 微軟亞洲研究院視覺計算組又一個令人拍案叫絕的操作
微軟亞洲研究院視覺計算組又一個令人拍案叫絕的操作
微軟亞洲研究院視覺計算組又一個令人拍案叫絕的操作:可變形卷積網絡v2版!DCNv2方法簡單,結果更好,在COCO基準測試中比上個版本提升了5個點。
同樣的物體在圖像中可能呈現出不同的大小、姿態、視角變化甚至非剛體形變,如何適應這些復雜的幾何形變是物體識別的主要難點,也是計算機視覺領域多年來關注的核心問題。
去年,微軟亞洲研究院視覺計算組提出了 “Deformable Convolutional Networks”(可變形卷積網絡),首次在卷積神經網絡(CNN)中引入了學習空間幾何形變的能力,得到可變形卷積網絡(Deformable ConvNets),從而更好地解決了具有空間形變的圖像識別任務。
通俗地說,圖像中的物體形狀本來就是千奇百怪,方框型的卷積核,即使卷積多次反卷積回去仍然是方框,不能真實表達物體的形狀,如果卷積核的形狀是可以變化的,這樣卷積后反卷積回去就可以形成一個多邊形,更貼切的表達物體形狀,從而可以更好地進行圖像分割和物體檢測。
研究員們通過大量的實驗結果驗證了該方法在復雜的計算機視覺任務(如目標檢測和語義分割)上的有效性,首次表明在深度卷積神經網絡(deep CNN)中學習空間上密集的幾何形變是可行的。
但這個Deformable ConvNets也有缺陷,例如,激活單元的樣本傾向于集中在其所在對象的周圍。然而,對象的覆蓋是不精確的,顯示出超出感興趣區域的樣本的擴散。在使用更具挑戰性的COCO數據集進行分析時,研究人員發現這種傾向更加明顯。這些研究結果表明,學習可變形卷積還有更大的可能性。
昨天,MSRA視覺組發布可變形卷積網絡的升級版本:Deformable ConvNets v2 (DCNv2),論文標題也相當簡單粗暴:更加可變形,更好的結果!
論文地址:
https://arxiv.org/pdf/1811.11168.pdf
DCNv2具有更強的學習可變形卷積的建模能力,體現在兩種互補的形式:
第一種是網絡中可變形卷積層的擴展使用。配備具有offset學習能力的更多卷積層允許DCNv2在更廣泛的特征級別上控制采樣。
第二種是可變形卷積模塊中的調制機制,其中每個樣本不僅經過一個學習的offset,而且還被一個學習特征調制。因此,網絡模塊能夠改變其樣本的空間分布和相對影響。
為了充分利用DCNv2增強的建模能力,需要進行有效的訓練。受神經網絡的knowledge distillation這一工作的啟發,我們利用教師網絡來實現這一目的,教師在訓練期間提供指導。
