 電子發燒友App
電子發燒友App


第36屆 SIGCOMM 于2022年8月22日-8月26日在荷蘭阿姆斯特丹召開。本次會議共收到279篇投稿,接收55篇論文,錄取率為19.71%。 ? 廈門大學SNG的同學們按照會議日程對論文內容進行了分期評述,本期介紹session6的論文。 ? Session?6:?Machine Learning
Genet: Automatic Curriculum Generation for Learning Adaptation in Networking
Zhengxu Xia (University of Chicago), Yajie Zhou (Boston University), Francis Y. Yan (Microsoft Research), Junchen Jiang (University of Chicago)
背景
這篇文章來自芝加哥大學,波士頓大學和微軟的研究者。它提出了一個針對增強學習的新框架Genet,利用課程學習(curriculum learning)自動搜索會給訓練帶來實質性改善的環境,逐步提供相對困難的環境以提高學習和訓練效果。 ? 目前,增強學習在網絡領域的應用已經成為了熱點,但在實際應用中仍存在一些限制條件,例如,(1)傳統RL訓練中通常會從給定的訓練范圍內均勻地抽取網絡環境樣本,這使得在狹窄分布上進行訓練時泛化性較差(poor generalizability);(2)在訓練分布較廣的情況下也會出現不容易收斂的情況(poor converged)。因此,需要考慮如何改善RL訓練,使學習到的適應策略在廣泛的目標網絡環境中取得良好的性能。
?
設計
為了解決上述問題,本文提出使用課程學習(curriculum learning)來改變RL訓練環境的分布,引入新環境為模型提供越來越多的學習機會。逐漸增加了訓練環境的難度,因此在訓練中會看到更多更有可能改進的環境,我們稱之為獎勵環境(reward environment)。在許多RL的應用中,先前的工作已經顯示了課程學習的前景,包括更快的收斂、更高的漸進性能和更好的泛化。 ? 那么,隨之需要解決的問題是:我們如何確定哪些環境是對訓練更有益的,也就是說如何按順序排列網絡環境,使得優先考慮當前RL策略的回報率高的環境。本文的工作提出這一觀點:如果當前的RL模型與基線有很大的差距(gap-to-baseline),即RL策略的性能在環境中落后于傳統的基于規則的基線,則認為環境是有價值的。 ? 基于這個觀點,設計出Genet這一學習框架。如圖所示,通過迭代識別當前RL模型與基線有較大差距的獎勵環境,然后將其加入RL訓練,從而生成RL訓練課程。
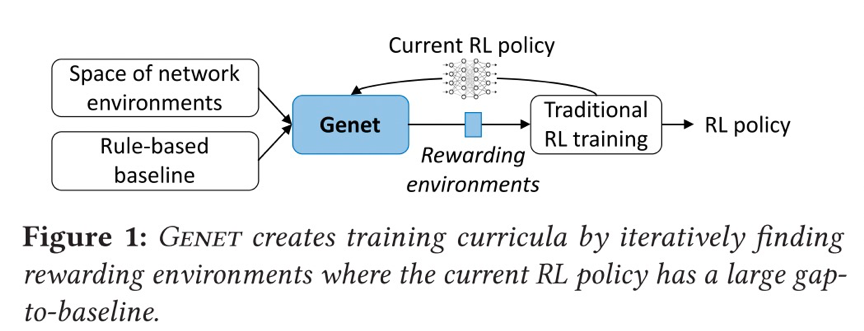
對于每個RL用例,Genet對網絡環境空間進行了參數化,使我們能夠在綜合實例化的環境和跟蹤驅動的環境中搜索到有價值的環境。Genet還使用貝葉斯優化(BO)來促進大空間中的搜索。 ?
