") 華為云刷新深度學(xué)習(xí)加速紀(jì)錄
華為云刷新深度學(xué)習(xí)加速紀(jì)錄
華為云ModelArts在國際權(quán)威的深度學(xué)習(xí)模型基準(zhǔn)測試平臺斯坦福DAWNBenchmark上取得了當(dāng)前圖像識別訓(xùn)練時間最佳成績,ResNet-50在ImageNet數(shù)據(jù)集上收斂僅用10分28秒,比第二名成績提升近44%。華為自研了分布式通用加速框架MoXing,在應(yīng)用層和TensorFlow、MXNet、PyTorch等框架之間實現(xiàn)再優(yōu)化。
日前,斯坦福大學(xué)發(fā)布了DAWNBenchmark最新成績,在圖像識別(ResNet50-on-ImageNet,93%以上精度)的總訓(xùn)練時間上,華為云ModelArts排名第一,僅需10分28秒,比第二名提升近44%。

斯坦福大學(xué)DAWNBenchmark圖像識別訓(xùn)練時間最新成績,華為云ModelArts以10分28秒排名第一,超越了fast.ai、谷歌等勁敵。
作為人工智能最重要的基礎(chǔ)技術(shù)之一,近年來深度學(xué)習(xí)逐步延伸到更多的應(yīng)用場景。除了精度,訓(xùn)練時間和成本也是構(gòu)建深度學(xué)習(xí)模型時需要考慮的核心要素。然而,當(dāng)前的深度學(xué)習(xí)基準(zhǔn)往往以衡量精度為主,斯坦福大學(xué)DAWNBench正是在此背景下提出。
斯坦福DAWNBench是衡量端到端深度學(xué)習(xí)模型訓(xùn)練和推理性能的國際權(quán)威基準(zhǔn)測試平臺,提供了一套通用的深度學(xué)習(xí)評價指標(biāo),用于評估不同優(yōu)化策略、模型架構(gòu)、軟件框架、云和硬件上的訓(xùn)練時間、訓(xùn)練成本、推理延遲以及推理成本,吸引了谷歌、亞馬遜AWS、fast.ai等高水平隊伍參與,相應(yīng)的排名反映了當(dāng)前全球業(yè)界深度學(xué)習(xí)平臺技術(shù)的領(lǐng)先性。
正是在這樣高手云集的基準(zhǔn)測試中,華為云ModelArts第一次參加國際排名,便實現(xiàn)了更低成本、更快速度的體驗。
華為云創(chuàng)造端到端全棧優(yōu)化新紀(jì)錄:128塊GPU,10分鐘訓(xùn)練完ImageNet
為了達(dá)到更高的精度,通常深度學(xué)習(xí)所需數(shù)據(jù)量和模型都很大,訓(xùn)練非常耗時。例如,在計算機視覺領(lǐng)域常用的經(jīng)典ImageNet數(shù)據(jù)集(1000個類別,共128萬張圖片)上,用1塊P100 GPU訓(xùn)練一個ResNet-50模型, 耗時需要將近1周。這嚴(yán)重阻礙了深度學(xué)習(xí)應(yīng)用的開發(fā)進(jìn)度。因此,深度學(xué)習(xí)訓(xùn)練加速一直是學(xué)術(shù)界和工業(yè)界所關(guān)注的重要問題,也是深度學(xué)習(xí)應(yīng)用的主要痛點。
曾任Kaggle總裁和首席科學(xué)家的澳大利亞數(shù)據(jù)科學(xué)家和企業(yè)家Jeremy Howard,與其他幾位教授共同組建了AI初創(chuàng)公司fast.ai,專注于深度學(xué)習(xí)加速。他們用128塊V100 GPU,在上述ImageNet數(shù)據(jù)集上訓(xùn)練ResNet-50模型,最短時間為18分鐘。
最近BigGAN、NASNet、BERT等模型的出現(xiàn),預(yù)示著訓(xùn)練更好精度的模型需要更強大的計算資源。可以預(yù)見,在未來隨著模型的增大、數(shù)據(jù)量的增加,深度學(xué)習(xí)訓(xùn)練加速將變得會更加重要。
