") 深度強(qiáng)化學(xué)習(xí)打造的ANYmal登上Science子刊,真的超越了波士頓動(dòng)力!
深度強(qiáng)化學(xué)習(xí)打造的ANYmal登上Science子刊,真的超越了波士頓動(dòng)力!
深度強(qiáng)化學(xué)習(xí)開發(fā)出的機(jī)器人模型通常很難應(yīng)用到真實(shí)環(huán)境中,因此機(jī)器人開發(fā)中鮮少使用該技術(shù)。然而這已經(jīng)板上釘釘了嗎?在兩天前引發(fā)人工智能界關(guān)注的 ANYmal 機(jī)器人中,其機(jī)動(dòng)性和適應(yīng)性看起來絲毫不遜色于波士頓動(dòng)力。其相關(guān)論文近期登上了 Science 子刊《Science Robotics》,并且明確指出使用了深度強(qiáng)化學(xué)習(xí)技術(shù)。基于 AI 技術(shù)的成功應(yīng)用,ANYmal 在數(shù)據(jù)驅(qū)動(dòng)的開發(fā)上或許會(huì)更有優(yōu)勢。
摘要:足式機(jī)器人是機(jī)器人學(xué)中最具挑戰(zhàn)性的主題之一。動(dòng)物動(dòng)態(tài)、敏捷的動(dòng)作是無法用現(xiàn)有人為方法模仿的。一種引人注目的方法是強(qiáng)化學(xué)習(xí),它只需要極少的手工設(shè)計(jì),能夠促進(jìn)控制策略的自然演化。然而,截至目前,足式機(jī)器人領(lǐng)域的強(qiáng)化學(xué)習(xí)研究還主要局限于模仿,只有少數(shù)相對(duì)簡單的例子被部署到真實(shí)環(huán)境系統(tǒng)中。主要原因在于,使用真實(shí)的機(jī)器人(尤其是使用帶有動(dòng)態(tài)平衡系統(tǒng)的真實(shí)機(jī)器人)進(jìn)行訓(xùn)練既復(fù)雜又昂貴。本文介紹了一種可以在模擬中訓(xùn)練神經(jīng)網(wǎng)絡(luò)策略并將其遷移到當(dāng)前最先進(jìn)足式機(jī)器人系統(tǒng)中的方法,因此利用了快速、自動(dòng)化、成本合算的數(shù)據(jù)生成方案。該方法被應(yīng)用到 ANYmal 機(jī)器人中,這是一款中型犬大小的四足復(fù)雜機(jī)器人系統(tǒng)。利用在模擬中訓(xùn)練的策略,ANYmal 獲得了之前方法無法實(shí)現(xiàn)的運(yùn)動(dòng)技能:它能精確、高效地服從高水平身體速度指令,奔跑速度比之前的機(jī)器人更快,甚至在復(fù)雜的環(huán)境中還能跌倒后爬起來。
