 融合計算是如何提出來的
融合計算是如何提出來的
融合計算是微觀和宏觀視角算力提升策略的總結,是三個維度融合(異構融合x軟硬件融合x云邊端融合)的統稱,那么融合計算是如何提出來的?為什么融合計算有且僅有三個維度的融合?
性能和算力
1.1 性能的計算公式

定性的分析,一個芯片的性能由三個維度組成:
維度一,指令復雜度。理論上,指令復雜度越高,性能越好。但實際上,需要考慮系統的通用性,以及目標工作任務的靈活性特征,來選擇合適的處理器引擎。
維度二,運行頻率。運行頻率提升,主要是先進工藝,以及更復雜的流水線設計。
維度三,并行度。提高并行度比較好理解,并行也主要有同構并行、(兩個處理器的)異構并行和(三個以上)更多異構融合的并行。
1.2 算力的計算公式
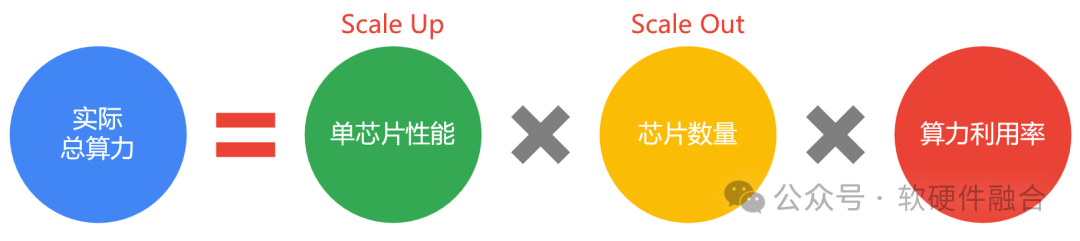
算力和性能的區別在哪里?性能是微觀的算力,算力是宏觀的性能。那么算力和性能之間的聯系是什么? 如上圖所示,我們定性分析,可以在性能和算力之間構建一個關聯的公式。從上述公式可以看到,宏觀的總算力,由三個維度的參數組成:
維度一,單芯片性能。通過提升單芯片性能的方式,也就是Scale Up的方式提升整體算力。
維度二,芯片的數量。通過增加計算芯片(計算節點)的數量,也就是Scale Out的方式,通過提升規模來提升整體算力。
維度三,算力利用率。如果僅有標稱算力,而無法達到很好的利用率,那也是徒勞。隨著AI的發展,集群規模越來越擴大,算力利用率越來越成為評價一個算力系統能力的關鍵指標。
從微觀到宏觀
2.1 微觀視角的算力提升
2.1.1 如何提升單芯片性能 融合提升單芯片的性能:
一方面是底層采用更先進的工藝,以及通過Chiplet封裝支撐,從而實現更大的計算規模;
另一方面,則是系統架構和微架構方面的創新,來實現單芯片層次更高的性能,這也是算力提升最本質的做法。
計算架構的創新則最主要的就是:
從第一代基于CPU的同構通用計算;
以及第二代基于CPU+GPU的異構通用計算;
逐步的走向第三代基于CPUxGPUxDSAs的異構融合通用計算。
2.1.2 如何提升芯片的數量和落地規模 芯片的落地,不是簡單的復制。國產算力芯片已經有好多家了,甚至一些公司的芯片都已經有三到四代了,但仍然銷售不是很順利。底層的原因在于:
生態的問題。國產芯片(相比NVIDIA CUDA)生態不夠好。但生態問題如何解決,不在于微觀的一家公司的一個架構和相應的私有生態如何構建和繁榮,而在于宏觀的很多公司很多架構如何整合(將在加下來的宏觀視角部分介紹)。
芯片需要足夠多的通用性,需要能夠覆蓋更多的業務場景和更多的業務迭代。
此外,芯片需要有非常高的I/O能力,確保在更大的規模下仍能有非常高的東西向通信效率(不耽誤計算,不影響計算效率),能夠支持更大規模的集群計算。
2.1.3 如何提升芯片的算力利用率 要想提升算力芯片的利用率,那么:
一方面,芯片需要有很好的擴展性能力,支持資源切分、池化、和重組;
另一方面,開放架構,減少多元異構算力的架構數量,從而使得更多的算力能夠匯集到統一的算力資源池,從而實現更大范圍的算力共享,進而提升整體的算力利用率。
2.2 宏觀視角的算力提升
2.2.1 如何提升單個節點的性能 從宏觀角度,單節點的性能提升,則主要是如何把更多異構融合架構的計算能力充分的用起來:
首先,是需要一個更加綜合的異構融合計算框架,既包括CPU的工具鏈,也有GPU、AI,以及其他如網絡、存儲、視頻、安全等領域的加速計算框架,還需要這個異構融合計算框架,支持異構協同和跨異構應用遷移。
第二,則是更復雜的計算架構和算力調度。在通算時代,一個物理的計算機,通常具有四類資源:CPU、內存、網絡和存儲;在異構計算時代,則是CPU、內存、網絡、存儲和加速器。而在異構融合時代,則是CPU、內存、網絡、存儲,以及更多種不同領域的加速器。那么,如此復雜的計算架構模型,如何資源切分、池化和重組,以及如何同架構調度,以及實現跨架構調度,都是需要深入考慮的事情。