評估
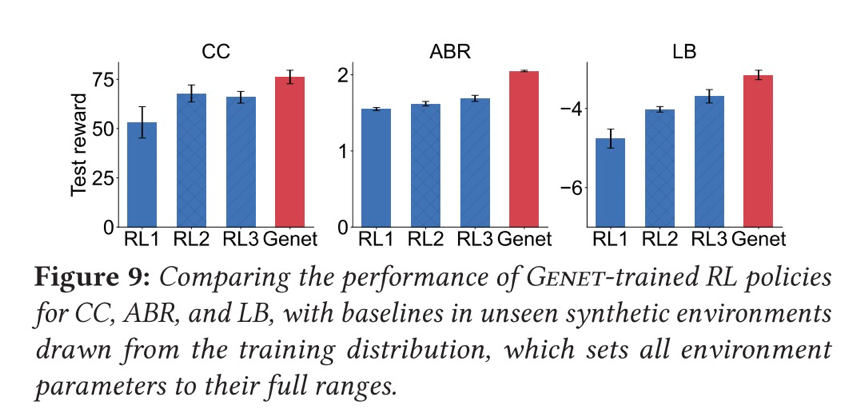
本文使用跟蹤驅動的模擬和真實世界的測試相結合,跨越三個用例(ABR、CC、LB),結果表明Genet與傳統的RL訓練方法相比,ABR的漸進性能提高了8-25%,CC提高了14-24%,LB提高了15%。
個人觀點
在增強學習逐步成為解決網絡領域重要問題的有效手段的背景下,本文工作者研究如果有效提升增強學習訓練的效果,重點關注了訓練環境對訓練效果產生的影響,是一個具有實際意見的研究點,創新點在于利用課程學習的方法為訓練不斷更新合適的環境。但如同在本文討論部分中提到的問題:gap-to-baseline值高或者低的環境是否總是意味著RL模型在對其進行訓練時有小或者大的改進?本文在這一問題上所進行的論證或者實驗不是非常充分。 ?
LiteFlow: Towards High-performance Adaptive Neural Networks for Kernel Datapath
Junxue Zhang, Chaoliang Zeng (Hong Kong University of Science and Technology), Hong Zhang (UC Berkeley), Shuihai Hu, Kai Chen (Hong Kong University of Science and Technology)
背景
自適應神經網絡在變化的環境中可以實現超高性能,所以在操作系統kernel數據路徑中部署這些網絡表現出流行趨勢。然而,現有的部署方法存在局限性。一種部署的方法是部署在user-space,然而,這樣的方法導致很高的cross-space 通信開銷和低響應,極大影響了函數性能;另一種方法是部署到純kernel-space,但這種方法會導致很大的性能下降,因為典型的模型微調的算法的計算邏輯十分復雜,干擾了正常的datapath的執行性能。模型推理要求快速執行,適合kernel-space,模型微調要求高精度和大量的計算,適合部署在user-space。 ?
設計
基于以上的觀察,一種符合直覺的方法是解耦自適應神經網絡的控制路徑:模型推理放到kenel-space,模型微調放到user-space。 ? 然而,實現這個思路有3個挑戰:1. 這樣的設計要求兩個目標:既兼容kenel-space,又兼容user-space,要求大量的開發和debug;2.kernel-space的神經網絡不能及時體現神經網絡微調的結果;3.在user-space訓練要求從kernel-space的數據傳輸,導致性能下降。 ? 為了解決這些挑戰,作者提出LiteFlow。LiteFlow將自適應神經網絡的控制路徑解耦為:為高效模型推理的kernel space快速路徑,為有效模型微調的user space慢速路徑。設計框架上,Lite Flow是一個混合框架,它包括user-space的組件和kernel-space的組件。給定一個user-space的神經網絡,LiteFlow首先生成神經網絡快照,該快照將被部署到kernel-space以實現快速推理。同時,LiteFlow也收集該快照的輸入和輸出數據來進一步微調user-space的神經網絡。在訓練幾批數據后,LiteFlow將評估是否需要更新快照。
