") 谷歌大腦打造“以一當(dāng)十”的GAN:僅用10%標(biāo)記數(shù)據(jù),生成圖像卻更逼真
谷歌大腦打造“以一當(dāng)十”的GAN:僅用10%標(biāo)記數(shù)據(jù),生成圖像卻更逼真
近日,谷歌大腦研究人員提出了一種基于自監(jiān)督和半監(jiān)督學(xué)習(xí)的“條件GAN”,使用的標(biāo)記數(shù)據(jù)量大降90%,生成圖像的質(zhì)量比現(xiàn)有全監(jiān)督最優(yōu)模型BigGAN高出20%(以FID得分計),有望緩解圖像生成和識別領(lǐng)域標(biāo)記數(shù)據(jù)量嚴(yán)重不足的問題。
生成對抗網(wǎng)絡(luò)(GAN)是一類強(qiáng)大的深度生成模型。GAN背后的主要思想是訓(xùn)練兩個神經(jīng)網(wǎng)絡(luò):生成器負(fù)責(zé)學(xué)習(xí)如何合成數(shù)據(jù),而判別器負(fù)責(zé)學(xué)習(xí)如何區(qū)分真實數(shù)據(jù)與生成器合成的虛假數(shù)據(jù)。目前,GAN已成功用于高保真自然圖像合成,改善學(xué)習(xí)圖像壓縮質(zhì)量,以及數(shù)據(jù)增強(qiáng)等任務(wù)。
對于自然圖像合成任務(wù)來說,現(xiàn)有的最優(yōu)結(jié)果是通過條件GAN實現(xiàn)的。與無條件GAN不同,條件GAN在訓(xùn)練期間要使用標(biāo)簽(比如汽車,狗等)。雖然數(shù)據(jù)標(biāo)記讓圖像合成任務(wù)變得更容易實現(xiàn),在性能上獲得了顯著提升,但是這種方法需要大量標(biāo)記數(shù)據(jù),而在實際任務(wù)中很少有大量標(biāo)記數(shù)據(jù)可用。
隨著ImageNet上訓(xùn)練過程的持續(xù),生成的圖像逼真度進(jìn)步明顯
谷歌大腦的研究人員在最近的《用更少的數(shù)據(jù)標(biāo)簽生成高保真圖像》中,提出了一種新方法來減少訓(xùn)練最先進(jìn)條件GAN所需的標(biāo)記數(shù)據(jù)量。文章提出結(jié)合大規(guī)模GAN的最新進(jìn)展,將高保真自然圖像合成技術(shù)與最先進(jìn)技術(shù)相結(jié)合,使數(shù)據(jù)標(biāo)記數(shù)量減少到原來的10%。
在此基礎(chǔ)上,研究人員還發(fā)布了Compare GAN庫的重大更新,其中包含了訓(xùn)練和評估現(xiàn)代GAN所需的所有組件。
利用半監(jiān)督和自監(jiān)督方式提升預(yù)測性能
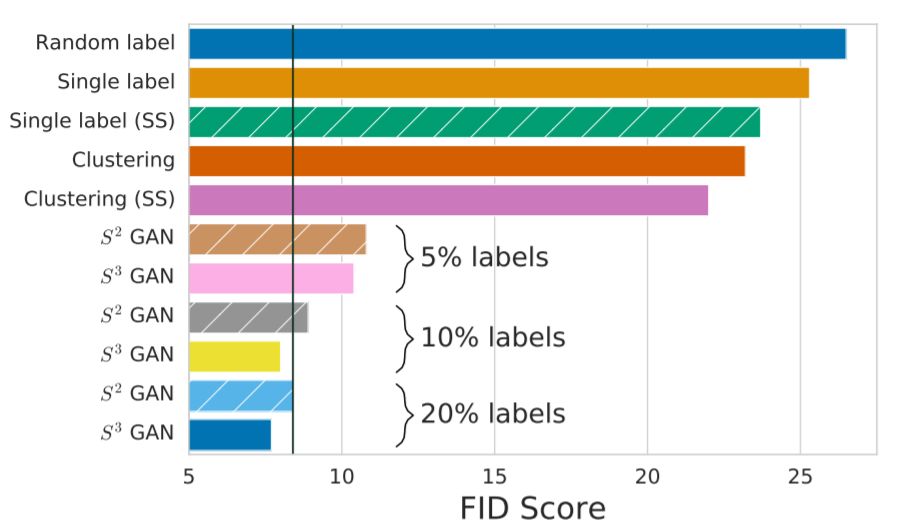
條件GAN與基線BigGAN的FID分?jǐn)?shù)對比,圖中黑色豎線為BigGAN基線模型(使用全部標(biāo)記數(shù)據(jù))得分。S3GAN在僅使用10%標(biāo)記數(shù)據(jù)的情況下,得分比基線模型最優(yōu)得分高20%
在條件GAN中,生成器和判別器通常都以分類標(biāo)簽為應(yīng)用條件。現(xiàn)在,研究人員建議使用推斷得出的數(shù)據(jù)標(biāo)簽,來替換手工標(biāo)記的真實標(biāo)簽。
上行:BigGAN全監(jiān)督式學(xué)習(xí)生成的128×128像素最優(yōu)圖像樣本。下行為S3GAN生成的圖像樣本,標(biāo)記數(shù)據(jù)量降低了90%,F(xiàn)ID得分與BigGAN表現(xiàn)相當(dāng)
為了推斷大型數(shù)據(jù)集中多數(shù)未標(biāo)記數(shù)據(jù)的高質(zhì)量標(biāo)簽,可以采取兩步方法:首先,僅使用數(shù)據(jù)集的未標(biāo)記部分來學(xué)習(xí)特征表示。
為了學(xué)習(xí)特征表示,需要利用新方法,以不同的方法利用自我監(jiān)督機(jī)制:將未標(biāo)記的圖像進(jìn)行隨機(jī)旋轉(zhuǎn),由深度卷積神經(jīng)網(wǎng)絡(luò)負(fù)責(zé)預(yù)測旋轉(zhuǎn)角度。這背后的思路是,模型需要能夠識別主要對象及其形狀,才能在此類任務(wù)中獲得成功。
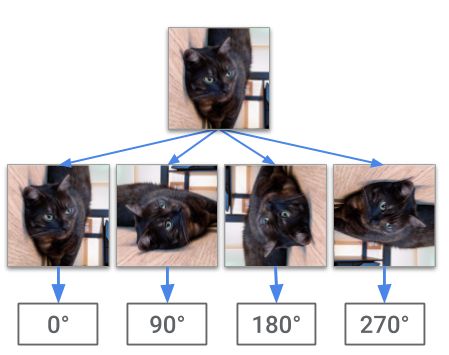
