") 中文分詞在2007-2017十年間的技術(shù)進(jìn)展
中文分詞在2007-2017十年間的技術(shù)進(jìn)展

本文回顧了中文分詞在2007-2017十年間的技術(shù)進(jìn)展,尤其是自深度學(xué)習(xí)滲透到自然語(yǔ)言處理以來(lái)的主要工作。我們的基本結(jié)論是,中文分詞的監(jiān)督機(jī)器學(xué)習(xí)方法在從非神經(jīng)網(wǎng)絡(luò)方法到神經(jīng)網(wǎng)絡(luò)方法的遷移中尚未展示出明顯的技術(shù)優(yōu)勢(shì)。中文分詞的機(jī)器學(xué)習(xí)模型的構(gòu)建,依然需要平衡考慮已知詞和未登錄詞的識(shí)別問(wèn)題。
盡管迄今為止深度學(xué)習(xí)應(yīng)用于中文分詞尚未能全面超越傳統(tǒng)的機(jī)器學(xué)習(xí)方法,我們審慎推測(cè),由于人工智能聯(lián)結(jié)主義基礎(chǔ)下的神經(jīng)網(wǎng)絡(luò)模型有潛力契合自然語(yǔ)言的內(nèi)在結(jié)構(gòu)分解方式,從而有效建模,或能在不遠(yuǎn)將來(lái)展示新的技術(shù)進(jìn)步成果。
1
背景
中文分詞是中文信息處理的一個(gè)基礎(chǔ)任務(wù)和研究方向。十年前,黃和趙(2007)接受《中文信息學(xué)報(bào)》委托,針對(duì)自20世紀(jì)末以來(lái)的中文分詞的機(jī)器學(xué)習(xí)方法做了十年回顧,發(fā)表了《中文分詞十年回顧》一文。 該文的基本結(jié)論是中文分詞的統(tǒng)計(jì)機(jī)器學(xué)習(xí)方法優(yōu)于傳統(tǒng)的規(guī)則方法,尤其在未登錄詞(out-of-vocabulary words, OOV)即訓(xùn)練集之中未出現(xiàn)的詞的識(shí)別上,具有無(wú)可比擬的優(yōu)勢(shì)。這一基本結(jié)論隨后得到全面證實(shí)。現(xiàn)在10年過(guò)去,截至2017年3月, Google Scholar顯示該文被引用166次,而中國(guó)知網(wǎng)記錄其引用為483次。
今天看來(lái),使用機(jī)器學(xué)習(xí)方法在具有切分標(biāo)記的分詞語(yǔ)料上學(xué)習(xí)或訓(xùn)練出高效能中文分詞器是自然而然的想法,然而十年前的情形大不相同。首先,直到20世紀(jì)的最后十年,中文信息處理界才意識(shí)到分詞可以作為真實(shí)標(biāo)注語(yǔ)料上的機(jī)器學(xué)習(xí)任務(wù)進(jìn)行操作。其次,充足的語(yǔ)料準(zhǔn)備也并非一蹴而就。兩個(gè)早期的語(yǔ)料來(lái)自賓州大學(xué)中文樹庫(kù)(Chinese Penn Treebank, CTB) 和北京大學(xué)計(jì)算語(yǔ)言所標(biāo)注的人民日?qǐng)?bào)語(yǔ)料。在各類切分語(yǔ)料齊備的基礎(chǔ)上, SIGHAN才得以組織第一次國(guó)際性的中文分詞評(píng)測(cè)SIGHANBakeoff-2003。
語(yǔ)料準(zhǔn)備之外,還有兩個(gè)歷史性的因素,遲滯了中文分詞這一中文信息處理基礎(chǔ)子任務(wù)走向徹底的機(jī)器學(xué)習(xí)。其一,長(zhǎng)期以來(lái),中文分詞的經(jīng)典方法,即最大匹配算法,在合適的詞典搭配下,通常能夠取得一定程度上頗可接受的性能。以F值度量,最大匹配分詞一般情況下約能獲得80%甚至更高的成績(jī)。這類簡(jiǎn)單有效的規(guī)則方法的存在,極大降低了研發(fā)先進(jìn)機(jī)器學(xué)習(xí)技術(shù)的迫切性。其二,機(jī)器學(xué)習(xí)方法的計(jì)算代價(jià)巨大,在必要硬件條件尚未普及或者成本仍過(guò)于高昂的情況下,機(jī)器學(xué)習(xí)方法的優(yōu)勢(shì)得不到體現(xiàn)。 2005年,典型的分詞學(xué)習(xí)工具條件隨機(jī)場(chǎng)(conditional random field, CRF)在百萬(wàn)詞語(yǔ)料庫(kù)上的訓(xùn)練,需要12-18小時(shí)的單線程CPU時(shí)間,占用內(nèi)存2-3G,遠(yuǎn)超當(dāng)時(shí)個(gè)人計(jì)算機(jī)的一般硬件配置水準(zhǔn)。
因此,我們?cè)?017年的今天回顧10年前的學(xué)術(shù)狀態(tài),必須歷史性地考慮當(dāng)時(shí)當(dāng)?shù)氐木唧w情形,才能理解當(dāng)時(shí)以及后來(lái)那些理所當(dāng)然的技術(shù)進(jìn)步有其內(nèi)在而特殊的合理性和必然性。最近10年機(jī)器學(xué)習(xí)領(lǐng)域最為顯著的技術(shù)井噴,顯然是深度學(xué)習(xí)方法的崛起和全面覆蓋。因而,我們下面將技術(shù)總結(jié)分為兩大部分,即中文分詞的傳統(tǒng)機(jī)器學(xué)習(xí)模型和最近的深度學(xué)習(xí)(神經(jīng)網(wǎng)絡(luò))模型。本文對(duì)技術(shù)論文的最新引用截止至ACL-2017會(huì)議的部分已錄用論文。但由于篇幅所限,我們僅關(guān)注嚴(yán)格意義上的監(jiān)督機(jī)器學(xué)習(xí)模式下的相關(guān)工作,而對(duì)于非監(jiān)督學(xué)習(xí)、半監(jiān)督學(xué)習(xí)、領(lǐng)域遷移學(xué)習(xí)以及其它分詞方法和應(yīng)用等,則尚付闕如,有待日后或各路高賢的努力。我們冒昧以此相對(duì)狹窄的視角,回顧我們力所能及范圍內(nèi)的一些當(dāng)時(shí)及當(dāng)今相對(duì)前沿的研究工作,旨在拋磚引玉,以供借鑒。
