 聚焦 | 新技術“紅”不過十年?半監督學習卻成例外?
聚焦 | 新技術“紅”不過十年?半監督學習卻成例外?
這一波深度學習的發展,以2006年Hinton發表Deep Belief Networks的論文為起點,到今年已經超過了10年。從過往學術界和產業界對新技術的追捧周期,超過10年的是極少數。從深度學習所屬的機器學習領域來看,到底什么樣的方向能夠支撐這個領域繼續蓬勃發展下去,讓學術界和產業界都能持續投入和產出,就目前來看,半監督學習是一個很有潛力的方向。
機器學習范式的發展
傳統機器學習的解決路徑可以表示為:
ML Solution = ML expertise + Computation + Data
其中ML expertise是機器學習專家,負責特征工程、機器學習模型設計和最終的訓練,是整個機器學習解決方案效果的關鍵因素。Computation是計算能力,代表具體選擇什么的硬件去承載專家設計的優化方案。這個部分一般來說窮有窮的打法,富有富的策略:以CTR預估為例,小廠設備不多,資源不足,那么可能GBDT就是一個不錯的選擇;大廠的話,資源相對富裕,那么各種DNN就上來了。Data無論做什么業務,或多或少也都有一些,C端產品的話,上線后總會有用戶反饋可以做為label;B端產品的話,以我曾經搞過的圖片識別為例,定向爬蟲和人工標注也能弄到有標簽樣本。Data總會有,無外乎多少的區別。
這里就存在一個問題,Computation和Data即便有了,也不一定有很匹配的人來把整個事情串聯運用起來,發揮最終的價值。21世紀,最貴的是人才;為什么貴?因為稀缺。于是大家就在想,能不能把機器學習問題的解決路徑改為:
New ML Solution = 100x Computation + 100x Data
簡而言之,就是用更多地Computation和Data代替人的作用。100x Computation替代人工模型設計,這兩年也得到了長足的發展,這就是AutoML。狹義的來看AutoML,NAS和Meta Learning在學術界工業界都有不錯的進展。尤其是NAS,2017年Zoph和Le發表的Neural Architecture Search with Reinforcement Learning作為引爆點,快速形成了一個火爆的研究領域,主要思路是通過RNN controller來sample神經網絡結構,訓練這個網絡結構,以這個網絡結構的指標作為RL的reward優化這個controller,讓這個controller能夠sample出更有效的網絡結構。
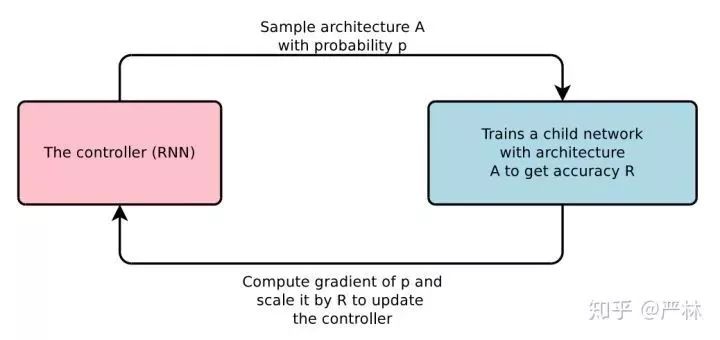
Controller訓練過程
這個領域后續還有一些列出色的工作,但由于不是今天討論的重點,暫且按下不表,有時間再寫一篇關于NAS的從認知到實踐。
100x Data聽上去就是一個很有誘惑力的事情,因為更多的數據,往往意味著更好的效果。以最近異常火爆的BERT和GPT2,都被認為是大力出奇跡的暴力美學典范。大量的數據帶來效果提高了人們對當前AI的認知邊界,GPT2生成的文本就是一個很好的例子。但是數據規模的擴大,往往意味著某方面成本的提升。廣告CTR預估,100x的樣本要么是DAU增長了100倍,要么是出了100x的廣告(估計會被用戶打死的),都不太真實;圖片的人工標注增長100x即便金錢成本能接受,時間成本也太長,猜想ImageNet如果1億標注樣本,估計CV的發展還會有更多的爆發點。
在談半監督學習的進展前,我們先看看另一個機器學習方向在解決數據不足和數據稀疏上的努力。
Multi-Task Learning
Multi-Task Learning是指不同的任務之間通過共享全部或者部分模型參數,相互輔助,相互遷移,共同提高的機器學習方法。實際使用過程中,Multi-Task Learning由于多個任務共享參數,還能帶來Serving Cost的下降,在學術界和工業界都有不少相關工作,并且在一些數據上取得了不錯的進展。
Multi-Task Learning由于不同任務之間可以相互輔助學習,往往數據稀疏的任務能夠從數據豐富的任務收益,得到提高,同時數據豐富任務還不怎么受影響或者微弱提升。這在一定程度上緩解了數據量的需求。
最近幾年比較好的Multi-Task Learning工作,首先讓我比較有印象的是Cross-stitch。Cross-stitch通過在Multi-Task的表達學習中,通過權重轉換矩陣 alpha_{AB} 或者 alpha_{BA} 直接獲得另一個任務的中間表示信息,這種方案在效果上比傳統的Shared Bottom靈活,也減少了模型參數被某一個任務完全主導的風險。
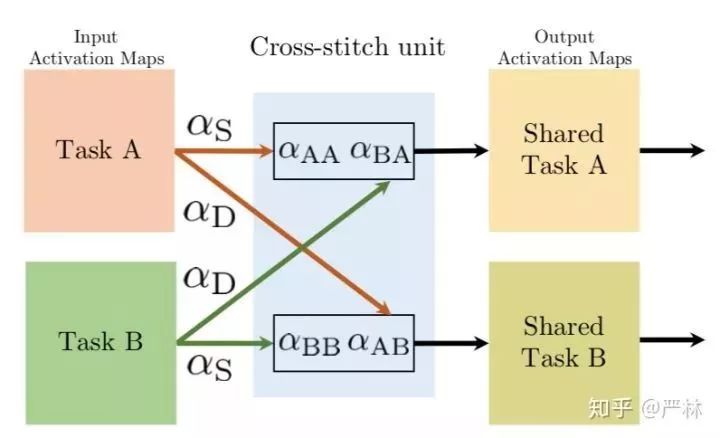
Cross-stitch子結構
后來的ESSM跟Cross-stitch有異曲同工之妙,只是將任務的學習方向改為單向:pCVR單向從pCTR中學習,以滿足業務上的邏輯因果關系。
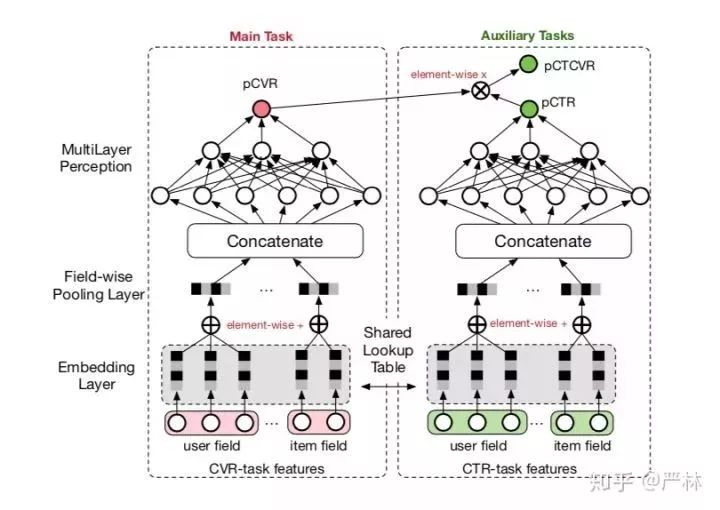
ESSM學習框架
Multi-Task Learning最近比較有意思的工作,SNR應該算一個,思路主要收到Mixture-of-Expert的啟發(Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer:這篇文章背后的思想其實是Google解決大規模機器學習的新思路,完全值得開篇另述!),不同的任務走不同的網絡路由,即不同的任務會由不同的Experts組合預估,而Experts總量固定,在不同任務間是部分共享的。對比Cross-stitch,每個任務都必須使用另外任務的信息,這種網絡架構設計,使得不同任務的Expert既有獨立又有共享。具體的獨立和共享方式,每個任務通過模型訓練學習得到,比較好的平衡了任務的獨立性和共通性。SNR還使用了稀疏路由的思想,使得每個任務在保證效果的前提下經過最少的Experts,降低計算量。

