") 速度提升270倍!微軟和浙大聯(lián)合推出全新語音合成系統(tǒng)FastSpeech
速度提升270倍!微軟和浙大聯(lián)合推出全新語音合成系統(tǒng)FastSpeech

目前,基于神經(jīng)網(wǎng)絡(luò)的端到端文本到語音合成技術(shù)發(fā)展迅速,但仍面臨不少問題——合成速度慢、穩(wěn)定性差、可控性缺乏等。為此,微軟亞洲研究院機(jī)器學(xué)習(xí)組和微軟(亞洲)互聯(lián)網(wǎng)工程院語音團(tuán)隊聯(lián)合浙江大學(xué)提出了一種基于Transformer的新型前饋網(wǎng)絡(luò)FastSpeech,兼具快速、魯棒、可控等特點(diǎn)。與自回歸的Transformer TTS相比,F(xiàn)astSpeech將梅爾譜的生成速度提高了近270倍,將端到端語音合成速度提高了38倍,單GPU上的語音合成速度達(dá)到了實(shí)時語音速度的30倍。
近年來,基于神經(jīng)網(wǎng)絡(luò)的端到端文本到語音合成(Text-to-Speech,TTS)技術(shù)取了快速發(fā)展。與傳統(tǒng)語音合成中的拼接法(concatenative synthesis)和參數(shù)法(statistical parametric synthesis)相比,端到端語音合成技術(shù)生成的聲音通常具有更好的聲音自然度。但是,這種技術(shù)依然面臨以下幾個問題:
合成語音的速度較慢:端到端模型通常以自回歸(Autoregressive)的方式生成梅爾譜(Mel-Spectrogram),再通過聲碼器(Vocoder)合成語音,而一段語音的梅爾譜通常能到幾百上千幀,導(dǎo)致合成速度較慢;
合成的語音穩(wěn)定性較差:端到端模型通常采用編碼器-注意力-解碼器(Encoder-Attention-Decoder)機(jī)制進(jìn)行自回歸生成,由于序列生成的錯誤傳播(Error Propagation)以及注意力對齊不準(zhǔn),導(dǎo)致出現(xiàn)重復(fù)吐詞或漏詞現(xiàn)象;
缺乏可控性:自回歸的神經(jīng)網(wǎng)絡(luò)模型自動決定一條語音的生成長度,無法顯式地控制生成語音的語速或者韻律停頓等。
為了解決上述的一系列問題,微軟亞洲研究院機(jī)器學(xué)習(xí)組和微軟(亞洲)互聯(lián)網(wǎng)工程院語音團(tuán)隊聯(lián)合浙江大學(xué)提出了一種基于Transformer的新型前饋網(wǎng)絡(luò)FastSpeech,可以并行、穩(wěn)定、可控地生成高質(zhì)量的梅爾譜,再借助聲碼器并行地合成聲音。
在LJSpeech數(shù)據(jù)集上的實(shí)驗(yàn)表明,F(xiàn)astSpeech除了在語音質(zhì)量方面可以與傳統(tǒng)端到端自回歸模型(如Tacotron2和Transformer TTS)相媲美,還具有以下幾點(diǎn)優(yōu)勢:
快速:與自回歸的Transformer TTS相比,F(xiàn)astSpeech將梅爾譜的生成速度提高了近270倍,將端到端語音合成速度提高了近38倍,單GPU上的語音合成速度是實(shí)時語音速度的30倍;
魯棒:幾乎完全消除了合成語音中重復(fù)吐詞和漏詞問題;
可控:可以平滑地調(diào)整語音速度和控制停頓以部分提升韻律。
模型框架
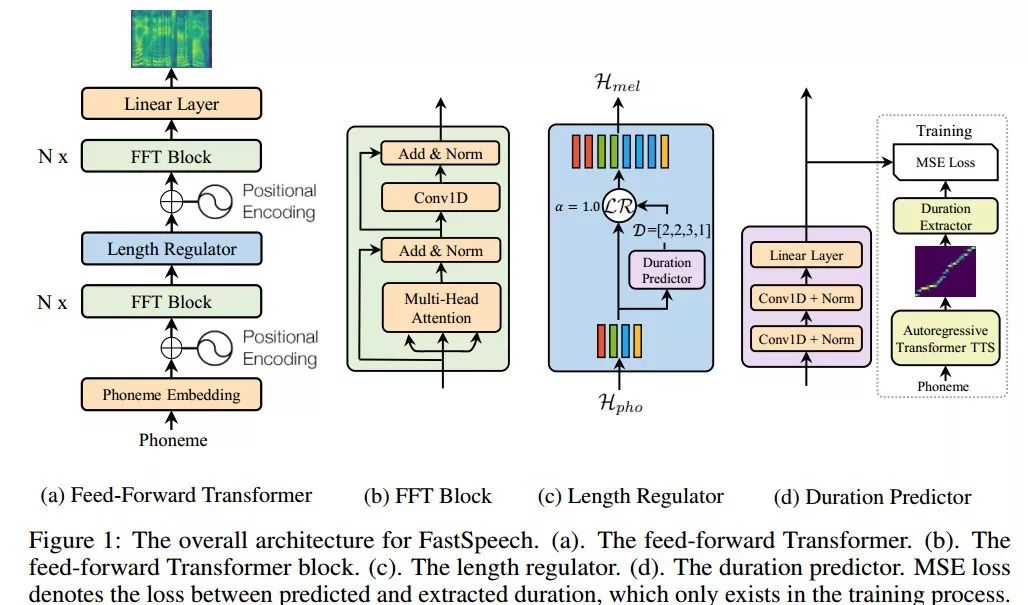
圖1. FastSpeech網(wǎng)絡(luò)架構(gòu)
前饋Transformer架構(gòu)