2
傳統(tǒng)的機(jī)器學(xué)習(xí)模型
分詞作為字符串上的切分過(guò)程,是一種相對(duì)簡(jiǎn)單的結(jié)構(gòu)化機(jī)器學(xué)習(xí)任務(wù)。根據(jù)所處理的結(jié)構(gòu)分解單元,大體可以將用于分詞的傳統(tǒng)機(jī)器學(xué)習(xí)模型分為兩大類,即基于字標(biāo)注的和基于詞(相關(guān)特征)的學(xué)習(xí)。
基于字標(biāo)注學(xué)習(xí)的方法始于Xue (2003)。該工作使用一個(gè)字在詞中的四種相對(duì)位置標(biāo)簽(tag),即B、M、 E和S等字位(如表1所示),來(lái)表達(dá)該字所攜帶的切分標(biāo)注信息,從而首次將分詞任務(wù)形式化為字位的串標(biāo)注學(xué)習(xí)任務(wù)。串標(biāo)注學(xué)習(xí)是自然語(yǔ)言處理中最基礎(chǔ)的結(jié)構(gòu)化學(xué)習(xí)任務(wù),在串標(biāo)注的概率圖模型中, 兩個(gè)串的各個(gè)節(jié)點(diǎn)單元需要嚴(yán)格一一對(duì)應(yīng), 非常方便于使用各種成熟的機(jī)器學(xué)習(xí)工具來(lái)建模和實(shí)現(xiàn)。Xue (2003)的首次實(shí)現(xiàn)其實(shí)尚未充分使用串標(biāo)注結(jié)構(gòu)學(xué)習(xí),而是直接應(yīng)用了字位分類模型。 Ng & Low(2004)和Low et al. (2005)才是第一次將嚴(yán)格的串標(biāo)注學(xué)習(xí)應(yīng)用于分詞, 用的是最大熵(Maximum Entropy,ME) Markov模型。而Peng et al. (2004)和Tseng et al. (2005)則自然地將標(biāo)準(zhǔn)的串標(biāo)注學(xué)習(xí)工具條件隨機(jī)場(chǎng)引入分詞學(xué)習(xí)。隨后, CRF多個(gè)變種構(gòu)成了深度學(xué)習(xí)時(shí)代之前的標(biāo)準(zhǔn)分詞模型。

中文分詞任務(wù)是切分出特定上下文環(huán)境下正確的詞,因此,所謂基于詞的分詞學(xué)習(xí)建模需要解決一個(gè)“先有雞還是先有蛋”的問(wèn)題。基于詞的隨機(jī)過(guò)程建模引致一個(gè)CRF變種,即semi-CRF(半條件隨機(jī)場(chǎng))模型的直接應(yīng)用。基于字位標(biāo)注的分詞學(xué)習(xí)通常用到的是線性鏈條件隨機(jī)場(chǎng)(linear chain CRF),它是基于Markov過(guò)程建模,處理過(guò)程中的每步只對(duì)輸入序列的一個(gè)文本單元進(jìn)行標(biāo)注。而semi-CRF則基于semi-Markov過(guò)程建模,它在每步給序列中的連續(xù)單元標(biāo)注成相同標(biāo)簽。這一特性和分詞處理步驟高度契合,使其可以直接用于分詞處理。
Andrew (2006)發(fā)表semi-CRF的第一個(gè)分詞實(shí)現(xiàn)。然而, 即使以當(dāng)時(shí)的標(biāo)準(zhǔn), 號(hào)稱直接建模的semi-CRF模型的分詞性能卻不甚理想。通常來(lái)說(shuō),直接建模會(huì)獲得更好的機(jī)器學(xué)習(xí)效果,然而在semi-CRF直接應(yīng)用于分詞時(shí),卻一直很難兌現(xiàn)。之后,Sun et al. (2009)和Sun et al. (2012)將包含隱變量的semi-CRF學(xué)習(xí)模型用于分詞,才將其分詞性能提升到前沿水平:前者是首個(gè)隱變量semi-CRF模型的工作,聲稱能夠同時(shí)利用基于字序列和基于詞序列的特征信息,并經(jīng)驗(yàn)證明引入隱含變量能通過(guò)有效捕捉長(zhǎng)距信息來(lái)提升長(zhǎng)詞的召回率;后者額外引用了新的高維標(biāo)簽轉(zhuǎn)移Markov特征,同時(shí)針對(duì)性地提出了基于特征頻數(shù)的自適應(yīng)在線梯度下降算法,以提升訓(xùn)練效率。值得注意的是,線性鏈CRF模型的訓(xùn)練時(shí)間比對(duì)應(yīng)的最大熵Markov模型會(huì)慢數(shù)倍,因?yàn)樽畲箪啬P陀?xùn)練時(shí)間正比于需要學(xué)習(xí)的標(biāo)簽數(shù)量,而CRF訓(xùn)練時(shí)間則正比于標(biāo)簽數(shù)量的平方,但semi-CRF的訓(xùn)練比標(biāo)準(zhǔn)的CRF還要緩慢,因此極大地限制了該類模型的實(shí)際應(yīng)用。
