 用于無人車交通環境感知的視覺主導的多傳感器融合計算框架
用于無人車交通環境感知的視覺主導的多傳感器融合計算框架

人類駕駛與自主駕駛在對交通環境的理解方式上有著明顯差別。首先,人主要通過視覺來理解交通場景,而機器感知需要融合多種異構的傳感信息才能保證行車安全。其次,一個熟練的駕駛員可以輕松適應各種動態交通環境,但現有的機器感知系統卻會經常輸出有噪聲的感知結果,而自主駕駛要求感知結果近乎100%準確。
本文提出了一種用于無人車交通環境感知的視覺主導的多傳感器融合計算框架,通過幾何和語義約束融合來自相機、激光雷達(LIDAR)及地理信息系統(GIS)的信息,為無人車提供高精度的自主定位和準確魯棒的障礙物感知,并進一步討論了已成功集成到上述框架內的魯棒的視覺算法,主要包括從訓練數據收集、傳感器數據處理、低級特征提取到障礙物識別和環境地圖創建等多個層次的視覺算法。所提出的框架里已用于自主研發的無人車,并在各種真實城區環境中進行了長達八年的實地測試,實驗結果驗證了視覺主導的多傳感融合感知框架的魯棒性和高效性。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
傳感器
+關注
關注
2565文章
52982瀏覽量
767252 -
無人車
+關注
關注
1文章
310瀏覽量
36916
原文標題:無人車自主定位和障礙物感知的視覺主導多傳感器融合方法
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
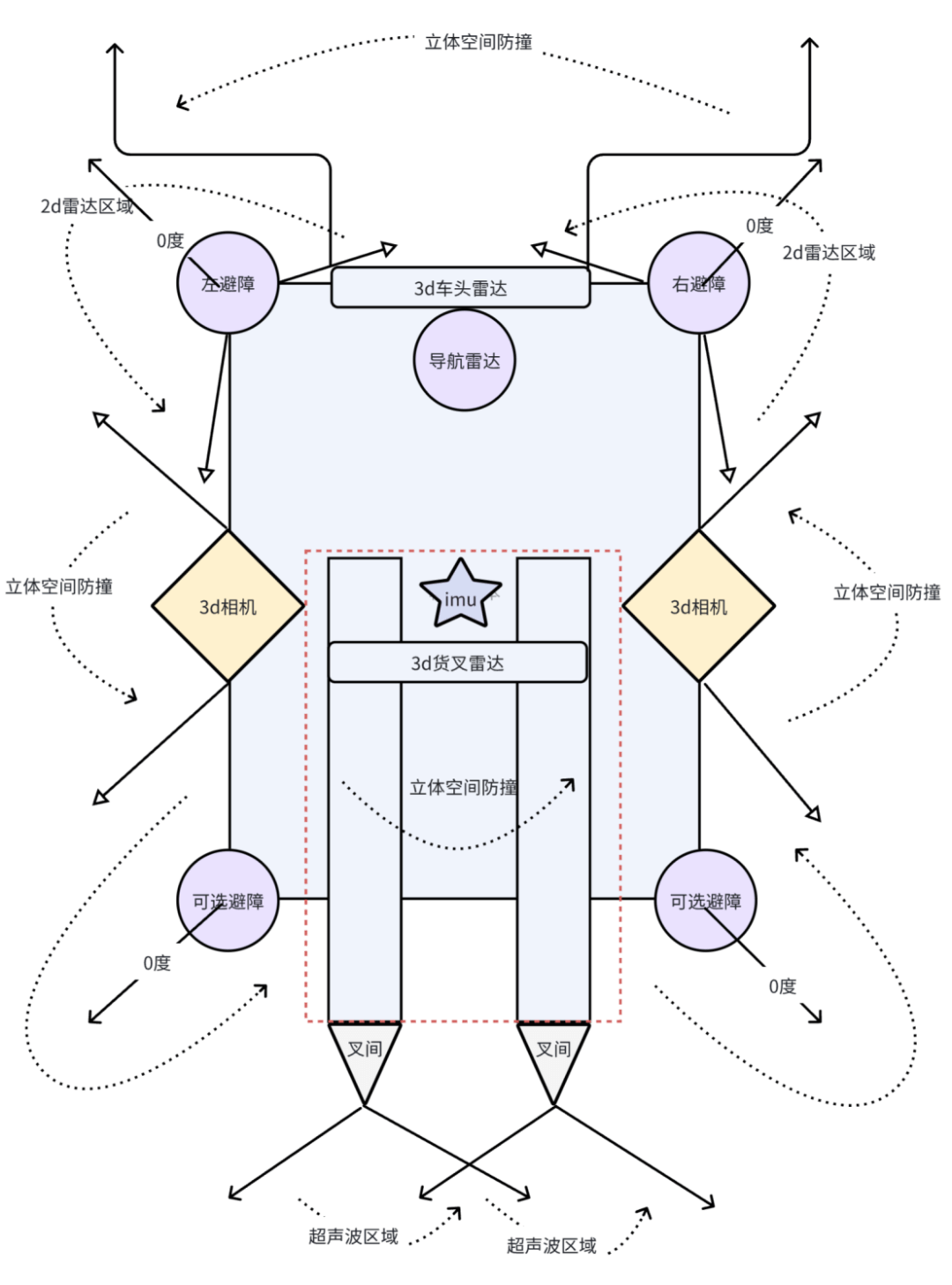
