 詳解RAD端到端強化學習后訓練范式
詳解RAD端到端強化學習后訓練范式
RAD
端到端智駕強化學習后訓練范式
受限于算力和數據,大語言模型預訓練的 scalinglaw 已經趨近于極限。DeepSeekR1/OpenAl01通過強化學習后訓練涌現了強大的推理能力,掀起新一輪技術革新。當下主流的端到端智駕模型采用模仿學習訓練范式,即從大量的人類駕駛數據中擬合類人的駕駛策略。與大語言模型預訓練范式相對應,模仿學習的 scaling law 也將觸及瓶頸,其上限是人類的駕駛水平,難以實現遠超人類的高階自動駕駛。此外,模仿學習天然存在因果混淆和開環閉環差異性兩方面的局限性,其下限(安全性和穩定性)也難以保證。
我們提出端到端強化學習后訓練范式 RAD(ReinforcedAutonomous Driving),基于 3DGS 技術構建真實物理世界的孿生數字世界,讓端到端模型在數字世界中控制車輛行駛,像人類駕駛員一樣不斷地與環境交互并獲得反饋,基于安全性相關的獎勵函數,通過強化學習微調引導模型建模物理世界的因果關系。強化學習和模仿學習天然地互補,在模仿學習scalinglaw 的基礎上,強化學習scaling law 將進一步拓展端到端智駕模型的能力邊界。
項目主頁:https://hgao-cv.github.io/RAD 論文地址:https://arxiv.org/pdf/2502.13144
概述
受限于算力和數據,大語言模型預訓練的scaling law已經趨近于極限。DeepSeek R1 / OpenAI o1 通過強化學習后訓練涌現了強大的推理能力,掀起新一輪技術革新。當下主流的端到端智駕模型采用模仿學習訓練范式,即從大量的人類駕駛數據中擬合類人的駕駛策略。與大語言模型預訓練范式相對應,模仿學習的scaling law也將觸及瓶頸,其上限是人類的駕駛水平,難以實現遠超人類的高階自動駕駛。此外,模仿學習天然存在因果混淆和開環閉環差異性兩方面的局限性,其下限(安全性和穩定性)也難以保證。