") 解析DARTS:海量數(shù)據(jù)訓(xùn)練和新樣本特征的綜合
解析DARTS:海量數(shù)據(jù)訓(xùn)練和新樣本特征的綜合
摘要:研究人員首次將深度學(xué)習(xí)與貝葉斯假設(shè)檢驗結(jié)合,利用深度學(xué)習(xí)強(qiáng)化RNA可變剪接分析的準(zhǔn)確性。
在生命科研領(lǐng)域,常有人說深度學(xué)習(xí)的基因組學(xué)應(yīng)用好比是“一個盲人在一間黑暗的房子里尋找一頂并不存在的黑色帽子”。言下之意,是遺憾深度學(xué)習(xí)的基因組學(xué)應(yīng)用并沒有給人們帶來太多驚喜。不過,近日賓夕法尼亞大學(xué)和費(fèi)城兒童醫(yī)院教授邢毅團(tuán)隊的一項研究,找到了這樣一頂“黑帽子”。
這項發(fā)表在《自然—方法》上的論文成果,提出了一種新的計算框架——DARTS(“利用深度學(xué)習(xí)強(qiáng)化對RNA-seq的可變剪接分析”英文的首字母縮寫)。該計算框架首次將深度學(xué)習(xí)與貝葉斯假設(shè)檢驗結(jié)合,用于RNA可變剪接分析。這種結(jié)合使得它即使對于測序深度不那么高的樣品,也能有效提高RNA-seq定量差異剪接的準(zhǔn)確度。
清華大學(xué)生命科學(xué)學(xué)院教授張強(qiáng)鋒點(diǎn)評道:“DARTS綜合了深度學(xué)習(xí)和貝葉斯假設(shè)檢驗統(tǒng)計模型的優(yōu)點(diǎn),為那些低測序深度的數(shù)據(jù)提供了更好的做可變剪接分析的手段,拓展了傳統(tǒng)RNA-seq可變剪接分析的敏感度和準(zhǔn)確度。”
計算基因組學(xué)中
一個廣受關(guān)注的問題
邢毅等人在上述論文中指出,目前,RNA-seq技術(shù)是研究RNA剪接最常用的實驗手段。然而,RNA-seq技術(shù)雖然能較好地定量基因表達(dá)的結(jié)果,但對于差異剪接分析來說,它依賴于更高的測序深度。而且即便如此,現(xiàn)有的計算方法還不能較準(zhǔn)確地定量低表達(dá)基因的剪接變化。因此,為了提高剪接定量的準(zhǔn)確性,急需引入新的計算分析方法。
“可變剪接現(xiàn)象從20世紀(jì)70年代被發(fā)現(xiàn)后,其基本的科學(xué)問題聚焦為可變剪接位點(diǎn)發(fā)現(xiàn)、差異分析、調(diào)控元件和網(wǎng)絡(luò)的發(fā)現(xiàn)和構(gòu)建。RNA-seq 技術(shù)的發(fā)明,使得系統(tǒng)、定量的可變剪接差異分析成為可能。”張強(qiáng)鋒介紹說,大量測序數(shù)據(jù)的可變剪接差異分析需要優(yōu)秀的統(tǒng)計模型和計算工具,因此一直是一個需要高度技巧的生物信息學(xué)研究課題。
據(jù)張強(qiáng)鋒介紹,邢毅研究組在針對大量測序數(shù)據(jù)的可變剪接差異分析的計算分析領(lǐng)域深耕多年,已經(jīng)貢獻(xiàn)了多個有影響力的算法和計算工具。該團(tuán)隊針對高通量RNA-seq數(shù)據(jù)開發(fā)出的用于差異剪接分析的rMATS等軟件,對于測序較深、質(zhì)量較好的數(shù)據(jù)集都能取得不錯的結(jié)果,已在全世界范圍內(nèi)被廣泛下載使用。
然而,由于成本等原因,大量RNA-seq 測序?qū)嶒炘O(shè)計的測序深度較淺。對于這些數(shù)據(jù)集,能利用來做差異分析的可變剪接事件非常有限。
美國卡耐基梅隆大學(xué)計算機(jī)學(xué)院教授馬堅也表示,在基因組學(xué)中,確實有很多類似的問題——如何在現(xiàn)有數(shù)據(jù)上對特定的基因組標(biāo)注(譬如染色質(zhì)結(jié)構(gòu)、轉(zhuǎn)錄因子結(jié)合)訓(xùn)練一個機(jī)器學(xué)習(xí)模型并在全新的細(xì)胞系中有效預(yù)測,已經(jīng)成為一個計算基因組學(xué)中廣泛關(guān)注的問題。“DARTS嶄新的整體設(shè)計理念值得很多其他類似的問題借鑒。”