AGV機器人如何實現毫秒級避障?深度解析多傳感器融合的核心技術
整合,彌補單一傳感器的局限,最終構建出對環境的一致性感知。該技術既能融合多源數據的互補優勢(如精準測距與物體識別),又能通過智能算法優化信息
【「# ROS 2智能機器人開發實踐」閱讀體驗】視覺實現的基礎算法的應用
的有效途徑。
結語
本書第7章和第8章內容系統性強,從基礎理論到代碼實踐,為讀者提供了機器人視覺與SLAM的完整知識框架。未來,我計劃結合書中案例,進一步探索多傳感器
發表于 05-03 19:41
仿生傳感器:讓機器擁有“生命感知”的神奇科技
在科幻電影中,機器人通過皮膚感知溫度、用“鼻子”識別氣味、用“耳朵”捕捉聲音的場景曾令人驚嘆。如今,這些“超能力”正通過仿生傳感器逐漸走進現實。仿生傳感器,這一融合生物學與工程學的創新
融合視覺傳感器廠商銳思智芯完成B輪融資
近日,融合視覺傳感器研發商銳思智芯(AlpsenTek)宣布完成B輪融資,本輪投資方包括智慧互聯產業基金、浦耀信曄、中車時代投資、智宸投資、毅嶺資本等多家機構。 「銳思智芯」是一家新型
從安防到元宇宙:RK3588如何重塑視覺感知邊界?
示例:
多模態AI融合:支持TensorFlow、PyTorch等主流框架模型部署,可應用于智能零售中的行為識別系統,通過攝像頭+紅外傳感器
發表于 04-07 16:11
康謀應用 | 基于多傳感器融合的海洋數據采集系統
在海洋監測與無人艇控制領域,數據采集面臨數據噪聲誤差、融合協同等挑戰。本文康謀深度剖析基于多傳感器融合的海洋數據采集系統交付案例,詳細解析其

