 從數據科學從業者的角度退一步看一下人工智能的一些關鍵領域的發展
從數據科學從業者的角度退一步看一下人工智能的一些關鍵領域的發展
1、簡介
過去幾年一直是人工智能愛好者和機器學習專業人士最幸福的時光。因為這些技術已經發展成為主流,并且正在影響著數百萬人的生活。各國現在都有專門的人工智能規劃和預算,以確保在這場比賽中保持優勢。
數據科學從業人員也是如此,這個領域正在發生很多事情,你必須要跑的足夠的快才能跟上時代步伐。回顧歷史,展望未來一直是我們尋找方向的最佳方法。
這也是我為什么想從數據科學從業者的角度退一步看一下人工智能的一些關鍵領域的發展,它們突破了什么?2018年發生了什么?2019年會發生什么?
我將在本文中介紹自然語言處理(NLP)、計算機視覺、工具庫、強化學習、走向合乎正道的人工智能。
2、自然語言處理(NLP)
讓機器分析單詞和句子似乎是一個夢想,就算我們人類有時候也很難掌握語言的細微差別,但2018年確實是NLP的分水嶺。
我們看到了一個又一個顯著的突破:ULMFiT、ELMO、OpenAI的Transformer和Google的BERT等等。遷移學習(能夠將預訓練模型應用于數據的藝術)成功應用于NLP任務,為無限可能的應用打開了大門。讓我們更詳細地看一下這些關鍵技術的發展。
ULMFiT
ULMFiT由Sebastian Ruder和fast.ai的Jeremy Howard設計,它是第一個在今年啟動的NLP遷移學習框架。對于沒有經驗的人來說,它代表通用語言的微調模型。Jeremy和Sebastian讓ULMFiT真正配得上Universal這個詞,該框架幾乎可以應用于任何NLP任務!
想知道對于ULMFiT的最佳部分以及即將看到的后續框架嗎?事實上你不需要從頭開始訓練模型!研究人員在這方面做了很多努力,以至于你可以學習并將其應用到自己的項目中。ULMFiT可以應用六個文本分類任務中,而且結果要比現在最先進的方法要好。
你可以閱讀Prateek Joshi關于如何開始使用ULMFiT以解決任何文本分類問題的優秀教程。
ELMO
猜一下ELMo代表著什么嗎?它是語言模型嵌入的簡稱,是不是很有創意? ELMo一發布就引起了ML社區的關注。
ELMo使用語言模型來獲取每個單詞的嵌入,同時還考慮其中單詞是否適合句子或段落的上下文。上下文是NLP的一個重要領域,大多數人以前對上下文都沒有很好的處理方法。ELMo使用雙向LSTM來創建嵌入,如果你聽不懂-請參考這篇文章,它可以讓你很要的了解LSTM是什么以及它們是如何工作的。
與ULMFiT一樣,ELMo顯著提高了各種NLP任務的性能,如情緒分析和問答,在這里了解更多相關信息。
BERT
不少專家聲稱BERT的發布標志著NLP的新時代。繼ULMFiT和ELMo之后,BERT憑借其性能真正擊敗了競爭對手。正如原論文所述,“BERT在概念上更簡單且更強大”。BERT在11個NLP任務中獲得了最先進的結果,在SQuAD基準測試中查看他們的結果:
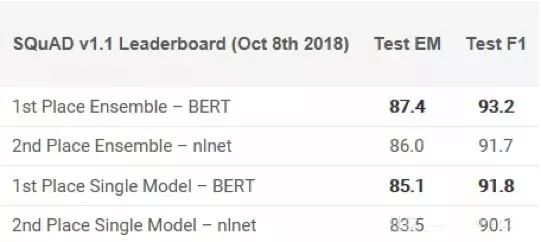
有興趣入門嗎?你可以使用PyTorch實現或Google的TensorFlow代碼嘗試在自己的計算機上得出結果。
我很確定你想知道BERT代表什么,它實際上是Transformers的雙向編碼器表示,如果你能夠領悟到這些,那很不錯了。
PyText
