") 研究人員們提出了一種新的導航工具SafeRoute
研究人員們提出了一種新的導航工具SafeRoute
最近的研究表明,85%的女性會在外出時特意避開危險區(qū)域,選擇相對安全的道路,防止受到騷擾或傷害。盡管如此,現(xiàn)有的導航工具并不能給用戶提供安全性指數(shù)。在這篇論文中,研究人員們提出了一種新的導航工具SafeRoute,它借助深度強化學習工具,能顯示城市街道中潛在的犯罪概率。以下是論智對論文的介紹:
康奈爾大學和Hollaback公司2014年調查了美國4872名女性,其中85%的人會為了避免潛在的危險而選擇繞路,67%的調查對象會改變出行時間確保安全。或許當?shù)厝藭煜に麄兊木幼…h(huán)境,知道哪里危險、哪里相對安全。可是對第一次來某地的人來說,環(huán)境的陌生會大大增加危險發(fā)生的概率。隨著犯罪率的上升,我們在想,是否能創(chuàng)建一款安全道路導航應用,讓更多人能保護自己呢?
在這篇論文中,我們的研究對象僅限于非機動車道(例如可以走路或騎自行車的區(qū)域)。在美國,想紐約、波士頓、舊金山這樣的城市,通常有很多步行街道。我們想計算出到達目的地的最短距離,并且危險系數(shù)低的步行方案。現(xiàn)有的導航方法也能覆蓋大城市,但他們沒有考慮犯罪率的問題,忽略了小范圍的犯罪區(qū)域。
另外,最接近也有很多有關深度強化學習進行最短路徑導航的成果出現(xiàn),但我們的模型不僅僅是為了規(guī)劃路徑,而是要加入安全因素。于是我們選擇了基于深度強化學習的解決方案,這在很多數(shù)據(jù)挖掘問題中都是常用方法。
SafeRoute介紹
我們可以將路徑選擇的過程看作是馬爾科夫決策過程,在每個步驟,智能體都要決定下一步的方向,最終到達目的地。首先會向模型輸入開始和結束點的坐標,模型會返回智能體做出的決策坐標列表,同時對智能體進行獎勵,避免道路上遇到犯罪事件。
模型架構
SafeRoute系統(tǒng)主要有兩大部分:強化學習智能體可以交互的環(huán)境,以及智能體進行表示并做決定的策略網絡。主要架構如下圖:
環(huán)境是用具有< S, A, P, R >元組的馬爾科夫決策過程表示。S表示環(huán)境持續(xù)的狀態(tài),A={a1,a2,…,aN},定義了智能體可能做出的所有動作。P(St+1= s0|St= s,At= a)表示從一個狀態(tài)轉移到另一個狀態(tài)的概率。R(s, a)是智能體在狀態(tài)s下做出動作a時的獎勵函數(shù)。
在我們的模型中,智能體的狀態(tài)表示目前在地圖上的位置以及目標位置。如果目標位置和此前訓練時的目標位置很接近,那么智能體會采取相似行動靠近該目標。為了表示狀態(tài),地圖信息被轉換成有節(jié)點和線條的圖,其中圖嵌入用來表示強化學習智能體的連續(xù)狀態(tài),這些嵌入用node2vec來生成。用圖嵌入而不用坐標的原因是,坐標不能體現(xiàn)地圖上的交互是如何連接的任何信息。狀態(tài)從智能體目前的節(jié)點和目標節(jié)點中使用的嵌入如下所示:
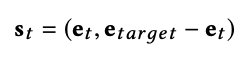
其中et表示當前節(jié)點的嵌入,etarget表示目標節(jié)點的嵌入。
另外,策略網絡表示強化學習智能體使用的隨機策略,用πθ(s, a) = p(a|s;θ)表示,其中θ是神經網絡的參數(shù)列表,會用Adam優(yōu)化器進行更新。系統(tǒng)使用隨機梯度而不是貪婪策略,是為了防止智能體在地圖上循環(huán)前進,停滯不前。運用隨機梯度,智能體可以打破循環(huán)(例如向死路前進或選擇可能會通向死路的道路)。神經網絡包含兩個隱藏層,每一層都有一個ReLU激活函數(shù)。輸出使用一個softmax函數(shù),可以返回所有行為的概率分布。
至于獎勵,智能體要考慮多方面優(yōu)化,所以獎勵函數(shù)也必須包含多種因素。由于SafeRoute的一個重要特征就是躲避犯罪區(qū)域,所以我們將安全性添加到獎勵中,用函數(shù)表示坐標到此前有過犯罪記錄坐標的平均距離。
雖然SafeRoute的主要目標是增加安全性,但是我們還想盡量選擇較短路線。路徑沿線距離犯罪現(xiàn)場的所有平均距離都要計算,如果附近沒有發(fā)生過犯罪事件,那么就得到獎勵k。最終的獎勵函數(shù)定義如下:

