 機器學習中的數據預處理與特征工程
機器學習中的數據預處理與特征工程
在機器學習的整個流程中,數據預處理與特征工程是兩個至關重要的步驟。它們直接決定了模型的輸入質量,進而影響模型的訓練效果和泛化能力。本文將從數據預處理和特征工程的基本概念出發,詳細探討這兩個步驟的具體內容、方法及其在機器學習中的應用。
一、數據預處理
數據預處理是機器學習過程中的第一步,也是至關重要的一步。它的主要目的是提高數據的質量,確保數據的一致性和準確性,從而為后續的模型訓練提供可靠的基礎。數據預處理通常包括以下幾個方面:
1. 數據清洗
數據清洗是數據預處理的核心環節,主要目的是消除數據中的噪聲、缺失值和異常值。具體方法包括:
- 缺失值處理 :對于數據中的缺失值,可以采用刪除法或插補法進行處理。刪除法包括刪除觀測樣本、刪除變量、使用完整原始數據分析以及改變權重等方法。插補法則是在條件允許的情況下,找到缺失值的替代值進行插補,常用的插補方法包括均值插補、回歸插補、熱平臺插補和冷平臺插補等。
- 異常值處理 :異常值(或稱離群點)是指與數據集中其他觀測值有顯著不同的數據點。這些點可能是由于測量誤差、數據輸入錯誤或真實的異常情況造成的。處理異常值的方法包括刪除這些點、使用魯棒的統計數據代替受影響的統計量,或在模型訓練中使用能夠抵抗異常點的算法。
- 噪聲處理 :噪聲是數據中的隨機錯誤和偏差,可以通過分箱、聚類、回歸等方法進行“光滑”處理,以去除數據中的噪聲。
2. 數據集成
數據集成是將多個數據源中的數據合并到一個一致的數據存儲中的過程。這些數據源可能包括多個數據庫、數據立方體或一般文件。在數據集成過程中,需要解決的主要問題包括如何對多個數據集進行匹配以及如何處理數據冗余。
3. 數據變換
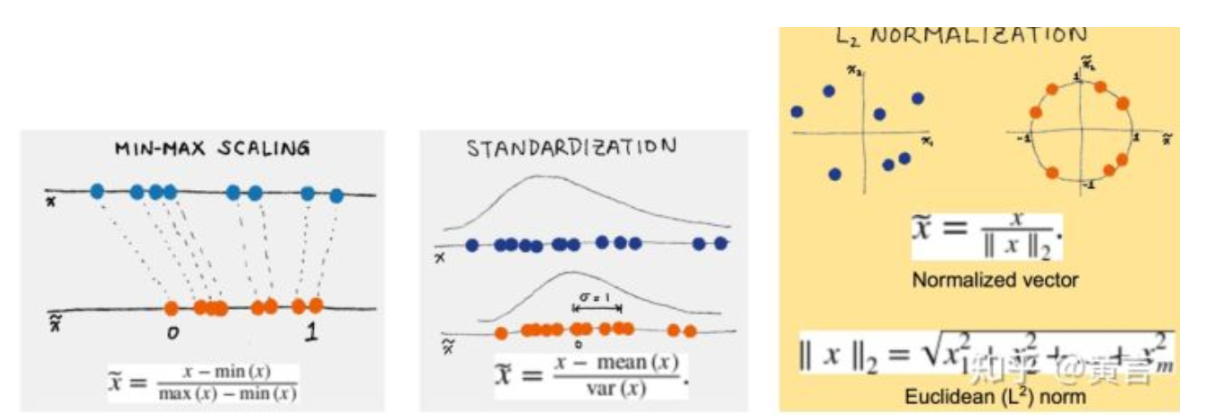
數據變換是找到數據的特征表示,用維度變換來減少有效變量的數目或找到數據的不變式。常用的數據變換方法包括規格化、規約、切換和投影等操作。其中,規格化(如標準化和歸一化)是常用的特征縮放方法,旨在將不同范圍的特征值歸一化到相同的尺度,以消除數據不同特征的尺度差異。
二、特征工程
特征工程是機器學習中至關重要的步驟,它是指將原始數據轉換為機器可理解的特征表示形式的過程。特征工程的目標是提取和選擇對于機器學習算法來說最有信息量和預測能力的特征,從而改善模型的性能。
1. 特征構建
特征構建是通過對原始特征進行組合、轉換和提取來創建新的特征的過程。特征構建可以幫助機器學習算法更好地捕捉數據中的模式和關系。常用的特征構建方法包括多項式特征、交互特征和集合特征等。多項式特征通過對原始特征進行多項式擴展來創建新的特征;交互特征通過對多個特征進行相乘或相除來創建新的特征;集合特征則通過統計數據集中某個特征的計數或頻率來創建新的特征。
2. 特征編碼
特征編碼是將非數值特征轉換為機器學習算法能夠處理的數值特征的過程。常用的特征編碼方法包括獨熱編碼和標簽編碼。獨熱編碼將一個具有n個不同取值的特征轉換為一個n維的二進制向量,其中只有一個元素為1,其余元素都為0。標簽編碼則將不同取值的特征分配一個整數標簽。
3. 特征選擇
特征選擇是從原始特征中選擇最重要的特征子集的過程。特征選擇有助于減少特征維度,提高模型的泛化能力和訓練速度。常用的特征選擇方法包括過濾法、包裝法和嵌入法。過濾法通過計算特征與目標變量之間的相關性來選擇特征;包裝法通過訓練并評估模型的性能來選擇特征;嵌入法則將特征選擇嵌入到模型訓練的過程中。
4. 特征降維
特征降維是減少特征維度的過程,它可以簡化模型的復雜度并提高模型的訓練效率和泛化能力。常用的特征降維方法包括主成分分析(PCA)和線性判別分析(LDA)。PCA通過線性變換將原始特征投影到一個低維度的子空間中;LDA則通過最大化類間距離和最小化類內距離來選擇重要的特征。