只有擁有端到端全棧的優(yōu)化能力,才能使得深度學(xué)習(xí)的訓(xùn)練性能做到極致。
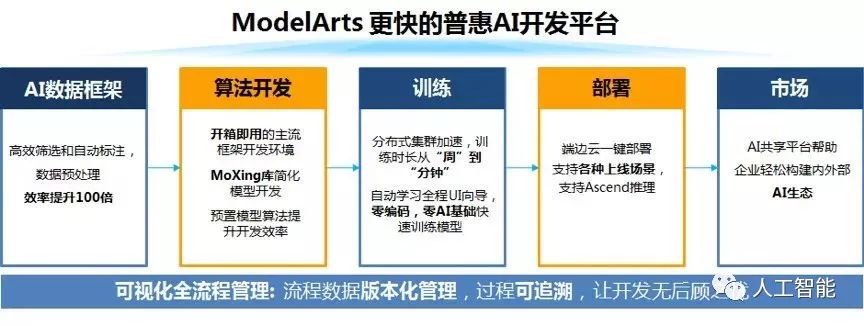
華為云ModelArts功能視圖
華為云ModelArts是一站式的AI開發(fā)平臺,已經(jīng)服務(wù)于華為公司內(nèi)部各大產(chǎn)品線的AI模型開發(fā),幾年下來已經(jīng)積累了跨場景、軟硬協(xié)同、端云一體等多方位的優(yōu)化經(jīng)驗。
ModelArts提供了自動學(xué)習(xí)、數(shù)據(jù)管理、開發(fā)管理、訓(xùn)練管理、模型管理、推理服務(wù)管理、市場等多個模塊化的服務(wù),使得不同層級的用戶都能夠很快地開發(fā)出自己的AI模型。
自研分布式通用加速框架MoXing,性能再加速
為什么ModelArts能在圖像識別的訓(xùn)練時間上取得如此優(yōu)異的成績?
答案是“MoXing”。
在模型訓(xùn)練部分,ModelArts通過硬件、軟件和算法協(xié)同優(yōu)化來實現(xiàn)訓(xùn)練加速。尤其在深度學(xué)習(xí)模型訓(xùn)練方面,華為將分布式加速層抽象出來,形成一套通用框架——MoXing(“模型”的拼音,意味著一切優(yōu)化都圍繞模型展開)。

采用與fast.ai一樣的硬件、模型和訓(xùn)練數(shù)據(jù),ModelArts可將訓(xùn)練時長可縮短到10分鐘,創(chuàng)造了新的紀(jì)錄,為用戶節(jié)省44%的時間
MoXing是華為云ModelArts團隊自研的分布式訓(xùn)練加速框架,它構(gòu)建于開源的深度學(xué)習(xí)引擎TensorFlow、MXNet、PyTorch、Keras之上,使得這些計算引擎分布式性能更高,同時易用性更好。
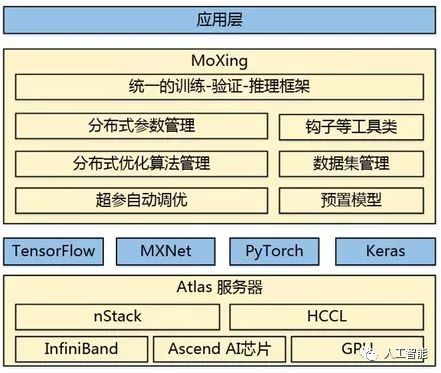
華為云MoXing架構(gòu)圖
MoXing內(nèi)置了多種模型參數(shù)切分和聚合策略、分布式SGD優(yōu)化算法、級聯(lián)式混合并行技術(shù)、超參數(shù)自動調(diào)優(yōu)算法,并且在分布式訓(xùn)練數(shù)據(jù)切分策略、數(shù)據(jù)讀取和預(yù)處理、分布式通信等多個方面做了優(yōu)化,結(jié)合華為云Atlas高性能服務(wù)器,實現(xiàn)了硬件、軟件和算法協(xié)同優(yōu)化的分布式深度學(xué)習(xí)加速。
有了MoXing后,上層開發(fā)者可以聚焦業(yè)務(wù)模型,無需關(guān)注下層分布式相關(guān)的API,只用根據(jù)實際業(yè)務(wù)定義輸入數(shù)據(jù)、模型以及相應(yīng)的優(yōu)化器即可,訓(xùn)練腳本與運行環(huán)境(單機或者分布式)無關(guān),上層業(yè)務(wù)代碼和分布式訓(xùn)練引擎可以做到完全解耦。
用數(shù)據(jù)說話:從吞吐量和收斂時間看加速性能
深度學(xué)習(xí)加速屬于一個從底層硬件到上層計算引擎、再到更上層的分布式訓(xùn)練框架及其優(yōu)化算法多方面協(xié)同優(yōu)化的結(jié)果,具備全棧優(yōu)化能力才能將用戶訓(xùn)練成本降到最低。
在模型訓(xùn)練這方面,華為云ModelArts內(nèi)置的MoXing框架使得深度學(xué)習(xí)模型訓(xùn)練速度有了很大的提升。
下圖是華為云團隊測試的模型收斂曲線(128塊V100 GPU,完成ResNet50-on-ImageNet)。一般在ImageNet數(shù)據(jù)集上訓(xùn)練ResNet-50模型,當(dāng)Top-5精度≥93%或者Top-1 精度≥75%時,即可認(rèn)為模型收斂。