我們提出端到端強化學習后訓練范式RAD(Reinforced Autonomous Driving),基于3DGS技術構建真實物理世界的孿生數字世界,讓端到端模型在數字世界中控制車輛行駛,像人類駕駛員一樣不斷地與環境交互并獲得反饋,基于安全性相關的獎勵函數,通過強化學習微調引導模型建模物理世界的因果關系。強化學習和模仿學習天然地互補,在模仿學習scaling law的基礎上,強化學習scaling law將進一步拓展端到端智駕模型的能力邊界。
模仿學習的局限性:因果混淆與開環閉環差異
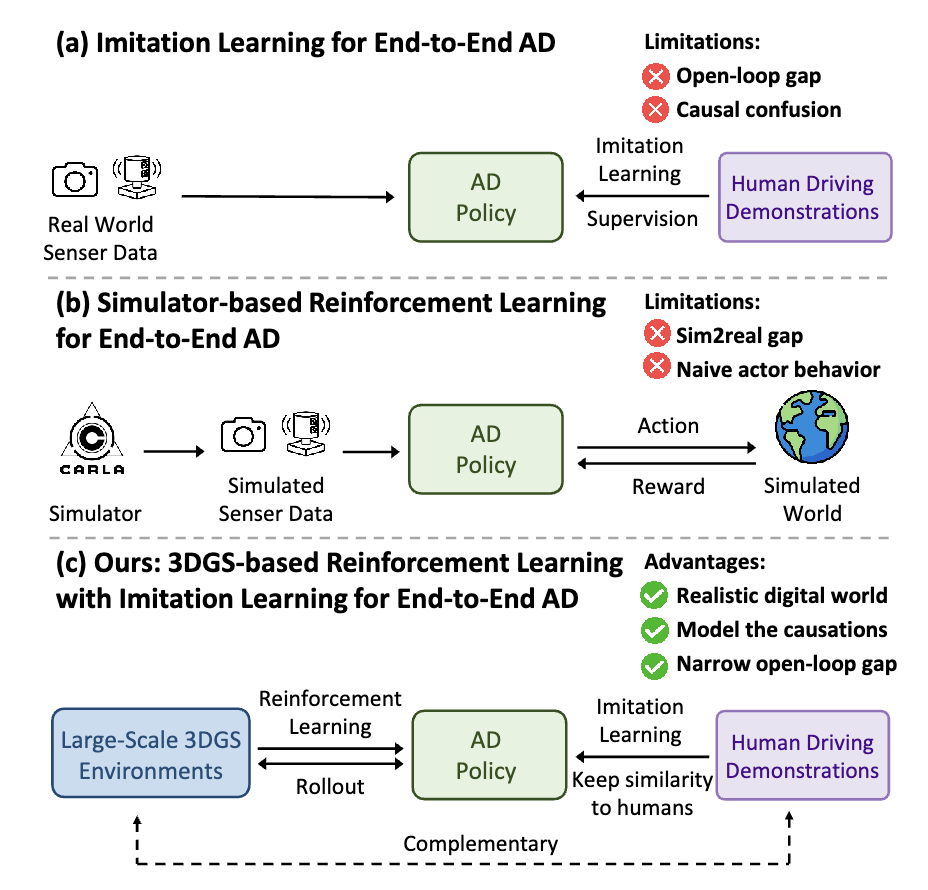
因果混淆(causal confusion)是模仿學習訓練范式的一大痛點。模仿學習的本質是使神經網絡模仿人類駕駛員的駕駛策略,其優化目標是最小化預測軌跡與專家軌跡之間的差異。模仿學習建模的是環境信息和規劃軌跡之間的相關性而非因果關系,容易造成因果混淆的問題。特別是對于端到端自動駕駛而言,輸入的環境信息尤為豐富,很難從高維度信息中找出導致規劃結果的真實原因,容易導致捷徑學習(shortcut learning),例如,從歷史軌跡外推未來軌跡。此外,由于訓練集主要由常見的駕駛行為主導,在僅使用模仿學習訓練的情況下,導致對駕駛的安全性不夠敏感。
另外,開環訓練和閉環部署之間的差距,也是模仿學習訓練范式難以忽視的問題。模仿學習是基于良好的分布內駕駛數據以開環方式進行訓練,但真實世界的駕駛系統是一個閉環系統,開環與閉環間存在極大的差異。在閉環中,單步的微小軌跡誤差會隨時間累積,導致駕駛系統進入一個偏離訓練集分布的場景。僅經過開環訓練的駕駛策略在面對訓練集分布外的場景時往往會失效。
RAD訓練范式
RAD基于3DGS技術構建真實物理世界的孿生數字世界,讓端到端模型在數字世界中控制車輛行駛,像人類駕駛員一樣不斷地與環境交互并獲得反饋,充分地探索狀態空間,學習應對各種復雜和罕見的分布外場景,基于安全性相關的獎勵函數,通過強化學習微調讓模型對安全性保持敏感,并建模物理世界的因果關系。
(1)三階段訓練架構
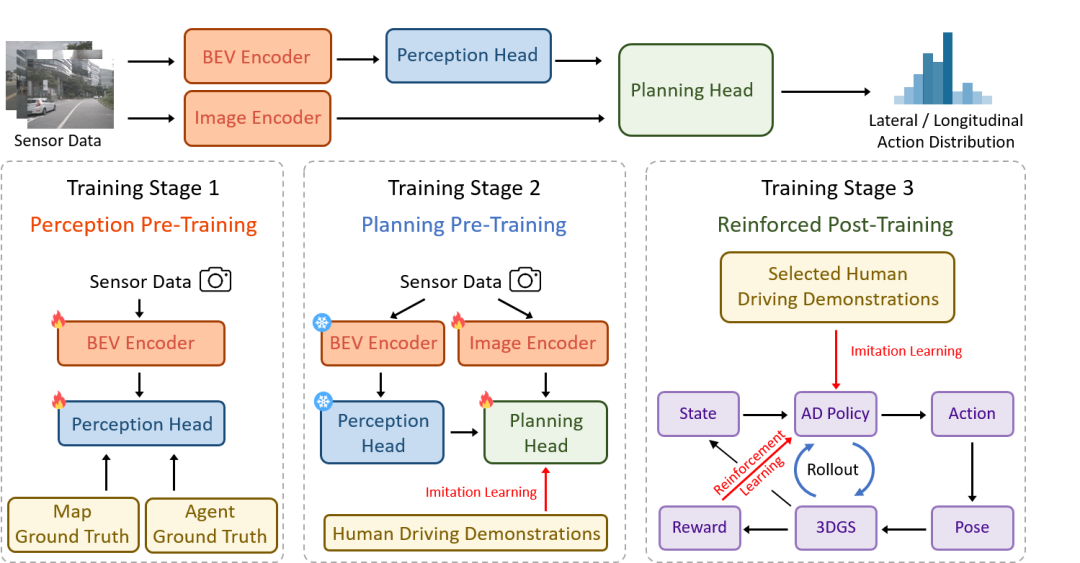