FastSpeech采用一種新型的前饋Transformer網(wǎng)絡(luò)架構(gòu),拋棄掉傳統(tǒng)的編碼器-注意力-解碼器機(jī)制,如圖1(a)所示。其主要模塊采用Transformer的自注意力機(jī)制(Self-Attention)以及一維卷積網(wǎng)絡(luò)(1D Convolution),我們將其稱之為FFT塊(Feed-Forward Transformer Block, FFT Block),如圖1(b)所示。前饋Transformer堆疊多個FFT塊,用于音素(Phoneme)到梅爾譜變換,音素側(cè)和梅爾譜側(cè)各有N個FFT塊。特別注意的是,中間有一個長度調(diào)節(jié)器(Length Regulator),用來調(diào)節(jié)音素序列和梅爾譜序列之間的長度差異。
長度調(diào)節(jié)器
長度調(diào)節(jié)器如圖1(c)所示。由于音素序列的長度通常小于其梅爾譜序列的長度,即每個音素對應(yīng)于幾個梅爾譜序列,我們將每個音素對齊的梅爾譜序列的長度稱為音素持續(xù)時間。長度調(diào)節(jié)器通過每個音素的持續(xù)時間將音素序列平鋪以匹配到梅爾譜序列的長度。我們可以等比例地延長或者縮短音素的持續(xù)時間,用于聲音速度的控制。此外,我們還可以通過調(diào)整句子中空格字符的持續(xù)時間來控制單詞之間的停頓,從而調(diào)整聲音的部分韻律。
音素持續(xù)時間預(yù)測器
音素持續(xù)時間預(yù)測對長度調(diào)節(jié)器來說非常重要。如圖1(d)所示,音素持續(xù)時間預(yù)測器包括一個2層一維卷積網(wǎng)絡(luò),以及疊加一個線性層輸出標(biāo)量用以預(yù)測音素的持續(xù)時間。這個模塊堆疊在音素側(cè)的FFT塊之上,使用均方誤差(MSE)作為損失函數(shù),與FastSpeech模型協(xié)同訓(xùn)練。我們的音素持續(xù)時間的真實(shí)標(biāo)簽信息是從一個額外的基于自回歸的Transformer TTS模型中抽取encoder-decoder之間的注意力對齊信息得到的,詳細(xì)信息可查閱文末論文。
實(shí)驗(yàn)評估
為了驗(yàn)證FastSpeech模型的有效性,我們從聲音質(zhì)量、生成速度、魯棒性和可控制性幾個方面來進(jìn)行了評估。
聲音質(zhì)量
我們選用LJSpeech數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),LJSpeech包含13100個英語音頻片段和相應(yīng)的文本,音頻的總長度約為24小時。我們將數(shù)據(jù)集分成3組:300個樣本作為驗(yàn)證集,300個樣本作為測試集,剩下的12500個樣本用來訓(xùn)練。
我們對測試樣本作了MOS測試,每個樣本至少被20個英語母語評測者評測。MOS指標(biāo)用來衡量聲音接近人聲的自然度和音質(zhì)。我們將FastSpeech方法與以下方法進(jìn)行對比:1) GT, 真實(shí)音頻數(shù)據(jù);2) GT (Mel + WaveGlow), 用WaveGlow作為聲碼器將真實(shí)梅爾譜轉(zhuǎn)換得到的音頻;3) Tacotron 2 (Mel + WaveGlow);4) Transformer TTS (Mel + WaveGlow);5) Merlin (WORLD), 一種常用的參數(shù)法語音合成系統(tǒng),并且采用WORLD作為聲碼器。
從表1中可以看出,我們的音質(zhì)幾乎可以與自回歸的Transformer TTS和Tacotron 2相媲美。