圖 1:創(chuàng)建一個(gè)控制策略。第一步是確定機(jī)器人的物理參數(shù)并估計(jì)其中的不確定性。第二步是訓(xùn)練一個(gè)致動(dòng)器網(wǎng)絡(luò),建模復(fù)雜的致動(dòng)器/軟件動(dòng)力機(jī)制。第三步是利用前兩步中得到的模型訓(xùn)練一個(gè)控制策略。第四步是直接在物理系統(tǒng)中部署訓(xùn)練好的策略。
結(jié)果
該視頻展示了結(jié)果和方法。
基于命令的運(yùn)動(dòng)
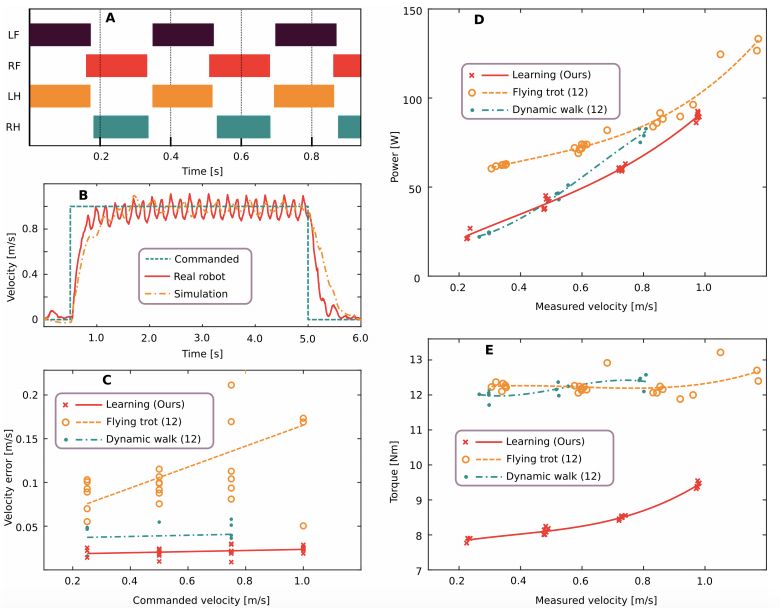
圖 2:習(xí)得運(yùn)動(dòng)控制器的量化評(píng)估結(jié)果。A. 發(fā)現(xiàn)的步態(tài)模式按速度指令以 1.0 m/s 的速度運(yùn)行。LF 表示左前腿,RF 表示右前腿,LH 表示左后腿,RH 表示右后腿。B. 使用本文方法得到的基礎(chǔ)速度的準(zhǔn)確率。C-E. 本文習(xí)得控制器與現(xiàn)有最佳控制器在能耗、速度誤差、扭矩大小方面的對(duì)比,給定的前進(jìn)速度指令為 0.25、0.5、0.75 和 1.0 m/s。
高速運(yùn)動(dòng)
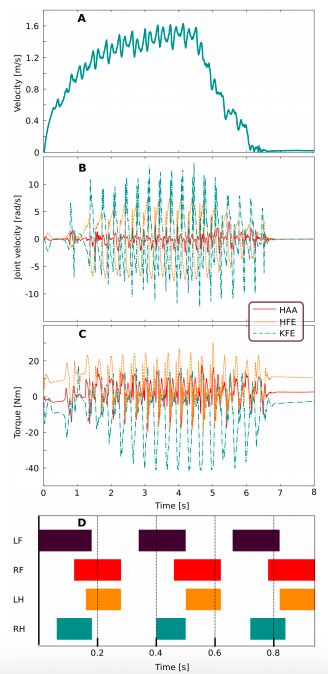
圖 3:對(duì)高速運(yùn)動(dòng)訓(xùn)練策略的評(píng)估結(jié)果。A. ANYmal 的前進(jìn)速度。B. 關(guān)節(jié)速度。C. 關(guān)節(jié)扭矩。D. 步態(tài)模式。
跌倒后的恢復(fù)
圖 4:在真實(shí)機(jī)器人上部署的恢復(fù)控制器。該研究學(xué)到的策略成功使機(jī)器人在 3 秒內(nèi)從隨機(jī)初始配置中恢復(fù)。
材料和方法
這一部分會(huì)詳細(xì)描述模擬環(huán)境、訓(xùn)練過程和在物理環(huán)境中的部署。圖 5 是訓(xùn)練方法概覽。訓(xùn)練過程如下:剛體模擬器會(huì)根據(jù)關(guān)節(jié)扭矩和當(dāng)前狀態(tài)輸出機(jī)器人的下一個(gè)狀態(tài)。關(guān)節(jié)速度和位置誤差會(huì)被緩存在有限時(shí)間窗口的關(guān)節(jié)狀態(tài)歷史中。由帶兩個(gè)隱藏層的 MLP 實(shí)現(xiàn)的控制策略會(huì)將當(dāng)前狀態(tài)和關(guān)節(jié)狀態(tài)歷史的觀察結(jié)果映射為關(guān)節(jié)位置目標(biāo)。最后,致動(dòng)器網(wǎng)絡(luò)會(huì)將關(guān)節(jié)狀態(tài)歷史和關(guān)節(jié)位置目標(biāo)映射為 12 個(gè)關(guān)節(jié)扭矩值,然后進(jìn)入下一個(gè)訓(xùn)練循環(huán)。
