") 自編碼器的原理和類型
自編碼器的原理和類型
一、自編碼器概述
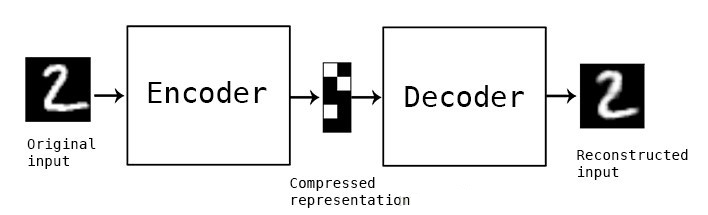
自編碼器(Autoencoder, AE)是一種無監(jiān)督學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò)模型,它通過編碼器和解碼器的組合,實(shí)現(xiàn)了對(duì)輸入數(shù)據(jù)的壓縮和重構(gòu)。自編碼器由兩部分組成:編碼器(Encoder)和解碼器(Decoder)。編碼器負(fù)責(zé)將輸入數(shù)據(jù)映射到一個(gè)低維的潛在空間(latent space),而解碼器則負(fù)責(zé)將這個(gè)低維表示映射回原始輸入空間,從而實(shí)現(xiàn)對(duì)輸入數(shù)據(jù)的重構(gòu)。自編碼器的目標(biāo)是最小化重構(gòu)誤差,即使得解碼器的輸出盡可能接近原始輸入數(shù)據(jù)。
自編碼器最早由Yann LeCun在1987年提出,用于解決表征學(xué)習(xí)中的“編碼器問題”,即基于神經(jīng)網(wǎng)絡(luò)的降維問題。隨著深度學(xué)習(xí)的發(fā)展,自編碼器在數(shù)據(jù)壓縮、特征提取、圖像生成等領(lǐng)域得到了廣泛應(yīng)用。
二、自編碼器的原理
1. 編碼器
編碼器的主要作用是將輸入數(shù)據(jù)映射到一個(gè)低維的潛在空間。這一過程通常通過多層神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn),每一層都會(huì)對(duì)數(shù)據(jù)進(jìn)行一定的變換和壓縮,最終得到一個(gè)低維的編碼表示。這個(gè)編碼表示是輸入數(shù)據(jù)的一種壓縮形式,它包含了輸入數(shù)據(jù)的主要特征信息,但去除了冗余和噪聲。
2. 解碼器
解碼器的作用是將編碼器的輸出(即低維表示)映射回原始輸入空間。與編碼器相反,解碼器通過多層神經(jīng)網(wǎng)絡(luò)逐層上采樣和變換,將低維表示恢復(fù)成原始輸入數(shù)據(jù)的近似形式。解碼器的目標(biāo)是使得重構(gòu)后的數(shù)據(jù)與原始輸入數(shù)據(jù)盡可能接近,即最小化重構(gòu)誤差。
3. 重構(gòu)誤差
重構(gòu)誤差是衡量自編碼器性能的重要指標(biāo)。它表示了原始輸入數(shù)據(jù)與重構(gòu)數(shù)據(jù)之間的差異程度。在訓(xùn)練過程中,自編碼器通過不斷調(diào)整編碼器和解碼器的參數(shù)來減小重構(gòu)誤差,從而實(shí)現(xiàn)對(duì)輸入數(shù)據(jù)的更好重構(gòu)。
4. 學(xué)習(xí)過程
自編碼器的訓(xùn)練過程是一個(gè)無監(jiān)督學(xué)習(xí)的過程。在訓(xùn)練過程中,不需要額外的標(biāo)簽信息,只需要輸入數(shù)據(jù)本身即可。通過前向傳播計(jì)算重構(gòu)誤差,然后通過反向傳播算法調(diào)整網(wǎng)絡(luò)參數(shù)以減小重構(gòu)誤差。這個(gè)過程會(huì)不斷迭代進(jìn)行,直到重構(gòu)誤差達(dá)到一個(gè)可接受的范圍或者訓(xùn)練輪次達(dá)到預(yù)設(shè)的上限。
三、自編碼器的類型
自編碼器根據(jù)其結(jié)構(gòu)和功能的不同可以分為多種類型,包括但不限于以下幾種:
1. 基本自編碼器(Vanilla Autoencoder)
基本自編碼器是最簡單的自編碼器形式,由一個(gè)編碼器和一個(gè)解碼器組成。它主要用于數(shù)據(jù)壓縮和去噪等任務(wù)。
2. 稀疏自編碼器(Sparse Autoencoder)
稀疏自編碼器在基本自編碼器的基礎(chǔ)上增加了稀疏性約束,通過限制隱藏層神經(jīng)元的激活程度來避免過擬合和提高特征表示的稀疏性。
3. 收縮自編碼器(Contractive Autoencoder)
收縮自編碼器通過添加對(duì)編碼器輸出關(guān)于輸入數(shù)據(jù)變化的懲罰項(xiàng)來鼓勵(lì)學(xué)習(xí)到的表示對(duì)數(shù)據(jù)變化具有魯棒性。這種自編碼器對(duì)于異常值檢測(cè)等任務(wù)特別有效。
4. 變分自編碼器(Variational Autoencoder, VAE)