DARTS計算框架
給出問題答案
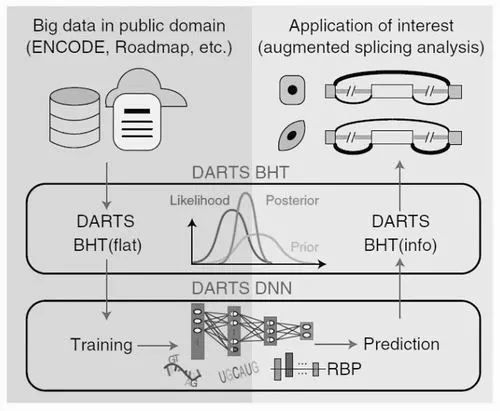
據(jù)邢毅研究組這篇發(fā)表在《自然—方法》上的論文介紹,DARTS由兩部分構(gòu)成:深度神經(jīng)網(wǎng)絡(luò)模塊(DNN)和貝葉斯推斷模塊(BHT)。其中,DNN基于順式序列特征和樣品特異的RNA結(jié)合蛋白表達(dá)水平特征來預(yù)測差異剪接的結(jié)果;而BHT則通過整合實驗樣品測序數(shù)據(jù)本身和基于深度神經(jīng)網(wǎng)絡(luò)的先驗概率來推斷差異剪接的結(jié)果。
研究者在論文中強(qiáng)調(diào)稱,與其他計算方法不同的是,在DARTS計算框架下,DNN不僅通過順式序列特征來預(yù)測可變剪接的結(jié)果,而且還將樣品中RNA結(jié)合蛋白的表達(dá)水平整合進(jìn)了RNA可變剪接結(jié)果的預(yù)測中,增加了預(yù)測參數(shù)的維度。
DARTS的邏輯是,通過DNN對ENCODE和Roadmap數(shù)據(jù)庫中大量RNA-seq結(jié)果的深度學(xué)習(xí),能夠獲得高精度的預(yù)測值作為BHT中的貝葉斯先驗概率,進(jìn)而結(jié)合具體實驗中RNA-seq的結(jié)果,來獲得更為準(zhǔn)確的差異剪接推斷。
在研究實踐中,邢毅研究組發(fā)現(xiàn),在低通量RNA-seq文庫中,通過使用DNN預(yù)測值進(jìn)行強(qiáng)化分析后,能夠達(dá)到比使用傳統(tǒng)方法分析更高的準(zhǔn)確度,并且這種提升在越低通量的文庫中越明顯;即使在高通量的RNA-seq文庫中,使用DNN預(yù)測仍能發(fā)現(xiàn)在低表達(dá)基因中的可變剪接變化。而在過去,這些低表達(dá)基因的可變剪接變化在傳統(tǒng)分析方法中往往會被忽略。
也就是說,研究結(jié)果證明了DARTS不僅提升了基于RNA-seq方法研究可變剪接的準(zhǔn)確性,同時也提供了在低表達(dá)基因中研究可變剪接的研究手段。
解析DARTS:
海量數(shù)據(jù)訓(xùn)練和新樣本特征的綜合
“從計算方法設(shè)計的策略和概念角度而言,此工作的最大亮點(diǎn)是充分利用海量公有數(shù)據(jù)如ENCODE,但模型本身又不完全依賴于這些公有數(shù)據(jù)。”馬堅點(diǎn)評道,換言之,DARTS的整體思想是用深度神經(jīng)網(wǎng)絡(luò)從現(xiàn)有海量數(shù)據(jù)中找出通用的有用信息作為先驗,然后用貝葉斯假設(shè)檢驗結(jié)合來自樣本本身的RNA-seq數(shù)據(jù)信息,做可變剪接的預(yù)測,“這有效綜合了海量數(shù)據(jù)的訓(xùn)練以及新樣本的特殊性”。
馬堅解釋說,從模型本身的技術(shù)角度而言,DARTS有效利用了深度神經(jīng)網(wǎng)絡(luò)對異質(zhì)數(shù)據(jù)特征的整合,并且整個計算方法的評測和方法都比較“明智而審慎”。他舉例說,比如DARTS的深度神經(jīng)網(wǎng)絡(luò)部分結(jié)合了剪接位置附近的序列信息、進(jìn)化信息、可變剪接產(chǎn)生的RNA二級結(jié)構(gòu)信息等;同時DARTS還巧妙地利用深度神經(jīng)網(wǎng)絡(luò)預(yù)測的結(jié)果來作為貝葉斯假設(shè)檢驗中的先驗數(shù)據(jù),結(jié)合樣本本身的RNA-seq序列信息實現(xiàn)了更可靠的可變剪接預(yù)測。