FastSpeech合成的聲音Demo:
文字:“The result of the recommendation of the committee of 1862 was the Prison Act of 1865”
合成速度
我們比較FastSpeech與具有近似參數(shù)量的Transformer TTS的語音合成速度。從表2可以看出,在梅爾譜的生成速度上,F(xiàn)astSpeech比自回歸的Transformer TTS提速將近270倍;在端到端(合成語音)的生成速度上,F(xiàn)astSpeech比自回歸的Transformer TTS提速將近38倍。FastSpeech平均合成一條語音的時間為0.18s,由于我們的語音平均時長為6.2s,我們的模型在單GPU上的語音合成速度是實(shí)時語音速度的30倍(6.2/0.18)。
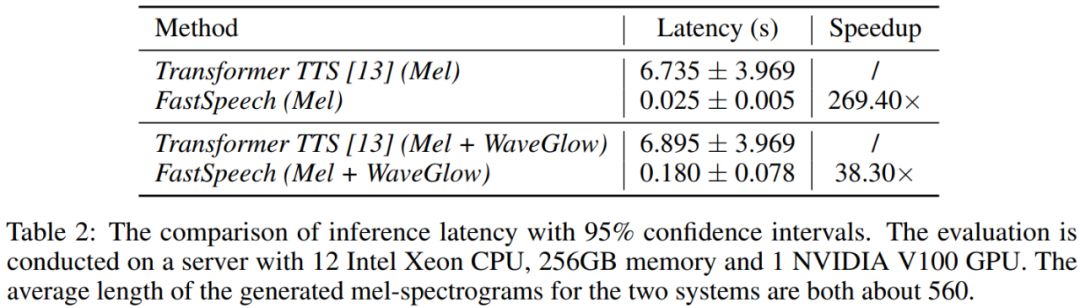
圖2展示了測試集上生成語音的耗時和生成的梅爾譜長度(梅爾譜長度與語音長度成正比)的可視化關(guān)系圖。可以看出,隨著生成語音長度的增大,F(xiàn)astSpeech的生成耗時并沒有發(fā)生較大變化,而Transformer TTS的速度對長度非常敏感。這也表明我們的方法非常有效地利用了GPU的并行性實(shí)現(xiàn)了加速。
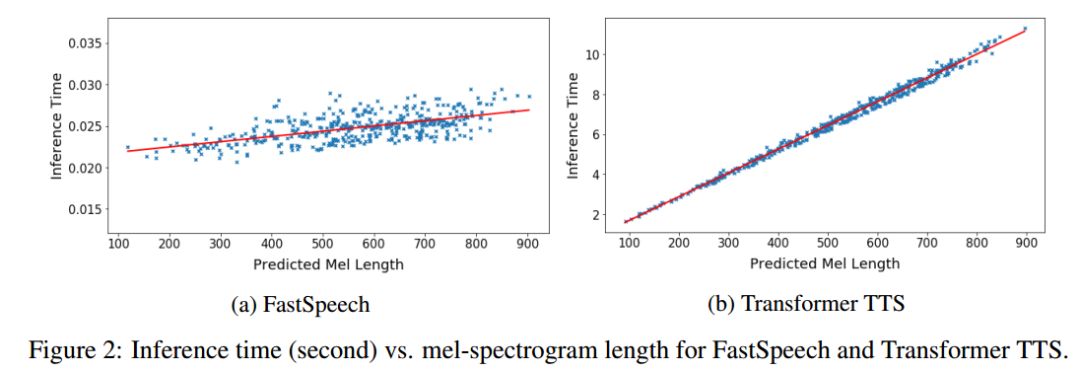
圖2. 生成語音的耗時與生成的梅爾譜長度的可視化關(guān)系圖
魯棒性
自回歸模型中的編碼器-解碼器注意力機(jī)制可能導(dǎo)致音素和梅爾譜之間的錯誤對齊,進(jìn)而導(dǎo)致生成的語音出現(xiàn)重復(fù)吐詞或漏詞。為了評估FastSpeech的魯棒性,我們選擇微軟(亞洲)互聯(lián)網(wǎng)工程院語音團(tuán)隊產(chǎn)品線上使用的50個較難的文本對FastSpeech和基準(zhǔn)模型Transformer TTS魯棒性進(jìn)行測試。從下表可以看出,Transformer TTS的句級錯誤率為34%,而FastSpeech幾乎可以完全消除重復(fù)吐詞和漏詞。

