") 樹莓派5上的Gemma 2:如何打造高效的邊緣AI解決方案?
樹莓派5上的Gemma 2:如何打造高效的邊緣AI解決方案?
從數(shù)學基礎(chǔ)到邊緣實現(xiàn),研究團隊: Conecta.ai (ufrn.br)

摘要
1.引言
2.GEMMA 2:通用集成機器模型算法
2.1 模型架構(gòu)
2.2 預訓練
2.3 后訓練
3.邊緣AI實現(xiàn)
1. 引言
GEMMA 2(通用集成機器模型算法,第二版)是一個復雜的框架,專為可擴展和靈活的機器學習模型訓練而設(shè)計,特別是在分布式和資源受限的環(huán)境中。在其前身的基礎(chǔ)上,GEMMA 2引入了增強的功能,適用于監(jiān)督和無監(jiān)督學習任務(wù),使其成為人工智能、邊緣計算和數(shù)據(jù)科學等領(lǐng)域研究人員和從業(yè)者的強大工具。
GEMMA 2的核心在于其能夠處理多樣化的數(shù)據(jù)集和模型架構(gòu),同時優(yōu)化計算效率。這是通過算法設(shè)計中的創(chuàng)新實現(xiàn)的,包括支持自適應(yīng)聚類、多分辨率數(shù)據(jù)分析和量化技術(shù),確保與微控制器和嵌入式系統(tǒng)等資源受限設(shè)備的兼容性。
GEMMA 2的主要特點包括:
1.分布式學習:利用并行計算在多個節(jié)點上實現(xiàn)更快的訓練和評估。
2.模型壓縮:采用先進的量化和剪枝策略,在不犧牲準確性的情況下減小模型大小。
3.邊緣部署:針對在邊緣設(shè)備上部署機器學習模型進行定制優(yōu)化,確保實時性能和最小能耗。
4.增強的靈活性:支持廣泛的機器學習范式,包括神經(jīng)網(wǎng)絡(luò)、決策樹和集成方法。
5.以用戶為中心的設(shè)計:模塊化架構(gòu)和用戶友好的API,簡化了特定用例的集成和定制。
2 — Gemma 2
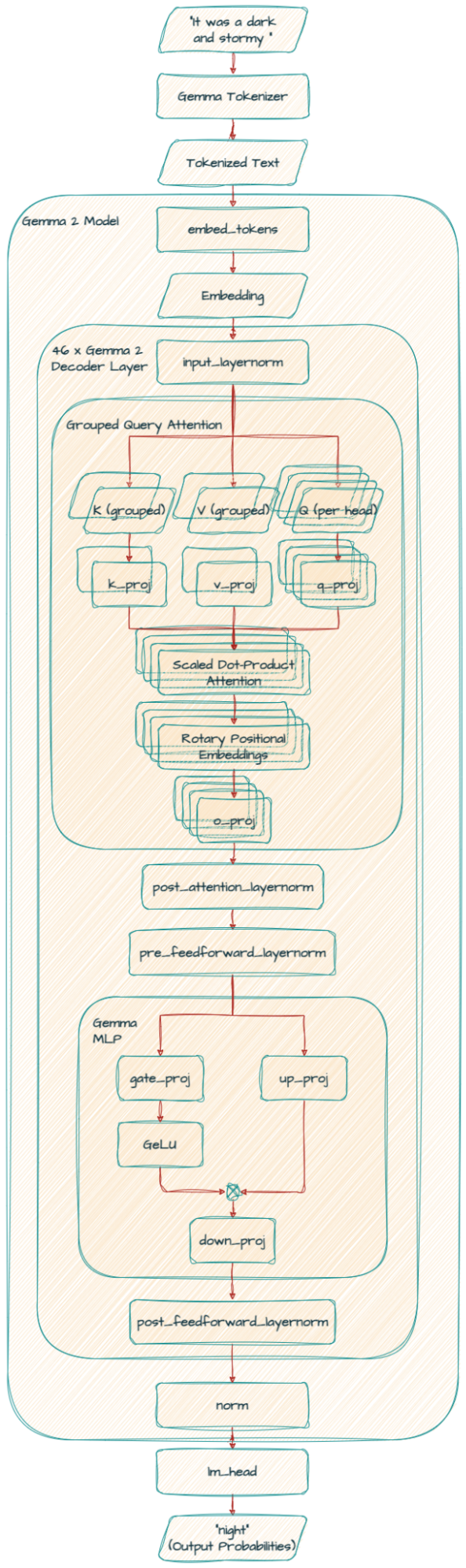
Gemma 2模型基于僅解碼器的Transformer架構(gòu)。我們在表中總結(jié)了主要參數(shù)和架構(gòu)選擇。
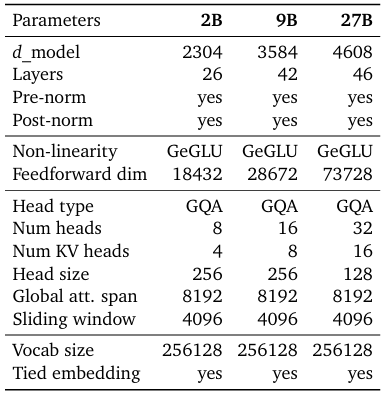
一些架構(gòu)元素與Gemma模型的第一版相似;即上下文長度為8192個標記,使用旋轉(zhuǎn)位置嵌入(RoPE)和近似的GeGLU非線性。Gemma 1和Gemma 2之間有幾個元素不同,包括使用更深的網(wǎng)絡(luò)。我們在下面總結(jié)了關(guān)鍵差異。
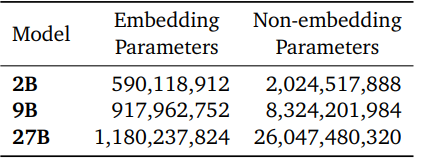
2.1 模型架構(gòu)
2.1.1 局部滑動窗口和全局注意力
我們在每一層交替使用局部滑動窗口注意力和全局注意力。局部注意力層的滑動窗口大小設(shè)置為4096個標記,而全局注意力層的跨度設(shè)置為8192個標記。
2.1.2 Logit軟限制
我們在每個注意力層和最終層對logit進行限制,使其值保持在?soft_cap和+soft_cap之間。更具體地說,我們使用以下函數(shù)對logit進行限制:
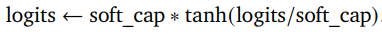
我們將self-attention層的soft_cap參數(shù)設(shè)置為50.0,將最終層的soft_cap參數(shù)設(shè)置為30.0。
2.1.3 使用RMSNorm的后歸一化和前歸一化
為了穩(wěn)定訓練,我們使用RMSNorm對每個Transformer子層、注意力層和前饋層的輸入和輸出進行歸一化。
2.1.4 分組查詢注意力
這種技術(shù)幫助模型更高效地處理信息,特別是在處理大量文本時。它通過將查詢分組在一起,改進了傳統(tǒng)的多頭注意力(MHA),實現(xiàn)了更快的處理,特別是對于大型模型。這就像將一個大任務(wù)分成更小、更易管理的部分,使模型能夠更快地理解單詞之間的關(guān)系,而不犧牲準確性。
Gemma2ForCausalLM( (model):Gemma2Model( (embed_tokens):Embedding(256000,4608, padding_idx=0) (layers):ModuleList( (0-45):46xGemma2DecoderLayer( (self_attn):Gemma2SdpaAttention( (q_proj):Linear(in_features=4608, out_features=4096, bias=False) (k_proj):Linear(in_features=4608, out_features=2048, bias=False) (v_proj):Linear(in_features=4608, out_features=2048, bias=False) (o_proj):Linear(in_features=4096, out_features=4608, bias=False) (rotary_emb):Gemma2RotaryEmbedding() ) (mlp):Gemma2MLP( (gate_proj):Linear(in_features=4608, out_features=36864, bias=False) (up_proj):Linear(in_features=4608, out_features=36864, bias=False) (down_proj):Linear(in_features=36864, out_features=4608, bias=False) (act_fn):PytorchGELUTanh() ) (input_layernorm):Gemma2RMSNorm() (post_attention_layernorm):Gemma2RMSNorm() (pre_feedforward_layernorm):Gemma2RMSNorm() (post_feedforward_layernorm):Gemma2RMSNorm() ) ) (norm):Gemma2RMSNorm() ) (lm_head):Linear(in_features=4608, out_features=256000, bias=False))