傳統(tǒng)的字標(biāo)注模型方法在進(jìn)一步發(fā)展之后, 也引入部分標(biāo)志性的已知詞信息(即詞表詞, in-vocabularywords, IV)。 Zhang et al. (2006)提出了一種基于子詞(subword)的標(biāo)注學(xué)習(xí),基本思路是從訓(xùn)練集中抽取高頻已知詞構(gòu)造子詞詞典。然而,該方法單獨(dú)使用效果不佳,需要結(jié)合其他模型,其性能才能和已有方法進(jìn)行有意義的比較。 Zhao&Kit(2007a)大幅度改進(jìn)了這個(gè)策略,通過(guò)在訓(xùn)練集上迭代最大匹配分詞的方法,找到最優(yōu)的子詞(子串)詞典,使用單一的子串標(biāo)注學(xué)習(xí)即可獲得最佳性能。
基于子串的直接標(biāo)注模型事實(shí)上過(guò)強(qiáng)地應(yīng)用了已知詞信息,因?yàn)樗凶哟紝儆谝阎~,并且在模型一開始就不能再切分。這一缺陷后來(lái)得到修正,主要的工作包括Zhao&Kit(2007b;2008b;2008a;2011)。在這些工作中,對(duì)已有工作的改進(jìn)主要有兩點(diǎn):其一,所有可能子串按照某個(gè)特定的統(tǒng)計(jì)度量方式根據(jù)訓(xùn)練集上的n-gram計(jì)數(shù)來(lái)進(jìn)行打分;其二,基本模型還是字位標(biāo)注學(xué)習(xí),前面獲得的子串信息以附加特征形式出現(xiàn)。這一工作獲得了傳統(tǒng)標(biāo)注模型下的最佳性能,包括囊括2008年SIGHAN Bakeoff-4的全部五項(xiàng)分詞封閉測(cè)試的第一名(Zhao&Kit, 2008b)。當(dāng)子串的抽取和統(tǒng)計(jì)度量得分計(jì)算擴(kuò)展到訓(xùn)練集之外,Zhao&Kit(2011)實(shí)際上提出了一種擴(kuò)展性很強(qiáng)的半監(jiān)督分詞方法,實(shí)驗(yàn)也驗(yàn)證了其有效性。
和以上所有基于串標(biāo)注,無(wú)論是線性鏈CRF標(biāo)注還是semi-CRF標(biāo)注的方法都不相同, Zhang & Clark(2007)引入了一種基于整句切分結(jié)構(gòu)學(xué)習(xí)的分詞方法。雖然他們聲稱這是一種基于詞的方法,但是他們的方法不同于以往的最顯著點(diǎn),是字和詞的n-gram特征,都以同等地位在整句的切分結(jié)構(gòu)分解中進(jìn)行特征提取。在細(xì)節(jié)上,他們采用了擴(kuò)展的感知機(jī)算法進(jìn)行訓(xùn)練,在解碼階段則使用近似的定寬搜索(beam search)。盡管其模型具備理論上更廣泛的特征表達(dá)能力,但事實(shí)上該工作未能給出更佳的分詞性能(參見表6的結(jié)果對(duì)比)。
由于分詞是自然語(yǔ)言處理的一個(gè)起始任務(wù),因此串標(biāo)注學(xué)習(xí)下的可選特征類型相當(dāng)有限。實(shí)際上,能選用的只是滑動(dòng)窗口下的n-gram特征, n-gram單元為字或者詞。理論上,以單個(gè)n-gram特征為單位進(jìn)行任意的特征模板選擇,在工程計(jì)算量上是可行的。實(shí)際的系統(tǒng)中,對(duì)于字特征多采取5字的滑動(dòng)窗口,而Zhao et al. (2006a)及其后續(xù)工作則僅用3字窗口;對(duì)于詞,則多采取3詞的滑動(dòng)窗口。然而,字位標(biāo)注并非直接的切分點(diǎn)學(xué)習(xí),從后者(切分點(diǎn))到前者(字位標(biāo)注系統(tǒng))有著多種方案,而一旦字位標(biāo)注發(fā)生改變,相應(yīng)的優(yōu)化n-gram特征集顯然會(huì)發(fā)生改變。這一現(xiàn)象的發(fā)現(xiàn)及其完整的經(jīng)驗(yàn)研究,發(fā)表在Zhaoet al. (2006b)和Zhao et al. (2010a)中。表2和表3分別列出了之前的標(biāo)注集和Zhao et al. (2010a)考察過(guò)的完整標(biāo)注集序列, 后者證明在6-tag標(biāo)注集配合使用3字窗口的6個(gè)n-gram特征(分別是C-1, C0, C1, C-1C0, C0C1,C-1C1,其中C0代表當(dāng)前字),即可獲得字位標(biāo)注學(xué)習(xí)的最佳性能(默認(rèn)使用CRF模型)。
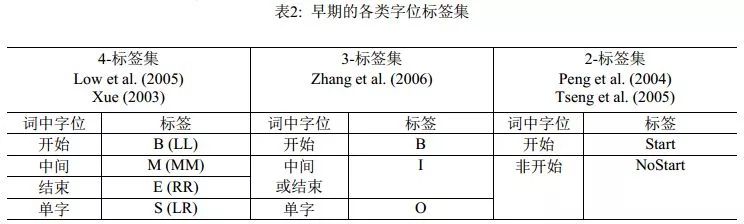
表3: 6-標(biāo)簽以下所有可能的字標(biāo)簽集及示例
3
深度學(xué)習(xí):神經(jīng)網(wǎng)絡(luò)分詞模型
自從詞嵌入(word embedding)表示達(dá)到了數(shù)值計(jì)算的實(shí)用化階段之后,深度學(xué)習(xí)開始席卷自然語(yǔ)言處理領(lǐng)域。原則上,嵌入向量承載了一部分字或詞的句法和語(yǔ)義信息,應(yīng)該能帶來(lái)進(jìn)一步的性能提升。如前所述,中文分詞任務(wù)中可用的特征僅限于滑動(dòng)窗口內(nèi)的n-gram特征。由此,雖然典型的深度學(xué)習(xí)模型皆以降低特征工程代價(jià)的優(yōu)勢(shì)而著稱,但是對(duì)于分詞任務(wù)的特征工程壓力的緩解卻相當(dāng)有限。因而,期望神經(jīng)分詞模型帶來(lái)進(jìn)一步性能改進(jìn)的方向在于:一,有效集成字或者詞的嵌入式表示,充分利用其中蘊(yùn)含的有效句法和語(yǔ)義信息;二,將神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力有效地和已有的傳統(tǒng)結(jié)構(gòu)化建模方法結(jié)合,如在經(jīng)典的字位標(biāo)注模型中用等價(jià)的相應(yīng)網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行置換。
