") Llama 3 模型訓練技巧
Llama 3 模型訓練技巧
Llama 3 模型,假設是指一個先進的人工智能模型,可能是一個虛構的或者是一個特定領域的術語。
1. 數(shù)據(jù)預處理
數(shù)據(jù)是任何機器學習模型的基礎。在訓練之前,確保數(shù)據(jù)質量至關重要。
- 數(shù)據(jù)清洗 :去除噪聲和異常值,確保數(shù)據(jù)的一致性和準確性。
- 特征工程 :提取有助于模型學習的特征,可能包括特征選擇、特征轉換和特征編碼。
- 數(shù)據(jù)增強 :對于圖像或文本數(shù)據(jù),可以通過旋轉、縮放、裁剪等方法增加數(shù)據(jù)多樣性。
- 歸一化/標準化 :將數(shù)據(jù)縮放到相同的范圍,有助于模型更快地收斂。
2. 選擇合適的模型架構
根據(jù)任務的性質(如分類、回歸、生成等),選擇合適的模型架構。
- 卷積神經(jīng)網(wǎng)絡(CNN) :適用于圖像處理任務。
- 循環(huán)神經(jīng)網(wǎng)絡(RNN) :適用于序列數(shù)據(jù),如時間序列分析或自然語言處理。
- 變換器(Transformer) :適用于處理長距離依賴問題,如機器翻譯或文本生成。
- 混合模型 :結合多種模型架構的優(yōu)點,以適應復雜的任務。
3. 超參數(shù)調優(yōu)
超參數(shù)是影響模型性能的關鍵因素,需要仔細調整。
- 學習率 :控制模型權重更新的步長,過低可能導致訓練緩慢,過高可能導致訓練不穩(wěn)定。
- 批大小 :影響模型的內(nèi)存使用和訓練穩(wěn)定性,需要根據(jù)硬件資源和模型復雜度進行調整。
- 正則化 :如L1、L2正則化,可以防止模型過擬合。
- 優(yōu)化器 :如SGD、Adam等,影響模型的收斂速度和穩(wěn)定性。
4. 訓練策略
- 早停法(Early Stopping) :在驗證集上的性能不再提升時停止訓練,以防止過擬合。
- 學習率衰減 :隨著訓練的進行,逐漸減小學習率,有助于模型在訓練后期更細致地調整權重。
- 梯度累積 :在資源有限的情況下,通過累積多個小批量的梯度來模擬大批量訓練。
- 混合精度訓練 :使用混合精度(如FP16)來減少內(nèi)存使用和加速訓練。
5. 模型評估
- 交叉驗證 :通過將數(shù)據(jù)分成多個子集進行訓練和驗證,以評估模型的泛化能力。
- 性能指標 :選擇合適的性能指標,如準確率、召回率、F1分數(shù)等,以評估模型在特定任務上的表現(xiàn)。
- 混淆矩陣 :對于分類任務,混淆矩陣可以提供關于模型性能的詳細信息。
6. 模型微調
在預訓練模型的基礎上進行微調,可以提高模型在特定任務上的性能。
- 遷移學習 :利用在大規(guī)模數(shù)據(jù)集上預訓練的模型,將其應用于特定任務。
- 領域適應 :根據(jù)目標領域的數(shù)據(jù)調整模型參數(shù),以提高模型的適應性。
7. 模型部署和監(jiān)控
- 模型壓縮 :通過剪枝、量化等技術減小模型大小,以便于部署。
- 模型服務 :將模型部署到生產(chǎn)環(huán)境,如使用TensorFlow Serving、TorchServe等工具。
- 性能監(jiān)控 :持續(xù)監(jiān)控模型在生產(chǎn)環(huán)境中的表現(xiàn),以確保其穩(wěn)定性和準確性。
8. 倫理和可解釋性
- 偏見檢測 :確保模型不會對某些群體產(chǎn)生不公平的偏見。
- 可解釋性 :提高模型的透明度,讓用戶理解模型的決策過程。
結語
訓練一個高級的人工智能模型是一個復雜的過程,涉及到數(shù)據(jù)預處理、模型選擇、訓練策略、評估和部署等多個步驟。通過遵循上述技巧,可以提高模型的性能和可靠性。然而,每個模型和任務都有其獨特性,因此需要根據(jù)具體情況進行調整和優(yōu)化。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權轉載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
人工智能
+關注
關注
1804文章
48637瀏覽量
246111 -
模型
+關注
關注
1文章
3480瀏覽量
49946
發(fā)布評論請先 登錄
相關推薦
熱點推薦
【飛騰派4G版免費試用】仙女姐姐的嵌入式實驗室之五~LLaMA.cpp及3B“小模型”O(jiān)penBuddy-StableLM-3B
預訓練語言模型。該模型最大的特點就是基于以較小的參數(shù)規(guī)模取得了優(yōu)秀的性能,根據(jù)官網(wǎng)提供的信息,LLaMA的模型包含4個版本,最小的只有70億
發(fā)表于 12-22 10:18
基于LLAMA的魔改部署
訓練),并且和Vision結合的大模型也逐漸多了起來。所以怎么部署大模型是一個 超級重要的工程問題 ,很多公司也在緊鑼密鼓的搞著。 目前效果最好討論最多的開源實現(xiàn)就是LLAMA,所以我
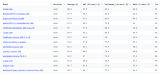
State of GPT:大神Andrej揭秘OpenAI大模型原理和訓練過程
你可以看到,Llama 的參數(shù)數(shù)量大概是 650 億。現(xiàn)在,盡管與 GPT3 的 1750 億個參數(shù)相比,Llama 只有 65 個 B 參數(shù),但 Llama 是一個明顯更強大的