語速調(diào)節(jié)
FastSpeech可以通過長度調(diào)節(jié)器很方便地調(diào)節(jié)音頻的語速。通過實(shí)驗(yàn)發(fā)現(xiàn),從0.5x到1.5x變速,F(xiàn)astSpeech生成的語音清晰且不失真。
消融對比實(shí)驗(yàn)
我們也比較了FastSpeech中一些重要模塊和訓(xùn)練方法(包括FFT中的一維卷積、序列級別的知識蒸餾技術(shù)和參數(shù)初始化)對生成音質(zhì)效果的影響,通過CMOS的結(jié)果來衡量影響程度。由下表可以看出,這些模塊和方法確實(shí)有助于我們模型效果的提升。

未來,我們將繼續(xù)提升FastSpeech模型在生成音質(zhì)上的表現(xiàn),并且將會把該模型應(yīng)用到其它語言(例如中文)、多說話人和低資源場景中。我們還會嘗試將FastSpeech與并行神經(jīng)聲碼器結(jié)合在一起訓(xùn)練,形成一個完全端到端訓(xùn)練的語音到文本并行架構(gòu)。
-
微軟
+關(guān)注
關(guān)注
4文章
6685瀏覽量
105752 -
互聯(lián)網(wǎng)
+關(guān)注
關(guān)注
55文章
11250瀏覽量
106399 -
語音合成系統(tǒng)
+關(guān)注
關(guān)注
0文章
3瀏覽量
6408
原文標(biāo)題:速度提升270倍!微軟和浙大聯(lián)合推出全新語音合成系統(tǒng)FastSpeech
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
DeepSeek最新論文:訓(xùn)練速度提升9倍,推理速度快11倍!

Arm 與微軟合作,為基于 Arm 架構(gòu)的 PC 和移動設(shè)備應(yīng)用提供超強(qiáng) AI 體驗(yàn)

F1?與亞馬遜云科技聯(lián)合推出全新在線體驗(yàn) 車迷可親手打造專屬賽道
芯資訊|廣州唯創(chuàng)電子WT2003H語音芯片:靈活高效的語音文件更新方案

微軟推出兩款全新銷售智能體
微軟推出全新Surface Windows11 AI+ PC Surface Laptop 13 英寸和Surface Pro 12英寸
MVG推出SpeedProbe DL解決方案:有源相控陣天線校準(zhǔn)速度提升至5倍

【CW32模塊使用】語音合成播報模塊

芯資訊|WT3000T8語音合成芯片:高性價比語音交互解決方案

貿(mào)澤電子與Amphenol聯(lián)合推出全新電子書
電子鎖語音芯片方案,低功耗語音播報ic,NV256H
浙大與海康威視合作再添新成果
英偉達(dá)推出歸一化Transformer,革命性提升LLM訓(xùn)練速度
Commvault與Pure Storage聯(lián)合推出網(wǎng)絡(luò)就緒解決方案
OTA遠(yuǎn)程升級語音芯片”在線更新語音內(nèi)容的方式有哪幾種?分別如何使用及有什么優(yōu)勢?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論