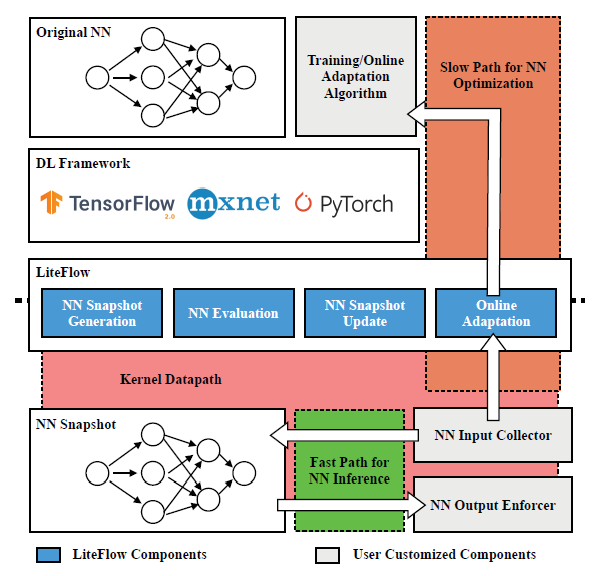
評估
作者在congestion control(Aurora和MOCC模型),flow scheduling(FFNN模型)和path selection(MLP模型)任務中評估了LiteFlow的效果。在congestion control中,神經網絡的輸入是RTT,ECN等這些擁塞信號,輸出是流的發送速率。Aurora使用強化學習算法,利用2層全連接層;MOCC使用多目標強化學習,用2層全連接層,提升了Aurora的設計。對比方法選擇的是純user-space發布,傳統在kernel-space發布。實驗結果顯示,LiteFlow可以實現更高的有效吞吐量,分別超出44.4%和26.6%,此外,吞吐量的標準差也更小,說明LiteFlow緩解了cross-space通信。為了測試在線自適應能力,作者禁用LiteFlow的神經網絡自適應功能,實驗結果表明goodput顯著下降。 ? 在開銷方面,使用LiteFlow部署的性能和kernel-space的相近,超出user-space的性能,表明緩解cross-space的開銷是重要的。為了理解批數據不同傳輸間隔的影響,作者也進行相關實驗,結果表明所花費的時間不超過14.1%。 ? 此外,LiteFlow在高吞吐量時性能下降不超過5%。 ? 在flow scheduling場景中,作者對比了FFNN在user-space和LiteFlow的FFNN,預測延遲和flow completion time的實驗結果表明,LiteFlow的延遲更低,在flow completion time上表現更優。 ? 在load balancing上,作者使用的神經網絡是MLP,對比的方法是user-space方式和禁止更新的LiteFlow,結果表明LiteFlow在短流和長流上都超出對比方法。 ?
總結
LiteFlow通過將kernel-space、user-spcae與inference、training分別對齊,實現了自適應神經網絡的高性能推理、基于反饋更新。實驗結果證明了方法有效。 ?
個人觀點
神經網絡的推理引擎已經有很多,比如mnn等。然而,考慮到在線學習維度,當前的推理引擎和訓練引擎都不能很好滿足。這篇論文分析了神經網絡訓練和推理的特點、user-sapce和kernel-sapce的特點,然后設計LiteFlow將之對齊,彌補了之前的研究空白。 ?
Multi-Resource Interleaving for Deep Learning Training
Yihao Zhao, Yuanqiang Liu (Peking University), Yanghua Peng, Yibo Zhu (ByteDance Inc.), Xuanzhe Liu, Xin Jin (Peking University)
背景
訓練深度學習模型正在成為計算集群的重要負載之一。該訓練過程需要多種資源,包括CPU,GPU,存儲IO,網絡IO。在典型的多任務場景下,如何為不同作業分配合適的資源是一個經典調度問題。然而,現有的深度學習調度器聚焦在GPU分配上,忽視了其他類型資源的調度。 ?