RAD 采用三階段訓練范式。在感知預訓練階段,通過監督學習的方式,訓練模型識別駕駛場景的關鍵元素,建立對周圍環境的準確認知;規劃預訓練階段,利用大規模的真實世界駕駛示范數據,通過模仿學習來初始化動作的概率分布,避免強化學習訓練的冷啟動問題;在強化后訓練階段,強化學習和模仿學習協同對策略進行微調。強化學習主要負責引導策略建模物理世界的因果關系和適應分布外的場景;模仿學習作為正則,約束與人類駕駛行為相似性。
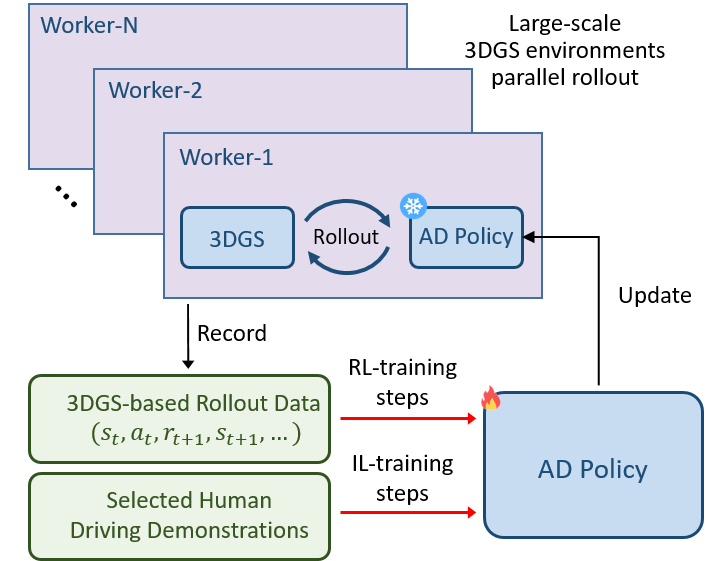
(2)安全導向的獎勵函數設計
為了確保自動駕駛汽車在行駛過程中的安全性,RAD 設計了專門的獎勵機制。這個機制主要關注四個方面:碰撞動態障礙物、碰撞靜態障礙物、與專家軌跡的位置偏差和航向偏差。一旦出現不安全的駕駛行為,比如碰撞或者偏離專家軌跡,就會觸發相應的懲罰獎勵。通過這種方式,引導策略有效地應對關鍵安全事件,讓自動駕駛汽車在訓練過程中逐漸學會如何避免危險,更好地理解現實世界中的因果關系。
(3)策略優化與輔助目標設計
為了提高訓練效率和效果,RAD將動作解耦為橫向動作和縱向動作,在 0.5 秒的短時間范圍內構建動作空間,有效降低了動作空間的維度,加快了訓練的收斂速度。此外,在策略優化方面,RAD 使用廣義優勢估計(GAE)來傳播獎勵,優化前面步驟的動作分布。考慮到動作空間的解耦,將獎勵和價值函數也進行解耦,分別計算橫向和縱向的優勢估計,并根據近端策略優化(PPO)來微調策略。
同時,針對強化學習中常見的稀疏獎勵問題,RAD 引入了輔助目標。這些輔助目標基于動態碰撞、靜態碰撞、位置偏差和航向偏差等多種獎勵源設計,能夠對舊策略選擇的動作進行評估,并通過調整動作概率分布來懲罰不良行為。例如,當前方存在潛在碰撞風險時,系統會降低加速動作的概率,并提升減速或制動的概率;當車輛偏離預定軌跡向左偏移時,則增加向右修正方向的動作概率,以減少軌跡偏差。通過這種方式,RAD 為整個動作分布提供密集的指導信息,確保策略能夠更快學會安全合理的駕駛行為,從而加速訓練的收斂。
閉環驗證
