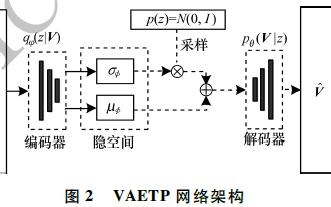
 采用的網絡架構,實現了基于圖像強度的變分深度自編碼器
采用的網絡架構,實現了基于圖像強度的變分深度自編碼器
相信各位小伙伴一定已經學習了今年CVPR的兩篇最佳論文了,一篇是來自于斯坦福和伯克利大學的研究人員共同進行的關于如何進行高效遷移學習的:Taskonomy: Disentangling Task Transfer Learning,另一篇來自卡耐基梅隆大學的論文:Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies實現了多尺度人類行為的三維重建和追蹤。但除此之外,還有四篇優秀的工作被授予了最佳論文的榮譽提名獎,分別是來自:
帝國理工戴森機器人實驗室的:CodeSLAM — Learning a Compact, Optimisable Representation for Dense Visual SLAM;
加州大學默塞德分校、麻省大學阿默斯特分校和英偉達的:SPLATNet: Sparse Lattice Networks for Point Cloud Processing;
隆德大學、羅馬尼亞科學院的:Deep Learning of Graph Matching;
奧地利科技學院、馬克思普朗克圖賓根研究所、海德巴拉國際信息技術研究所和劍橋大學共同研究的:Efficient Optimization for Rank-based Loss Functions四篇論文分別從幾何描述、點云處理、圖匹配和優化等方面進行了研究,下面讓我們一起學習一下吧!
CodeSLAM — Learning a Compact, Optimisable Representation for Dense Visual SLAM
在實時三維感知系統中,物體幾何的表述一直是一個十分關鍵的問題,特別是在定位和映射算法中有著重要的作用,它不僅影響著映射的幾何質量,更與其采取的算法息息相關。在SLAM特別是單目SLAM中場景幾何信息不能從單一的視角得到,而與生俱來的不確定性在大自由度下會變得難以控制。這使得目前主流的slam分成了稀疏和稠密兩個方向。雖然稠密地圖可以捕捉幾何的表面形貌并用語義標簽進行增強,但它的高維特性帶來的龐大存儲計算量限制了它的應用,同時它還不適用于精密的概率推測。稀疏的特征可以避免這些問題,但捕捉部分場景的特征僅僅對于定位問題有用。
為了解決這些問題,這篇文章里作者提出了一種緊湊但稠密的場景幾何表示,它以場景的單幅強度圖作為條件并由很少參數的編碼來生成。研究人員在從圖像學習深度和自編碼器等工作的啟發下設計了這一方法。這種方法適用于基于關鍵幀的稠密slam系統:每一個關鍵幀通過編碼可以生成深度圖,而編碼可以通過位姿變量和重疊的關鍵幀進行優化以保持全局的連續性。訓練的深度圖可使得編碼表示不能直接從圖像預測出的局部幾何特征。
這篇文章的貢獻主要在兩個方面:
推導出了一種通過強度圖訓練深度自編碼器的稠密集合表示,并進行了優化;
首次實現了稠密集合與運動估計聯合優化的單目系統。
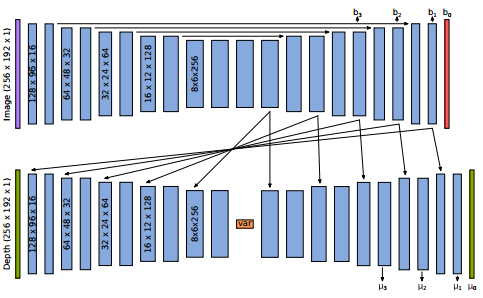
下圖是研究人員采用的網絡架構,實現了基于圖像強度的變分深度自編碼器。
下圖是編解碼階段不同的輸出,以及編碼抓取細節的能力:

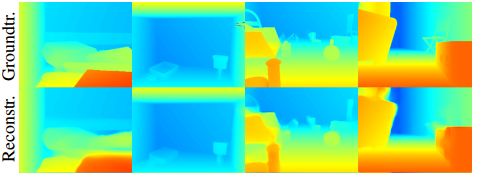
下圖是編碼后的恢復以及sfm結果:
研究人員們希望在未來構建出完整的基于關鍵幀的實時SLAM系統,并在更遠的將來致力于研究一般三維幾何更加緊湊的表示,甚至用于三維物體識別。
如果有興趣,可以訪問項目主頁獲取更詳細信息,也可參看附件的視頻簡介:
http://www.imperial.ac.uk/dyson-robotics-lab/projects/codeslam/
SPLATNet: Sparse Lattice Networks for Point Cloud Processing
激光雷達等三維傳感器的數據經常是不規則的點云形式,分析和處理點云數據在機器人和自動駕駛中有著十分重要的作用。
但點云具有稀疏性和無序性的特征,使得一般的卷積神經網絡處理3D點數據十分困難,所以目前主要利用手工特征來對點云進行處理。其中一種方法就是對點云進行預處理使其符合標準空間卷積的輸入形式。按照這一思路,用于3D點云分析的深度學習架構都需要對不規則的點云進行預處理,或者進行體素表示,或者投影到2D。這需要很多的人工并且會失去點云中包含自然的不變性信息。
為了解決這些問題,在這篇文章中作者提出了一種用于處理點云的網絡架構,其中的關鍵在于研究發現雙邊卷積層(e bilateral convolutionlayers——BCLs)對于處理點云有著很多優異的特性。
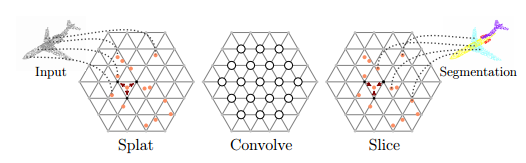
雙邊卷積層
BCLs提供了一種系統的方法來除了無序點,但同時保持了卷積操作中柵格的靈活性。BCL將輸入點云平滑地映射到稀疏的柵格上,并在稀疏柵格上進行卷積操作,隨后進行平滑插值并將信號映射到原始輸入中去。利用BCLs研究人員們建立了SPLATNet(SParse LATtice Networks)用于分層處理無序點云并識別器空間特征。
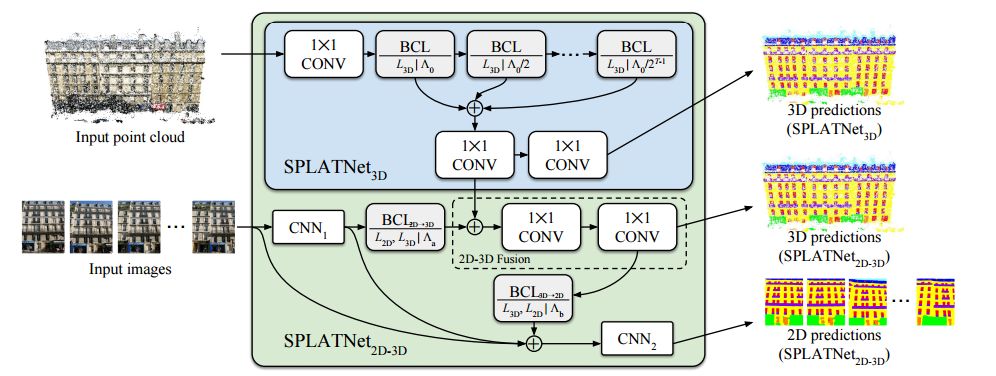
SPLATNet的架構
它具有以下優點:
無需點云預處理;
可以方便實現像標準CNN一樣的鄰域操作;
利用哈希表可高效處理稀疏輸入;
利用稀疏高效的柵格濾波實現對輸入點云分層和空間特征的處理;
可實現2D-3D之間的互相映射。
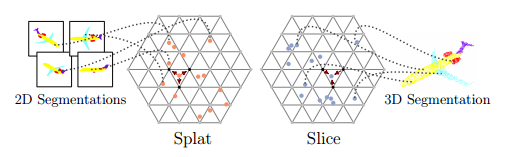
二維到三維的投影
下圖是對于建筑物點云的處理結果:

如果有興趣的小伙伴可以參考項目主頁:
http://vis-www.cs.umass.edu/splatnet/
和英偉達的官方介紹:https://news.developer.nvidia.com/nvidia-splatnet-research-paper-wins-a-major-cvpr-2018-award/
如果想要上手練練,這里還有代碼可以跑一波:https://github.com/NVlabs/splatnet
今天附件中包含了視頻介紹,敬請觀看。
https://pan.baidu.com/s/1dIyZyEx-Bc9zYPIr4F_5bw
Deep Learning of Graph Matching
圖匹配問題是優化、機器學習、計算機視覺中的重要問題,而如何表示節點與其相鄰結構的關系是其中的關鍵。這篇文章提出了一種端到端的模型來使得學習圖匹配過程中的所有參數成為可能。其中包括了單位的和成對的節點鄰域、表達成了深度分層的特征抽取。
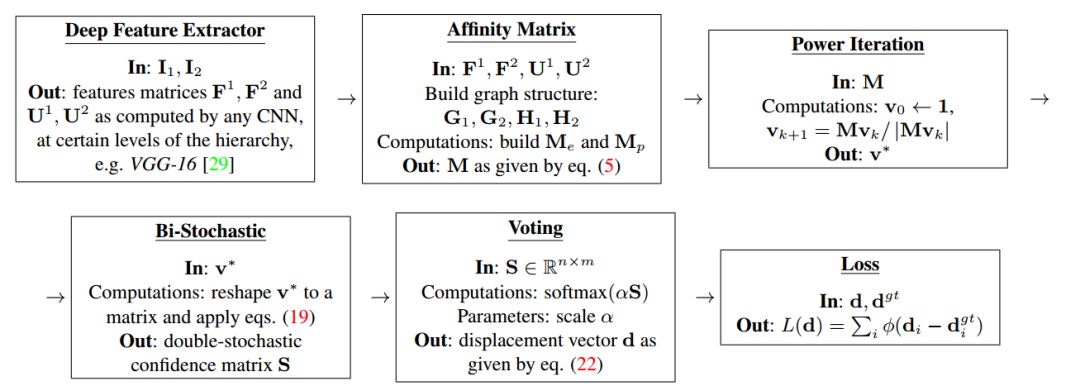
完整訓練圖匹配模型的計算流程
這其中的難點在于為不同層之間的矩陣運算建立從損失函數開始的完整流程、實現高效、連續的梯度傳播。通過結合優化層解決了匹配問題,并利用了分層特征抽取。最后在計算機視覺的實驗中取得了很好的結果。
可以看到在外形和位姿都極不同的各個實例中,關鍵點的圖匹配算法依然表現良好。
Efficient Optimization for Rank-based Loss Functions
在信息檢索系統中通常利用復雜的損失函數(AP,NDCG)來衡量系統的表現。雖然可以通過正負樣本來估計檢索系統的參數,但這些損失函數不可微、不可分解使得基于梯度的算法無法使用。通常情況下人們通過優化損失函數hinge-loss上邊界或者使用漸進方法來規避這一問題。

系統算法
為了解決這一問題,研究人員們提出了一種用于大規模不可微損失函數算法。提供了符合這一算法的損失函數的特征描述,它可以處理包括AP和NDCC系列的損失函數。同時研究人員們還提出了一種非比照的算法改進了上述漸進過程的計算復雜度。這種方法與更簡單的可分解(需要對照訓練)損失函數相比有著更好的結果。
-
神經網絡
+關注
關注
42文章
4809瀏覽量
102834 -
圖像
+關注
關注
2文章
1092瀏覽量
41038 -
激光雷達
+關注
關注
971文章
4196瀏覽量
192002
原文標題:提名也是莫大的榮譽:除了最佳論文,CVPR的這些論文也不容錯過
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?

自編碼器介紹
基于稀疏自編碼器的屬性網絡嵌入算法SAANE
基于變分自編碼器的海面艦船軌跡預測算法
自編碼器基礎理論與實現方法、應用綜述
一種多通道自編碼器深度學習的入侵檢測方法


基于變分自編碼器的網絡表示學習方法
自編碼器神經網絡應用及實驗綜述
基于深度稀疏自編碼網絡的行人檢測
基于交叉熵損失函欻的深度自編碼器診斷模型
自編碼器 AE(AutoEncoder)程序






 工商網監
工商網監
評論