瞞著他們的信息。同理,全球石油市場(chǎng)也并非完全透明,幾乎所有的產(chǎn)油國(guó)都在努力隱藏著自己的總產(chǎn)量、消費(fèi)量和儲(chǔ)存量,各國(guó)這樣做是為了間接地向外界隱瞞其實(shí)際經(jīng)濟(jì),并增強(qiáng)其國(guó)防系統(tǒng)的能力,這種做法可能會(huì)對(duì)其他國(guó)家造成威脅。出于這個(gè)原因,許多初創(chuàng)公司,如Planet和Orbital Insight,都通過(guò)衛(wèi)星圖像來(lái)關(guān)注各國(guó)的此類(lèi)活動(dòng)。通過(guò)收集儲(chǔ)油罐的衛(wèi)星圖像來(lái)估算石油儲(chǔ)量。但問(wèn)題是,如何僅憑衛(wèi)星圖像來(lái)估計(jì)儲(chǔ)油罐的體積呢?首先第一個(gè)條件是儲(chǔ)油罐為浮頂油罐,因?yàn)橹挥羞@樣,衛(wèi)星才能檢測(cè)到。這種特殊類(lèi)型的油罐是專(zhuān)門(mén)為儲(chǔ)存大量石油產(chǎn)品而設(shè)計(jì)的,如原油或凝析油,它由頂蓋組成,直接位于油的頂部,隨著油箱中油量的增加或下降,并在其周?chē)纬蓛蓚€(gè)陰影。如下圖所示,陰影位于北側(cè)

(外部陰影)是指儲(chǔ)罐的總高度,而儲(chǔ)罐內(nèi)的陰影(內(nèi)部陰影)表示浮頂?shù)纳疃龋w積可估計(jì)計(jì)算為1-(內(nèi)部陰影區(qū)域/外部陰影區(qū)域)。在本文,我們將使用Tensorflow2.x框架,在衛(wèi)星圖像的幫助下,使用python從零開(kāi)始實(shí)現(xiàn)一個(gè)完整的模型來(lái)估計(jì)儲(chǔ)油罐的占用量。GitHub倉(cāng)庫(kù)本文的所有內(nèi)容和整個(gè)代碼都可以在這個(gè)github存儲(chǔ)庫(kù)中找到https://github.com/mdmub0587/Oil-Storage-Tank-s-Volume-Occupancy以下是本文目錄。我們會(huì)逐一探索。目錄
問(wèn)題陳述、數(shù)據(jù)集和評(píng)估指標(biāo)
現(xiàn)有方法
相關(guān)研究工作
有用的博客和研究論文
我們的貢獻(xiàn)
探索性數(shù)據(jù)分析(EDA)
數(shù)據(jù)擴(kuò)充
數(shù)據(jù)預(yù)處理、擴(kuò)充和TFRecords
基于YoloV3的目標(biāo)檢測(cè)
儲(chǔ)量估算
結(jié)果
結(jié)論
今后的工作
參考引用
1.問(wèn)題陳述、數(shù)據(jù)集和評(píng)估指標(biāo)
問(wèn)題陳述:利用衛(wèi)星圖像進(jìn)行浮頂油罐的檢測(cè)和儲(chǔ)油量的估算,然后將圖像塊重新組合成具有儲(chǔ)油量估計(jì)的全圖像。數(shù)據(jù)集:數(shù)據(jù)集鏈接:https://www.kaggle.com/towardsentropy/oil-storage-tanks該數(shù)據(jù)集包含一個(gè)帶注釋的邊界框,衛(wèi)星圖像是從谷歌地球(google earth)拍攝的,它包含有世界各地的工業(yè)區(qū)。數(shù)據(jù)集中有2個(gè)文件夾和3個(gè)文件,讓我們逐一看看。large_images: 這是一個(gè)文件夾,包含100個(gè)衛(wèi)星原始圖像,每個(gè)大小為4800x4800,所有圖像都以id_large.jpg格式命名。Image_patches: Image_patches目錄包含從大圖像生成的512x512大小的子圖,每個(gè)大的圖像被分割成100個(gè)512x512大小的子圖,兩個(gè)軸上的子圖之間有37個(gè)像素的重疊,生成圖像子圖的程序以id_row_column.jpg格式命名**labels.json:**它包含所有圖像的標(biāo)簽。標(biāo)簽存儲(chǔ)為字典列表,每個(gè)圖像對(duì)應(yīng)一個(gè)字典,不包含任何浮頂罐的圖像將被標(biāo)記為“skip”,邊界框標(biāo)簽的格式為邊界框四個(gè)角的(x,y)坐標(biāo)。