具體來說,我們利用R-CNN作為教師網絡。由于它是訓練用于對裁剪圖像內容進行分類的網絡,因此R-CNN學習的特征不受感興趣區域之外無關信息的影響。為了模仿這個屬性,DCNv2在其訓練中加入了一個特征模擬損失,這有利于學習與R-CNN一致的特征。通過這種方式,DCNv2得到強大的訓練信號,用于增強可變形采樣。
通過這些改變,可變形模塊仍然是輕量級的,并且可以容易地結合到現有網絡架構中。
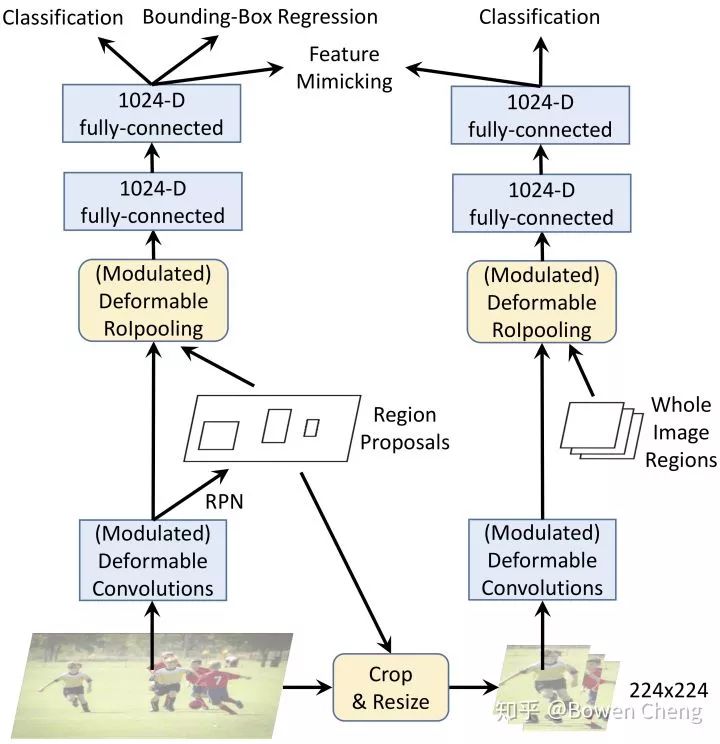
具體而言,我們將DCNv2合并到Faster R-CNN 和Mask R-CNN 系統,并具有各種backbone網絡。在COCO基準測試上的大量實驗證明了DCNv2相對于DCNv1在物體檢測和實例分割方面都有顯著改進。
我們將在不久后發布DCNv2的代碼。
圖1:常規ConvNet、DCNv1以及DCNv2中conv5 stage最后一層節點的空間支持。
圖3:利用R-CNN feature mimicking的訓練
結果
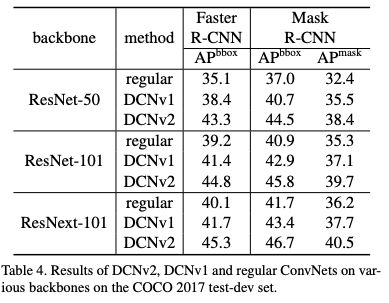
表4:COCO 2017 test-dev set 中各種backbones上的DCNv2、DCNv1和regular ConvNets的結果。
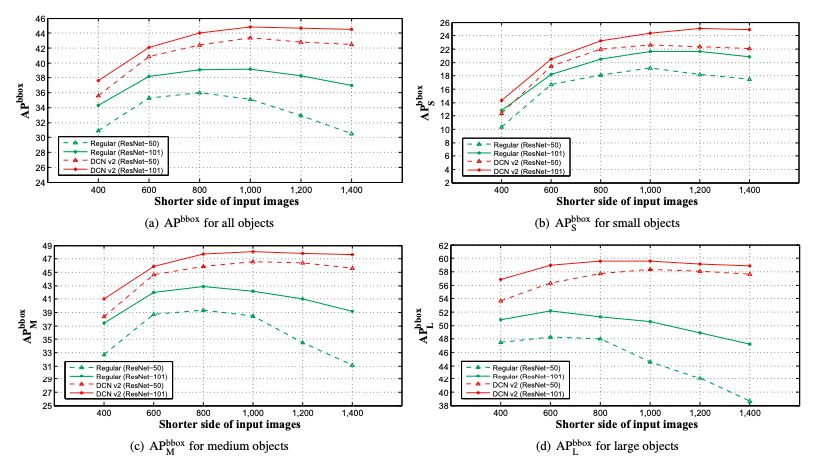
圖4:在COCO 2017 test-dev set不同分辨率的輸入圖像上,DCNv2和regular ConvNets(Faster R-CNN + ResNet-50 / ResNet-101)的APbbox分數。
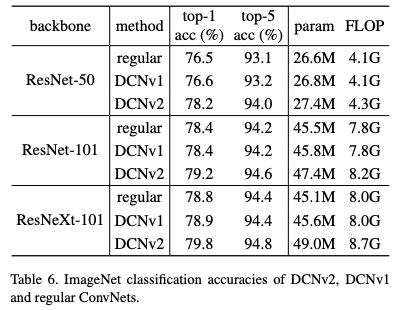
表6:DCNv2、DCNv1和regular ConvNets的ImageNet分類準確度。
可以看到,Deformable ConvNets v2的結果相當亮眼!下面,我們精選了兩篇業內對這篇論文的評價,經授權發布:
業界良心DCNV2:方法簡單,結果好,分析充分
知乎用戶Bowen Cheng的評價:
一周前就聽說 Jifeng 組做出了Deformable ConvNet V2(DCNV2),今天 Jifeng 告訴我 paper 已經掛 ArXiv 上之后果斷放下所有事把這篇 paper 好好讀了讀。感覺這個工作特別 solid,果然沒有讓人失望。下面簡單談談個人對這篇 paper 的理解,可能有不對的地方請大家多多指點!
