 OpenAI“里程碑”的含金量到底高不高?
OpenAI“里程碑”的含金量到底高不高?
上周,OpenAI Five擊敗DOTA2業余人類玩家,轟動游戲圈和AI圈,連比爾·蓋茨都忍不住發推特點贊,稱之為“里程碑事件”。這個事件對業界帶來的影響有多大?技術含量有多高?新智元采訪了數位國內外專家,他們并不全都贊同“里程碑”的觀點。
上周,OpenAI自學習多智能體5v5團隊戰擊敗DOTA2業余人類玩家,成為轟動人工智能圈的一件大事。
這個事件的意義,不僅僅局限于AI“攻克”星際爭霸或者Dota這樣的復雜電子競技游戲,而是代表著AI在決策智能上的能力大幅向前推進。
對于這件事,比爾·蓋茨也發推文稱贊:這是一件大事,因為它們的勝利需要團隊合作和協作——這是推進人工智能的一個巨大里程碑。
不過,也有觀點認為OpenAI這個“里程碑”只是在算力上的巨大勝利,并沒有在算法上創新,他們只是擴展了已有的方法。
OpenAI“里程碑”的含金量到底高不高?
先來看技術:強化學習能夠進行大但是可實現規模的長期規劃
OpenAI Five之所以戰勝DOTA2的業余選手,成為比爾·蓋茨眼里的里程碑事件,主要原因在于它使用“近端策略優化”(PPO)的擴展版算法,在256個GPU和128000個CPU內核上進行訓練。每個英雄都使用單獨的LSTM,不使用人類數據,最終AI能夠學會識別策略。
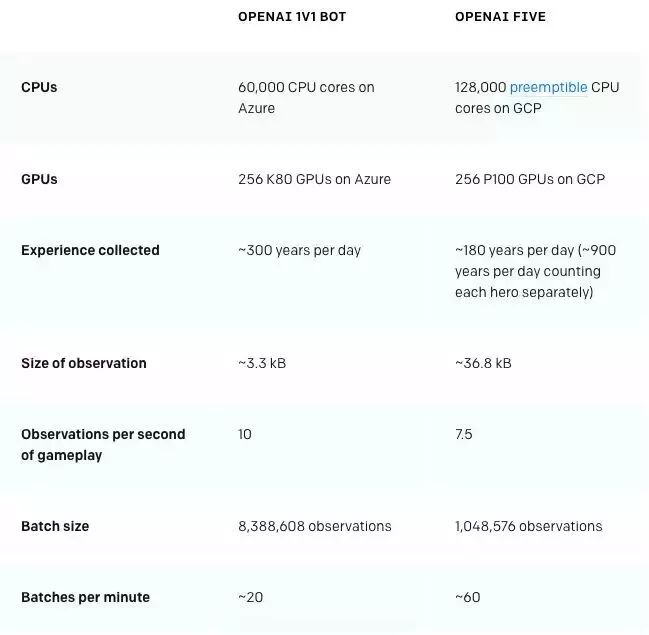
這種做法表明,強化學習能夠進行大但卻可實現規模(large but achievable scale)的長期規劃,而不發生根本性的進展。
國內首家決策智能公司啟元世界研究科學家、香港科技大學彭鵬博士認為,從Dota2中展現出來的群體智能來看,OpenAI Five無論從對整體局勢的判斷還是對局部戰場的應對,都展現了很高的智能決策能力。
整體戰略上,通過前期給輔助英雄一定的資源,讓輔助英雄可以通過gank和push幫助隊伍快速進入中期階段,加快并試圖掌握游戲節奏;能夠快速集結起部分隊員進行連續有效的gank;集中push敵方優勢路和中路,逼迫對方在較難防守的位置交戰。在團戰中,對切入時機、距離控制、英雄的職責分配、集火目標選擇和多種裝備的靈活運用做的非常到位。
最令人驚訝的是,OpenAI Five直接在微操級別的動作空間中進行探索和學習,僅僅通過幾天的訓練就達到了上述的效果。雖然有12800 CPU cores和256 P100 GPU的加持,這一結果足以使大家對深度強化學習有更強的信心。
此外,盡管當前版本的OpenAI Five的補兵能力表現不佳,但它在選擇優先攻擊目標上已經達到專業水平。獲得長期回報往往需要犧牲短期回報,例如發育后的金錢,因為團推時也需要耗費時間。這表明系統真正在進行長期的優化。
(關于更具體的實現過程,新智元此前有詳細報道,讀者可移步新智元知乎專欄閱讀:
https://zhuanlan.zhihu.com/p/38499219)
OpenAI自有過人之處,Smerity高度評價
彭鵬博士認為,從技術角度來講,OpenAI Five延續了OpenAI在1v1中所采用的建模方式,相比Deepmind主打的端到端學習(end-to-end learning),OpenAI Five直接使用語義信息作為模型的輸入,極大地降低模型訓練所需的計算力,這算是一個新進展。
另外,OpenAI Five也在reward function的構造也很有特色,在個人reward和團隊reward之間做了很好的平衡;模型會在訓練前期重視優化個人reward,而在訓練后期開始注重團隊reward。最后,OpenAI大規模高性能的Rapid系統設計也體現了他們的功力,同時調度上萬的CPU和GPU資源,在自我對弈的過程中不斷變強。
如果僅僅是通過算力提升來訓練模型,恐怕不能稱之為“里程碑”。
Metamind高級研究科學家Stephen Merity(即Smerity)在OpenAI Five的研究發布當天,連發數條推特,高度評價了這項成果。