Collobert et al. (2011)提出使用神經(jīng)網(wǎng)絡(luò)解決自然語(yǔ)言處理問(wèn)題,尤其是序列標(biāo)注類問(wèn)題的一般框架,這一框架抽取滑動(dòng)窗口內(nèi)的特征,在每一個(gè)窗口內(nèi)解決標(biāo)簽分類問(wèn)題。在此基礎(chǔ)上, Zheng et al. (2013)提出神經(jīng)網(wǎng)絡(luò)中文分詞方法,首次驗(yàn)證了深度學(xué)習(xí)方法應(yīng)用到中文分詞任務(wù)上的可行性。他們的工作直接借用了Collobert模型的結(jié)構(gòu),將字向量作為系統(tǒng)輸入,其技術(shù)貢獻(xiàn)包括:一,使用了大規(guī)模文本上預(yù)訓(xùn)練的字向量表示來(lái)改進(jìn)監(jiān)督學(xué)習(xí)(開放測(cè)試意義);二,使用類似感知機(jī)的訓(xùn)練方式取代傳統(tǒng)的最大似然方法,以加速神經(jīng)網(wǎng)絡(luò)訓(xùn)練。就結(jié)構(gòu)化建模來(lái)說(shuō),該工作等同于Low et al. (2005)的字位標(biāo)記的串學(xué)習(xí)模型,區(qū)別僅在于是用一個(gè)簡(jiǎn)單的神經(jīng)網(wǎng)絡(luò)模型替代了后者的最大熵模型,其模型框圖見圖1中的左圖。由于結(jié)構(gòu)化建模的缺陷,該模型的精度僅和早期Xue (2003)的結(jié)果相當(dāng),而遠(yuǎn)遜于傳統(tǒng)字標(biāo)注學(xué)習(xí)模型的佼佼者。
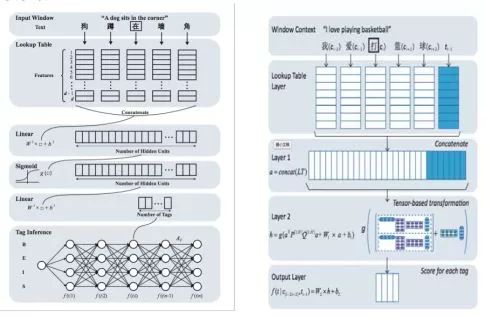
圖 1: Zheng et al. (2013) (左)和Pei et al. (2014) (右)的模型框架。
2014年,Pei et al. (2014)對(duì)Zheng et al. (2013)的模型做了重要改進(jìn),引入了標(biāo)簽向量來(lái)更精細(xì)地刻畫標(biāo)簽之間的轉(zhuǎn)移關(guān)系, 其改進(jìn)程度類似于Low et al. (2005)首次引入Markov特征到Ng & Low (2004)的最大熵模型之中。Pei et al.提出了一種新型神經(jīng)網(wǎng)絡(luò)即最大間隔張量神經(jīng)網(wǎng)絡(luò)(Max-Margin Tensor NeuralNetwork, MMTNN)并將其用于分詞任務(wù)(見圖1右),使用標(biāo)簽向量和張量變化來(lái)捕捉標(biāo)簽與標(biāo)簽之間、標(biāo)簽與上下文之間的關(guān)系。另外,為了降低計(jì)算復(fù)雜度和防止過(guò)擬合(所有神經(jīng)網(wǎng)絡(luò)模型的通病),該文還專門提出了一種新型張量分解方式。
隨后,為了更完整精細(xì)地對(duì)分詞上下文建模, Chen et al.(2015a)提出了一種帶有自適應(yīng)門結(jié)構(gòu)的遞歸神經(jīng)網(wǎng)絡(luò)(Gated recursive neural network, GRNN)抽取n-gram特征, 其中的兩種定制的門結(jié)構(gòu)(重置門、更新門)被用來(lái)控制n-gram信息的融合和抽取。與前述兩項(xiàng)研究中簡(jiǎn)單拼接字級(jí)信息不同,該模型用到了更深的網(wǎng)絡(luò)結(jié)構(gòu),為免于傳統(tǒng)優(yōu)化方法所受到的梯度擴(kuò)散的制約,該工作使用了有監(jiān)督逐層訓(xùn)練的方法。
同年, Chen et al. (2015b)針對(duì)滑動(dòng)窗口的局部性,提出用長(zhǎng)短期記憶神經(jīng)網(wǎng)絡(luò)(Long Short-TermMemory Neural Networks, LSTM)來(lái)捕捉長(zhǎng)距離依賴, 部分克服了過(guò)往的序列標(biāo)注方法只能從固定大小的滑動(dòng)窗口抽取特征的不足。 Xu & Sun(2016)將GRNN和LSTM聯(lián)合起來(lái)使用。 該工作可以看作是結(jié)合了Chen et al. (2015a)和Chen et al. (2015b)兩者的模型。該模型中,先用雙向LSTM提取上下文敏感的局部信息,然后在滑動(dòng)窗口內(nèi)將這些局部信息用帶門結(jié)構(gòu)的遞歸神經(jīng)網(wǎng)絡(luò)融合起來(lái),最后用作標(biāo)簽分類的依據(jù)。 LSTM是神經(jīng)網(wǎng)絡(luò)模型家族中和線性鏈CRF同等角色的結(jié)構(gòu)化建模工具,隨著它被引入分詞學(xué)習(xí),神經(jīng)網(wǎng)絡(luò)模型在分詞性能上開始可以和傳統(tǒng)機(jī)器學(xué)習(xí)模型相抗衡。我們將結(jié)構(gòu)化建模的傳統(tǒng)-神經(jīng)模型的對(duì)照情況列在表4中。
