 谷歌 | 大規模深度推薦模型的特征嵌入問題有解了!
谷歌 | 大規模深度推薦模型的特征嵌入問題有解了!
導讀:本文主要介紹下Google在大規模深度推薦模型上關于特征嵌入的最新論文。
一、背景
大部分的深度學習模型主要包含如下的兩大模塊:輸入模塊以及表示學習模塊。自從NAS[1]的出現以來,神經網絡架構的設計上正在往數據驅動的自動機器學習方向演進。不過之前更多的研究都是聚焦在如何自動設計表示學習模塊而不是輸入模塊,主要原因是在計算機視覺等成熟領域原始輸入(圖像像素)已經是浮點數了。
輸入模塊:負責將原始輸入轉換為浮點數;表示學習模塊:根據輸入模塊的浮點值,計算得到模型的最終輸出;
而在推薦、搜索以及廣告工業界的大規模深度模型上,情況卻完全不同。因為包含大量高維稀疏的離散特征(譬如商品id,視頻id或者文章id)需要將這些類別特征通過embedding嵌入技術將離散的id轉換為連續的向量。而這些向量的維度大小往往被當做一個超參手動進行設定。
一個簡單的數據分析就能告訴我們嵌入向量維度設定的合理與否非常影響模型的效果。以YoutubeDNN[2]為例,其中使用到的VideoId的特征詞典大小是100萬,每一個特征值嵌入向量大小是256。僅僅一個VideoId的特征就包含了2.56億的超參,考慮到其他更多的離散類特征輸入模塊的需要學習的超參數量可想而知。相應地,表示學習模塊主要包含三層全連接層。也就是說大部分的超參其實聚集在了輸入模塊,那自然就會對模型的效果有著舉足輕重的影響。
二、主要工作
Google的研究者們在最新的一篇論文[3]中提出了NIS技術(Neural Input Search),可以自動學習大規模深度推薦模型中每個類別特征最優化的詞典大小以及嵌入向量維度大小。目的就是為了在節省性能的同時盡可能地最大化深度模型的效果。
并且,他們發現傳統的Single-size Embedding方式(所有特征值共享同樣的嵌入向量維度)其實并不能夠讓模型充分學習訓練數據。因此與之對應地,提出了Multi-size Embedding方式讓不同的特征值可以擁有不同的嵌入向量維度。
在實際訓練中,他們使用強化學習來尋找每個特征值最優化的詞典大小和嵌入向量維度。通過在兩大大規模推薦問題(檢索、排序)上的實驗驗證,NIS技術能夠自動學習到更優化的特征詞典大小和嵌入維度并且帶來在Recall@1以及AUC等指標上的顯著提升。
三、Neural Input Search問題
NIS-SE問題:SE(Single-size Embedding)方式是目前常用的特征嵌入方式,所有特征值共享同樣的特征嵌入維度。NIS-SE問題就是在給定資源條件下,對于每個離散特征找到最優化的詞典大小v和嵌入向量維度d。
這里面其實包含了兩部分的trade-off:一方面是各特征之間,更有用的特征應該給予更多的資源;另一方面是每個特征內部,詞典大小和嵌入向量維度之間。對于一個特征來說,更大的詞典可以有更大的覆蓋度,包含更多長尾的item;更多的嵌入向量維度則可以提升head item的嵌入質量,因為head item擁有充分的訓練數據。而SE在資源限制下無法同時做到高覆蓋度和高質量的特征嵌入。所以需要引入ME(Multi-size Embedding)。