設計
為了實現多種資源的高效調度,作者提出了深度學習訓練作業的key observations:訓練深度學習模型表現出明顯的階段性,這樣的階段迭代進行。這個現象為時間上細粒度的多資源交替使用創造了條件。比如,深度學習訓練的每個階段包括數據加載、預處理、前向和反向傳播、梯度同步操作。每個子階段都高度使用一種資源,這使不同作業的不同階段在資源集合上交替執行成為可能。 ? 作者提出Muri。Muri的核心思想是調度多個作業對資源的交替使用來最大化資源利用率或作業完成時間。Muri把交替作業調度問題建模為k維最大帶權匹配問題,采用Blossom算法為單個GPU作業在兩種資源類型之間找到最佳組合計劃,并且使用多輪方法來處理超過兩種資源的情況。 ? 在架構上,Muri包括3個組件:resource profiler,job scheduler、worker monitor。 ? resource profiler負責測量每個job對每種資源的利用情況,并估計不同作業交替時的效率;job scheduler維護一個job queue,當job到達或job完成時,基于不同job group的交替效率和resource profiler的信息,job scheduler使用多輪job 聚類算法來決定哪些job組成群體來共享資源,從而實現資源利用最大化;worker monitor負責收集每臺機器的資源信息并跟蹤每個job的訓練進度。最后,基于job scheduler生成的策略,每臺機器上會配備Muri executor,它負責將策略具體執行。
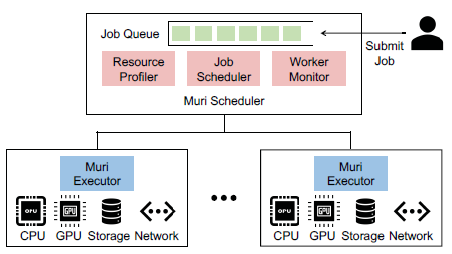
評估
作者建立了Muri原型,并集成到PyTorch中。實驗評估選擇在一個8臺機器,每臺機器配備8個GPU、2個Xeon Platinum、256GB內存、1個Mellanox CX-5單口網卡的集群上進行。作者使用了Microsoft的trace。在作業時間已知時,選擇SRSF和2D-LAS作為對比方法;在作業時間未知時,選擇Tiresias,AntMan和Themis作為對比方法。實驗結果表明,和現有的深度學習調度器相比,Muri在JCT方面提升3倍,在makespan上提升1.6倍。 ?
總結
作者觀察到深度學習作業存在階段迭代特征,聯系到這些作業的訓練會使用多種類型資源,因此提出使用多資源交替來提升集群和作業效率。作者首先把調度問題建模為k維最大帶權匹配問題,然后使用Blossom算法求解最佳組合計劃。實驗效果驗證了該方法可以提升資源效率和作業完成時間。 ?
個人觀點
盡管作者在文中做了大量努力來區分Muri與pipeline,但本人覺得Muri可以看作是pipeline擴到到multi-job時的調度問題,因此研究問題的價值有限。會議上,有人問到的2個問題:一是關于multi-job的交替執行安全性問題,二是關于profiler準確性問題。和提問者一樣,個人對這2點也持保留意見,作者在會議上的答復并不令人信服。 ?
DeepQueueNet: Towards Scalable and Generalized Network Performance Estimation with Packet-level Visibility
Qing-Qing Yang, Xi Peng (Huawei Theory Lab), Li Chen (Zhongguancun Laboratory), Libin Liu (Shandong Computer Science Center), Jingze Zhang, Hong Xu (Chinese University of Hong Kong), Baochun Li (University of Toronto), Gong Zhang (Huawei Theory Lab)
這篇工作來自華為理論實驗室,中關村實驗室,香港中文大學,山東省計算機科學中心和多倫多大學的多位研究者。通過將基于可擴展DNN的連續仿真與離散事件仿真相結合,提出了一種可擴展的、可推廣的、具有包級可見性的網絡性能估計器DeepQueueNet。 ?
背景
網絡模擬器是網絡操作人員理解實際應用任務網絡的重要工具,可以幫助完成容量規劃、拓撲設計和參數調優等任務。目前,主流的模擬器都是基于離散事件模擬的,它們的性能無法適應現代網絡的規模。同時,隨著基于深度學習的技術被引入來解決可擴展性問題,本文工作者通過實驗表明它們的模擬結果的可見性很差,并且不能推廣到不同的場景。因此,我們需要一個具有更好的通用性,更高的可擴展性,并且在數據包級別具有可見性的網絡模擬器。 ?