labels_coco.json: 它包含與前一個(gè)文件相同的標(biāo)簽的COCO標(biāo)簽格式。在這里,邊界框的格式為[x_min, y_min, width, height].**large_image_data.csv:**它包含大型圖像文件的元數(shù)據(jù),包括每個(gè)圖像的中心坐標(biāo)和海拔高度。評(píng)估指標(biāo):對(duì)于儲(chǔ)油罐的檢測(cè),我們將使用每種儲(chǔ)油罐的平均精度(Average Precision,AP)和各種儲(chǔ)油罐的mAP(Mean Average Precision,平均精度)來(lái)作為評(píng)估指標(biāo)。浮頂罐的估計(jì)容積沒(méi)有度量標(biāo)準(zhǔn)。mAP 是目標(biāo)檢測(cè)模型的標(biāo)準(zhǔn)評(píng)估指標(biāo)。mAP 的詳細(xì)說(shuō)明可以在下面的youtube播放列表中找到https://www.youtube.com/watch?list=PL1GQaVhO4f_jE5pnXU_Q4MSrIQx4wpFLM&v=e4G9H18VYmA
2.現(xiàn)有方法
Karl Keyer [1]在他的存儲(chǔ)庫(kù)中使用RetinaNet來(lái)完成儲(chǔ)油罐探測(cè)任務(wù)。他從頭開(kāi)始創(chuàng)建模型,并將生成的錨框應(yīng)用于該數(shù)據(jù)集,他的研究使得浮頂罐的平均精度(AP)達(dá)到76.3%,然后他應(yīng)用陰影增強(qiáng)和像素閾值法來(lái)計(jì)算它的體積。據(jù)我所知,這是互聯(lián)網(wǎng)上唯一可用的方法。
3.相關(guān)研究工作
Estimating the Volume of Oil Tanks Based on High-Resolution Remote Sensing Images [2]:這篇文章提出了一種基于衛(wèi)星圖像的油罐容量/容積估算方法。為了計(jì)算一個(gè)儲(chǔ)油罐的總?cè)莘e,他們需要儲(chǔ)油罐的高度和半徑。為了計(jì)算高度,他們使用了與投影陰影長(zhǎng)度的幾何關(guān)系,但是計(jì)算陰影的長(zhǎng)度并不容易,為了突出陰影使用了HSV(即色調(diào)飽和度值)顏色空間,因?yàn)橥ǔj幱霸贖SV顏色空間中具有高飽和度,然后采用基于亞像素細(xì)分定位(sub-pixel subdivision positioning)的中值法來(lái)計(jì)算陰影長(zhǎng)度,最后利用Hough變換算法得到油罐半徑。在本文的相關(guān)工作中,提出了基于衛(wèi)星圖像的建筑物高度計(jì)算方法。
4.有用的博客和研究論文
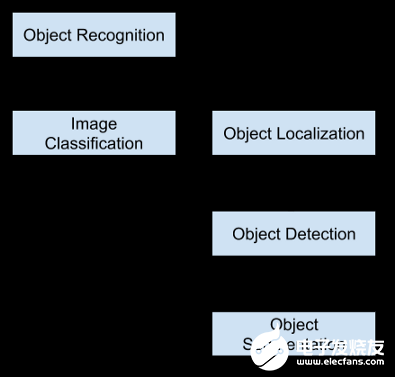
A Beginner’s Guide To Calculating Oil Storage Tank Occupancy With Help Of Satellite Imagery [3]:本博客作者為T(mén)ankerTracker.com,其中的一項(xiàng)工作是利用衛(wèi)星圖像跟蹤幾個(gè)感興趣的地理位置的原油儲(chǔ)存情況。在這篇博客中,他們?cè)敿?xì)描述了儲(chǔ)油罐的外部和內(nèi)部陰影如何幫助我們估計(jì)其中的石油含量,還比較了衛(wèi)星在特定時(shí)間和一個(gè)月后拍攝的圖像,顯示了一個(gè)月來(lái)儲(chǔ)油罐的變化。這個(gè)博客給了我們一個(gè)直觀的知識(shí),即如何估計(jì)量。A Gentle Introduction to Object Recognition With Deep Learning [4] :本文會(huì)介紹對(duì)象檢測(cè)初學(xué)者頭腦中出現(xiàn)的最令人困惑的概念。首先,描述了目標(biāo)分類(lèi)、目標(biāo)定位、目標(biāo)識(shí)別和目標(biāo)檢測(cè)之間的區(qū)別,然后討論了一些最新的深度學(xué)習(xí)算法來(lái)展開(kāi)目標(biāo)識(shí)別任務(wù)。