ResNet50-on-ImageNet訓(xùn)練收斂曲線(曲線上的精度為訓(xùn)練集上的精度):(a)所對應(yīng)的模型在驗證集上Top-1 精度≥75%,訓(xùn)練耗時為10分06秒;(b) 所對應(yīng)的模型在驗證集上Top-5精度≥93%,訓(xùn)練耗時為10分28秒。
Top-1和Top-5精度為訓(xùn)練集上的精度,為了達(dá)到極致的訓(xùn)練速度,訓(xùn)練過程中采用了額外進(jìn)程對模型進(jìn)行驗證,最終驗證精度如下表所示(包含與fast.ai的對比)。
MoXing與fast.ai的訓(xùn)練結(jié)果對比
華為云團隊介紹,衡量分布式深度學(xué)習(xí)框架加速性能時,主要看吞吐量和收斂時間。在與吞吐量和收斂時間相關(guān)的幾個關(guān)鍵指標(biāo)上,團隊都做了精心處理:
在數(shù)據(jù)讀取和預(yù)處理方面,MoXing通過利用多級并發(fā)輸入流水線使得數(shù)據(jù)IO不會成為瓶頸;
在模型計算方面,MoXing對上層模型提供半精度和單精度組成的混合精度計算,通過自適應(yīng)的尺度縮放減小由于精度計算帶來的損失;
在超參調(diào)優(yōu)方面,采用動態(tài)超參策略(如momentum、batch size等)使得模型收斂所需epoch個數(shù)降到最低;
在底層優(yōu)化方面,MoXing與底層華為自研服務(wù)器和通信計算庫相結(jié)合,使得分布式加速進(jìn)一步提升
后續(xù),華為云ModelArts將進(jìn)一步整合軟硬一體化的優(yōu)勢,提供從芯片(Ascend)、服務(wù)器(Atlas Server)、計算通信庫(CANN)到深度學(xué)習(xí)引擎(MindSpore)和分布式優(yōu)化框架(MoXing)全棧優(yōu)化的深度學(xué)習(xí)訓(xùn)練平臺。
ModelArts會逐步集成更多的數(shù)據(jù)標(biāo)注工具,擴大應(yīng)用范圍,將繼續(xù)服務(wù)于智慧城市、智能制造、自動駕駛及其它新興業(yè)務(wù)場景,在公有云上為用戶提供更普惠的AI服務(wù)。
-
華為
+關(guān)注
關(guān)注
216文章
35024瀏覽量
255040 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122475
原文標(biāo)題:華為云刷新深度學(xué)習(xí)加速紀(jì)錄:128塊GPU,10分鐘訓(xùn)練完ImageNet
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
廣汽集團與阿里云、華為展開深度合作
拓維信息榮膺華為云生態(tài)大會2025「突出貢獻(xiàn)獎」,以“AI+鴻蒙”加速行業(yè)智能躍遷

潤和的Hi3861開發(fā)版如何連接華為云
潤和的Hi3861開發(fā)板如何連接華為云
軍事應(yīng)用中深度學(xué)習(xí)的挑戰(zhàn)與機遇
華為云 Flexus X 加速 Redis 案例實踐與詳解
使用 sysbench 對華為云 Flexus 服務(wù)器 X 做 Mysql 應(yīng)用加速測評
華為云 Flexus X 實例部署安裝 Jupyter Notebook,學(xué)習(xí) AI,機器學(xué)習(xí)算法
華為云Flexus X實例,Redis性能加速評測及對比
NPU在深度學(xué)習(xí)中的應(yīng)用
Pytorch深度學(xué)習(xí)訓(xùn)練的方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論