DCNV2 首先用了更好的 visualization 來更深入的理解 DCNV1 為什么 work 以及還存在什么缺陷,發現存在的問題就是因為 offset 不可控導致引入了過多的 context,而這些 context 可能是有害的([1]和 [2] 中也說明了這些 context 可能是有害的)。
解決方法也很簡單粗暴:
(1) 增加更多的 Deformable Convolution
(2)讓 Deformable Conv 不僅能學習 offset,還能學習每個采樣點的權重(modulation)
(3)模擬 R-CNN 的 feature(knowledge distillation)
(1) 就不用說了,在 DCNV1 中只有 ResNet 的 Conv5 stage 中有 Deformable Conv,在 DCNV2 中把 Conv3-Conv5 的 3x3 convolution 都換成了 Deformable Conv
(2) 在 DCNV1 里,Deformable Conv 只學習 offset:
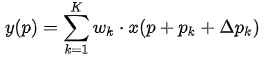
而在 DCNV2 中,加入了對每個采樣點的權重:
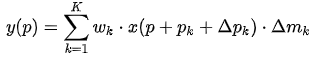
其中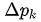 是學到的 offset,
是學到的 offset,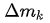 是學到的權重。這樣的好處是增加了更大的自由度,對于某些不想要的采樣點權重可以學成 0。
是學到的權重。這樣的好處是增加了更大的自由度,對于某些不想要的采樣點權重可以學成 0。
(3) [1] 中作者(好吧,其實作者是我)發現把 R-CNN 和 Faster RCNN 的 classification score 結合起來可以提升 performance,說明 R-CNN 學到的 focus 在物體上的 feature 可以解決 redundant context 的問題。但是增加額外的 R-CNN 會使 inference 速度變慢很多。DCNV2 里的解決方法是把 R-CNN 當做 teacher network,讓 DCNV2 的 ROIPooling 之后的 feature 去模擬 R-CNN 的 feature。(圖里畫的很清楚了)
其中 feature mimic 的 loss 定義是:
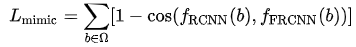
在 end-to-end train 的時候這個 loss 給了一個 0.1 的 weight。
實驗結果大家看 paper 就好了,在 ResNet-50 backbone COCO 上跟 DCNV1 比漲了 5 個點!這比目前大部分 detection paper 靠東拼西湊漲的那一兩個點要強多了。我驚訝的是和 DCNV1 對比,在 image classification 上也有很大的提升。
說說自己的想法吧,DCNV2 方法簡單,結果好,分析充分,我覺得和近期各種 detection paper 比算是業界良心了。我覺得還有可以學習的一點就是 context 的問題。很多 detection 的 paper 都在引入 context(大家都 claim 說小物體需要引入 context 來解決),其實我個人覺得有點在扯淡,物體小最直接的方法難道不是放大物體來解決嗎?比如 SNIP/SNIPER 都是在 “放大” 物體。所以在 context 這個問題上我(詳情見 [1] 和[2])跟 Jifeng 他們的看法是一樣的,我們也許不需要那么多沒用的 context。作者都是熟人,我也不多吹了,反正我是準備去 follow 這個工作了哈哈。
最后說說 DCN 有一個小缺點,其實就是速度的問題。因為沒有 cudnn 的加速,DCN 完全是靠 im2col 實現的(從目前的 MXNet 版本來看是這樣的),當 batchsize 大的時候我感覺速度會比有 cudnn 加速的 3x3 conv 慢。很好奇當 batchsize 大的時候(比如 ImageNet)的 training 時間會慢多少。希望以后能和 dilated convolution 一樣被加到 cudnn 里支持吧。
發現好多人好像沒有看過 [1][2],放張 network 的圖(宣傳一下自己的工作),DCN V2 的 mimic R-CNN 和 DCR V1 的結構類似,但是通過 knowledge distillation 很巧妙的在 inference 階段把 R-CNN 給去掉了。
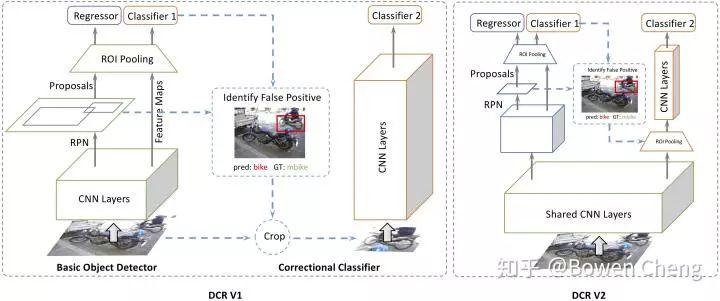
[1] Revisiting RCNN: On Awakening the Classification Power of Faster RCNN
[2] Decoupled Classification Refinement: Hard False Positive Suppression for Object Detection
創新性與性能雙贏,COCO漲了5個點!