對(duì)象分類(lèi)是指將標(biāo)簽分配給包含單個(gè)對(duì)象的圖像,而對(duì)象定位是指在圖像中的一個(gè)或多個(gè)對(duì)象周?chē)L制一個(gè)邊界框,目標(biāo)檢測(cè)任務(wù)結(jié)合了目標(biāo)分類(lèi)和定位。這意味著這是一個(gè)更具挑戰(zhàn)性/復(fù)雜的任務(wù),首先通過(guò)本地化技術(shù)在感興趣對(duì)象(OI)周?chē)L制一個(gè)邊界框,然后借助分類(lèi)為每個(gè)OI分配一個(gè)標(biāo)簽。目標(biāo)識(shí)別是上述所有任務(wù)的集合(即分類(lèi)、定位和檢測(cè))。
最后,本文還討論了兩種主要的目標(biāo)檢測(cè)算法/模型:Region-Based Convolutional Neural Networks (R-CNN)和You Only Look Once (YOLO)。Selective Search for Object Recognition [5]:在目標(biāo)檢測(cè)任務(wù)中,最關(guān)鍵的部分是目標(biāo)定位,因?yàn)槟繕?biāo)分類(lèi)是在此基礎(chǔ)上進(jìn)行的,它依賴(lài)于定位所輸出的目標(biāo)區(qū)域(簡(jiǎn)稱(chēng)區(qū)域建議)。更完美的定位可以實(shí)現(xiàn)更完美的目標(biāo)檢測(cè)。選擇性搜索是一種新興的算法,在一些物體識(shí)別模型中被用于物體定位,如R-CNN和Fast-R-CNN。該算法首先使用高效的基于圖的圖像分割方法生成輸入圖像的子段,然后使用貪婪算法將較小的相似區(qū)域合并為較大的相似區(qū)域。分段相似性基于顏色、紋理、大小和填充四個(gè)屬性。
Region Proposal Network — A detailed view[6]:RPN(Region-proposition Network)由于其比傳統(tǒng)選擇性搜索算法更快而被廣泛地應(yīng)用于目標(biāo)定位,它從特征圖中學(xué)習(xí)目標(biāo)的最佳位置,就像CNN從特征圖中學(xué)習(xí)分類(lèi)一樣。它負(fù)責(zé)三個(gè)主要任務(wù),首先生成錨定框(每個(gè)特征映射點(diǎn)生成9個(gè)不同形狀的錨定框),然后將每個(gè)錨定框分類(lèi)為前景或背景(即是否包含對(duì)象),最后學(xué)習(xí)錨定框的形狀偏移量以使其適合對(duì)象。Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[7]:Faster R-CNN模型解決了前兩個(gè)相關(guān)模型(R-CNN和Fast R-CNN)的所有問(wèn)題,并使用RPN作為區(qū)域建議生成器。它的架構(gòu)與Fast R-CNN完全相同,只是它使用了RPN而不是選擇性搜索,這使得它比Fast R-CNN快34倍。

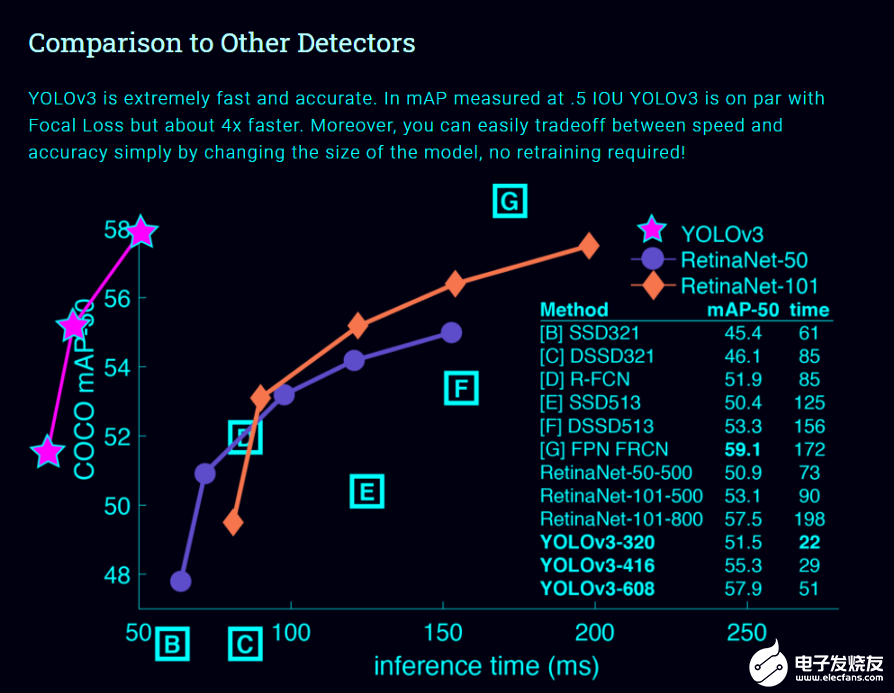
Real-time Object Detection with YOLO, YOLOv2, and now YOLOv3 [8]:在介紹Yolo系列模型之前,讓我們先看一下首席研究員約瑟夫·雷德曼在Ted演講上的演講。https://youtu.be/Cgxsv1riJhI這個(gè)模型在對(duì)象檢測(cè)模型列表中占據(jù)首位的原因有很多,然而,最主要的原因是它的牢固性,它的推理時(shí)間非常短,這是為什么它很容易匹配視頻的正常速度(即25fps)并應(yīng)用于實(shí)時(shí)數(shù)據(jù)的原因。