國內首顆車規級數字環境光傳感器
隨著汽車智能化加速演進,傳感器技術正向集成化、微型化、低功耗方向迭代。矽力杰率先推出國內首顆車規級數字環境光傳感器SA88137AS22-J00,該器件憑借小封裝、超高靈敏度及低功耗,


BEVFusion —面向自動駕駛的多任務多傳感器高效融合框架技術詳解
和高效融合機制,解決了多模態傳感器在幾何與語義任務中的權衡問題,成為自動駕駛多任務感知的標桿框架其設計范式為后續研究提供了重要啟發 ?**“


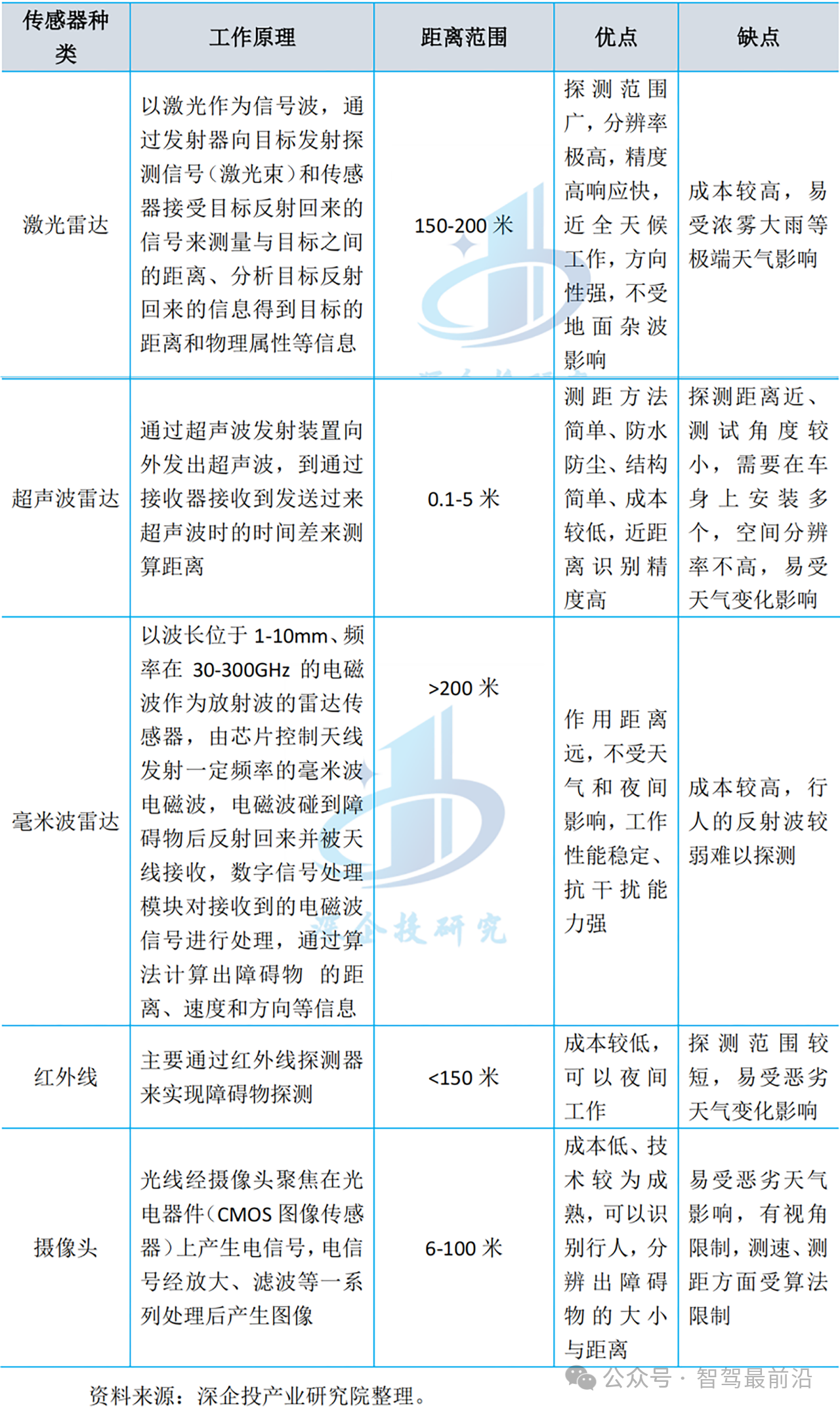
多傳感器融合在自動駕駛中的應用趨勢探究
自動駕駛技術的快速發展加速交通行業變革,為實現車輛自動駕駛,需要車輛對復雜動態環境做出準確、高效的響應,而多傳感器融合技術為提升自動駕駛系統
精密制造的革新:光譜共焦傳感器與工業視覺相機的融合
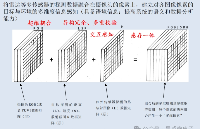
在現代精密制造領域,對微小尺寸、高精度產品的檢測需求日益迫切。光譜共焦傳感器憑借其非接觸、高精度測量特性脫穎而出,而工業視覺相機則以其高分辨率、實時成像能力著稱。兩者的融合,不僅解決了傳統檢測方式在

人形機器人感知系統的特點:多模態感知、高精度、實時性
電子發燒友網報道(文/李彎彎)感知系統是人形機器人實現智能交互和自主行動的關鍵組成部分。該系統通常包括多種傳感器和算法,用于收集、處理和分析來自外部環境的信息。不同企業所采用的





 工商網監
工商網監
評論