與傳統(tǒng)方法中基于字的序列標(biāo)注方案幾乎一統(tǒng)江湖的局面不同,神經(jīng)網(wǎng)絡(luò)有相對(duì)更靈活的結(jié)構(gòu)化建模能力,因而有別于序列標(biāo)注的其他方法也相繼涌現(xiàn)出來(lái)。 Ma & Hinrichs (2015)提出了一種基于字的切分動(dòng)作匹配算法,該算法在保持相當(dāng)程度的分詞性能的同時(shí),有著不亞于傳統(tǒng)方法的速度優(yōu)勢(shì)。具體來(lái)說(shuō),該文提出了一種新型的向量匹配算法,可以視為傳統(tǒng)序列標(biāo)注方法的一種擴(kuò)展,在訓(xùn)練和測(cè)試階段都只有線性的時(shí)間復(fù)雜度(見圖2左)。該工作有兩個(gè)亮點(diǎn)值得注意:一,首次嚴(yán)肅考慮了神經(jīng)模型分詞的計(jì)算效率問(wèn)題;二,遵循了嚴(yán)格的SIGHAN Bakeoff封閉測(cè)試的要求,只使用了簡(jiǎn)單的特征集合,而完全不依賴訓(xùn)練集之外的語(yǔ)言資源。
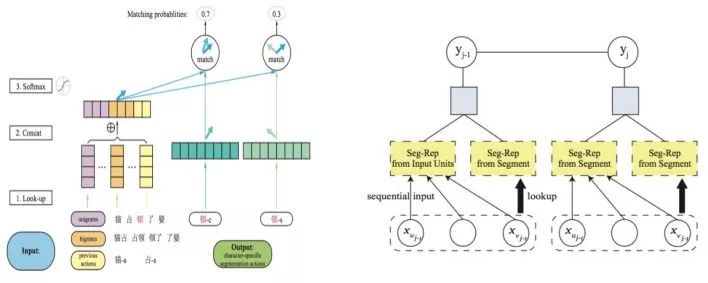
圖2: Ma & Hinrichs (2015) (左)和Liu et al. (2016) (右)的模型框圖
Zhang et al. (2016)提出了一種基于轉(zhuǎn)移的模型用于分詞,并將傳統(tǒng)的特征模版和神經(jīng)網(wǎng)絡(luò)自動(dòng)提取的特征結(jié)合起來(lái), 在神經(jīng)網(wǎng)絡(luò)自動(dòng)提取的特征和傳統(tǒng)的離散特征的融合方法做了嘗試。結(jié)果表明,通過(guò)組合這兩種特征,分詞精度可以得到進(jìn)一步提升。
Liu et al. (2016)首次將零階半馬爾可夫隨機(jī)場(chǎng)應(yīng)用到神經(jīng)分詞模型中,并分析了不同字向量和詞向量對(duì)分詞效果的影響。 此文基于semi-CRF建模分詞學(xué)習(xí)(見圖2右),用直接的切分塊嵌入表示和間接的輸入單元融合表示來(lái)刻畫切分塊,同時(shí)還考察了多種融合方式和多種切分塊嵌入表示。遺憾的是,該系統(tǒng)嚴(yán)重依賴傳統(tǒng)方法的輸出結(jié)果來(lái)提升性能。他們的具體做法是用傳統(tǒng)方法的分詞結(jié)果(在外部語(yǔ)料上)作為詞向量訓(xùn)練語(yǔ)料,因此,該文所報(bào)告的最終結(jié)果應(yīng)屬于開放測(cè)試范疇。而作為純粹的神經(jīng)模型版本下的semi-CRF模型,在封閉測(cè)試意義下,該系統(tǒng)的效果和傳統(tǒng)semi-CRF(如Andrew (2006))同樣效果不佳(具體見表6的結(jié)果對(duì)照)。
Cai & Zhao(2016) 徹底放棄滑動(dòng)窗口,提出對(duì)分詞句子直接建模的方法,以捕捉分詞的全部歷史信息, 提出了一個(gè)類似于Zhang & Clark (2007)的神經(jīng)分詞模型, 同時(shí)充分吸收了前面一些工作的有益經(jīng)驗(yàn),如門網(wǎng)絡(luò)結(jié)構(gòu)等(圖3)。由于覆蓋了前所未有的特征范圍,該模型在封閉測(cè)試意義上取得了和傳統(tǒng)模型接近的分詞性能。 概括來(lái)說(shuō),該方法使用了一個(gè)帶自適應(yīng)門結(jié)構(gòu)的組合神經(jīng)網(wǎng)絡(luò),詞向量表示通過(guò)其字向量生成,并用LSTM網(wǎng)絡(luò)的打分模型對(duì)詞向量序列打分。這種方法直接對(duì)分詞結(jié)構(gòu)進(jìn)行了建模,能利用字、詞、句三個(gè)層次的信息,是首個(gè)能完整捕捉切分和輸入歷史的方法。與之前的無(wú)論傳統(tǒng)和還是深度學(xué)習(xí)的方法相比,該模型將分詞動(dòng)作依賴的特征窗口擴(kuò)張到最大程度(見表5)。該文所提的分詞系統(tǒng)框架可以分為三個(gè)組件:一個(gè)依據(jù)字序列的詞向量生成網(wǎng)絡(luò)組合門網(wǎng)絡(luò) (gated combination neuralnetwork, GCNN,見圖4左);一個(gè)能對(duì)不同切分從最終結(jié)果(也就是詞序列)上進(jìn)行打分的估值網(wǎng)絡(luò);和一種尋找擁有最大分?jǐn)?shù)的切分的搜索算法。第一個(gè)模塊近似于模擬中文造詞法過(guò)程,這對(duì)于未登陸詞識(shí)別有著重要意義;第二個(gè)模塊從全句的角度對(duì)分詞的結(jié)果從流暢度和合理性上進(jìn)行打分,能最大限度地利用分詞上下文;第三個(gè)模塊則使在指數(shù)級(jí)的切分空間中尋找最可能的切分最優(yōu)解。
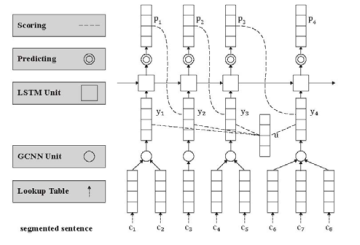
圖 3: Cai & Zhao (2016)的模型框圖