三、數據預處理與特征工程在機器學習中的應用
在機器學習的實際應用中,數據預處理與特征工程往往是緊密結合在一起的。有效的數據預處理可以提高數據的質量,為后續的特征工程提供可靠的基礎;而精心的特征工程則可以進一步提取和選擇最有信息量和預測能力的特征,從而顯著提升模型的性能。
具體來說,數據預處理與特征工程在機器學習中的應用可以概括為以下幾個步驟:
- 數據收集與整理 :首先收集相關的原始數據,并進行初步的整理和清洗,以消除數據中的噪聲、缺失值和異常值。
- 特征構建與編碼 :根據問題的需求和數據的特點,構建新的特征并進行編碼處理,以便機器學習算法能夠理解和處理這些數據。3. 特征選擇與降維 :在構建了豐富的特征集之后,接下來進行特征選擇和降維。這一步驟旨在剔除冗余或無關的特征,減少模型的復雜度,提高訓練效率和泛化能力。通過特征選擇,我們可以識別出哪些特征對模型的預測性能貢獻最大,從而保留這些重要特征,去除或忽略其他不重要的特征。同時,特征降維技術如PCA、LDA等可以幫助我們進一步減少特征的數量,同時盡量保留原始數據中的信息。
- 模型訓練與評估 :在完成了數據預處理和特征工程之后,我們就可以使用處理好的數據來訓練機器學習模型了。訓練過程中,我們會不斷調整模型的參數,以最小化損失函數,提高模型的預測準確性。同時,為了評估模型的性能,我們需要使用一部分未參與訓練的數據(如驗證集或測試集)來測試模型的泛化能力。
- 模型優化與迭代 :根據模型在測試集上的表現,我們可能會發現模型在某些方面存在不足,如過擬合、欠擬合或泛化能力差等。這時,我們需要回到數據預處理和特征工程的步驟,重新審視我們的數據處理和特征選擇策略,進行必要的調整和優化。這個過程可能需要多次迭代,直到我們找到最佳的模型配置為止。
四、數據預處理與特征工程的挑戰與解決策略
盡管數據預處理與特征工程在機器學習中扮演著至關重要的角色,但它們也面臨著一些挑戰。以下是一些常見的挑戰及其解決策略:
- 數據質量差 :原始數據中可能存在大量的噪聲、缺失值和異常值,這會嚴重影響模型的性能。解決策略包括使用數據清洗技術來消除這些不良數據,以及采用魯棒的機器學習算法來抵抗噪聲和異常值的影響。
- 特征維度高 :在許多實際應用中,數據的特征維度可能非常高,這會導致計算復雜度高、模型訓練時間長等問題。解決策略包括使用特征選擇和降維技術來減少特征的數量,同時盡量保留原始數據中的有用信息。
- 特征冗余 :特征之間可能存在冗余或相關性,這會導致模型過擬合或降低預測準確性。解決策略包括使用相關性分析或聚類分析等方法來識別冗余特征,并在特征選擇過程中予以剔除。
- 領域知識不足 :在某些領域,如醫學、金融等,數據可能具有高度的專業性和復雜性,而機器學習工程師可能缺乏相應的領域知識。這會導致在特征構建和選擇過程中難以把握關鍵特征。解決策略包括與領域專家合作,共同進行特征工程的設計和實施。
五、結論
數據預處理與特征工程是機器學習中不可或缺的兩個步驟。它們對于提高模型性能、防止過擬合和增強模型泛化能力具有至關重要的作用。通過精心設計和實施數據預處理與特征工程策略,我們可以從原始數據中提取出最有價值的信息,為機器學習模型的訓練提供可靠的基礎。然而,我們也應該認識到這兩個步驟所面臨的挑戰,并采取相應的解決策略來克服這些挑戰。隨著數據科學和機器學習技術的不斷發展,我們相信數據預處理與特征工程將會變得更加高效和智能化,為更多的應用場景提供有力的支持。
-
模型
+關注
關注
1文章
3483瀏覽量
49968 -
機器學習
+關注
關注
66文章
8490瀏覽量
134062 -
數據預處理
+關注
關注
1文章
20瀏覽量
2862
發布評論請先 登錄










 工商網監
工商網監
評論