") 算法 | 超Mask RCNN速度4倍,僅在單個GPU訓練的實時實例分割算法
算法 | 超Mask RCNN速度4倍,僅在單個GPU訓練的實時實例分割算法
在論文《YOLACT:Real-time Instance Segmentation》中,作者提出了一種簡潔的實時實例分割全卷積模型,僅使用單個 Titan Xp,以 33 fps 在MS COCO 上實現(xiàn)了 29.8 的 mAP,速度明顯優(yōu)于以往已有的算法。而且,這個結果是就在一個 GPU 上訓練取得的!
引言
一開始,作者提出了一個疑問:創(chuàng)建實時實例分割算法需要什么?
在過去的幾年中,在實例分割方向取得了很大進展,部分原因是借鑒了物體檢測領域相關的技術。比如像 mask RCNN 和 FCIS 這樣的實例分割方法,是直接建立在像Faster R-CNN 和 R-FCN 這樣的物體檢測方法之上。然而,這些方法主要關注圖像性能,而較少出現(xiàn) SSD,YOLO 這類關注實時性的實例分割算法。因此,本文的工作主要是來填補這一空白。SSD 這類方法是將 Two-Stage 簡單移除成為 One-Stage 方法,然后通過其它方式來彌補性能的損失。而這類方法在實例分割領域擴充起來卻并不容易,由于 Two-Stage 的方法高度依賴于特征定位來產(chǎn)生 mask,而這類方法不可逆。而 One-Stage 的方法,如 FCIS,由于后期需要大量的處理,因此也達不到實時。
YOLACT 介紹
基于此,作者在這項研究中提出一種放棄特征定位的方法——YOLACT(You Only Look At CoefficienTs)來解決實時性問題。
YOLACT 將實例分割分解為兩個并行任務:(1)在整副圖像上生成非局部原型 mask 的字典;(2)為每個實例預測一組線性組合系數(shù)。 從這兩部分內(nèi)容生成全圖像實例分割的想法簡單:對于每個實例,使用預測的系數(shù)線性組合原型,然后用預測邊界框來 crop。作者通過這種方式來讓網(wǎng)絡學會如何定位實例mask本身,這些在視覺上,空間上和語義上相似的實例,在原型中卻不同。
作者發(fā)現(xiàn),由于這個過程不依賴于 repooling,因此此方法可以產(chǎn)生高質量和高動態(tài)穩(wěn)定性的 masks。盡管本文使用了全卷積網(wǎng)絡實現(xiàn),但模板 mask 可以自己在具有平移變換情況下對實例進行定位。最后,作者還提出了 Fast NMS,這比標準 NMS 的快12ms,并且性能損失很小。
這種方法有是三個優(yōu)點:第一,速度非常快。第二,由于沒使用類似“repool”的方法,mask的質量非常高。第三,這個想法可以泛化。生成原型和mask系數(shù)的想法可以添加到現(xiàn)有的目標檢測的算法里面。
算法
算法介紹
為了提高實例分割的速度,作者提出了一種快速、單階段的實例分割模型——YOLACT。主要思想是將 Mask 分支添加到單階段目標檢測框架中。因此,研究人員將實例分割任務分解為兩個更簡單的并行任務,將其組合以形成最終的 Mask。YOLACT 的網(wǎng)絡結構圖如下圖所示。
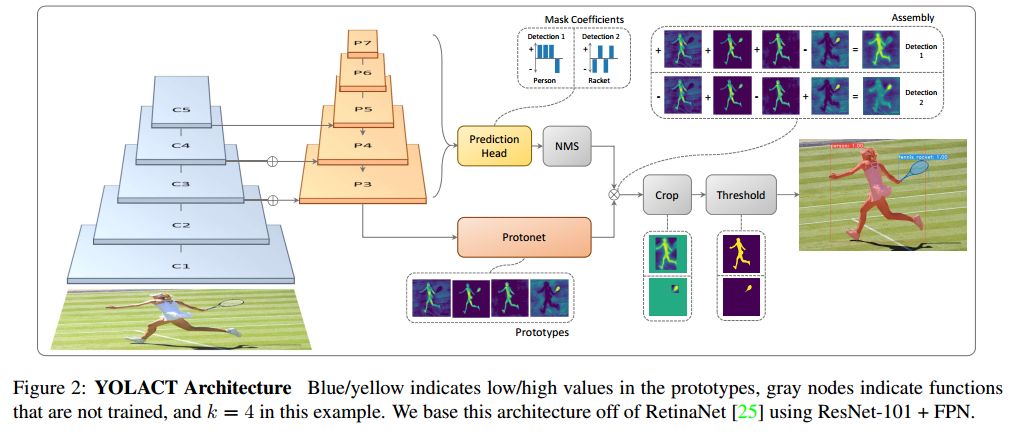
作者將實例分割的復雜任務分解為兩個更簡單的并行任務,這些任務可以組合以形成最終的 mask。 第一個分支使用 FCN 生成一組圖像大小的“原型掩碼”(prototype masks),它們不依賴于任何一個實例。第二個是給目標檢測分支添加額外的 head ,用于預測每個 anchor 的“掩碼系數(shù)”(mask coefficients)的向量,其中 anchor 是在編碼原型空間中的實例表示。最后,對經(jīng)過NMS后的每個實例,本文通過線性組合這兩個分支來為該實例構造mask。