2.2 預訓練
簡要概述我們與Gemma 1不同的預訓練部分。
2.2.1 訓練數(shù)據(jù)
Gemma 2 27B模型在13萬億個主要是英語數(shù)據(jù)的標記上進行訓練,9B模型在8萬億個標記上進行訓練,2B模型在2萬億個標記上進行訓練。這些標記來自多種數(shù)據(jù)源,包括網(wǎng)頁文檔、代碼和科學文章。我們的模型不是多模態(tài)的,也不是專門為最先進的多語言能力而訓練的。最終的數(shù)據(jù)混合是通過類似于Gemini 1.0中的方法確定的。
分詞器:使用與Gemma 1和Gemini相同的分詞器:一個帶有數(shù)字分割、保留空白和字節(jié)級編碼的SentencePiece分詞器。生成的詞匯表有256k個條目。
過濾:使用與Gemma 1相同的數(shù)據(jù)過濾技術(shù)。具體來說,我們過濾預訓練數(shù)據(jù)集以減少不需要或不安全的話語的風險,過濾掉某些個人信息或其他敏感數(shù)據(jù),從預訓練數(shù)據(jù)混合中凈化評估集,并通過最小化敏感輸出的擴散來減少重復的風險。
2.2.2 知識蒸餾
給定一個用作教師的大型模型,我們通過從教師給出的每個標記x在其上下文xc下的概率PT(x | xc)中進行蒸餾來學習較小的模型。更準確地說,我們最小化教師和學生概率之間的負對數(shù)似然:

其中PS是學生的參數(shù)化概率。注意,知識蒸餾也在Gemini 1.5中使用過。
2.3 后訓練
對于后訓練,我們將預訓練模型微調(diào)為指令調(diào)優(yōu)模型。首先,我們在純文本、僅英語的合成和人工生成的提示-響應(yīng)對混合上進行監(jiān)督微調(diào)(SFT)。然后,我們在這些模型上應(yīng)用RLHF,獎勵模型是在僅英語的標記偏好數(shù)據(jù)上訓練的,策略基于與SFT階段相同的提示。最后,我們對每個階段后獲得的模型進行平均,以提高它們的整體性能。最終的數(shù)據(jù)混合和后訓練配方,包括調(diào)整的超參數(shù),是根據(jù)在提高有用性的同時最小化與安全和幻覺相關(guān)的模型危害而選擇的。
我們擴展了Gemma 1.1的后訓練數(shù)據(jù),使用了內(nèi)部和外部公共數(shù)據(jù)的混合。特別是,我們使用了LMSYS-chat-1M中的提示,但沒有使用答案。我們所有的數(shù)據(jù)都經(jīng)過下面描述的過濾階段。
監(jiān)督微調(diào)(SFT):我們在合成和真實的提示以及主要由教師(一個更大的模型)合成的響應(yīng)上運行行為克隆。我們還在學生的分布上從教師那里進行蒸餾。
基于人類反饋的強化學習(RLHF):我們使用與Gemma 1.1類似的RLHF算法,但使用了不同的獎勵模型,該模型比策略大一個數(shù)量級。新的獎勵模型也更側(cè)重于對話能力,特別是多輪對話。
模型合并:我們對通過使用不同超參數(shù)運行我們的流程獲得的不同模型進行平均。