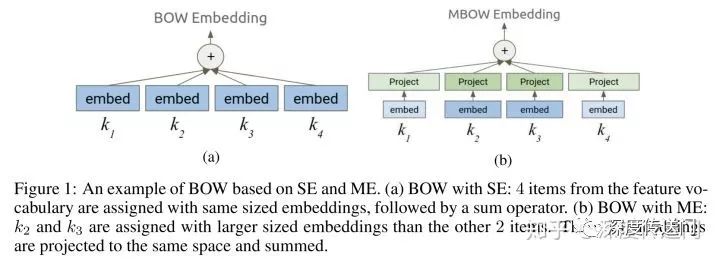
NIS-ME問題:ME允許每個特征詞典內不同的特征值可以有不同的嵌入向量維度。其實就是為了實現越頻繁的特征值擁有更大的嵌入特征維度,因為有更多的訓練數據;而長尾的特征值則用更小的嵌入特征維度。引入ME為每一個類別離散特征找到最優化的詞典大小和嵌入向量維度,就可以實現在長尾特征值上的高覆蓋度以及在頻繁特征值上的高質量嵌入向量。下圖給出了embedding使用的場景例子中,SE和ME使用上的區別。
四、NIS解決方案
要想為每個類別離散特征手動找到最優化的詞典大小和嵌入向量維度是很難的,因為推薦廣告工業界的大規模深度模型的訓練時很昂貴的。為了達到在一次訓練中就能自動找到最優化的詞典大小和嵌入向量維度,他們改造了經典的ENAS[4]:
首先針對深度模型的輸入模塊提出了一個新穎的搜索空間;
然后有一個單獨的Controller針對每一個離散特征選擇SE或者ME;
其次可以根據Controller決策后考慮模型準確度和資源消耗計算得到reward;
最后可以根據reward使用強化學習A3C[5]訓練Controller進行迭代。
搜索空間
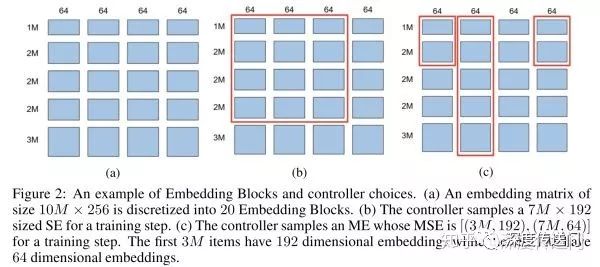
Embedding Block的概念實際上就是原始Embedding矩陣的分塊。如下圖所示,假設原始Embedding矩陣大小是(10M,256),圖a將其分成了20個Embedding Block。Controller為每個特征有兩種選擇:圖b所示的SE以及圖c的所示的ME。
Reward函數
主模型是隨著Controller的選擇進行訓練的,因此Controller的參數實際上是根據在驗證集上前向計算的reward通過RL追求收益最大化而來。考慮到在限定資源下的深度模型訓練,這里的reward函數設計為同時考慮業務目標與資源消耗。對于推薦領域的兩大主要任務:信息檢索和排序,信息檢索的目標可以使用Sampled Recall@1;而排序的目標則可以使用AUC。
五、實驗結果
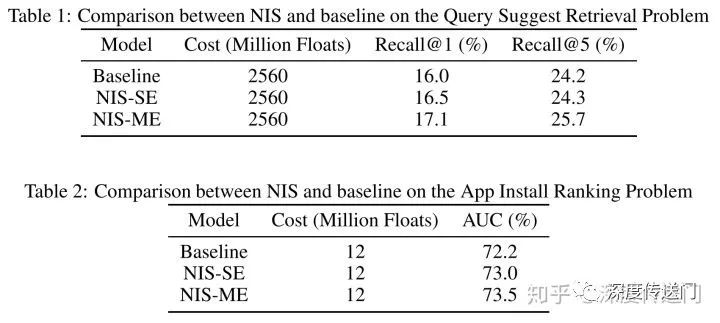
他們在兩大大規模推薦模型問題:檢索和排序上進行了實驗。在同等資源消耗的情況下,NIS可以獲得顯著提升,詳細數據如下圖所示。
-
谷歌
+關注
關注
27文章
6223瀏覽量
107555
原文標題:Google最新論文:大規模深度推薦模型的特征嵌入問題有解了!
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AI原生架構升級:RAKsmart服務器在超大規模模型訓練中的算力突破
谷歌新一代 TPU 芯片 Ironwood:助力大規模思考與推理的 AI 模型新引擎?
大模型領域常用名詞解釋(近100個)

淺談適用規模充電站的深度學習有序充電策略
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
谷歌發布“深度研究”AI工具,利用Gemini模型進行網絡信息檢索
NVIDIA與谷歌量子AI部門達成合作
使用EMBark進行大規模推薦系統訓練Embedding加速






 工商網監
工商網監
評論