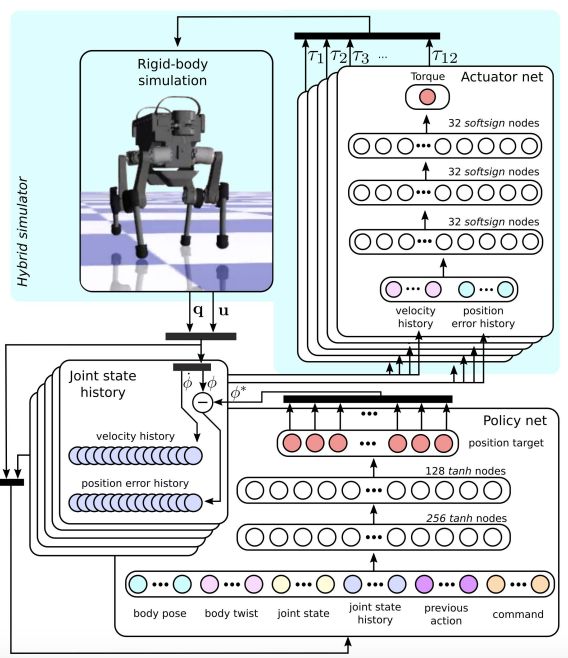
圖 5:模擬過程中的訓(xùn)練控制策略。
建模剛體動(dòng)力機(jī)制
為了在合理時(shí)間內(nèi)有效訓(xùn)練復(fù)雜的策略,并將其遷移到現(xiàn)實(shí)世界,我們需要一種又快又準(zhǔn)確的模擬平臺(tái)。開發(fā)行走機(jī)器人的最大挑戰(zhàn)之一是非連續(xù)接觸的動(dòng)力機(jī)制建模。為此,研究者使用了之前工作中開發(fā)出的剛體接觸求解器 [41]。這個(gè)接觸求解器使用了一個(gè)完全遵循庫倫摩擦錐約束的硬接觸模型。這種建模技術(shù)可以準(zhǔn)確地捕獲一系列剛體和環(huán)境進(jìn)行硬接觸時(shí)的真實(shí)動(dòng)力機(jī)制。該求解器能準(zhǔn)確而快速地在臺(tái)式計(jì)算機(jī)上每秒生成模擬四足動(dòng)物的 90 萬個(gè)時(shí)間步。
連接的慣性是從 CAD 模型估計(jì)出來的。研究者預(yù)期估計(jì)會(huì)達(dá)到 20% 的誤差因?yàn)闆]有建模布線和電子器件。為了考慮這些建模不確定性,研究者通過隨機(jī)采樣慣性訓(xùn)練了 30 種不同的 ANYmal 模型來使得策略更加穩(wěn)健。質(zhì)心位置、連接的質(zhì)量和關(guān)節(jié)位置分別通過添加從 U(?2, 2) cm、U(?15, 15)%、 U(?2, 2) cm 中采樣的噪聲進(jìn)行隨機(jī)化。
建模致動(dòng)器
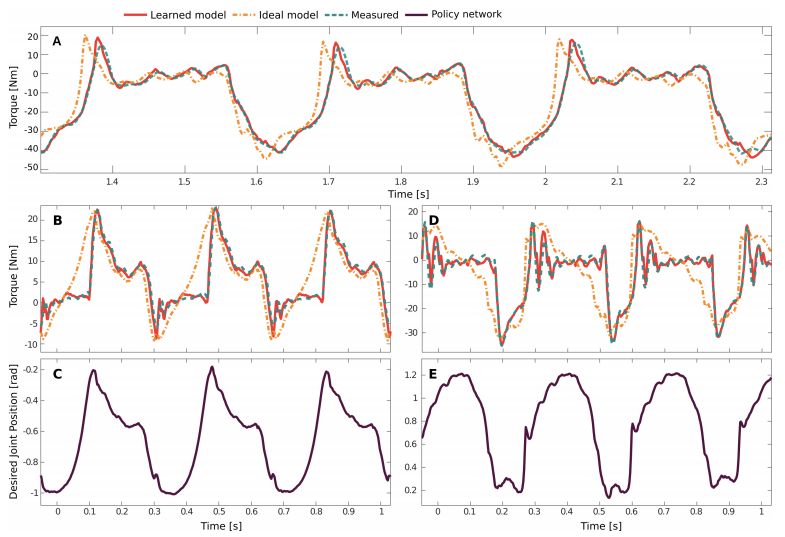
圖 6:學(xué)得致動(dòng)器模型的驗(yàn)證結(jié)果。
強(qiáng)化學(xué)習(xí)
研究者展示了離散時(shí)間中的控制問題。在每個(gè)時(shí)間步 t,智能體獲取觀測結(jié)果 o_t ∈O,執(zhí)行動(dòng)作 a_t ∈A,獲取標(biāo)量獎(jiǎng)勵(lì) r_t ∈ ?。研究者所指獎(jiǎng)勵(lì)和成本是可以互換的,因?yàn)槌杀揪褪秦?fù)的獎(jiǎng)勵(lì)。研究者用 O_t = 〈o_t, o_t ? 1, …, o_t ? h〉表示近期觀測結(jié)果的元組。智能體根據(jù)隨機(jī)策略 π(a_t|O_t) 選擇動(dòng)作,該隨機(jī)策略是基于近期觀測結(jié)果的動(dòng)作分布。其目的在于找到在無窮水平中使折扣獎(jiǎng)勵(lì)總和最大化的策略:
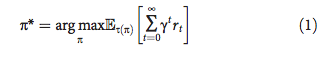
其中 γ ∈ (0, 1) 是折扣因子,τ(π) 是在策略 π 下的軌跡分布(該策略和環(huán)境動(dòng)態(tài)下的分布)。在研究設(shè)置中,觀測結(jié)果是評(píng)估機(jī)器人狀態(tài)的指標(biāo)(向控制器提供),動(dòng)作是向致動(dòng)器傳達(dá)的位置命令,獎(jiǎng)勵(lì)是指定的(以誘導(dǎo)感興趣的行為)。
多種強(qiáng)化學(xué)習(xí)算法可應(yīng)用于這個(gè)指定策略優(yōu)化問題。研究者選擇了置信域策略優(yōu)化(TRPO),該算法可在模擬中學(xué)習(xí)運(yùn)動(dòng)策略。它幾乎不需要調(diào)參,論文中所有學(xué)習(xí)會(huì)話都僅使用默認(rèn)參數(shù)([22, 54] 提供的參數(shù))。研究者使用了該算法的快速自定義實(shí)現(xiàn) [55]。這一高效實(shí)現(xiàn)和快速剛體模擬 [41] 可在約 4 小時(shí)內(nèi)生成和處理 2.5 億狀態(tài)轉(zhuǎn)換。當(dāng)該策略的平均性能在 300 個(gè) TRPO 迭代中的改進(jìn)沒有超過任務(wù)特定閾值時(shí),學(xué)習(xí)會(huì)話終止。
在物理系統(tǒng)上部署
研究者用 ANYmal 機(jī)器人來展示其方法在真實(shí)環(huán)境中的適用性,如圖 1 中步驟 4 所示。ANYmal 是一種體型與狗差不多的四足機(jī)器人,重 32kg。每只足約 55 厘米長,且有三個(gè)驅(qū)動(dòng)自由度,即髖部外展/內(nèi)收、髖關(guān)節(jié)屈/伸、膝關(guān)節(jié)屈/伸。
ANYmal 有 12 個(gè) SEA。一個(gè) SEA 由一個(gè)電動(dòng)機(jī)、一個(gè)高傳動(dòng)比傳動(dòng)裝置、一個(gè)彈性元件和兩個(gè)旋轉(zhuǎn)編碼器組成。它可以測量彈簧偏移和輸出位置。在本文中,研究者在 ANYmal 機(jī)器人的關(guān)節(jié)級(jí)促動(dòng)器模塊上使用了具有低反饋收益的關(guān)節(jié)級(jí) PD 控制器。促動(dòng)器的動(dòng)態(tài)包含多個(gè)連續(xù)的組件,如下所示。首先,使用 PD 控制器將位置指令轉(zhuǎn)換成期望的扭矩。接著,使用來自期望扭矩的 PID 控制器計(jì)算期望電流。然后,用磁場定向控制器將期望電流轉(zhuǎn)換成相電壓,該控制器在變速器的輸入端產(chǎn)生扭矩。變速器的輸出端與彈性元件相連,彈性元件的偏移最終在關(guān)節(jié)處生成扭矩。這些高度復(fù)雜的動(dòng)態(tài)引入了很多隱藏的內(nèi)部狀態(tài),研究者無法直接訪問這些內(nèi)部狀態(tài)并復(fù)雜化其控制問題。