YOLACT 將問題分解為兩個并行的部分,利用 fc 層(擅長產(chǎn)生語義向量)和 conv 層(擅長產(chǎn)生空間相干掩模)來分別產(chǎn)生“掩模系數(shù)”和“原型掩模” 。因為原型和掩模系數(shù)可以獨立地計算,所以 backbone 檢測器的計算開銷主要來自合成(assembly)步驟,其可以實現(xiàn)為單個矩陣乘法。通過這種方式,論文中的方法可以在特征空間中保持空間一致性,同時仍然是 One-Stage 和快速的。
原型生成
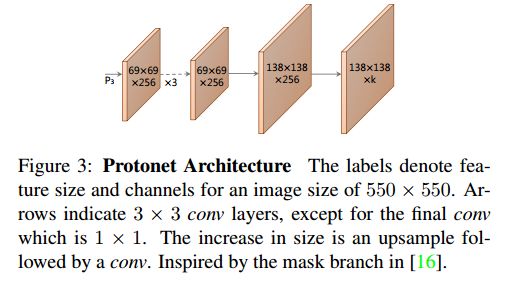
原型生成分支是預測整個圖像的一組K個原型 mask。采用 FCN 來實現(xiàn)protonet ,其最后一層有 k 個 channels(每個原型一個)并將其附加到 backbone 特征層。
掩碼系數(shù)(mask coefficients)
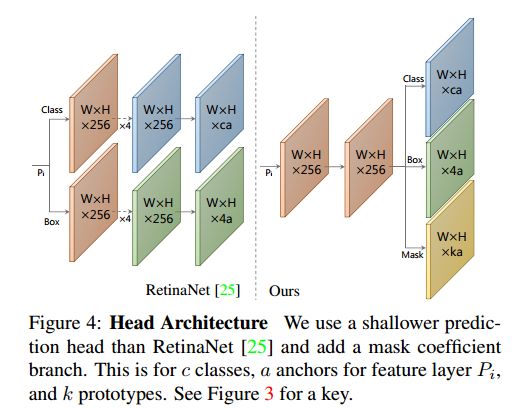
在實驗中,YOLACT 為每個Anchor預測(4+C+k)個值,額外 k 個值即為 mask系數(shù)。另外,為了能夠通過線性組合得到 mask,很重要的一步是從最終的mask 中減去原型 mask。換言之,mask 系數(shù)必須有正有負。所以,在 mask系數(shù)預測時使用了 tanh 函數(shù)進行非線性激活,因為 tanh 函數(shù)的值域是(-1,1)。
合成Mask
為了生成實例掩模,通過基本的矩陣乘法配合 sigmoid 函數(shù)來處理兩分支的輸出,從而合成 mask。
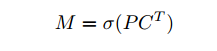
其中,P 是 h×w×k 的原型 mask 集合;C 是 n×k 的系數(shù)集合,代表有 n 個通過 NMS 和閾值過濾的實例,每個實例對應有 k 個 mask 系數(shù)。
Loss 設計:Loss 由分類損失、邊界框回歸損失和 mask 損失三部分組成。其中分類損失和邊界框回歸損失同 SSD,mask 損失為預測 mask 和 ground truth mask 的逐像素二進制交叉熵。
Mask 裁剪:為了改善小目標的分割效果,在推理時會首先根據(jù)檢測框進行裁剪,再閾值化。而在訓練時,會使用 ground truth 框來進行裁剪,并通過除以對應 ground truth框面積來平衡 loss 尺度。
Emergent Behavior
在實例分割任務中,通常需要添加轉移方差。在 YOLACT 中唯一添加轉移方差的地方是使用預測框裁剪 feature map 時。但這只是為了改善對小目標的分割效果,作者發(fā)現(xiàn)對大中型目標,不裁剪效果就很好了。
Backbone 檢測器
因為預測一組原型 mask 和 mask 系數(shù)是一個相對比較困難的任務,需要更豐富更高級的特征,所以在網(wǎng)絡設計上,作者希望兼顧速度和特征豐富度。因此,YOLACT 的主干檢測器設計遵循了 RetinaNet 的思想,同時更注重速度。 YOLACT 使用 ResNet-101 結合 FPN 作為默認主干網(wǎng)絡,默認輸入圖像尺寸為550×550,如上圖所示。使用平滑-L1 loss 訓練 bounding box 參數(shù),并且采用和 SSD 相同的 bounding box 參數(shù)編碼方式。 使用 softmax 交叉熵訓練分類部分,共(C+1)個類別。同時,使用 OHEM 方式選取訓練樣本,正負樣本比例設為 1:3. 值得注意的是,沒有像 RetinaNet 一樣采用 focal loss。