設計
本文結合了離散事件模擬 (DES) 和連續模擬,提出了一個高層次的設計方法:首先建立一個理論基礎來盡可能多地表達我們對網絡的先驗知識,然后識別數學上難以處理或計算量大的部分,最后將這些部分替換為可以使用真實數據跟蹤訓練的 DNN。按照這一思路,本文縮小 DNN 在端到端性能評估器 (EPE) 中的應用范圍——從網絡/集群規模到設備規模,僅使用 DNN 來對設備本地交通管理 (TM) 機制進行建模。本文使用兩個子模型組成設備模型:數據包級轉發模型(PFM)和數據包級 TM 模型(PTM)。PFM 指定轉發行為,可以使用給定路由表的張量乘法來明確描述。PTM 預測每個數據包經歷多少延遲。 ? 如圖所示為DeepQueueNet的架構,由五個核心組件組成:(1)設備模型實用程序 (DUtil) 生成經過訓練的設備模型;(2)設備模型庫 (DLib) 存儲和索引經過訓練的設備模型,包括交換機、路由器和鏈路;(3)流量生成實用程序 (TGUtil) 根據用戶規范創建流量生成器 (TGen);(4)模擬設置模塊 (SInit) 解析用戶輸入并設置模擬;(5)模擬執行模塊 (SRun) 運行模擬。與現有 DES 實現的工作流程相同類似,DeepQueueNet 通過以下步驟完成任務:準備模擬設置(拓撲、設備配置和流量生成器)、運行模擬、收集數據包跟蹤以及通過將任意度量應用于結果進行分析。
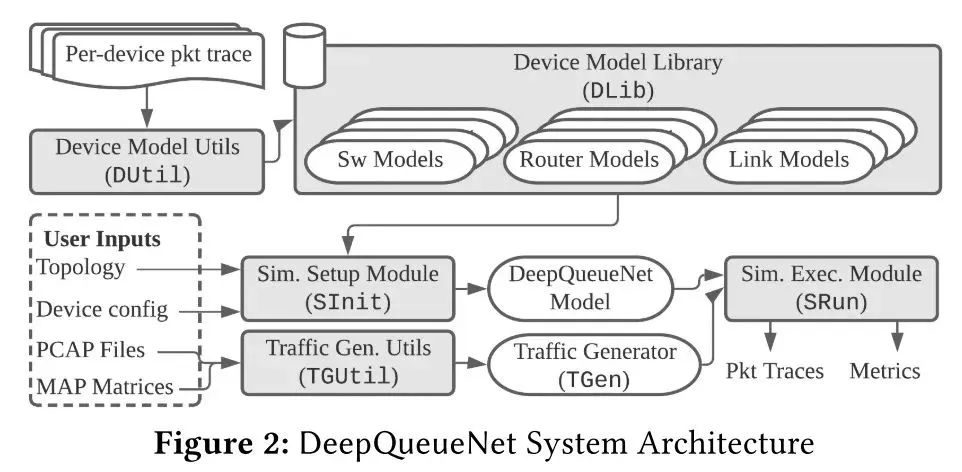
評估
1)準確性:與最先進的基于 DNN 的 EPE相比,DeepQueueNet 在所有場景中的平均和第 99 個百分位往返時間 (RTT) 均實現了卓越的準確性。 ? 2)泛化性:通過大量實驗表明,DeepQueueNet 關于歸一化 wasserstein distance的估計精度在拓撲、TM配置和流量生成模型的變化中仍然很高,無需重新訓練模型。 ? 3)可擴展性:展示了DeepQueueNet可以使用多個GPU 并行加速。本文在4-GPU集群上部署DeepQueueNet,它展示了隨著 GPU 數量的近線性加速。 ?