Smerity本身是一名DOTA的深度玩家,他從WC3時代開始并且已經打了830小時的DOTA2,他認為這一影響遠遠超出了DOTA本身。
這些機器人從來沒有見過傳統的人類策略,它們只是按照規則和目標來玩游戲。如果有一種正和(positive sum)的方式來玩“人”的零和游戲,它一定會找到的。
我們可以預見未來社會中很多錯綜復雜的東西都沒有了,為什么呢?因為這些自主系統將讓我們意識到,現在我們的一些優化措施實際上是不成熟的,反而讓問題變得復雜;這些系統還能讓我們少走很多彎路,現在我們都是走了彎路以后才意識到自己繞了道。
作為人類,我們還不夠聰明,無法看穿復雜和復雜交互的迷霧,但我們編寫的系統或許可以。它們可能幫助我們實現幾百年來我們一直不情愿地、迷茫地走向的目標——協作。
OpenAI并沒有在算法上創新,談不上“里程碑式的成就”
倫敦大學學院(UCL)的計算機教授汪軍告訴新智元,AlphaGo之后,AI領域的下一大挑戰就是多智能體強化學習(Multi-Agent reinforcement learning,MARL),也即讓多個智能體學會合作與競爭。
DOTA、星際爭霸,還有更多人熟悉的王者榮耀,都屬于多智能體強化學習(MARL),但DOTA 5v5的設置相對更加簡單。從去年開始,汪軍在UCL的團隊與上海的一家游戲公司合作,研究如何讓AI玩王者榮耀。目前,包括DeepMind、Facebook、阿里、騰訊在內的很多機構,都在這些游戲上從事MARL研究,但尚未有團隊公開實質性的突破。
OpenAI的工作讓更多學者和公眾關注MARL,這是一件好事,但如果說這是一項“里程碑式的成就”,則遠遠談不上。
汪軍說,OpenAI僅發布了blog,沒有發布學術論文,目前對其科學性還比較難以評估。但從發布的blog上看不到算法的創新。他們只是擴展了已有的方法,然后上了大量的計算力——整整128000 CPU和 256 GPU,這樣的硬件基礎設施是一般的高校所不具備的。”
“OpenAI證明了使用現有的算法和trick,加上強大的計算力、工程力量和足夠的耐心,是可以把這件事情做出來的。”
很可惜的是,OpenAI并沒有針對游戲中AI如何合作去明晰建模,沒有嘗試去理解AI彼此合作的機制,模型還是單獨的強化學習,把其他的英雄當成環境的一部分,并使用普通的團隊和個體結合的獎勵機制,通過大量試錯取得了最后的結果。“只要有足夠多的時間(也就是足夠多的計算資源),你總能試出一些結果。”汪軍說,因此它不太具有創新性。
汪軍呼吁大家重視并扶持基礎性的長期研究,將眼光放長遠,“多多資助我們這些搞基礎研究的一些GPU”,對領域長期健康發展做出積極貢獻。
不過,汪軍也非常肯定AlphaGo、OpenAI等機構的研究對產業帶來的潛移默化的影響。“目前,阿里巴巴、百度、滴滴、京東、華為這些公司都在嘗試把強化學習用在不同的場景,比如直接用在互聯網廣告、倉儲物流、自動駕駛等場景上面,這就是AlphaGo帶來的影響,大家都對強化學習非常關注。”
“據我所知,DeepMind已經把研究的一些能量輸入到谷歌內部中,好像我們看到DeepMind還沒有實現經濟價值,其實已經讓谷歌內部產生了效率。”汪軍說。
-
人工智能
+關注
關注
1804文章
48701瀏覽量
246448 -
智能體
+關注
關注
1文章
264瀏覽量
10960 -
強化學習
+關注
關注
4文章
269瀏覽量
11517
原文標題:OpenAI戰勝DOTA2人類玩家是“里程碑式成就”?有專家評含金量不高
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
四創電子水利監測設備取得里程碑式進展

三星電子1c nm內存開發良率里程碑推遲
三星1c nm DRAM開發良率里程碑延期
e絡盟達成micro:bit分銷里程碑
破萬億!中國芯片出口迎來里程碑

e絡盟實現重要里程碑:成功分銷 1000 萬套 micro:bit 設備

Coherent 高意已實現出貨150,000個OPSL的里程碑






 工商網監
工商網監
評論