與其他對(duì)象檢測(cè)模型不同,Yolo模型具有以下特性。單神經(jīng)網(wǎng)絡(luò)模型(即分類(lèi)和定位任務(wù)都將從同一個(gè)模型中執(zhí)行):以一張照片作為輸入,直接預(yù)測(cè)每個(gè)邊界框的邊界框和類(lèi)標(biāo)簽,這意味著它只看一次圖像。由于它對(duì)整個(gè)圖像而不是圖像的一部分執(zhí)行卷積,因此它產(chǎn)生的背景錯(cuò)誤非常少。YOLO學(xué)習(xí)對(duì)象的一般化表示。在對(duì)自然圖像進(jìn)行訓(xùn)練和藝術(shù)品測(cè)試時(shí),YOLO的性能遠(yuǎn)遠(yuǎn)超過(guò)DPM和R-CNN等頂級(jí)檢測(cè)方法。由于YOLO具有高度的通用性,所以當(dāng)應(yīng)用于新的域或意外的輸入時(shí),它不太可能崩潰。是什么讓YoloV3比Yolov2更好。如果你仔細(xì)看一下yolov2論文的標(biāo)題,那就是“YOLO9000: Better, Faster, Stronger”。yolov3比yolov2更好嗎?答案是肯定的,它更好,但不是更快更強(qiáng),因?yàn)轶w系的復(fù)雜性增加了。Yolov2使用了19層DarkNet架構(gòu),沒(méi)有任何殘差塊、skip連接和上采樣,因此它很難檢測(cè)到小對(duì)象,然而在Yolov3中,這些特性被添加了,并且使用了在Imagenet上訓(xùn)練的53層DarkNet網(wǎng)絡(luò),除此之外,還堆積了53個(gè)卷積層,形成了106個(gè)卷積層結(jié)構(gòu)。
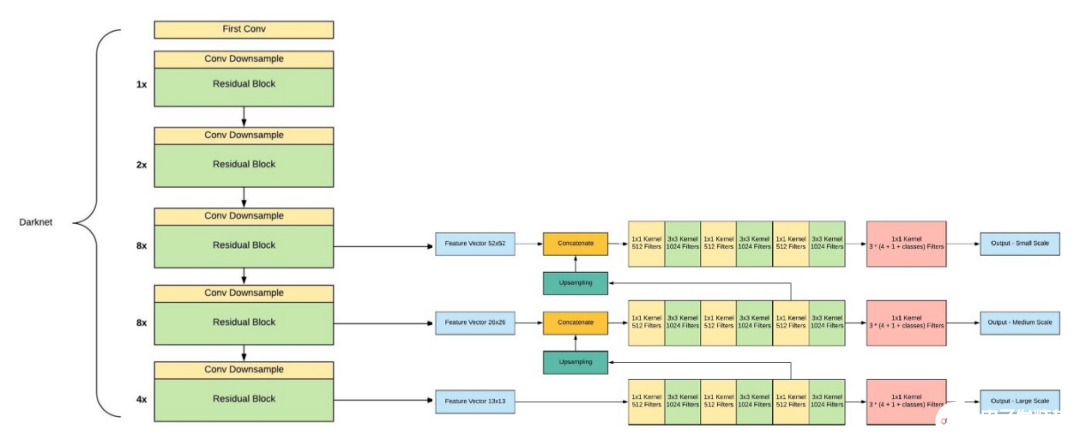
Yolov3在三種不同的尺度上進(jìn)行預(yù)測(cè),首先是大對(duì)象的13X13網(wǎng)格,其次是中等對(duì)象的26X26網(wǎng)格,最后是小對(duì)象的52X52網(wǎng)格。YoloV3總共使用9個(gè)錨箱,每個(gè)標(biāo)度3個(gè),用K均值聚類(lèi)法選出最佳錨盒。Yolov3可以對(duì)圖像中檢測(cè)到的對(duì)象執(zhí)行多標(biāo)簽分類(lèi),通過(guò)logistic回歸預(yù)測(cè)對(duì)象置信度和類(lèi)預(yù)測(cè)。
5.我們的貢獻(xiàn)
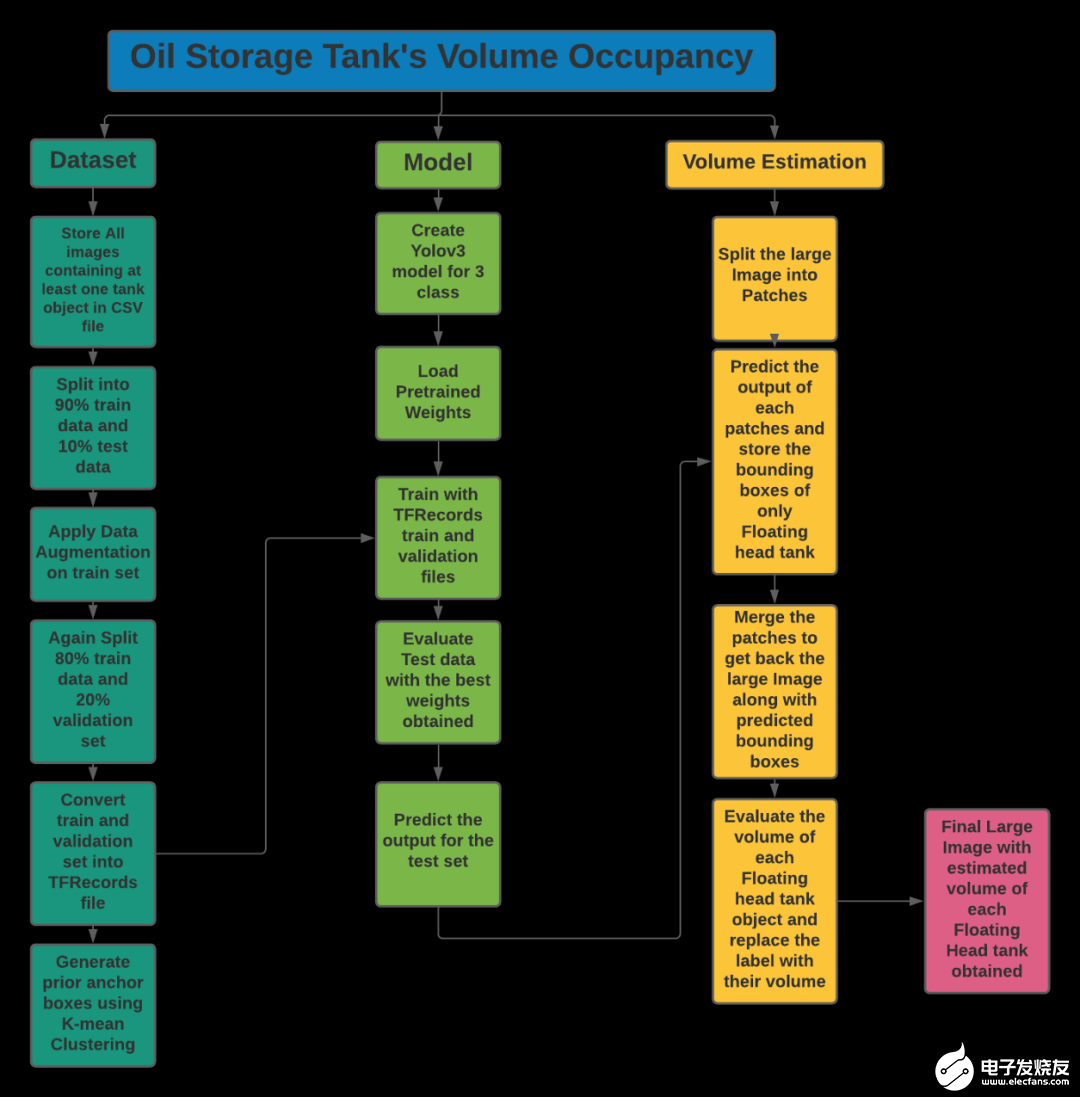
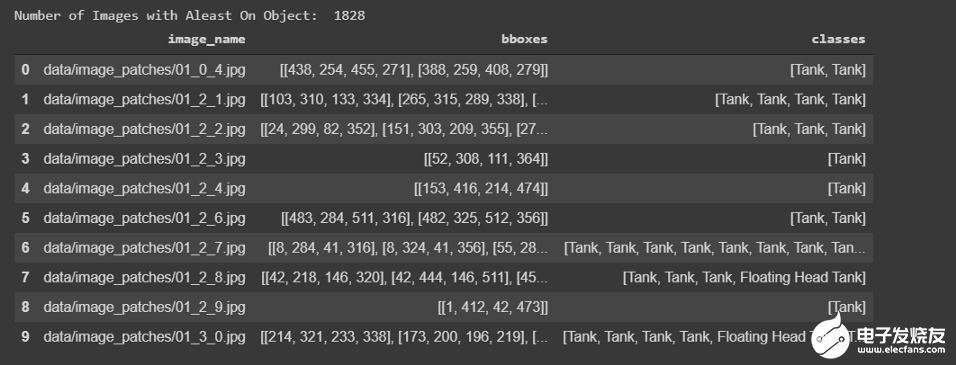
我們的問(wèn)題陳述包括兩個(gè)任務(wù),第一個(gè)是浮頂罐的檢測(cè),另一個(gè)是陰影的提取和已識(shí)別罐容積的估計(jì)。第一個(gè)任務(wù)是基于目標(biāo)檢測(cè),第二個(gè)任務(wù)是基于計(jì)算機(jī)視覺(jué)技術(shù)。讓我們描述一下解決每個(gè)任務(wù)的方法。儲(chǔ)罐檢測(cè):我們的目標(biāo)是估算浮頂罐的容積。我們可以為一個(gè)類(lèi)建立目標(biāo)檢測(cè)模型,但是為了減少一個(gè)模型與另一種儲(chǔ)油罐(即其他類(lèi)型儲(chǔ)油罐)的混淆,并使其具有魯棒性,我們提出了三個(gè)類(lèi)別的目標(biāo)檢測(cè)模型。使用帶有轉(zhuǎn)移學(xué)習(xí)的YoloV3進(jìn)行目標(biāo)檢測(cè)是因?yàn)樗菀自跈C(jī)器上訓(xùn)練,此外為了提高度量分值,還采用了數(shù)據(jù)增強(qiáng)的方法。陰影提取和體積估計(jì):陰影提取涉及許多計(jì)算機(jī)視覺(jué)技術(shù),由于RGB顏色方案對(duì)陰影不敏感,必須先將其轉(zhuǎn)換成HSV和LAB顏色空間,我們使用(l1+l3)/(V+1) (其中l(wèi)1是LAB顏色空間的第一個(gè)通道值)的比值圖像來(lái)增強(qiáng)陰影部分。然后,通過(guò)閾值0.5×t1+0.4×t2(其中t1是最小像素值,t2是平均值)來(lái)過(guò)濾增強(qiáng)圖像,再對(duì)閾值圖像進(jìn)行形態(tài)學(xué)處理(即去除噪聲、清晰輪廓等)。最后,提取出兩個(gè)儲(chǔ)油罐的陰影輪廓,然后根據(jù)上述公式估算出所占用的體積。這些想法摘自以下Notebook。https://www.kaggle.com/towardsentropy/oil-tank-volume-estimation遵循整個(gè)流程來(lái)解決這個(gè)案例研究如下所示。
讓我們從數(shù)據(jù)集的探索性數(shù)據(jù)分析EDA開(kāi)始吧!!