Facebook開源了深度學習NLP框架PyText,它在不久之前發布,但我仍然要測試它,但就早期的評論來說非常有希望。根據FB發表的研究,PyText使會話模型的準確性提高了10%,并且縮短了訓練時間。
PyText實際上落后于Facebook其他一些產品,如FB Messenger。如果你對此有興趣。你可以通過GitHub下載代碼來自行嘗試。
2019年NLP趨勢:
塞巴斯蒂安·羅德講述了NLP在2019年的發展方向,以下是他的想法:
預訓練的語言模型嵌入將無處不在,不使用它們的模型將是罕見的。
我們將看到可以編碼專門信息的預訓練模型,這些信息是對語言模型嵌入的補充。
我們將看到有關多語言應用程序和跨語言模型的成果。特別是,在跨語言嵌入的基礎上,我們將看到深度預訓練的跨語言表示的出現。
3、計算機視覺
這是現在深度學習中最受歡迎的領域,我覺得我們已經完全獲取了計算機視覺中容易實現的目標。無論是圖像還是視頻,我們都看到了大量的框架和庫,這使得計算機視覺任務變得輕而易舉。
我們今年在Analytics Vidhya花了很多時間研究這些概念的普通化。你可以在這里查看我們的計算機視覺特定文章,涵蓋從視頻和圖像中的對象檢測到預訓練模型列表的相關文章,以開始你的深度學習之旅。
以下是我今年在CV中看到的最佳開發項目:
如果你對這個美妙的領域感到好奇,那么請繼續使用我們的“使用深度學習的計算機視覺”課程開始你的旅程。
BigGAN的發布
在2014年,Ian Goodfellow設計了GAN,這個概念產生了多種多樣的應用程序。年復一年,我們看到原始概念為了適應實際用例正在慢慢調整,直到今年,仍然存在一個共識:機器生成的圖像相當容易被發現。
但最近幾個月,這個現象已經開始改變。或許隨著BigGAN的創建,該現象或許可以徹底消失,以下是用此方法生成的圖像:
除非你拿顯微鏡看,否則你將看不出來上面的圖片有任何問題。毫無疑問GAN正在改變我們對數字圖像(和視頻)的感知方式。
Fast.ai的模型18分鐘內在ImageNet上被訓練
這是一個非常酷的方向:大家普遍認為需要大量數據以及大量計算資源來執行適當的深度學習任務,包括在ImageNet數據集上從頭開始訓練模型。我理解這種看法,大多數人都認為在之前也是如此,但我想我們之前都可能理解錯了。
Fast.ai的模型在18分鐘內達到了93%的準確率,他們使用的硬件48個NVIDIA V100 GPU,他們使用fastai和PyTorch庫構建了算法。
所有的這些放在一起的總成本僅為40美元! 杰里米在這里更詳細地描述了他們的方法,包括技術。這是屬于每個人的勝利!
NVIDIA的vid2vid技術
在過去的4-5年里,圖像處理已經實現了跨越式發展,但視頻呢?事實證明,將方法從靜態框架轉換為動態框架比大多數人想象的要困難一些。你能拍攝視頻序列并預測下一幀會發生什么嗎?答案是不能!
NVIDIA決定在今年之前開源他們的方法,他們的vid2vid方法的目標是從給定的輸入視頻學習映射函數,以產生輸出視頻,該視頻以令人難以置信的精度預測輸入視頻的內容。
你可以在這里的GitHub上試用他們的PyTorch實現。
2019年計算機視覺的趨勢:
就像我之前提到的那樣,在2019年可能看到是改進而不是發明。例如自動駕駛汽車、面部識別算法、虛擬現實算法優化等。就個人而言,我希望看到很多研究在實際場景中實施,像CVPR和ICML這樣的會議描繪的這個領域的最新成果,但這些項目在現實中的使用有多接近?