從混合模擬中為訓(xùn)練策略獲得參數(shù)集后,在真實(shí)系統(tǒng)上的部署變得簡單多了。定制的 MLP 實(shí)現(xiàn)和訓(xùn)練好的參數(shù)集被導(dǎo)到機(jī)器人的機(jī)載 PC 上。當(dāng)這個(gè)網(wǎng)絡(luò)在 200Hz 時(shí),其狀態(tài)被評(píng)估為基于命令/高速的運(yùn)動(dòng),在 100Hz 時(shí)被評(píng)估為從墜落中恢復(fù)。研究者發(fā)現(xiàn),其性能出人意料地對(duì)控制率不敏感。例如,在 20 Hz 時(shí)訓(xùn)練恢復(fù)運(yùn)動(dòng)與在 100 Hz 時(shí)性能一致。這可能是因?yàn)榉D(zhuǎn)行為涉及低關(guān)節(jié)速度(大部分低于 6 弧度/秒)。更動(dòng)態(tài)的行為(如運(yùn)動(dòng))通常需要更高的控制率才能獲得足夠的性能。實(shí)驗(yàn)中使用了更高的頻率(100 Hz),因?yàn)檫@樣噪音更少。甚至在 100 Hz 時(shí),對(duì)網(wǎng)絡(luò)的評(píng)估僅使用了單個(gè) CPU 核上可用計(jì)算的 0.25 %。
-
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11517 -
ai技術(shù)
+關(guān)注
關(guān)注
1文章
1307瀏覽量
25010 -
波士頓動(dòng)力
+關(guān)注
關(guān)注
3文章
178瀏覽量
13405
原文標(biāo)題:真的超越了波士頓動(dòng)力!深度強(qiáng)化學(xué)習(xí)打造的 ANYmal 登上 Science 子刊
文章出處:【微信號(hào):WUKOOAI,微信公眾號(hào):悟空智能科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
18個(gè)常用的強(qiáng)化學(xué)習(xí)算法整理:從基礎(chǔ)方法到高級(jí)模型的理論技術(shù)與代碼實(shí)現(xiàn)

詳解RAD端到端強(qiáng)化學(xué)習(xí)后訓(xùn)練范式

淺談適用規(guī)模充電站的深度學(xué)習(xí)有序充電策略





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論