6.探索性數(shù)據(jù)分析(EDA)
探索Labels.json文件:json_labels = json.load(open(os.path.join('data','labels.json')))
print('Number of Images: ',len(json_labels))
json_labels[25:30]
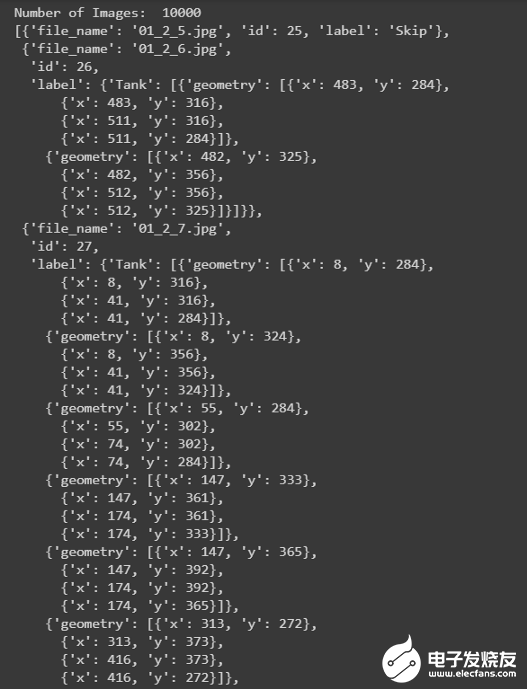
所有的標(biāo)簽都存儲(chǔ)在字典列表中,總共有10萬(wàn)張圖片。不包含任何儲(chǔ)罐的圖像將標(biāo)記為Skip,而包含儲(chǔ)罐的圖像將標(biāo)記為tank、tank Cluster或Floating Head tank,每個(gè)tank對(duì)象都有字典格式的四個(gè)角點(diǎn)的邊界框坐標(biāo)。計(jì)數(shù):
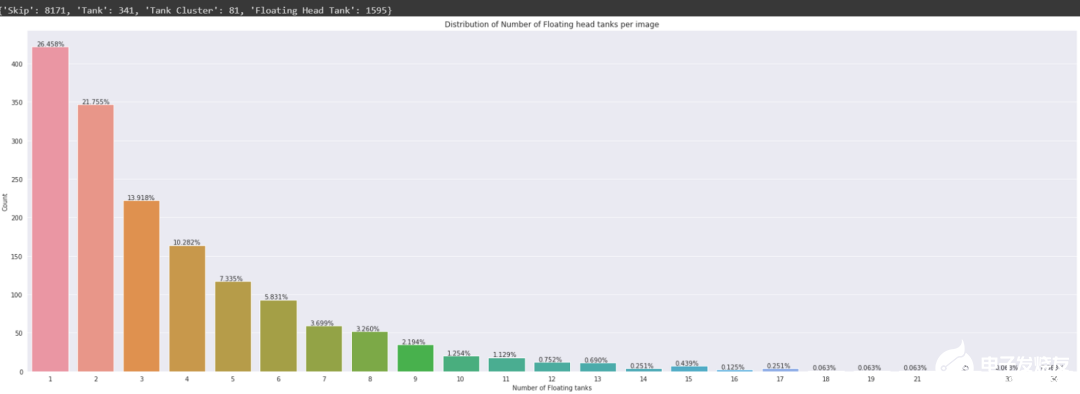
在10K個(gè)圖像中,8187個(gè)圖像沒(méi)有標(biāo)簽(即它們不包含任何儲(chǔ)油罐對(duì)象,此外有81個(gè)圖像包含至少一個(gè)儲(chǔ)油罐簇對(duì)象,1595個(gè)圖像包含至少一個(gè)浮頂儲(chǔ)油罐。在條形圖中,可以觀察到,在包含圖像的1595個(gè)浮頂罐中,26.45%的圖像僅包含一個(gè)浮頂罐對(duì)象,單個(gè)圖像中浮頂儲(chǔ)罐對(duì)象的最高數(shù)量為34。探索labels_coco.json文件:json_labels_coco = json.load(open(os.path.join('data','labels_coco.json')))
print('Number of Floating tanks: ',len(json_labels_coco['annotations']))
no_unique_img_id = set()
for ann in json_labels_coco['annotations']:
no_unique_img_id.a(chǎn)dd(ann['image_id'])
print('Number of Images that contains Floating head tank: ', len(no_unique_img_id))
json_labels_coco['annotations'][:8]
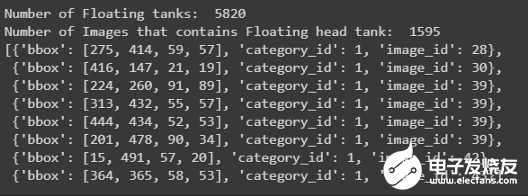
此文件僅包含浮頂罐的邊界框及其在字典格式列表中的image_id打印邊界框:
儲(chǔ)油罐有三種:Tank(T 油罐)Tank Cluster(TC 油罐組),F(xiàn)loating Head Tank(FHT,浮頂罐)
7.?dāng)?shù)據(jù)擴(kuò)充
在EDA中,人們觀察到10000幅圖像中有8171幅是無(wú)用的,因?yàn)樗鼈儾话魏螌?duì)象,此外1595個(gè)圖像包含至少一個(gè)浮頂罐對(duì)象。眾所周知,所有的深度學(xué)習(xí)模型都需要大量的數(shù)據(jù),沒(méi)有足夠的數(shù)據(jù)會(huì)導(dǎo)致性能的下降。因此,我們先進(jìn)行數(shù)據(jù)擴(kuò)充,然后將獲得的擴(kuò)充數(shù)據(jù)擬合到Y(jié)olov3目標(biāo)檢測(cè)模型中。
8.?dāng)?shù)據(jù)預(yù)處理、擴(kuò)充和TFRecords
數(shù)據(jù)預(yù)處理:對(duì)象的注釋是以Jason格式給出的,其中有4個(gè)角點(diǎn),首先,從這些角點(diǎn)提取左上角點(diǎn)和右下角點(diǎn),然后屬于單個(gè)圖像的所有注釋及其對(duì)應(yīng)的標(biāo)簽都保存在CSV文件的一行列表中。從角點(diǎn)提取左上角點(diǎn)和右下角點(diǎn)的代碼def conv_bbox(box_dict):
"""
input: box_dict-> 字典中有4個(gè)角點(diǎn)
Function: 獲取左上方和右下方的點(diǎn)
output: tuple(ymin, xmin, ymax, xmax)
"""
xs = np.a(chǎn)rray(list(set([i['x'] for i in box_dict])))
ys = np.a(chǎn)rray(list(set([i['y'] for i in box_dict])))
x_min = xs.min()
x_max = xs.max()
y_min = ys.min()
y_max = ys.max()
return y_min, x_min, y_max, x_max
CSV文件將如下所示
為了評(píng)估模型,我們將保留10%的圖像作為測(cè)試集。# 訓(xùn)練和測(cè)試劃分
df_train, df_test= model_selection.train_test_split(
df, #CSV文件注釋
test_size=0.1,
random_state=42,
shuffle=True,
)
df_train.shape, df_test.shape