Multi-Task Learning在學術界和工業界都獲得了不俗的成績,但是也有一個要命的短板,需要另外一個數據豐富且能夠學習比較好的任務幫忙。這個要求限制了Multi-Task Learning發揮的空間,因為很多情況下,不僅沒有其他任務,僅有的任務label也很匱乏,于是半監督學習就有了用武之地。
半監督學習
半監督學習通常情況下,只有少量的有label數據,但是可以獲得大量的無label數據,在這種情況下希望能夠獲得跟監督學習獲得相似甚至相同的效果。半監督學習的歷史其實已經也比較久遠了,2009年Chapalle編著的Semi-Supervised Learning,就對其定義和原理做了詳細介紹。在計算力隨著深度學習的熱潮快速發展的同時,大量的label貧困任務出現,于是半監督學習也越來越重要。
半監督學習近兩年最有亮點的工作當屬發表在EMNLP'2018的Phrase-Based & Neural Unsupervised Machine Translation,大幅提升了半監督機器機器翻譯的SOTA。
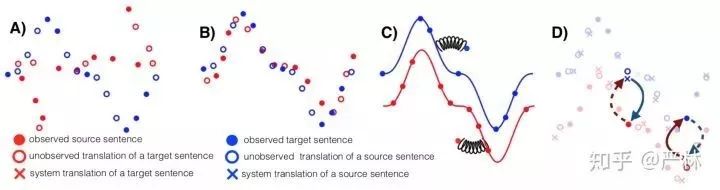
翻譯訓練過程示意
在整個訓練過程中,B)先對其兩種語言的work級別翻譯,然后C)針對兩種語言分別學一個Language Model,獲得語言分布,最后D)再根據語言分布反復使用Back-Translation在已知的少量句對上翻譯獲得最終模型。這種方案大幅提高了在對齊句對不多的語種之間的翻譯質量,同時由于其novelty,獲得了EMNLP'2018的Best Paper Award,初讀此文時有一種眼前一亮的感覺。(盡管標題叫Unsupervised Machine Translation,但是實際上利用到了部分label數據,我更愿意將其歸類為Semi-Supervised Machine Translation。)
最近Google的研究人員又提出來一種新的半監督訓練方法MixMatch,這種方法號稱是Holistic的,綜合運用了:A)distribution average; B)temperature sharpening; C)MixUp with labeled and unlabeled data. 其訓練過程如下:

這個方法在CIFAR-10上只有250個label時能將錯誤率從38%降到11%,令人印象深刻。『江山代有才人出』,另一波Google的研究人員提出了UDA,在我看來這種方法更為徹底,也更加End-to-End。UDA主要利用數據分布的連續性和一致性,在輸入有擾動的情況下,輸出應該保持穩定,于是對于unlabeled data增加了一個損失函數:

即有擾動和無擾動的unlabeled data的預估分布的KL距離應該非常小,同時數據擾動用盡可能貼近任務本身的方法去做,比如圖像用AutoArgument,文本用上面提到的Back-Translation和Word Replacement。
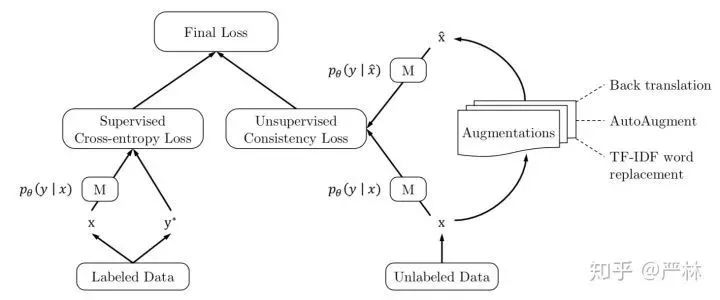
UDA訓練示意
UDA的效果在文本和圖像上都得到了很好地驗證,大幅降低標注數據不足情況下得錯誤率;更值得關注的一點是,即便在ImageNet這種標注數據已經非常多的情況下,再使用UDA依然能帶來效果的提升,說明UDA在數據分布擬合上具有很好地通用性。
結語
總體來看,半監督機器學習無論是采用聚類、圖傳播、數據增強還是泛化學習,主要依據的理論基礎都是labeled和unlabeled data在分布上的連續性和一致性,因此機器學習方法可以利用這點進行有效的結構化學習,增強模型的表征能力,進而很好地提高預測效果。雖然半監督機器學習已經取得了一些很好的結果,從近兩年ICML、ICLR和NeurIPS等會議看,相關工作也越來越多,但是還遠沒有到CV中的ResNet和NLP中的BERT的水平,要實現100x Data真正發揮作用,還需要學術界和工業界共同努力。
-
深度學習
+關注
關注
73文章
5554瀏覽量
122475 -
半監督學習
+關注
關注
0文章
20瀏覽量
2608
原文標題:新技術“紅”不過十年,半監督學習為什么是個例外?
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
2025年恩智浦創新技術峰會上海站圓滿落幕
使用MATLAB進行無監督學習

睿創微納五年&十年功勛員工頒獎大會圓滿舉行
聚焦離子束技術的歷史發展

時空引導下的時間序列自監督學習框架

沃達豐與谷歌深化十年戰略合作
特斯拉與晶圓廠商或簽訂十年長單,深化供應鏈合作
2024激光顯示技術與產業發展大會:共繪未來十年藍圖
哪種嵌入式處理器架構將引領未來十年的發展?

十年預言:Chiplet的使命
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
BOE京東方與聯合國教科文組織UNESCO簽訂合作協議 成為首個支持聯合國“科學十年”的中國科技企業






 工商網監
工商網監
評論