個人觀點
這篇論文的工作量十分扎實,提出的DeepQueueNet系統框架的建模也較為復雜。創新地將主流的網絡模擬器從離散事件拓展到基于DNN的連續模擬與離散事件模擬相結合,基于先驗知識縮小DNN的應用范圍。這些方法較為新穎,但是由于個人水平有限,對于整個系統的設計細節還未有更深入的理解,期待看到這個工作在更多評估實驗和實際應用中的性能測試。 ?
Practical GAN-based Synthetic IP Header Trace Generation using NetShar
Yucheng Yin, Zinan Lin, Minhao Jin, Giulia Fanti, Vyas Sekar (Carnegie Mellon University)
本文來自卡內基·梅隆大學的研究者,它探索了使用生成對抗網絡 (GAN) 自動學習生成模型以生成用于網絡任務(例如遙測、異常檢測、配置)的數據包和流級別的標頭跟蹤(Packet- and flow-level header traces)的可行性,并開發出一個端到端框架NetShare ?
背景
數據包和流級別的標頭跟蹤對于許多網絡管理工作流至關重要。它們用于指導網絡監控算法的設計和開發,開發新型異常檢測和指紋識別以及用于基準測試去檢驗新的硬件和軟件功能。由于隱私性等問題,我們無法直接訪問此類痕跡。往往通過合成痕跡(synthetic traces)來實現。目前,存在通過模擬驅動方法(simulation-driven)、模型驅動方法(model-driven)和機器學習模型(machine learning models)的方法生成合成痕跡的工作,但這些方法都各自存在問題:比如說基于模擬和模型驅動的方法需要大量的領域知識和人力來確定關鍵的工作負載特性和配置生成參數,同時不能很好地跨應用程序進行泛化。基于機器學習的方法容易泛化,但無法捕獲特定領域的屬性。 ? 因此在這項工作中,研究者探索了使用生成式對抗網絡生成基于ML的合成包頭和流頭跟蹤的可行性,并設計出NetShare用來產生合成痕跡從而解決上述問題。 ?
設計
1)本文將標頭跟蹤生成(header trace generation)重新表述為一個時間序列生成問題,即生成整個跟蹤的流量記錄,而不是每個epoch的表格方法。 ?
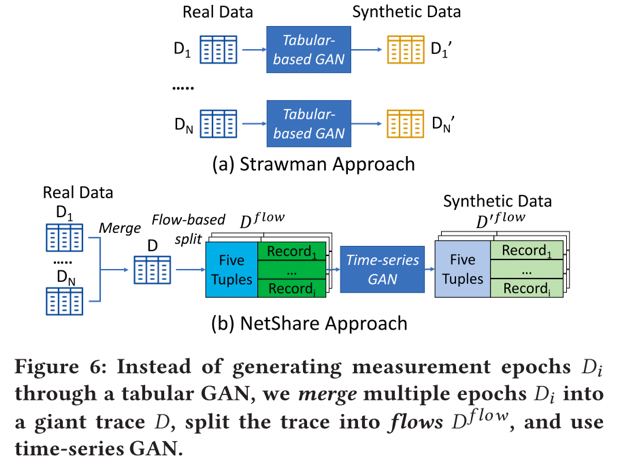
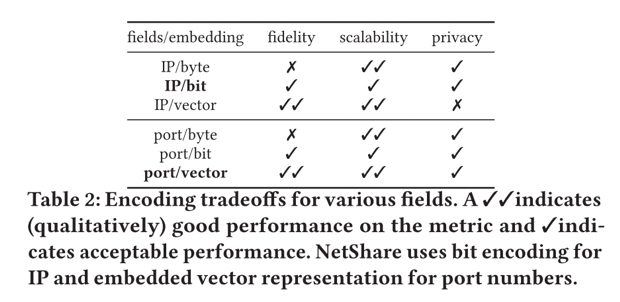