RAD 通過基于大規模 3DGS 的強化學習訓練,學習到了更有效的駕駛策略。在相同的閉環評估基準測試中,RAD 的碰撞率相較于傳統的模仿學習策略降低了 3 倍。這一結果表明,RAD 能在復雜的交通狀況下有效避免與動靜態障礙物的碰撞,做出更加安全、合理的決策。例如,在遇到突然闖入道路的行人或車輛時,RAD 能夠迅速做出準確反應,及時調整車速和行駛方向,避免碰撞事故的發生,而模仿學習策略則可能難以應對這種突發情況。 我們提供了一系列典型場景的閉環結果,以直觀展示 RAD 與模仿學習策略在實際駕駛場景中的關鍵差異:
場景1:繞行;右轉
場景2:U形掉頭
場景3:跟車蠕行
場景4:無保護左轉
場景5:擁擠路口通行
場景6:無保護左轉
場景7:繞行;窄道通行
場景8:無保護左轉
場景9:跟車行駛
后續工作
RAD作為創新的端到端自動駕駛后訓練范式,具有廣闊的應用前景和潛力。目前RAD仍存在一些局限性。例如,其他交通參與者的行為是基于場景回放,缺乏交互性的響應;在非剛性物體的渲染、欠觀測視角和低光照場景等方面,3DGS的效果還有提升的空間。在后續工作中,我們將進一步提升3DGS孿生數字世界的真實性和交互性,并繼續探索強化學習scaling law的上限。
-
模型
+關注
關注
1文章
3485瀏覽量
49987 -
強化學習
+關注
關注
4文章
269瀏覽量
11515 -
地平線
+關注
關注
0文章
391瀏覽量
15403 -
算力
+關注
關注
2文章
1142瀏覽量
15444
原文標題:開發者說|RAD:基于3DGS孿生數字世界的端到端強化學習后訓練范式
文章出處:【微信號:horizonrobotics,微信公眾號:地平線HorizonRobotics】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
什么是深度強化學習?深度強化學習算法應用分析

深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
機器學習中的無模型強化學習算法及研究綜述

模型化深度強化學習應用研究綜述

《自動化學報》—多Agent深度強化學習綜述

ICLR 2023 Spotlight|節省95%訓練開銷,清華黃隆波團隊提出強化學習專用稀疏訓練框架RLx2


端到端InfiniBand網絡解決LLM訓練瓶頸






 工商網監
工商網監
評論