變分自編碼器是一種生成模型,它通過引入隨機(jī)變量來生成輸入數(shù)據(jù)的潛在表示。VAE可以生成與原始數(shù)據(jù)分布相似的新數(shù)據(jù)樣本,因此在圖像生成、文本生成等領(lǐng)域具有廣泛應(yīng)用。
5. 卷積自編碼器(Convolutional Autoencoder)
卷積自編碼器特別適用于圖像數(shù)據(jù)的處理。它通過卷積層和池化層來實(shí)現(xiàn)對(duì)圖像數(shù)據(jù)的壓縮和重構(gòu),能夠保留圖像的主要特征信息并去除噪聲。
四、自編碼器的應(yīng)用
自編碼器在多個(gè)領(lǐng)域都有廣泛的應(yīng)用,包括但不限于以下幾個(gè)方面:
1. 數(shù)據(jù)壓縮
自編碼器通過將輸入數(shù)據(jù)映射到低維潛在空間來實(shí)現(xiàn)數(shù)據(jù)壓縮。與傳統(tǒng)的數(shù)據(jù)壓縮方法相比,自編碼器能夠?qū)W習(xí)到更加緊湊和有效的數(shù)據(jù)表示方式。
2. 特征提取
自編碼器在特征提取方面表現(xiàn)出色。通過訓(xùn)練自編碼器,可以得到輸入數(shù)據(jù)的有效特征表示,這些特征表示可以用于后續(xù)的分類、聚類等任務(wù)。
3. 圖像生成
變分自編碼器等生成模型可以生成與原始圖像相似的新圖像樣本。這對(duì)于圖像增強(qiáng)、圖像修復(fù)等任務(wù)具有重要意義。
4. 異常值檢測(cè)
收縮自編碼器等類型的自編碼器可以通過學(xué)習(xí)輸入數(shù)據(jù)的正常分布來檢測(cè)異常值。當(dāng)輸入數(shù)據(jù)偏離正常分布時(shí),自編碼器的重構(gòu)誤差會(huì)顯著增加,從而可以識(shí)別出異常值。
五、代碼實(shí)現(xiàn)
下面是一個(gè)使用Python和TensorFlow實(shí)現(xiàn)的基本自編碼器的示例代碼:
import tensorflow as tf
# 定義編碼器和解碼器
def encoder(x, encoding_dim):
hidden = tf.layers.dense(x, 1
hidden = tf.layers.dense(x, encoding_dim, activation='relu')
return hidden
def decoder(x, decoding_dim, input_shape):
hidden = tf.layers.dense(x, decoding_dim, activation='relu')
output = tf.layers.dense(hidden, np.prod(input_shape), activation='sigmoid')
output = tf.reshape(output, [-1, *input_shape])
return output
# 輸入數(shù)據(jù)的維度
input_shape = (28, 28, 1) # 例如,MNIST數(shù)據(jù)集的圖像大小
input_img = tf.keras.layers.Input(shape=input_shape)
# 編碼維度
encoding_dim = 32 # 可以根據(jù)需要調(diào)整
# 通過編碼器獲取編碼
encoded = encoder(input_img, encoding_dim)
# 解碼器輸出重構(gòu)的圖像
decoded = decoder(encoded, encoding_dim, input_shape)
# 自編碼器模型
autoencoder = tf.keras.Model(input_img, decoded)
# 編碼器模型
encoder_model = tf.keras.Model(input_img, encoded)
# 解碼器模型(需要自定義輸入層)
encoder_output = tf.keras.layers.Input(shape=(encoding_dim,))
decoder_layer = decoder(encoder_output, encoding_dim, input_shape)
decoder_model = tf.keras.Model(encoder_output, decoder_layer)
# 編譯模型
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 假設(shè)我們有一些MNIST數(shù)據(jù)用于訓(xùn)練