2)本文使用領域知識和機器學習的細致組合來告知標頭字段的表示,以平衡保真度-隱私-可擴展性的權衡。 ? 本文不是在原始數據表示上訓練GAN,而是使用領域知識將某些領域轉換為更易于 GAN 處理的格式。對于具有數字語義的字段,例如每個流的數據包/字節數,我們使用對數轉換。對于 IP 地址/端口號/協議等分類字段,使用 IP 地址的按位編碼,使用 IP2Vec 對端口號和協議進行編碼。表格顯示了針對 IP/端口的不同嵌入選擇在保真度、可擴展性和隱私性方面的定性分析。
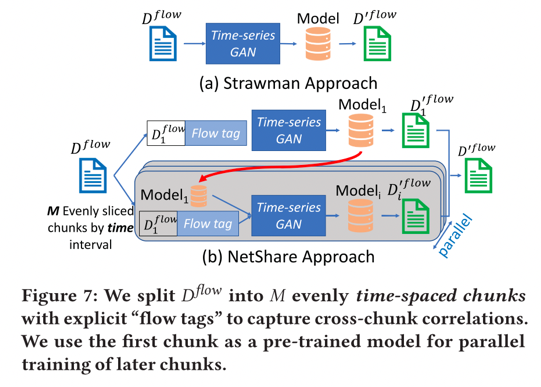
3)本文可以通過微調和并行訓練來提高可擴展性和保真度的權衡。 ? 首先,本文工作者從 ML文獻中借用微調的想法,即:使用預訓練模型作為“熱啟動”來為未來模型進行種子訓練。具體來說,使用第一個塊作為“種子”塊來進行熱啟動,隨后的塊使用從第一個塊訓練的模型進行微調,這允許跨塊進行并行訓練。同時本文們將“flowtags”附加到每個flowheader以捕獲塊間的相關性,用0-1標志注釋每個流標頭,表示它是否從“this”塊開始,還在標志之后附加一個0-1向量,其長度等于塊的總數,每個位指示流標頭是否出現在該特定塊中。
? 4)本文可以通過謹慎使用公共數據集來改善隱私-保真度的權衡。在 NetShare 中,研究者利用以下觀察結果:通過在相關公共數據集上預訓練 NetShare,可以減少達到固定保真度水平所需的 DP-SGD 輪數;然后,再從公共數據集中獲取學習參數,并使用 DP-SGD 3 這些在私有數據集上進行微調。這樣做可以減少了所需的 DP-SGD 迭代次數。
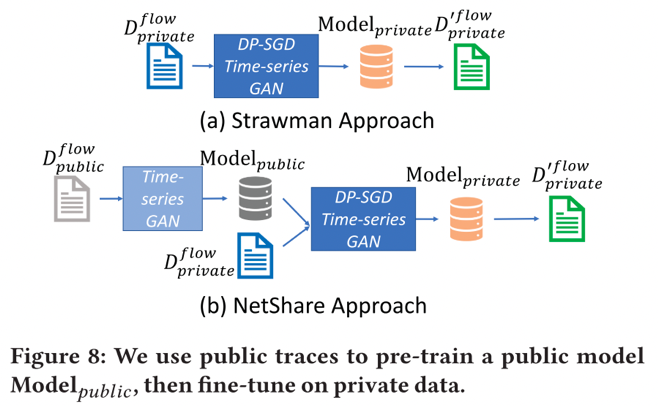
評估
我們在六個不同的數據包頭跟蹤上評估 NetShare,結果表明 : ? 1) 在所有的分布指標和跟蹤中,NetShare比使用不同生成式建模技術的基線方法的準確率高出46%。 2) NetShare滿足了用戶對下游任務的要求,保持了算法的準確性和有序性。 3) NetShare實現了比基線更好的可擴展性-保真度權衡。 4) 與基線方法相比,NetShare可以產生更高質量的差異化的私有痕跡。 ?
個人觀點
這也是一篇應用深度學習領域技術解決網絡問題的工作,創新點在于提出使用GAN來生成數據包和流級別的標頭跟蹤,是一個值得深入研究的方向。在本文中,針對生成的標頭跟蹤在實際網絡任務中的實驗結果不是很多,并且對于提出的端到端框架NetShare的可拓展性缺乏說明。 ? ?



















 工商網監
工商網監
評論