 使用LSTM模型對智能家居里的活躍設備進行預測
使用LSTM模型對智能家居里的活躍設備進行預測
今年 8 月份,香港中文大學張克環教授研究組在 arxiv 上公布了一篇文章,展示了他們組對于智能家居隱私性的研究。文章作者嘗試使用 LSTM 模型對智能家居里的活躍設備進行預測。該預測可以使服務提供商(ISP)猜測用戶正在家里使用什么類型的設備,從而有可能對擁有不同設備的用戶有不同的商業推廣手段。

在此之前,已經有不少人做了相關的研究,但他們的研究大都是基于純凈的實驗室環境,很難移植到復雜的現實環境中。作者通過分析真實世界中的 IoT 設備以及公開數據集,發現物聯網設備的流量與桌面流量和移動流量相比有以下區別:
同一類別的設備有相似的流量模式(下圖為兩種語音助手識別語音命令時的流量變化情況)
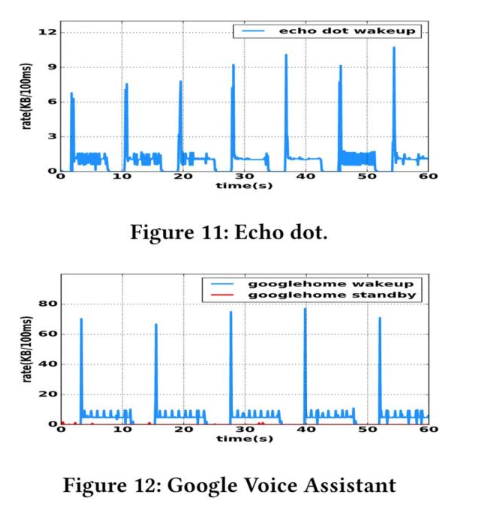
設備都有「心跳」傳輸來保證網絡和設備的聯通,不同設備的「心跳」模式不同不同設備傳輸協議比例不同(下圖展示了 IoT 設備和非 IoT 設備的協議使用情況)
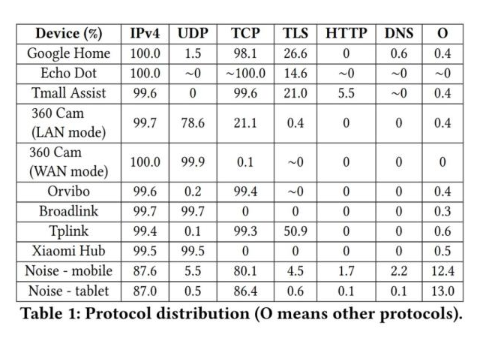
作者認為,這些特征表明即使是在復雜場景下,而且具有一定的安全設備(NAPT 和 VPN)也能鑒別不同的 IoT 設備。由于現有的數據集不滿足作者的要求,因此作者團隊自己搭建了一個數據采集的系統。
實驗數據收集
該系統包含 10 個 IoT 設備和 4 個非 IoT 設備,系統內設備如下圖所示。
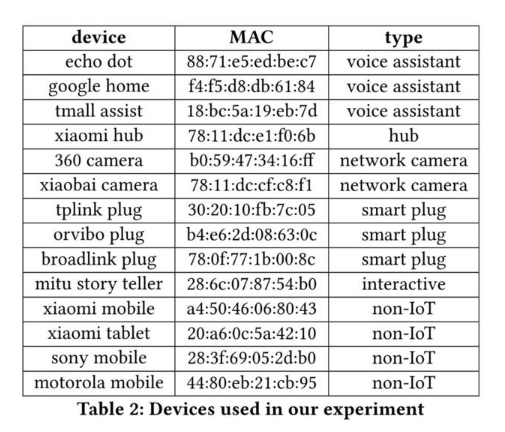
作者準備在三個環境下收集流量信息:單一設備環境、多設備嘈雜環境 (使用 NAPT 技術) 以及 VPN 環境。
首先介紹一下 NAPT 技術和 VPN 技術。NAPT 是一種網絡地址轉換技術,與 NAT 不同,NAPT 支持端口的映射。NAT 實現的是本地 IP 和 NAT 的公共 IP 之間的轉換,因此本地局域網中同時與公網進行通信的主機數量就受到 NAT 的公網 IP 地址數量的限制。而 NAPT 克服了這種缺陷——NAPT 技術在進行 IP 地址轉換的同時還對端口進行轉換,因此只要 NAT 中的端口不沖突,就允許本地局域網的多臺主機利用一個 NAT 公共 IP 就可以同時和公網進行通信。
VPN 通常用于互連不同的網絡,以形成具有更大容量的新網絡。它是基于 IP 隧道機制,不同子網中的主機可以相互通信,并且可以通過認證和加密保密傳送的信息。
在生成流量的過程中,作者采用了兩種觸發方式:手動觸發和自動觸發,手動觸發可以模擬真實環境下的人機交互,自動觸發可以減輕實驗者的負擔。在自動觸發模式下,作者使用 Monkey Runner 對需要用 APP 進行交互的 IoT 設備進行觸發;對于語音助手等 IoT 設備,作者通過重復播放口令來進行觸發。