# 這里僅展示模型構(gòu)建過程,數(shù)據(jù)加載和訓(xùn)練過程略去
# ...
# data_x = ... # 訓(xùn)練數(shù)據(jù)
# autoencoder.fit(data_x, data_x, epochs=50, batch_size=256, shuffle=True, validation_split=0.2)
# 使用自編碼器進(jìn)行預(yù)測(cè)(重構(gòu))
# reconstructed_imgs = autoencoder.predict(data_x)
# 注意:上述代碼是一個(gè)框架示例,實(shí)際使用時(shí)需要根據(jù)你的具體數(shù)據(jù)和需求進(jìn)行調(diào)整。
# 例如,你可能需要加載MNIST數(shù)據(jù)集,預(yù)處理數(shù)據(jù),然后訓(xùn)練模型。
在這個(gè)示例中,我們定義了一個(gè)基本自編碼器的編碼器和解碼器部分。編碼器通過一個(gè)全連接層將輸入圖像壓縮成一個(gè)低維的編碼表示,而解碼器則通過另一個(gè)全連接層和重塑操作將編碼表示恢復(fù)成原始圖像的大小。
我們使用了TensorFlow的高級(jí)API tf.keras 來構(gòu)建和編譯模型。模型autoencoder是一個(gè)完整的自編碼器,它包含了編碼器和解碼器兩部分。此外,我們還分別構(gòu)建了只包含編碼器的encoder_model和只包含解碼器的decoder_model,以便在需要時(shí)單獨(dú)使用它們。
請(qǐng)注意,這個(gè)示例代碼并沒有包含數(shù)據(jù)加載和訓(xùn)練的部分,因?yàn)槟菍⑷Q于你具體使用的數(shù)據(jù)集和訓(xùn)練環(huán)境。在實(shí)際應(yīng)用中,你需要加載你的數(shù)據(jù)集(如MNIST手寫數(shù)字?jǐn)?shù)據(jù)集),將其預(yù)處理為適合模型輸入的格式,并使用autoencoder.fit()方法來訓(xùn)練模型。
自編碼器的性能很大程度上取決于其結(jié)構(gòu)和超參數(shù)的選擇,如編碼維度encoding_dim、隱藏層的大小和激活函數(shù)等。這些參數(shù)需要通過實(shí)驗(yàn)和調(diào)整來找到最優(yōu)的組合。
-
編碼器
+關(guān)注
關(guān)注
45文章
3775瀏覽量
137127 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4807瀏覽量
102766 -
模型
+關(guān)注
關(guān)注
1文章
3486瀏覽量
49988
發(fā)布評(píng)論請(qǐng)先 登錄
基于變分自編碼器的異常小區(qū)檢測(cè)
是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?

自編碼器介紹
稀疏自編碼器及TensorFlow實(shí)現(xiàn)詳解
基于稀疏自編碼器的屬性網(wǎng)絡(luò)嵌入算法SAANE
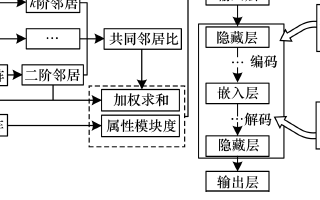
自編碼器基礎(chǔ)理論與實(shí)現(xiàn)方法、應(yīng)用綜述
自編碼器神經(jīng)網(wǎng)絡(luò)應(yīng)用及實(shí)驗(yàn)綜述
六種不同類型的編碼器 對(duì)應(yīng)旋轉(zhuǎn)和線性編碼器有什么區(qū)別?
旋轉(zhuǎn)編碼器如何工作?有哪些類型?
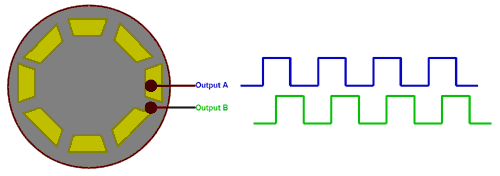
堆疊降噪自動(dòng)編碼器(SDAE)
自編碼器 AE(AutoEncoder)程序

旋轉(zhuǎn)編碼器的常見類型
編碼器類型詳解:探索不同編碼技術(shù)的奧秘






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論