對一幅未標(biāo)記的圖像進(jìn)行隨機(jī)旋轉(zhuǎn),網(wǎng)絡(luò)的任務(wù)是預(yù)測旋轉(zhuǎn)角度。成功的模型需要捕捉有意義的語義圖像特征,這些特征可用于完成其他視覺任務(wù)
研究人員將訓(xùn)練網(wǎng)絡(luò)的一個中間層的激活模式視為輸入的新特征表示,并訓(xùn)練分類器,以使用原始數(shù)據(jù)集的標(biāo)記部分識別該輸入的標(biāo)簽。由于網(wǎng)絡(luò)經(jīng)過預(yù)訓(xùn)練,可以從數(shù)據(jù)中提取具有語義意義的特征,因此,訓(xùn)練此分類器比從頭開始訓(xùn)練整個網(wǎng)絡(luò)更具樣本效率。最后使用分類器對未標(biāo)記的數(shù)據(jù)進(jìn)行標(biāo)記。
為了進(jìn)一步提高模型質(zhì)量和訓(xùn)練的穩(wěn)定性,最好讓判別器網(wǎng)絡(luò)學(xué)習(xí)有意義的特征表示。通過這些改進(jìn)手段,在加上大規(guī)模的訓(xùn)練,使得新的條件GAN在ImageNet圖像合成任務(wù)上達(dá)到了最優(yōu)性能。
給定潛在向量,由生成器網(wǎng)絡(luò)生成圖像。在每行中,最左側(cè)和最右側(cè)圖像的潛在代碼之間的線性插值導(dǎo)致圖像空間中的語義插值
CompareGAN:用于訓(xùn)練和評估GAN的庫
對GAN的前沿研究在很大程度上依賴于經(jīng)過精心設(shè)計和測試的代碼庫,即使只是復(fù)制或再現(xiàn)先前的結(jié)果和技術(shù),也需要付出巨大努力。
為了促進(jìn)開放科學(xué)并讓研究界從最近的進(jìn)步中獲益,研究人員發(fā)布了Compare GAN庫的重大更新。該庫包括現(xiàn)代GAN中常用的損失函數(shù),正則化和歸一化方案,神經(jīng)架構(gòu)和量化指標(biāo),現(xiàn)已支持:
GPU和TPU訓(xùn)練
通過Gin進(jìn)行輕量級配置(含實例)
通過TensorFlow數(shù)據(jù)集庫提供大量數(shù)據(jù)集
未來方向:自監(jiān)督學(xué)習(xí)會讓GAN更強(qiáng)大
由于標(biāo)記數(shù)據(jù)源和未標(biāo)記數(shù)據(jù)源之間的差距越來越大,讓模型具備從部分標(biāo)記的數(shù)據(jù)中學(xué)習(xí)的能力變得越來越重要。
目前來看,自監(jiān)督學(xué)習(xí)和半監(jiān)督學(xué)習(xí)的簡單而有力的結(jié)合,有助于縮小GAN的這一現(xiàn)實差距。自監(jiān)督是一個值得研究的領(lǐng)域,值得在該領(lǐng)域開展面向其他生成建模任務(wù)的研究。
-
谷歌
+關(guān)注
關(guān)注
27文章
6223瀏覽量
107535 -
GaN
+關(guān)注
關(guān)注
19文章
2177瀏覽量
76174
原文標(biāo)題:谷歌大腦打造“以一當(dāng)十”的GAN:僅用10%標(biāo)記數(shù)據(jù),生成圖像卻更逼真
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
利用NVIDIA 3D引導(dǎo)生成式AI Blueprint控制圖像生成
Gemini API集成Google圖像生成模型Imagen 3
技術(shù)分享 | 高逼真合成數(shù)據(jù)助力智駕“看得更準(zhǔn)、學(xué)得更快”

如何使用離線工具od SPSDK生成完整圖像?
?Diffusion生成式動作引擎技術(shù)解析
使用DLPC350投射格雷碼時,當(dāng)切換pattern頻率>10frame/s,出現(xiàn)了圖像重疊的問題怎么解決?
管廊、排澇、路燈接入數(shù)據(jù)中臺助力打造“智慧城市大腦”

借助谷歌Gemini和Imagen模型生成高質(zhì)量圖像

谷歌:超四分之一新代碼由人工智能生成
生成式AI工具作用
霍尼韋爾攜手谷歌云,在工業(yè)領(lǐng)域引入生成式AI Gemini
高通與谷歌達(dá)成多年技術(shù)合作,共推汽車行業(yè)數(shù)字化轉(zhuǎn)型
沃達(dá)豐與谷歌深化十年戰(zhàn)略合作
Freepik攜手Magnific AI推出AI圖像生成器
深入理解渲染引擎:打造逼真圖像的關(guān)鍵






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論