手動觸發模式只在多設備場景下使用,在該模式下,作者通過隨機進出房間來對房間內的試驗設備進行觸發。該種方式與自動觸發相比,更具有隨機隨機性,從而有助于模型的泛化。
整個流量收集過程持續 49.4 個小時,共收集 4.05GB 的數據,共包含 7223282 條有效通信包。
數據預處理
在進行實驗評估之前,作者先對數據進行了預處理——將初始數據轉換為模型能夠處理的數值向量。
數據預處理過程可分為兩部分,特征提取和制作數據包的標簽。在特征提取過程中,共提取了五個特征,分別是端口 (dport)、協議 (protocol)、方向 (direction)、幀長 (frame length)、時間間隔 (time interval),并將這五個特征組成一維向量,如下圖所示。
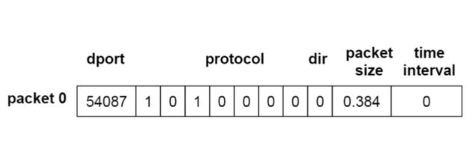
在給數據包制作標簽的過程中,針對在 VPN 環境下較難打標的問題,作者發現了如下規律,從而能夠較精確地給數據包打標簽:
經過 VPN 處理后,數據包的體積會變大不同體積的數據包經過 VPN 加密后體積相同VPN 會引起數據包傳輸延遲,這個延遲通常短于 0.02 秒
模型選擇
在模型選擇上,作者共選取了三個模型:隨機森林(基線模型)、LSTM 模型以及 BLSTM(雙向 LSTM)模型。由于隨機森林無法直接學習離散值,作者對端口的特征值進行了獨熱編碼處理。
對于 LSTM 模型,作者也對輸入模型的數據進行了處理,他將多個連續向量進行了分組并組成流量窗,如下圖所示。

作者使用的 LSTM 模型如下圖所示。該模型由多個基礎模塊組成,每個基礎模塊又包含有 Embedding 層、LSTM 層、全連接層以及 Softmax 層。
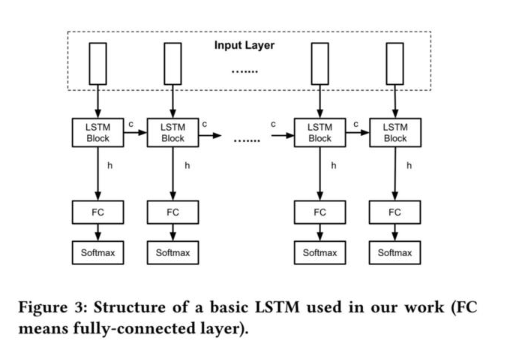
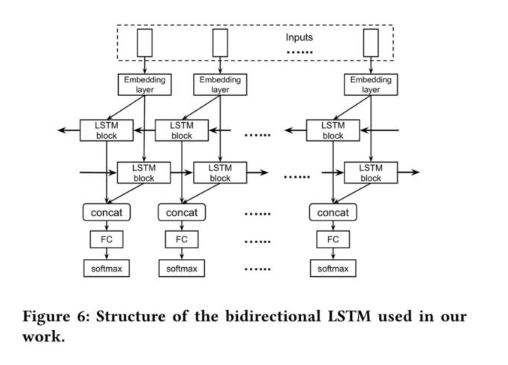
由于 LSTM 模型在學習上下文信息時只能查看數據包的「過去」,因此作者又使用了 BLSTM 模型。BLSTM(雙向 LSTM)是 LSTM 的擴展,它通過組合從序列末尾移動到其開頭的另一個 LSTM 層來利用來自「未來」的信息。作者使用的 BLSTM 模型見下圖。
模型評估
數據集
共有兩種數據集,Dataset-Ind 以及 Dataset-Noise。每種數據集又有兩個版本:NAPT 版本和 VPN 版本。Dataset-Ind 數據集包含來自 10 個單獨 IoT 設備的流量數據,這些數據被組成流量窗。Dataset-Ind 數據集共有 32760 個流量窗。