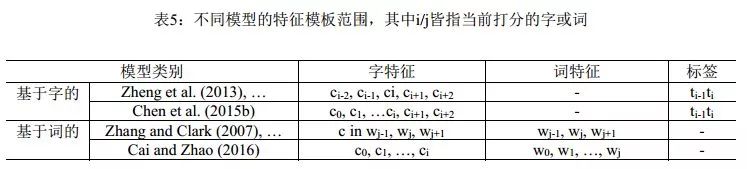
表6列出了近10年來(lái)主要的分詞系統(tǒng)在SIGHAN Bakeoff-2005語(yǔ)料上的分詞性能比較。神經(jīng)分詞系統(tǒng)短短數(shù)年間取得了長(zhǎng)足進(jìn)步,但整體上仍然不敵傳統(tǒng)模型。此外,盡管神經(jīng)網(wǎng)絡(luò)方法在知識(shí)依賴和特征工程方面有著巨大優(yōu)勢(shì),也取得了一定的進(jìn)展,但模型的計(jì)算復(fù)雜度也大幅提高,因?yàn)槌晒Φ纳窠?jīng)分詞器往往建立于更加精巧、更復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu)之上。事實(shí)上,經(jīng)歷五年,深度學(xué)習(xí)方法在最終模型的性能上,無(wú)論是分詞精度還是計(jì)算效率上,和傳統(tǒng)方法相比并都不具有顯著優(yōu)勢(shì)。
Cai et al. (2017)在Cai & Zhao (2016)的基礎(chǔ)上,通過(guò)簡(jiǎn)化網(wǎng)絡(luò)結(jié)構(gòu),混合字詞輸入以及使用早期更新(early update)等收斂性更好的訓(xùn)練策略, 設(shè)計(jì)了一個(gè)基于貪心搜索(greedy search)的快速分詞系統(tǒng)(見圖4右)。該算法與之前的深度學(xué)習(xí)算法相比不僅在速度上有了巨大提升,分詞精度也得到了進(jìn)一定提高。實(shí)驗(yàn)結(jié)果還表明,詞級(jí)信息比字級(jí)信息對(duì)于機(jī)器學(xué)習(xí)更有效,但是僅僅依賴詞級(jí)信息不可避免會(huì)削弱深度學(xué)習(xí)模型在陌生環(huán)境下的泛化能力。表7列舉了最近3年和速度相關(guān)的神經(jīng)分詞系統(tǒng)的結(jié)果。從中可見,Cai et al. (2017)首次使神經(jīng)模型方法在性能與效率上同時(shí)取得了和傳統(tǒng)方法相當(dāng)?shù)某煽?jī)。
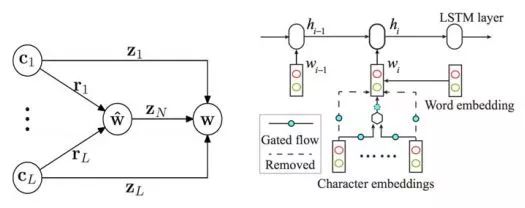
圖4: Cai & Zhao (2016) (左)和Cai et al. (2017) (右)的組合門網(wǎng)絡(luò)模塊
4
封閉及開放測(cè)試
SIGHAN Bakeoff的分詞評(píng)測(cè)定義了嚴(yán)格的封閉測(cè)試條件,要求不得使用訓(xùn)練集之外的語(yǔ)言資源,否則相應(yīng)結(jié)果則算開放測(cè)試類別。區(qū)分封閉和開放測(cè)試的一個(gè)主要目的,是分辨機(jī)器學(xué)習(xí)的性能提升的確是模型自身的改進(jìn),而非其它。
不管是傳統(tǒng)模型還是深度學(xué)習(xí)模型,可選的分詞用外部資源都可以包括各類詞典和切分語(yǔ)料(不一定和已有切分語(yǔ)料屬于同一個(gè)分詞規(guī)范)。外部資源的使用,可以通過(guò)額外標(biāo)記特征的形式引入,早期的開放測(cè)試系統(tǒng)包括Low et al. (2005)。 Zhao et al. (2010a)系統(tǒng)考察了多種外部資源,包括詞典、命名實(shí)體識(shí)別器以及其他語(yǔ)料上訓(xùn)練的分詞器,統(tǒng)一用于字標(biāo)注模型下的附加標(biāo)記特征,所提的具體做法很簡(jiǎn)單:在主切分器上加入其它分詞器(或命名實(shí)體識(shí)別器)給出的輔助標(biāo)記特征即可。結(jié)果表明,該策略在所有分詞規(guī)范語(yǔ)料上都能顯著提升性能,特別是在SIGHAN Bakeoff-2006的兩個(gè)簡(jiǎn)體語(yǔ)料上可以帶來(lái)額外的2個(gè)百分點(diǎn)的性能增益。表6展示的結(jié)果顯示, Zhao et al. (2010a)報(bào)告的開放測(cè)試結(jié)果目前為止依然為業(yè)界最高的分詞性能。該組結(jié)果實(shí)際上在Bakeoff-2006語(yǔ)料上給出,因而缺乏PKU上的結(jié)果,所用的附加資源則來(lái)自其它公開的Bakeoff語(yǔ)料。最后,該工作還經(jīng)驗(yàn)性暗示,如果可用的額外切分語(yǔ)料可以無(wú)限制擴(kuò)大,則分詞精度也可以無(wú)限制提升,雖然代價(jià)是切分速度會(huì)急劇下降。
基于嵌入表示的深度學(xué)習(xí)模型對(duì)于分詞的封閉和開放測(cè)試區(qū)分帶來(lái)了新的挑戰(zhàn)。顯然,在外部預(yù)訓(xùn)練的字或者詞嵌入向量屬于明顯的外部資源利用,因?yàn)樽窒蛄款A(yù)訓(xùn)練可以直接借用外部無(wú)標(biāo)記語(yǔ)料,典型如維基百科數(shù)據(jù),而詞向量的預(yù)訓(xùn)練則需要使用一個(gè)傳統(tǒng)分詞模型在外部語(yǔ)料上作預(yù)切分,這會(huì)同步地引入外部資源知識(shí)并隱性集成傳統(tǒng)分詞器的輸出結(jié)果。但是,相當(dāng)部分的神經(jīng)分詞的工作有意無(wú)意地忽略了以上做法的角色區(qū)分,實(shí)際上等于混淆了開放和封閉測(cè)試,更不用說(shuō)很多神經(jīng)模型系統(tǒng)甚至再次使用額外的詞典標(biāo)注來(lái)強(qiáng)化其性能。