2.2.2 如何提升芯片的數量和落地的規模 宏觀視角下,芯片的數量提升,主要是如下幾個層次:
最基礎的就是集群規模的擴大,這需要高性能網絡,更高的帶寬,更低的延遲。
接下來,就是跨集群管理和跨集群調度,這就需要更復雜的網絡和更高層次的算力調度。
再接下來,就是要實現跨數據中心的算力整合,這也就是目前火熱的算力網絡關注的范疇,有非常大的技術挑戰和商業上的挑戰。
再接下倆,那就是要跨云邊端,實現云邊端融合計算,挑戰會更大。
2.2.3 如何提升算力利用率 宏觀視角看算力利用率提升,主要是兩塊,承上啟下:
啟下。承載計算的芯片類型越來越多,多元異構問題凸顯,這是目前算力整合不得不面對的現實困難。芯片(或引擎)的類型有很多,每一張類型還有很多不同的架構,這些不同類型不同架構的芯片是一個個孤島,如何把這些孤島連成一體,是一個非常重要的事情。未來,開放計算架構會是一個不得不走的選項,逐漸的從目前各家芯片公司各自為政私有架構的模式,過渡到開放架構的模式,讓芯片的架構逐漸收斂。
承上。相比芯片側的問題,計算芯片所支撐的上層業務軟件側的問題相對較少。行業存在開源軟件生態,這是目前絕大部分業務客戶的共識,這也減少了很多底層硬件的適配難度。但這幾年,這個問題有所惡化:隨著AI發展,NVIDIA GPU和CUDA一家獨大,大家不得不在NVIDIA的封閉體系下工作。這不利于行業的競爭,也不利于算力成本的下降。理想的情況是:行業形成開源開放的計算軟硬件生態,開源軟件定義開放硬件;算力中心,不對任何硬件平臺有依賴,不需要為生態溢價付費,僅需要為功能和性能付費即可。
需要注意的是,宏觀和微觀,以及算力提升的三個維度,是彼此交叉關聯的。這里的很多策略,可能會同時影響兩個甚至三個維度,甚至“按下葫蘆浮起瓢”也是有可能的。實際的算力優化工作,需要仔細分析應對。
融合計算
隨著AI大模型以及AI+場景對算力的需求猛增,算力中心建設成本也水漲船高,算力網絡(實現算力共享)逐漸流行。同時許多AI+終端的場景,算力需求猛增,從云端和邊緣端“借”算力的云邊端融合計算模式,成為了終端算力提升的一個重要方式。 算力系統相當復雜,算力提升成為了一個龐大的系統工程。立足于最核心的芯片硬件和相關軟件,從微觀到宏觀,基于上面分析的算力提升的背景知識,提出了“融合計算”的概念。希望通過“融合計算”的全方位的整合優化,來實現算力最優的性能和成本。
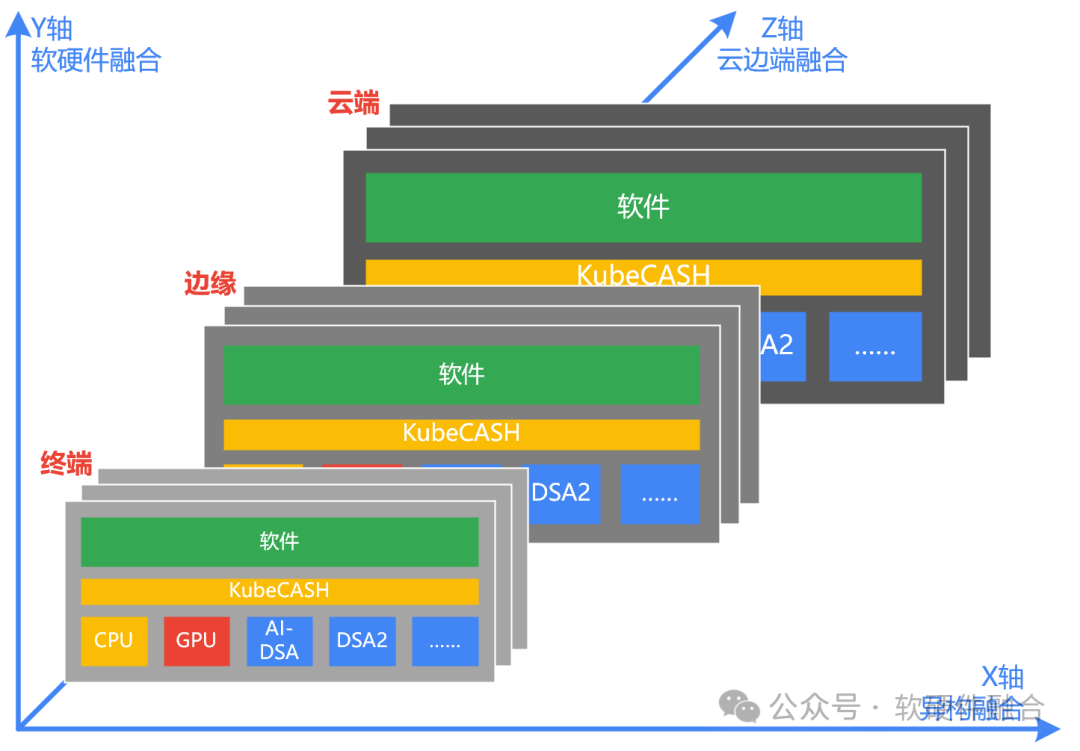
融合計算,其實就是微觀和宏觀視角算力提升策略的總結,是三個維度融合(異構融合x軟硬件融合x云邊端融合)的統稱:
X軸,芯片維度,異構融合,Scale Up,提升單芯片性能。通過異構融合計算,把各類異構算力的價值發揮到極致。
Y軸,計算堆棧維度,軟硬件融合,提升算力利用率。通過核心的算力調度系統中間件,實現承上啟下,向上對接開源軟件,向下對接多元異構算力,實現多元異構算力的協同和融合,從而最大化算力資源的利用率。
Z軸,集群擴展維度,云邊端融合,Scale Out,提升芯片數量。通過增加集群規模,同時實現跨算力中心、跨不同云運營商、跨云邊端融合的計算。
融合計算和多算融合的關系
融合計算,是從宏觀和微觀的角度,實現更底層更本質的提升性能和降低成本。而通算、智算和超算,則要更上層一些,是計算面向不同業務要求所做的定向性能和成本的調整。
隨著智算中心的發展,目前行業中出現了通算,智算和超算的融合的發展趨勢。但實際的做法,有待商榷。把CPU通算集群、GPU智算集群,以及存儲集群,以及超算集群,放置到一個算力中心里,就是多算融合嗎?顯然不是。