視覺問答和視覺對話系統最終可能很快就會如他們期盼的那樣首次亮相。雖然這些系統缺乏概括的能力,但希望我們很快就會看到一種綜合的多模式方法。
自監督學習是今年最重要的創新,我可以打賭明年它將會用于更多的研究。這是一個非常酷的學習線:標簽可以直接根據我們輸入的數據確定,而不是浪費時間手動標記圖像。
4、工具和庫
工具和庫是數據科學家的基礎。我參與了大量關于哪種工具最好的辯論,哪個框架會取代另一個,哪個庫是經濟計算的縮影等等。
但有一點共識--我們需要掌握該領域的最新工具,否則就有被淘汰的風險。 Python取代其他所有事物并將自己打造成行業領導者的步伐就是這樣的例子。 當然,其中很多都歸結為主觀選擇,但如果你不考慮最先進的技術,我建議你現在開始,否則后果可能將不可預測。那么成為今年頭條新聞的是什么?我們來看看吧!
PyTorch 1.0
什么是PyTorch?我已經多次在本文中提到它了,你可以在Faizan Shaikh的文章中熟悉這個框架。
這是我最喜歡的關于深度學習文章之一!當時TensorFlow很緩慢,這為PyTorch打開了大門快速獲得深度學習市場。我在GitHub上看到的大部分代碼都是PyTorch實現的。這并非因為PyTorch非常靈活,而是最新版本(v1.0)已經大規模應用到許多Facebook產品和服務,包括每天執行60億次文本翻譯。PyTorch的使用率在2019年上升,所以現在是加入的好時機。
AutoML—自動機器學習
AutoML在過去幾年中逐漸取得進展。RapidMiner、KNIME、DataRobot和H2O.ai等公司都發布了非常不錯的產品,展示了這項服務的巨大潛力。你能想象在ML項目上工作,只需要使用拖放界面而無需編碼嗎?這種現象在未來并不太遙遠。但除了這些公司之外,ML / DL領域還有一個重要的發布-Auto Keras!
它是一個用于執行AutoML任務的開源庫。其背后的目的是讓沒有ML背景的領域專家進行深度學習。請務必在此處查看,它準備在未來幾年內大規模運行。
TensorFlow.js-瀏覽器中的深度學習
我們一直都喜歡在最喜歡的IDE和編輯器中構建和設計機器學習和深度學習模型。如何邁出一步,嘗試不同的東西?我將要介紹如何在你的網絡瀏覽器中進行深度學習!由于TensorFlow.js的發布,已成為現實。
TensorFlow.js主要有三個優點/功能:
1.使用JavaScript開發和創建機器學習模型;
2.在瀏覽器中運行預先存在的TensorFlow模型;
3.重新創建已有的模型;
2019年的AutoML趨勢
我個人特別關注AutoML,為什么?因為我認為未來幾年它將成為數據科學領域真正的游戲規則改變者。跟我有同樣想法的人是H2O.ai的Marios Michailidis、Kaggle Grandmaster,他們都對AutoML有很高期望:
機器學習繼續成為未來最重要的趨勢之一,鑒于其增長速度,自動化是最大化其價值的關鍵,是充分利用數據科學資源的關鍵。它可以應用到的領域是無限的:信用、保險、欺詐、計算機視覺、聲學、傳感器、推薦、預測、NLP等等,能夠在這個領域工作是一種榮幸。AutoML趨勢:
提供智能可視化和解釋,以幫助描述和理解數據;
查找/構建/提取給定數據集的更好特征;
快速建立更強大/更智能的預測模型;
通過機器學習可解釋性彌補這些模型的黑匣子建模和生產之間的差距;
促進這些模型落地生產;
5、強化學習
如果我不得不選擇一個我看到的滲透更多領域的技術,那就是強化學習。除了不定期看到的頭條新聞之外,我還在社區中了解到,它太注重數學,并且沒有真正的行業應用程序可供專一展示。
雖然這在某種程度上是正確的,但我希望看到的是明年更多來自RL的實際用例。我在每月GitHub和Reddit排序系列中,我傾向于至少保留一個關于RL的存儲庫或討論,至少圍繞該主題的討論。
OpenAI已經發布了一個非常有用的工具包,可以讓初學者從這個領域開始。
OpenAI在深度強化學習中的應用
如果RL的研究進展緩慢,那么圍繞它的教育材料將會很少。但事實上,OpenAI已經開放了一些關于這個主題的精彩材料。他們稱這個項目為“Spinning Up in Deep RL”,你可以在這里閱讀所有相關內容。它實際上是非常全面RL的資源列表,這里有很多材料包括RL術語、如何成為RL研究者、重要論文列表、一個記錄完備的代碼存儲庫、甚至還有一些練習來幫助你入門。
如果你打算開始使用RL,那么現在開始!