其中n是路徑中線條的數(shù)量,m是每個節(jié)點一定半徑內的犯罪事件數(shù)量,x是路線中線段的中點,c是每個半徑上發(fā)生的犯罪事件,p是路線,k是超參數(shù)。
訓練
訓練SafeRoute也分為兩部分:監(jiān)督訓練和用獎勵進行重復訓練。在最初不使用監(jiān)督訓練的情況下,智能體在找尋目標節(jié)點時很困難,最終可能會隨意尋找方向。AlphaGo在訓練時用了模擬學習的方法,讓智能體在最初能夠找到正確方法。同樣,我們也在訓練開始時用監(jiān)督學習進行模擬學習。經過監(jiān)督學習之后,智能體還會再次訓練,避開犯罪率高的區(qū)域。再次訓練的算法過程如下:

實驗過程
由于此前沒有類似的實驗,所以我們創(chuàng)建了自己的SafeRoute數(shù)據(jù)集。我們從OpenStreetMap中收集了地圖信息,這是一個免費的協(xié)作世界地圖,我們選擇了波士頓、紐約和舊金山的市區(qū),這是很多游客會去的地方,也是繁華的市中心。最終,波士頓和舊金山的圖在訓練時每個epoch會歐2000個episode,而紐約的更大,可以達到4000個episode。三個模型都經過了60epoch的訓練。
犯罪數(shù)據(jù)從Spotcrime中收集,其中包括了最近有關犯罪的類型和地理坐標。我們只選擇了槍擊、騷擾和搶劫三類。
另外,我們在多種尺度上對SafeRoute進行了評估,路線的質量有三個方面:距離犯罪點的平均距離(包括局部和全局兩種)以及路線長短。局部犯罪平均距離只考慮當智能體走在路上時,附近的犯罪活動。而全局的平均距離會考慮該路線上所有發(fā)生過的犯罪活動。其中局部平均距離是重點考量因素。
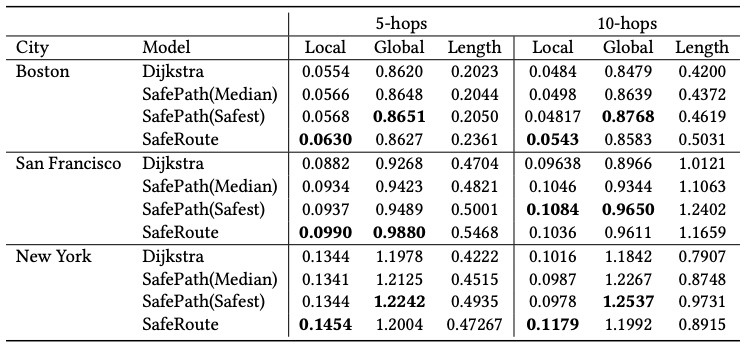
可以看到,在我們的評估前兩個因素的值越高并且路線距離越短的選擇更好。并且在波士頓遵循了離犯罪地點距離最短的原則,但是紐約的案例中,離犯罪地點遠的路線卻很長。
為了減少我們模型結果的多樣性,我們?yōu)槊總€城市創(chuàng)建了三種模型,并對結果進行了平均。下表表現(xiàn)了SafeRoute和SafePath最安全的路線相比,增加或減少的百分比。
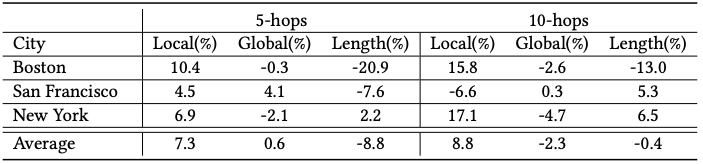
經過測試,SafeRoute能在大多情況下生成合適的結果,未來,我們打算讓SafeRoute作用于更長路徑和更大的地圖。除此之外,我們還會研究模型的可攜帶型。
-
神經網絡
+關注
關注
42文章
4806瀏覽量
102680 -
智能體
+關注
關注
1文章
259瀏覽量
10942 -
強化學習
+關注
關注
4文章
269瀏覽量
11512
原文標題:強化學習加持,這個導航不僅能計算路線,還能遠離危險犯罪
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
美國普渡大學和哈佛大學的研究人員推出了一項新發(fā)明 新...
研究人員提出了一種柔性可拉伸擴展的多功能集成傳感器陣列
以色列研究人員開發(fā)出了一種能夠識別不同刺激的新型傳感系統(tǒng)
哈佛大學研究人員提出一種用寡肽分子存儲信息的新方法
研究人員們提出了一系列新的點云處理模塊

JD和OPPO的研究人員們提出了一種姿勢引導的時尚圖像生成模型
Facebook的研究人員提出了Mesh R-CNN模型

瑞士研究人員研發(fā)出了一種可以躲閃障礙物的無人機
研究人員推出了一種新的基于深度學習的策略
中美研究人員合作開發(fā)出了一種可以預測新冠肺炎病情的AI工具
研究人員開發(fā)出了一種稱為LB-WayPtNav-DH的機器人導航新框架
麥克斯·德爾布呂克分子醫(yī)學中心的研究人員開發(fā)了一種新工具
微軟亞洲研究院的研究員們提出了一種模型壓縮的新思路
MIT研究人員提出了一種制造軟氣動執(zhí)行器的新方法





 工商網監(jiān)
工商網監(jiān)
評論