快速 NMS(fast NMS)
a.對每一類的得分前 n 名的框互相計算 IOU,得到 C*n*n 的矩陣X(對角矩陣),對每個類別的框進行降序排列。
b.其次,通過檢查是否有任何得分較高的框與其 IOU 大于某個閾值,從而找到要刪除的框,通過將 X 的下三角和對角區(qū)域設置為 0 實現(xiàn)。這可以在一個批量上三角中實現(xiàn),之后保留列方向上的最大值,來計算每個檢測器的最大 IOU 矩陣 K。
c.最后,利用閾值 t(K
論文實驗
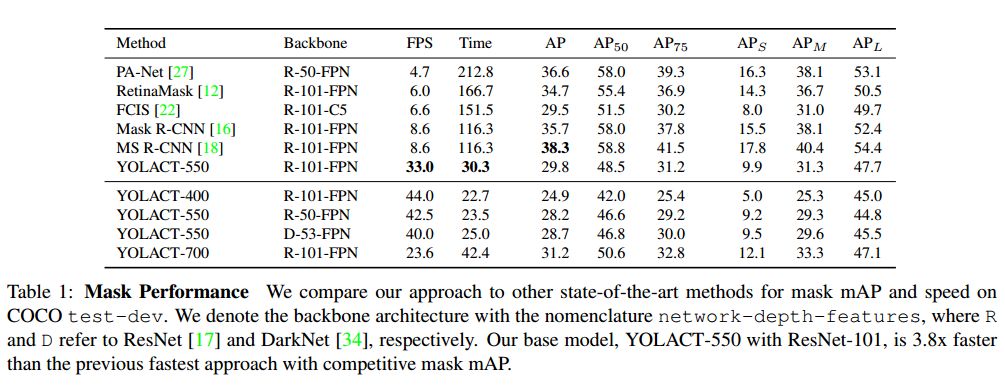
作者在 MS COCO 的 test-dev 數(shù)據(jù)集上對 YOLACT 和目前最好的方法進行了性能對比。本文的關注點在于速度的提升,且所有實驗都是在 Titan Xp 上進行的,故一些結果和原文中的結果可能略有不同。
實驗來驗證本文模型在不同大小輸入圖像情況下的性能。除了基本的 550×550 模型,還有輸入為 400×400 和 700×700 的模型,相應地也調整了 anchor 的尺寸(sx=s550/550*x s)。降低圖像大小會導致性能的大幅度下降,這說明越大的圖像進行實例分割的性能越好,但提升圖像尺寸帶來性能提升的同時會降低運行速度。
當然作者還做了關于 Mask 質量與視頻動態(tài)穩(wěn)定性相關的對比實驗,并詳細分析了優(yōu)劣緣由。詳見論文。
總結
YOLACT 網(wǎng)絡的優(yōu)勢:快速,高質量的 mask,優(yōu)良的動態(tài)穩(wěn)定性。
YOLACT 網(wǎng)絡的劣勢:性能略低于目前最好的實例分割方法,很多由檢測引起的錯誤,分類錯誤和邊界框的位移等。
此外,作者最后還提到了該方法的一些典型錯誤:
1)定位誤差:當場景中一個點上出現(xiàn)多個目標時,網(wǎng)絡可能無法在自己的模板中定位到每個對象,此時將會輸出一些和前景 mask 相似的物體,而不是在這個集合中實例分割出一些目標。
2)特征泄露(Leakage):網(wǎng)絡對預測的集成 mask 進行了裁剪,但并未對輸出的結果進行去噪。這樣一來,當b-box 準確的時候,沒有什么影響,但是當 b-box 不準確的時候,噪聲將會被帶入實例 mask,造成一些“泄露”。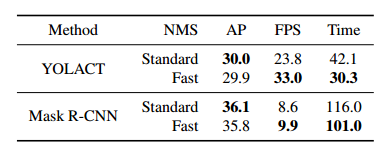
-
gpu
+關注
關注
28文章
4910瀏覽量
130660 -
算法
+關注
關注
23文章
4698瀏覽量
94742
原文標題:超Mask RCNN速度4倍,僅在單個GPU訓練的實時實例分割算法 | 技術頭條
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
改進粒子群算法的永磁同步電機PID控制器
實時生成步進電機速度曲線
RK3576 yolov11-seg訓練部署教程
無法轉換TF OD API掩碼RPGA模型怎么辦?
執(zhí)行“mask_rcnn_demo.exe”時,無法找到帶有名稱的Blob:DetectionOutput是怎么回事?
網(wǎng)絡筆記分享-實時生成步進電機速度曲線
華為云 Flexus X 實例部署安裝 Jupyter Notebook,學習 AI,機器學習算法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論