數(shù)據(jù)擴(kuò)充:我們知道目標(biāo)檢測(cè)需要大量的數(shù)據(jù),但是我們只有1645幅圖像用于訓(xùn)練,這是非常少的,為了增加數(shù)據(jù),我們必須執(zhí)行數(shù)據(jù)擴(kuò)充。我們通過(guò)翻轉(zhuǎn)和旋轉(zhuǎn)原始圖像來(lái)生成新圖像。我們轉(zhuǎn)到下面的GitHub存儲(chǔ)庫(kù),從中提取代碼進(jìn)行擴(kuò)充https://blog.paperspace.com/data-augmentation-for-bounding-boxes/通過(guò)執(zhí)行以下操作從單個(gè)原始圖像生成7個(gè)新圖像:水平翻轉(zhuǎn)旋轉(zhuǎn)90度旋轉(zhuǎn)180度旋轉(zhuǎn)270度水平翻轉(zhuǎn)和90度旋轉(zhuǎn)水平翻轉(zhuǎn)和180度旋轉(zhuǎn)水平翻轉(zhuǎn)和270度旋轉(zhuǎn)示例如下所示
TFRecords:TFRecords是TensorFlow自己的二進(jìn)制存儲(chǔ)格式。當(dāng)數(shù)據(jù)集太大時(shí),它通常很有用。它以二進(jìn)制格式存儲(chǔ)數(shù)據(jù),并對(duì)訓(xùn)練模型的性能產(chǎn)生顯著影響。二進(jìn)制數(shù)據(jù)復(fù)制所需的時(shí)間更少,而且由于在訓(xùn)練時(shí)只加載了一個(gè)batch數(shù)據(jù),所以占用的空間也更少。你可以在下面的博客中找到它的詳細(xì)描述。https://medium.com/mostly-ai/tensorflow-records-what-they-are-and-h(huán)ow-to-use-them-c46bc4bbb564也可以查看下面的Tensorflow文檔。https://www.tensorflow.org/tutorials/load_data/tfrecord我們的數(shù)據(jù)集已轉(zhuǎn)換成RFRecords格式,但是我們沒(méi)有必要執(zhí)行此任務(wù),因?yàn)槲覀兊臄?shù)據(jù)集不是很大,如果你感興趣,可以在我的GitHub存儲(chǔ)庫(kù)中找到代碼。
9.基于YoloV3的目標(biāo)檢測(cè)
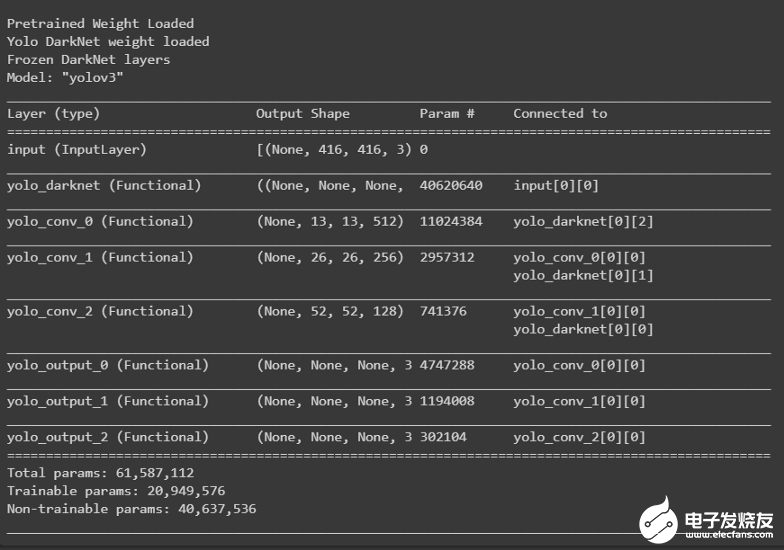
訓(xùn)練:為了訓(xùn)練yolov3模型,采用了遷移學(xué)習(xí)。第一步包括加載DarkNet網(wǎng)絡(luò)的權(quán)重,并在訓(xùn)練期間凍結(jié)它以保持權(quán)重不變。def create_model():
tf.keras.backend.clear_session()
pret_model = YoloV3(size, channels, classes=80)
load_darknet_weights(pret_model, 'Pretrained_M(jìn)odel/yolov3.weights')
print('Pretrained Weight Loaded')
model = YoloV3(size, channels, classes=3)
model.get_layer('yolo_darknet').set_weights(
pret_model.get_layer('yolo_darknet').get_weights())
print('Yolo DarkNet weight loaded')
freeze_all(model.get_layer('yolo_darknet'))
print('Frozen DarkNet layers')
return model
model = create_model()
model.summary()
我們使用adam優(yōu)化器(初始學(xué)習(xí)率=0.001)來(lái)訓(xùn)練我們的模型,并根據(jù)epoch應(yīng)用余弦衰減來(lái)降低學(xué)習(xí)速率。在訓(xùn)練過(guò)程中使用模型檢查點(diǎn)保存最佳權(quán)重,訓(xùn)練結(jié)束后保存最后一個(gè)權(quán)重。tf.keras.backend.clear_session()
epochs = 100
learning_rate=1e-3
optimizer = get_optimizer(
optim_type = 'adam',
learning_rate=1e-3,
decay_type='cosine',
decay_steps=10*600
)
loss = [YoloLoss(yolo_anchors[mask], classes=3) for mask in yolo_anchor_masks]
model = create_model()
model.compile(optimizer=optimizer, loss=loss)
# Tensorbaord
! rm -rf ./logs/
logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
%tensorboard --logdir $logdir
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
callbacks = [
EarlyStopping(monitor='val_loss', min_delta=0, patience=15, verbose=1),
ModelCheckpoint('Weights/Best_weight.hdf5', verbose=1, save_best_only=True),
tensorboard_callback,
]
history = model.fit(train_dataset,
epochs=epochs,
callbacks=callbacks,
validation_data=valid_dataset)
model.save('Weights/Last_weight.hdf5')