知乎用戶孔濤的評價:
首先祭出結論,這是一篇干貨滿滿,novelty 和 performance 雙贏的 paper(COCO 直接漲了~ 5 個點啊)。
自己一直在做 object detection 相關的工作,再加上之前在 MSRA 跟 Jifeng 及 CV 組的小伙伴共事過一段時間,努力給出客觀的評價吧。
從 Deform ConvNet V1 說起
目標檢測中有一個比較棘手的問題,即所謂的幾何形變問題(Geometric variations)。就拿人檢測來講,人的姿態有多種多樣(想想跳舞的場景),這就需要我們設計的模型具備 deformation 的能力。通常情況下為了解決這類問題有兩種思路:(a) 收集更多樣的數據用于模型的訓練;(b) 設計 transformation invariant 的特征來提升模型多樣化能力。
Deform ConvNet 是在卷積神經網絡的框架下,對 transformation-invariant feature 的比較成功的嘗試。思想非常直觀,在標準的卷積核上加入了可學習的 offset,使得原來方方正正的卷積核具備了形變的能力。
deformable convolution
用過的童鞋其實都知道,在大型的 object detection/instance segmentation 任務上的表現還蠻搶眼的。
Deform ConvNet V2 在干啥
我認為,Deform ConvNet 是在解決如何讓學到的 offset 能更聚焦到感興趣的物體上邊,也就是提取到更聚焦的 feature 來幫助物體的識別定位。在下邊的圖片中,我們當然希望模型的 feature 能夠聚焦到物體上邊,這樣才能提取到更有意義的 supporting feature。
為了做到這一點,作者主要用了幾種策略:
(a) 增加更多的 offset 層,這個不必細說;
(b) 在 deform convolution 中引入調節項 (modulation),這樣既學到了 offset,又有了每個位置的重要性信息;
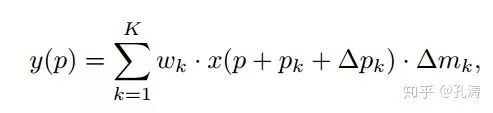
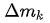
(c) Feature Mimicking,作者強調,簡單在對應的 feature 上用 roi-pooling 來提取對應位置的 feature 并不一定能提取到最有用的信息(可能包含無用的 context)。如何才能讓 feature 更加聚焦到物體上呢?解決就是 Mimicking 技術,讓 roi-pooling 之后的 feature 更像直接用 R-CNN 學到的 feature。
其他
除了漂亮的結果,我覺得 paper 的可視化分析部分也挺值得好好看看的。
另外很難理解為什么 Feature Mimicking 在 regular Faster R-CNN 上不 work。
從最近的一些 paper 結果看,至少目前在 deep 的框架下,針對 task,讓模型提取更加有意義的 feature 是個比較熱 / 好的方向吧。
-
微軟
+關注
關注
4文章
6671瀏覽量
105366 -
神經網絡
+關注
關注
42文章
4807瀏覽量
102756 -
計算機視覺
+關注
關注
9文章
1706瀏覽量
46568
原文標題:MSRA視覺組可變形卷積網絡升級!更高性能,更強建模能力
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
國家管網集團研究院選購我司HS-TH-3500炭黑含量測試儀

鯤云科技與中國工業互聯網研究院成立AI+安全生產聯合實驗室
加速科技榮獲“浙江省企業研究院”認定

浪潮信息與智源研究院攜手共建大模型多元算力生態
安謀科技與智源研究院達成戰略合作,共建開源AI“芯”生態

清新電源研究院榮獲深圳市5A級社會組織

天馬與武進南大未來技術創新研究院達成戰略合作
陳天橋雒芊芊腦科學研究院在人工智能領域取得重大突破
藍思科技將新增昆山創新研究院,重點服務蘋果
廣東省智能科學與技術研究院選購我司一批熱分析儀設備

摩爾線程攜手智源研究院完成基于Triton的大模型算子庫適配
香港城市大學與富士康鴻海研究院成立聯合研究中心






 工商網監
工商網監
評論