Google Dopamine
為了加速研究并讓社區更多的參與強化學習,Google AI團隊開源了Dopamine,這是一個TensorFlow框架,旨在通過它來使更靈活和可重復性來構建RL模型。
你可以在此GitHub存儲庫中找到整個訓練數據以及TensorFlow代碼(僅15個Python notebooks!)。這是在受控且靈活的環境中進行簡單實驗的完美平臺,聽起來像數據科學家的夢想。
2019年強化學習趨勢
Xander Steenbrugge是DataHack Summit的代表,也是ArxivInsights頻道的創始人,他非常擅長強化學習。以下是他對RL當前狀態的看法以及2019年的預期:
我目前看到RL領域的三個主要問題:
樣本復雜性(代理需要查看/收集以獲得的經驗數量);
泛化和轉移學習(訓練任務A,測試相關任務B);
分層RL(自動子目標分解);
我相信前兩個問題可以通過與無監督表示學習相關的類似技術來解決。目前在RL中,我們正在使用稀疏獎勵信號訓練深度神經網絡,從原始輸入空間(例如像素)映射到端到端方式的動作(例如,使用反向傳播)。
我認為能夠促進強化學習快速發展的道路是利用無監督的表示學習(自動編碼器、VAE、GAN)將凌亂的高維輸入空間(例如像素)轉換為低維“概念”空間。
人工智能:符合倫理才更重要
想象一下由算法統治的世界,算法決定了人類采取的每一個行動。這不是一個美好的場景,對嗎?AI中的倫理規范是Analytics Vidhya一直熱衷于討論的話題。
今年有相當多的組織因為Facebook的劍橋分析公司丑聞和谷歌內部普遍關于設計武器新聞丑聞而遭受危機。沒有一個開箱即用的解決方案或一個適合所有解決方案來處理AI的倫理方面。它需要一種細致入微的方法,并結合領導層提出的結構化路徑。讓我們看看今年出現的重大政策:GDPR。
GDPR如何改變游戲規則
GDPR或通用數據保護法規肯定會對用于構建AI應用程序的數據收集方式產生影響。GDPR的作用是以確保用戶可以更好地控制他們的數據。那么這對AI有何影響?我們可以想象一下,如果數據科學家沒有數據(或足夠數據),那么構建任何模型都會還沒開始就失敗。
2019年的AI倫理趨勢預期
這是一個灰色的領域。就像我提到的那樣,沒有一個解決方案可以解決這個問題。我們必須聚集在一起,將倫理問題整合到AI項目中。那么我們怎樣才能實現這一目標呢?正如Analytics Vidhya的創始人兼首席執行官Kunal Jain在2018年DataHack峰會上的演講中所強調的那樣:我們需要確定一個其他人可以遵循的框架。
結束語
有影響力!這是2018年來描述AI最佳的詞匯。今年我成為ULMFiT的狂熱用戶,我也很期待BERT。
-
人工智能
+關注
關注
1804文章
48788瀏覽量
247009 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14043 -
數據科學
+關注
關注
0文章
168瀏覽量
10422
原文標題:2018年AI和ML(NLP、計算機視覺、強化學習)技術總結和2019年趨勢
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
助推數字化影視進程:影視從業者的得力助手
哪些專業適合學習嵌入式開發?
沙子變芯片,一步步帶你走進高科技的微觀世界

學嵌入式好找工作嗎?
如何在化學和材料科學領域開展有影響力的人工智能研究?(一)






 工商網監
工商網監
評論