馬堅將基因組學(xué)形容為一個“存在太多未知和容易迷失的領(lǐng)域”,因此他認(rèn)為,有效深度學(xué)習(xí)的使用需要有強(qiáng)大的領(lǐng)域知識作為支撐。而DARTS工作恰恰體現(xiàn)了邢毅實驗室多年以來對可變剪接機(jī)理的研究和計算方法創(chuàng)新的積累。“由深入的領(lǐng)域知識和經(jīng)驗作為指導(dǎo),是一個有效利用不同計算模型和深度學(xué)習(xí)方法的優(yōu)勢實現(xiàn)基因組學(xué)新發(fā)現(xiàn)的經(jīng)典工作。”
張強(qiáng)鋒也直指“巧妙利用公開的RNA-seq大數(shù)據(jù)樣本、使用深度神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)得到了外顯子差異剪接的貝葉斯假設(shè)檢驗統(tǒng)計模型的準(zhǔn)確先驗概率分布”是DARTS在方法上最大的特色。同時他也表示,該計算框架使用深度神經(jīng)網(wǎng)絡(luò)通過順式序列和反式因子RBP表達(dá)豐度進(jìn)行差異剪接預(yù)測的思路也值得借鑒。
此外,馬堅認(rèn)為論文中其他對于機(jī)器學(xué)習(xí)方法的評測同樣可圈可點(diǎn)。例如,對常見的正負(fù)樣本不均衡的問題對模型訓(xùn)練和評測可能帶來的偏差有細(xì)致的控制。另外,該計算框架對模型中每個模塊的貢獻(xiàn)也做了詳細(xì)分析。
“隨著RNA-seq數(shù)據(jù)的不斷積累,相信DARTS會有廣泛的應(yīng)用,尤其是在RNA-seq測序深度并不高的實驗情況下。”馬堅說,這個計算工具對進(jìn)一步理解可變剪接在不同細(xì)胞狀態(tài)下的調(diào)控機(jī)理有深遠(yuǎn)的意義。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7246瀏覽量
91079 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5555瀏覽量
122510
原文標(biāo)題:科學(xué)家找到深度學(xué)習(xí)基因組學(xué)應(yīng)用的一頂“黑帽子”
文章出處:【微信號:AItists,微信公眾號:人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
嵌入式AI技術(shù)漫談:怎么為訓(xùn)練AI模型采集樣本數(shù)據(jù)
海思SD3403邊緣計算AI數(shù)據(jù)訓(xùn)練概述
Deepseek海思SD3403邊緣計算AI產(chǎn)品系統(tǒng)
用PaddleNLP為GPT-2模型制作FineWeb二進(jìn)制預(yù)訓(xùn)練數(shù)據(jù)集

中國聯(lián)通實現(xiàn)30TB樣本數(shù)據(jù)跨城存算分離訓(xùn)練
Kaggle知識點(diǎn):使用大模型進(jìn)行特征篩選

海量數(shù)據(jù)處理需要多少RAM內(nèi)存
什么是協(xié)議分析儀和訓(xùn)練器
Llama 3 模型訓(xùn)練技巧
【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)知識學(xué)習(xí)
BP神經(jīng)網(wǎng)絡(luò)最少要多少份樣本
pytorch如何訓(xùn)練自己的數(shù)據(jù)
神經(jīng)網(wǎng)絡(luò)如何用無監(jiān)督算法訓(xùn)練
機(jī)器學(xué)習(xí)中的數(shù)據(jù)預(yù)處理與特征工程
特征工程與數(shù)據(jù)預(yù)處理全解析:基礎(chǔ)技術(shù)和代碼示例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論