損失函數(shù):
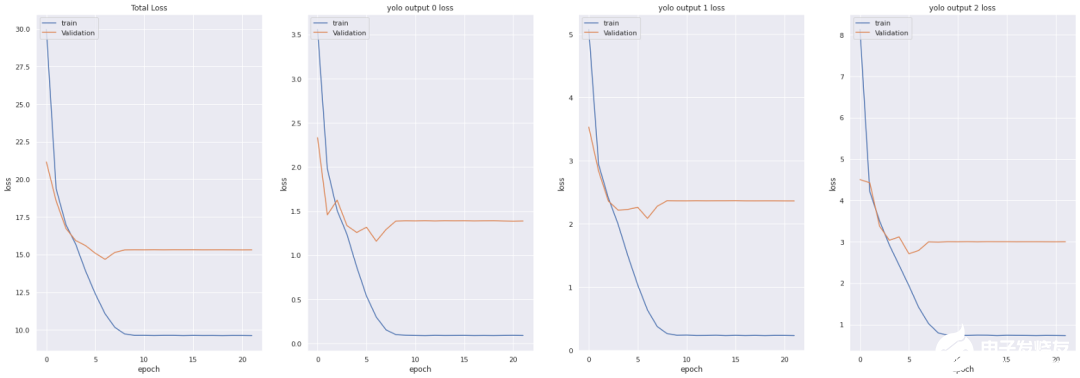
YOLO損失函數(shù):Yolov3模型訓(xùn)練中所用的損失函數(shù)相當(dāng)復(fù)雜。Yolo在三個(gè)不同的尺度上計(jì)算三個(gè)不同的損失,并對(duì)反向傳播進(jìn)行總結(jié)(正如你在上面的代碼單元中看到的,最終損失是三個(gè)不同損失的列表),每個(gè)loss都通過(guò)4個(gè)子函數(shù)來(lái)計(jì)算檢測(cè)損失和分類(lèi)損失。中心(x,y) 的MSE損失.邊界框的寬度和高度的均方誤差(MSE)邊界框的二元交叉熵得分與無(wú)目標(biāo)得分邊界框多類(lèi)預(yù)測(cè)的二元交叉熵或稀疏范疇交叉熵讓我們看看Yolov2中使用的損失公式
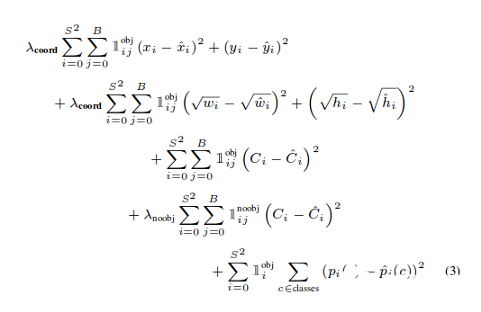
Yolov2中的最后三項(xiàng)是平方誤差,而在Yolov3中,它們被交叉熵誤差項(xiàng)所取代,換句話說(shuō),Yolov3中的對(duì)象置信度和類(lèi)預(yù)測(cè)現(xiàn)在通過(guò)logistic回歸來(lái)進(jìn)行預(yù)測(cè)。看看Yolov3損失函數(shù)的實(shí)現(xiàn)def YoloLoss(anchors, classes=3, ignore_thresh=0.5):
def yolo_loss(y_true, y_pred):
# 1. 轉(zhuǎn)換所有預(yù)測(cè)輸出
# y_pred: (batch_size, grid, grid, anchors, (x, y, w, h, obj, ...cls))
pred_box, pred_obj, pred_class, pred_xywh = yolo_boxes(
y_pred, anchors, classes)
# predicted (tx, ty, tw, th)
pred_xy = pred_xywh[..., 0:2] #x,y of last channel
pred_wh = pred_xywh[..., 2:4] #w,h of last channel
# 2. 轉(zhuǎn)換所有真實(shí)輸出
# y_true: (batch_size, grid, grid, anchors, (x1, y1, x2, y2, obj, cls))
true_box, true_obj, true_class_idx = tf.split(
y_true, (4, 1, 1), axis=-1)
#轉(zhuǎn)換 x1, y1, x2, y2 to x, y, w, h
# x,y = (x2 - x1)/2, (y2-y1)/2
# w, h = (x2- x1), (y2 - y1)
true_xy = (true_box[..., 0:2] + true_box[..., 2:4]) / 2
true_wh = true_box[..., 2:4] - true_box[..., 0:2]
# 小的box要更高權(quán)重
#shape-> (batch_size, grid, grid, anchors)
box_loss_scale = 2 - true_wh[..., 0] * true_wh[..., 1]
# 3. 對(duì)pred box進(jìn)行反向
# 把 (bx, by, bw, bh) 變?yōu)?(tx, ty, tw, th)
grid_size = tf.shape(y_true)[1]
grid = tf.meshgrid(tf.range(grid_size), tf.range(grid_size))
grid = tf.expand_dims(tf.stack(grid, axis=-1), axis=2)
true_xy = true_xy * tf.cast(grid_size, tf.float32) - tf.cast(grid, tf.float32)
true_wh = tf.math.log(true_wh / anchors)
true_wh = tf.where(tf.logical_or(tf.math.is_inf(true_wh),
tf.math.is_nan(true_wh)),
tf.zeros_like(true_wh), true_wh)
# 4. 計(jì)算所有掩碼
#從張量的形狀中去除尺寸為1的維度。
#obj_mask: (batch_size, grid, grid, anchors)
obj_mask = tf.squeeze(true_obj, -1)
#當(dāng)iou超過(guò)臨界值時(shí),忽略假正例
#best_iou: (batch_size, grid, grid, anchors)
best_iou = tf.map_fn(
lambda x: tf.reduce_max(broadcast_iou(x[0], tf.boolean_mask(
x[1], tf.cast(x[2], tf.bool))), axis=-1),
(pred_box, true_box, obj_mask),
tf.float32)
ignore_mask = tf.cast(best_iou < ignore_thresh, tf.float32)
# 5.計(jì)算所有損失
xy_loss = obj_mask * box_loss_scale *
tf.reduce_sum(tf.square(true_xy - pred_xy), axis=-1)
wh_loss = obj_mask * box_loss_scale *