數(shù)據(jù)過濾:當使用合成數(shù)據(jù)時,我們運行幾個階段的過濾,以刪除顯示某些個人信息、不安全或有毒模型輸出、錯誤自我識別數(shù)據(jù)和重復示例的示例。遵循Gemini的方法,我們發(fā)現(xiàn)包括鼓勵更好的上下文歸屬、謹慎和拒絕以最小化幻覺的數(shù)據(jù)子集,可以提高事實性指標的性能,而不會降低模型在其他指標上的性能。
格式化:Gemma 2模型使用與Gemma 1模型相同的控制標記進行微調(diào),但格式化方案不同。注意,模型明確地以標記結(jié)束生成,而之前它只是生成。有關(guān)這種格式化結(jié)構(gòu)背后的動機,請參閱Gemma 1。
3. 邊緣AI實現(xiàn)
通過這個示例,你可以在樹莓派5上實現(xiàn)機器學習算法。
3.0 收集必要的材料
樹莓派5(帶兼容的電源線)
MicroSD卡(最小32 GB,推薦64 GB或更高)
帶SD卡讀卡器或USB適配器的計算機
HDMI電纜和顯示器/電視
USB鍵盤和鼠標(或如果支持,則使用藍牙)
互聯(lián)網(wǎng)連接(通過Wi-Fi或以太網(wǎng)電纜)
3.1 下載并安裝操作系統(tǒng)
訪問此處了解如何在樹莓派4或5上下載和安裝操作系統(tǒng)。
https://medium.com/p/4dffd65d33ab/edit
3.2 — 安裝Ollama
curl-fsSL https://ollama.com/install.sh | sh
3.3 — 運行g(shù)emma2
ollamarun gemma2:2b --verbose
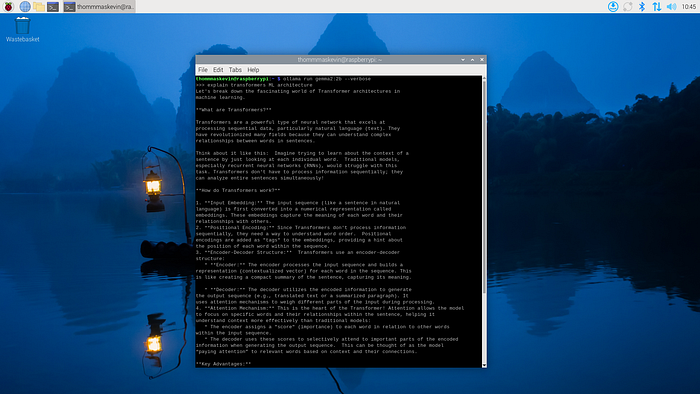
3.4 —問題結(jié)果
問題:解釋Transformer ML架構(gòu)
-
機器學習
+關(guān)注
關(guān)注
66文章
8497瀏覽量
134222 -
樹莓派
+關(guān)注
關(guān)注
121文章
1966瀏覽量
107104 -
集成機器人
+關(guān)注
關(guān)注
0文章
3瀏覽量
2888 -
邊緣AI
+關(guān)注
關(guān)注
0文章
151瀏覽量
5377
發(fā)布評論請先 登錄
樹莓派5,Raspberry Pi 5 評測
Banana Pi 發(fā)布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 計算與嵌入式開發(fā)
樹莓派怎么打造開心農(nóng)場
樹莓派3b用HDMI接電視沒信號的解決方案?
索尼投資樹莓派,共同開發(fā)邊緣 AI 解決方案
樹莓派的學習設(shè)計方案合集

加熱和冷卻樹莓派5(Raspberry Pi5)這是真嘞?

貿(mào)澤現(xiàn)已開售運行速度遠超前代產(chǎn)品的樹莓派5單板計算機
宏集嵌入式工業(yè)樹莓派,為企業(yè)提供更高效、精確和靈活的包裝解決方案

Hailo聯(lián)手樹莓派,開創(chuàng)人工智能新紀元
用 樹莓派 Zero 打造的智能漫游車!
樹莓派分類器:用樹莓派識別不同型號的樹莓派!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論