Dataset-Noise 數據集中的數據也是以流量窗的形式存在,與 Dataset-Ind 數據集不同的是,該數據集中的每個流量窗都是由多個設備的數據包組成。Dataset-Noise 數據集包含 114989 個流量窗。
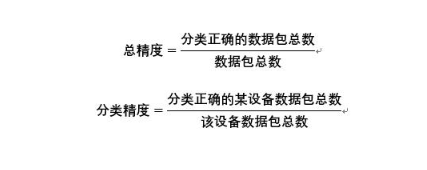
評估指標
總精度(overall accuracy) 和分類精度(category accuracy)
評估結果
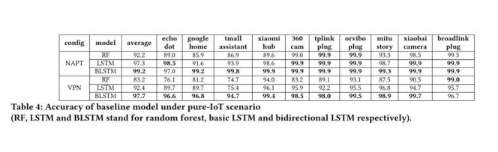
在 Datatset-Ind 數據集下的評估結果如下表所示。從表中可以看出,LSTM 模型的精度普遍高于隨機森林模型。
隨后,作者又在 Dataset-Ind 數據集下研究了流量窗大小對實驗精度的影響,結果顯示,流量窗越大,實驗精度越高。因此,在接下來的實驗中,流量窗的大小默認為 100。
在 Dataset-Noise 數據集下的評估結果如下圖所示。由圖中可以看出,隨機森林模型在該數據集下的總精度下降明顯,在 NAPT 環境下總精度為 84.5%,在 VPN 環境下的總精度為 67.6%。而 LSTM 模型在 NAPT 環境下表現較好,在 VPN 環境下表現較差。
作者對隨機森林模型和 LSTM 模型精度降低的現象進行了分析,認為隨機森林模型精度降低的原因是多個 IoT 設備和非 IoT 設備同時使用一個端口進行通信,使得該模型分類失敗;而 LSTM 模型精度下降的原因,作者認為是由稀疏流量造成的:因此在 VPN 協議的極端情況下,智能插頭(圖中 orvibo, tplink)產生的流量包可以在流量窗口中被稀釋到不到 3%。令這兩款智能插頭不能被識別出。
結論
根據實驗結果,作者認為即使是在加密和流量融合的情況下,物聯網設備的網絡通信也會產生嚴重的隱私影響。人們應該進行更多該方面的研究,以更好地了解智能家居網絡中地隱私問題并緩解此類問題。
-
物聯網
+關注
關注
2928文章
46024瀏覽量
389408 -
智能家居
+關注
關注
1934文章
9768瀏覽量
189953 -
數據集
+關注
關注
4文章
1223瀏覽量
25317
發布評論請先 登錄
Matter 智能家居的通用語言
明遠智睿SSD2351開發板:智能家居的智能核心
智能家居Mesh組網方案:實現智能化生活的無縫連接NRF52832
智能家居物聯網:數字化生活模式
物聯網智能家居解決方案,實現設備間的無縫連接
人臉識別技術在智能家居中的應用有哪些
Zigbee智能家居的未來發展趨勢
如何使用Python構建LSTM神經網絡模型
圖為大模型一體機新探索,賦能智能家居行業
人工智能如何強化智能家居設備的功能
掃碼模組在智能家居領域中的應用






 工商網監
工商網監
評論