tf.reduce_sum(tf.square(true_wh - pred_wh), axis=-1)
obj_loss = binary_crossentropy(true_obj, pred_obj)
obj_loss = obj_mask * obj_loss +
(1 - obj_mask) * ignore_mask * obj_loss
#TODO:使用binary_crossentropy代替
class_loss = obj_mask * sparse_categorical_crossentropy(
true_class_idx, pred_class)
# 6. 在(batch, gridx, gridy, anchors)求和得到 => (batch, 1)
xy_loss = tf.reduce_sum(xy_loss, axis=(1, 2, 3))
wh_loss = tf.reduce_sum(wh_loss, axis=(1, 2, 3))
obj_loss = tf.reduce_sum(obj_loss, axis=(1, 2, 3))
class_loss = tf.reduce_sum(class_loss, axis=(1, 2, 3))
return xy_loss + wh_loss + obj_loss + class_loss
return yolo_loss
分?jǐn)?shù):為了評(píng)估我們的模型,我們使用了AP和mAP來(lái)評(píng)估訓(xùn)練和測(cè)試數(shù)據(jù)測(cè)試集分?jǐn)?shù)get_mAP(model, 'data/test.csv')

訓(xùn)練集分?jǐn)?shù)get_mAP(model, 'data/train.csv')
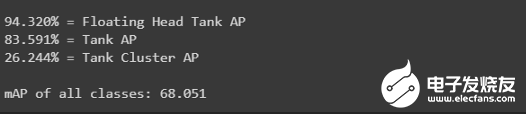
推理:讓我們看看這個(gè)模型是如何執(zhí)行的
10.儲(chǔ)量估算
體積估算是本案例研究的主要內(nèi)容。雖然沒(méi)有評(píng)估估計(jì)容積的標(biāo)準(zhǔn),但我們?cè)噲D找到圖像的最佳閾值像素值,以便能夠在很大程度上檢測(cè)陰影區(qū)域(通過(guò)計(jì)算像素?cái)?shù))。我們將使用衛(wèi)星拍攝到的4800X4800形狀的大圖像,并將其分割成100個(gè)512x512的子圖,兩個(gè)軸上的子圖之間重疊37像素。圖像修補(bǔ)程序在id_row_column.jpg命名。每個(gè)生成的子圖預(yù)測(cè)都將存儲(chǔ)在一個(gè)CSV文件中,然后再估計(jì)每個(gè)浮頂儲(chǔ)油罐的體積(代碼和解釋以Notebook格式在我的GitHub存儲(chǔ)庫(kù)中提供)。最后,將所有的圖像塊和邊界框與標(biāo)簽合并,輸出估計(jì)的體積,形成一個(gè)大的圖像。你可以看看下面的例子:
11.結(jié)果
測(cè)試集上浮頂罐的AP分?jǐn)?shù)為0.874,訓(xùn)練集上的AP分?jǐn)?shù)為0.942。
12.結(jié)論
只需有限的圖像就可以得到相當(dāng)好的結(jié)果。數(shù)據(jù)增強(qiáng)工作得很到位。在本例中,與RetinaNet模型的現(xiàn)有方法相比,yolov3表現(xiàn)得很好。
13.今后的工作
浮頂罐的AP值為87.4%,得分較高,但我們可以嘗試在更大程度上提高分?jǐn)?shù)。我們將嘗試生成的更多數(shù)據(jù)來(lái)訓(xùn)練這個(gè)模型。我們將嘗試訓(xùn)練另一個(gè)更精確的模型,如yolov4,yolov5(非官方)。
責(zé)任編輯:gt
-
通信
+關(guān)注
關(guān)注
18文章
6173瀏覽量
137369 -
衛(wèi)星
+關(guān)注
關(guān)注
18文章
1754瀏覽量
68123 -
導(dǎo)航
+關(guān)注
關(guān)注
7文章
547瀏覽量
43004
發(fā)布評(píng)論請(qǐng)先 登錄
基于RV1126開(kāi)發(fā)板的人臉姿態(tài)估計(jì)算法開(kāi)發(fā)
基于衛(wèi)星圖像的智能定位系統(tǒng)軟件
基于衛(wèi)星圖像的智能定位系統(tǒng)全面解析
【AIBOX 應(yīng)用案例】單目深度估計(jì)

無(wú)人機(jī)石油巡檢系統(tǒng)讓能源設(shè)施管理更高效
儲(chǔ)油自動(dòng)化革命,網(wǎng)關(guān)PROFINET與MODBUS網(wǎng)橋的無(wú)縫融合,錦上添花


油庫(kù)智能雷電預(yù)警系統(tǒng) 儲(chǔ)油罐接地電阻在線裝置 三維閃電定位儀 #雷電預(yù)警系統(tǒng) #油庫(kù)雷電預(yù)警 #油庫(kù)儲(chǔ)油罐
如何利用電磁波譜進(jìn)行遙感
國(guó)產(chǎn)模數(shù)轉(zhuǎn)換器SC1641兼容AD7793用于工業(yè)油罐液位測(cè)量

通過(guò)北斗衛(wèi)星進(jìn)行授時(shí),時(shí)鐘同步裝置的工作原理是什么?

第三章:訓(xùn)練圖像估計(jì)光照度算法模型
利用圖像處理板避障 讓小型飛行器像昆蟲(chóng)一樣靈巧

紅外熱像儀在儲(chǔ)罐液位檢測(cè)的應(yīng)用

如何利用CNN實(shí)現(xiàn)圖像識(shí)別
發(fā)電機(jī)油罐控制柜PLC數(shù)據(jù)采集物聯(lián)網(wǎng)解決方案






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論