這些做法嚴(yán)重干擾了對(duì)于當(dāng)前神經(jīng)分詞模型的分析和效果評(píng)估:到底這些模型聲稱的性能提升,是來(lái)自新引入的深度學(xué)習(xí)模型,還是屬于悄悄引入的外部資源的貢獻(xiàn)?從表6中所比對(duì)的神經(jīng)分詞器的開放和封閉測(cè)試效果可以看出,大部分神經(jīng)分詞系統(tǒng)引入外部輔助信息,才能再獲得1-2個(gè)百分點(diǎn)的性能提升(已經(jīng)屬于開放測(cè)試范疇),才能和嚴(yán)格封閉測(cè)試意義上的傳統(tǒng)模型抗衡。如果嚴(yán)格剝離掉所有額外預(yù)訓(xùn)練的字或詞嵌入、額外引入的詞典標(biāo)注特征以及隱性集成的傳統(tǒng)分詞器的性能貢獻(xiàn),可以公正地看出,直至2016年底,所有神經(jīng)分詞系統(tǒng)單獨(dú)運(yùn)行時(shí),在性能(更不用說(shuō)在效率上)都不敵傳統(tǒng)系統(tǒng)。
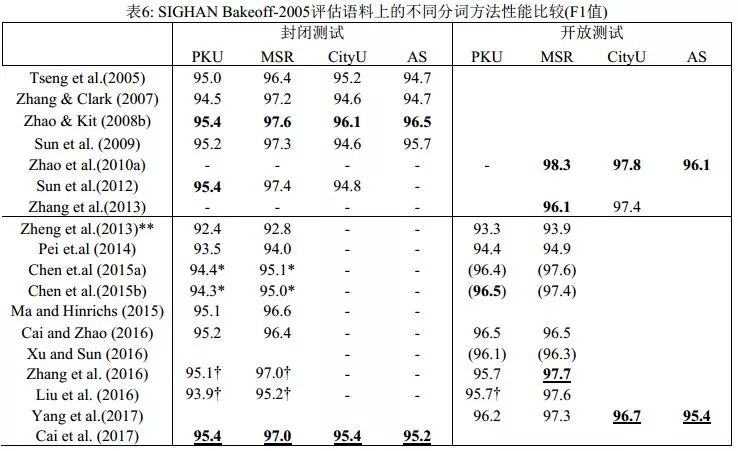
說(shuō)明:表格上部展示的是傳統(tǒng)方法,下部是深度學(xué)習(xí)方法。標(biāo)有雙星號(hào)(**)的是來(lái)自Pei et al. (2014)的再運(yùn)行結(jié)果;標(biāo)有星號(hào)(*)的是來(lái)自Cai & Zhao (2016)的再運(yùn)行結(jié)果;帶有? 是指使用了或者可能使用了預(yù)訓(xùn)練的字向量;帶有? 側(cè)是依賴傳統(tǒng)模型(在大規(guī)模未標(biāo)注語(yǔ)料上使用傳統(tǒng)切分的結(jié)果進(jìn)行預(yù)訓(xùn)練);而括號(hào)(…)里的結(jié)果使用了成語(yǔ)表。
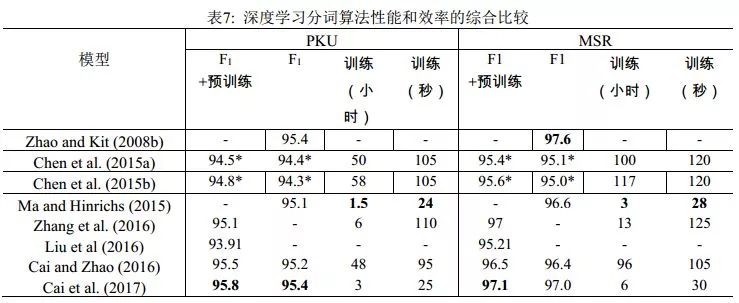
說(shuō)明:標(biāo)有星號(hào)(*)的數(shù)據(jù)來(lái)自Cai and Zhao (2016)再運(yùn)行的結(jié)果。此表列出的是Zhang et al. (2016)與Liu et al. (2016)中神經(jīng)網(wǎng)絡(luò)模型單獨(dú)工作的結(jié)果。注意大多數(shù)深度學(xué)習(xí)方法使用的字向量可以事先在大規(guī)模無(wú)標(biāo)記的語(yǔ)料上進(jìn)行預(yù)訓(xùn)練。嚴(yán)格來(lái)說(shuō),這類結(jié)果需歸于SIGHAN Bakeoff開放測(cè)試的類別。
Yang et al. (2017)專門調(diào)查分析了外部資源對(duì)中文分詞效果的影響,包括預(yù)訓(xùn)練的字/詞向量、標(biāo)點(diǎn)符號(hào)、自動(dòng)分詞結(jié)果、詞性標(biāo)注等,他們把每一種外部資源當(dāng)作一個(gè)輔助的分類任務(wù),使用多任務(wù)神經(jīng)學(xué)習(xí)方法預(yù)訓(xùn)練了一組對(duì)漢字上下文建模的共享參數(shù)。大量的實(shí)驗(yàn)表明了外部資源對(duì)神經(jīng)模型的性能的提升同樣具有重要意義。
如果把外部資源的貢獻(xiàn)進(jìn)行量化,或者簡(jiǎn)化一些,是否能夠給出機(jī)器學(xué)習(xí)的語(yǔ)料規(guī)模和學(xué)習(xí)性能的增長(zhǎng)之間的聯(lián)系規(guī)律?其實(shí),這方面的經(jīng)驗(yàn)工作已在Zhao et al. (2010b)之中完成,基本結(jié)論是統(tǒng)計(jì)機(jī)器學(xué)習(xí)系統(tǒng)給出的分詞精度和訓(xùn)練語(yǔ)料規(guī)模大體符合Zipf律,即:語(yǔ)料規(guī)模指數(shù)增長(zhǎng),性能才能線性增長(zhǎng)。而和統(tǒng)計(jì)分詞不同,更傳統(tǒng)的規(guī)則分詞,例如最大匹配法,其精度和所用的詞典(即所收錄的詞表詞)的規(guī)模成線性關(guān)系,因?yàn)榉衷~錯(cuò)誤主要是未登錄詞導(dǎo)致的。這一結(jié)論意味著統(tǒng)計(jì)方法,無(wú)論是傳統(tǒng)的字標(biāo)注還是現(xiàn)代的神經(jīng)模型,仍有著巨大的增長(zhǎng)空間。
5
結(jié)論
關(guān)于中文分詞的機(jī)器學(xué)習(xí)方法,長(zhǎng)期以來(lái)一直存在著“字還是詞”的特征表示優(yōu)越性之爭(zhēng),這恰好和語(yǔ)言學(xué)界對(duì)于中文結(jié)構(gòu)分析的“字本位”還是“詞本位”的爭(zhēng)議相映成趣。這一點(diǎn)早在黃和趙 (2006)中就給出了經(jīng)驗(yàn)性觀察結(jié)果:字、詞的特征學(xué)習(xí)需要在分詞系統(tǒng)中均衡表達(dá),才能獲得最佳性能。實(shí)際上,所謂字、詞爭(zhēng)議的核心對(duì)應(yīng)于分詞的兩個(gè)指標(biāo),已知詞(或詞表詞,即出現(xiàn)在切分訓(xùn)練語(yǔ)料中的詞)的識(shí)別精度和未登錄詞的識(shí)別精度,前者識(shí)別精度很高、相對(duì)容易但所占百分比高,后者識(shí)別精度很低、難度較大但所占百分比較低。