多算融合,必然是需要一套體系,能夠統一通算、智算和超算,有統一的資源切分重組,有統一的資源池,有統一的算力調度,有統一的上層算力服務,才能稱之為多算融合:
首先,是要構建統一的計算機模型。通算一般是CPU+標準網卡,而智算是CPU+GPU+高性能網卡,而超算則是CPU+GPU+高性能網卡+內存一致性加速,存儲則是CPU+更多的存儲I/O。不管咋樣,可以通過我們前面講到的計算模型來統一,不管是哪種計算,都是CPU+加速卡+內存+網絡+存儲的統一的計算模型。
然后是資源的池化。通過云計算的虛擬化和容器的機制,實現資源的切分、池化和重組,可以組合出符合要求的不同類型的計算實例。
目前,計算集群已經成為主流的計算方式。通過VPC,可以在公共算力服務的多租戶場景為用戶構建專屬的通算的、智算的或超算的計算集群。
融合計算,是更底層更本地算力優化問題,它存在于軟硬件協同層次,通過全方位的各種融合,實現算力的最佳效果:同算力條件下,成本更優;同成本下,算力更高。
融合計算,是云計算未來發展最大的創新方向,通過融合計算,夯實算力底座,支撐云計算繼續往前發展。再以云計算為基,構建出面向通算、智算和超算等不同場景的算力服務。
-
芯片
+關注
關注
459文章
52145瀏覽量
435734 -
計算
+關注
關注
2文章
453瀏覽量
39199 -
算力
+關注
關注
2文章
1141瀏覽量
15433
原文標題:融合計算的概念是如何提出來的?
文章出處:【微信號:bdtdsj,微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
突破智能駕艙邊界,Imagination如何構建高安全GPU+AI融合計算架構

融合計算突破界限,英特爾大小腦融合架構加速具身智能進化

曦智科技時隔八年再登《Nature》,光電混合計算架構首次公開

光電混合新范式:全球首款128x128矩陣規模光電混合計算卡正式發布

曦智科技全球首發新一代光電混合計算卡

大數據與云計算是干嘛的?
AD9826采集出來的數據有漂移和震蕩,是什么原因導致的?
ads1256有效位數怎么計算?
知合計算完成數億元A1輪融資
計算機視覺中的圖像融合





 工商網監
工商網監
評論