8G顯存一鍵訓練,解鎖Llama2隱藏能力!XTuner帶你玩轉大模型
針對 GPU 計算特點,在顯存允許的情況下,XTuner 支持將多條短數(shù)據(jù)拼接至模型最大輸入長度,以此最大化 GPU 計算核心的利用率,可以顯著提升訓練速度。例如,在使用 oasst1 數(shù)據(jù)集微調 Llama2-7B 時,數(shù)據(jù)拼

Meta推出最強開源模型Llama 3 要挑戰(zhàn)GPT
Meta推出最強開源模型Llama 3 要挑戰(zhàn)GPT Facebook母公司Meta Platforms(META.US)推出了開源AI大模型“Ll
百度智能云國內(nèi)首家支持Llama3全系列訓練推理!
4月18日,Meta 正式發(fā)布 Llama 3,包括8B 和 70B 參數(shù)的大模型,官方號稱有史以來最強大的開源大模型。
Llama 3 王者歸來,Airbox 率先支持部署
前天,智算領域迎來一則令人振奮的消息:Meta正式發(fā)布了備受期待的開源大模型——Llama3。Llama3的卓越性能Meta表示,Llama3在多個關鍵基準測試中展現(xiàn)出卓越性能,超越了

Meta Llama 3基礎模型現(xiàn)已在亞馬遜云科技正式可用
亞馬遜云科技近日宣布,Meta公司最新發(fā)布的兩款Llama 3基礎模型——Llama 3 8B和Llam
Optimum Intel三步完成Llama3在算力魔方的本地量化和部署
Llama3 是Meta最新發(fā)布的開源大語言模型(LLM), 當前已開源8B和70B參數(shù)量的預訓練模型權重,并支持指令微調。
Llama 3 語言模型應用
在人工智能領域,語言模型的發(fā)展一直是研究的熱點。隨著技術的不斷進步,我們見證了從簡單的關鍵詞匹配到復雜的上下文理解的轉變。 一、Llama 3 語言模型的核心功能 上下文理解 :
Llama 3 與 GPT-4 比較
隨著人工智能技術的飛速發(fā)展,我們見證了一代又一代的AI模型不斷突破界限,為各行各業(yè)帶來革命性的變化。在這場技術競賽中,Llama 3和GPT-4作為兩個備受矚目的模型,它們代表了當前A
Llama 3 模型與其他AI工具對比
Llama 3模型與其他AI工具的對比可以從多個維度進行,包括但不限于技術架構、性能表現(xiàn)、應用場景、定制化能力、開源與成本等方面。以下是對Llama
Llama 3 與開源AI模型的關系
在人工智能(AI)的快速發(fā)展中,開源AI模型扮演著越來越重要的角色。它們不僅推動了技術的創(chuàng)新,還促進了全球開發(fā)者社區(qū)的合作。Llama 3,作為一個新興的AI項目,與開源AI模型的關系
Meta發(fā)布Llama 3.2量化版模型
近日,Meta在開源Llama 3.2的1B與3B模型后,再次為人工智能領域帶來了新進展。10月24日,Meta正式推出了這兩個模型的量化版本,旨在進一步優(yōu)化
用Ollama輕松搞定Llama 3.2 Vision模型本地部署
Ollama的安裝。 一,Llama3.2 Vision簡介 Llama 3.2 Vision是一個多模態(tài)大型語言模型(LLMs)的集合,它包括預訓練和指令調整的圖像推理生成






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論