經(jīng)驗(yàn)性的結(jié)果表明,強(qiáng)調(diào)基于字的特征及其表示會(huì)帶來(lái)更好的未登錄詞的識(shí)別性能。原因無(wú)他,未登錄詞從未在訓(xùn)練集出現(xiàn),只能依賴于模型通過(guò)字的創(chuàng)造性組合才能識(shí)別。反過(guò)來(lái),強(qiáng)調(diào)詞特征的系統(tǒng),包括基于詞的切分系統(tǒng),對(duì)于未登錄詞的識(shí)別效果通常略為遜色。最佳的分詞系統(tǒng)總是需要合理考慮字表示和詞表示的平衡問(wèn)題。最近的兩個(gè)工作的改進(jìn)點(diǎn)可以輔證這一結(jié)論: Caiet al. (2017)對(duì)于Cai & Zhao (2016)的一個(gè)關(guān)鍵性改進(jìn),是詞向量不再總是由字向量通過(guò)神經(jīng)網(wǎng)絡(luò)計(jì)算得到,而是采取了兩種策略,即低頻或者未知詞繼續(xù)由字向量計(jì)算,而訓(xùn)練集中的高頻詞(可以認(rèn)為是更為穩(wěn)定的已知詞)則進(jìn)行直接計(jì)算。當(dāng)系統(tǒng)由后者偏向字向量表示的模式轉(zhuǎn)向字-詞均衡的表示模式以后,確實(shí)帶來(lái)了額外的性能提升。
最近5年,基于神經(jīng)網(wǎng)絡(luò)模型的分詞學(xué)習(xí)已經(jīng)取得了一系列成果。就目前的結(jié)果來(lái)看,我們可以得出兩個(gè)基本結(jié)論:一,神經(jīng)分詞所取得的性能效果僅與傳統(tǒng)分詞系統(tǒng)大體相當(dāng),如果不是稍遜一籌的話;二,相當(dāng)一部分的神經(jīng)分詞系統(tǒng)所報(bào)告的性能改進(jìn)(我們謹(jǐn)慎推測(cè))來(lái)自于經(jīng)由字或詞嵌入表示所額外引入的外部語(yǔ)言資源信息,而非模型本身或字詞嵌入表示方式所導(dǎo)致的性能改進(jìn)。如果說(shuō)詞嵌入表示蘊(yùn)含著深層句法和語(yǔ)義信息的話,那么,這個(gè)結(jié)論似乎暗示一個(gè)推論,即分詞學(xué)習(xí)是一個(gè)不需要太多句法和語(yǔ)義信息即可良好完成的任務(wù)。
現(xiàn)代深度學(xué)習(xí)意義下的神經(jīng)網(wǎng)絡(luò)歸類于人工智能的聯(lián)結(jié)主義思潮,由于其帶有先天性的內(nèi)在拓?fù)浣Y(jié)構(gòu),如果能克服其訓(xùn)練計(jì)算低效的弊病,它就應(yīng)該是本身需要結(jié)構(gòu)化學(xué)習(xí)的自然語(yǔ)言處理任務(wù)的理想建模方式。這是我們?cè)谏疃葘W(xué)習(xí)時(shí)代看到更多樣化的結(jié)構(gòu)建模方法用于中文分詞任務(wù)的主要原因。如果我們能有效平衡字-詞表示的均衡性,不排除將來(lái)深度學(xué)習(xí)基礎(chǔ)上的分詞系統(tǒng)能有進(jìn)一步的成長(zhǎng)空間。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103550 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8501瀏覽量
134573 -
自然語(yǔ)言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14150
原文標(biāo)題:深度長(zhǎng)文:中文分詞的十年回顧
文章出處:【微信號(hào):thejiangmen,微信公眾號(hào):將門創(chuàng)投】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
蔡司工業(yè)CT三坐標(biāo)檢測(cè)智能駕艙護(hù)航三電質(zhì)量安全
BOE(京東方)“照亮成長(zhǎng)路”公益項(xiàng)目新十年啟幕 科技無(wú)界照亮美好未來(lái)
十年磨一劍,百頻通萬(wàn)物:國(guó)產(chǎn)無(wú)線通信突圍之路

10周年文章合集白皮書
如何應(yīng)對(duì)邊緣設(shè)備上部署GenAI的挑戰(zhàn)
氣侯技術(shù)公司紛紛采用 NVIDIA Earth-2 用于高分辨率、高能效、更準(zhǔn)確的天氣預(yù)報(bào)和備災(zāi)工作
納米技術(shù)的發(fā)展歷程和制造方法
北汽福田與寧德時(shí)代簽署十年戰(zhàn)略合作協(xié)議
2024年石墨烯科技的十大進(jìn)展和應(yīng)用領(lǐng)域

睿創(chuàng)微納五年&十年功勛員工頒獎(jiǎng)大會(huì)圓滿舉行
何小鵬宣布未來(lái)十年愿景,加速全球化AI汽車布局
以關(guān)鍵射頻技術(shù)賦能衛(wèi)星通信,Qorvo的產(chǎn)品陣列再擴(kuò)增

沃達(dá)豐與谷歌深化十年戰(zhàn)略合作
十年預(yù)言:Chiplet的使命
BOE京東方與聯(lián)合國(guó)教科文組織UNESCO簽訂合作協(xié)議 成為首個(gè)支持聯(lián)合國(guó)“科學(xué)十年”的中國(guó)科技企業(yè)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論