") 在樹莓派5上使用YOLO進(jìn)行物體和動物識別-入門指南
在樹莓派5上使用YOLO進(jìn)行物體和動物識別-入門指南

大家好,接下來會為大家開一個樹莓派5和YOLO的專題。
內(nèi)容包括四個部分:
在樹莓派5上使用YOLO進(jìn)行物體和動物識別-入門指南
在樹莓派5上開啟YOLO人體姿態(tài)估計識別之旅
YOLO物體檢測在樹莓派AI Hat+上 | 如何編寫自定義Python代碼
YOLO姿態(tài)估計在樹莓派AI Hat+上 | 編寫自定義Python代碼
今天是第一部分:在樹莓派5上使用YOLO進(jìn)行物體和動物識別-入門指南
如果大家對這個專題有興趣,記得關(guān)注樹莓派開發(fā)者,這樣你將會第一時間收到我們的內(nèi)容更新通知。
你是否曾想涉足計算機(jī)視覺領(lǐng)域?比如在樹莓派這樣的低功耗便攜式硬件上嘗試如何?
在本指南中,我們將在樹莓派5上配置YOLO視覺模型系列、OpenCV和COCO對象庫。我們將探討一些可用的不同YOLO模型,如何針對處理能力和速度優(yōu)化它們,如何使用檢測結(jié)果控制硬件,還將介紹YOLO World——一個非常令人興奮的開放詞匯模型,它能夠根據(jù)提示而非預(yù)訓(xùn)練項目列表來檢測對象。
如今,由于我們能夠在樹莓派等硬件上運行高性能視覺模型,計算機(jī)視覺變得比以往任何時候都更簡單、高效。這得益于我們將在本指南中利用的出色開源項目:COCO庫、OpenCV和YOLO。不過,在我們深入探討這些之前,我們會經(jīng)常提到它們,因此先通過一個簡單的類比來解釋它們的作用。
OpenCV就像我們計算機(jī)視覺“廚師”的廚房。它為我們準(zhǔn)備了制作食物所需的工具和框架。YOLO則是廚房里的“廚師”。它是系統(tǒng)中實際工作、“思考”并嘗試識別物體的部分。最后,我們有COCO庫。這是YOLO附帶的訓(xùn)練數(shù)據(jù)——就像YOLO要遵循的食譜或烹飪書。如果COCO庫中有識別汽車的指令,那么YOLO這位“廚師”就能識別汽車;如果沒有這些指令,YOLO就無法識別。因此,在OpenCV這個廚房里,YOLO這位“廚師”根據(jù)COCO庫這本烹飪書來工作。
希望這個解釋能讓你明白,讓我們開始吧!你可以選擇觀看視頻演示
目錄
所需物品
硬件組裝
安裝樹莓派操作系統(tǒng)
設(shè)置虛擬環(huán)境并安裝YOLO
運行YOLOv8
運行其他YOLO模型
提高處理速度(NCNN轉(zhuǎn)換和分辨率)
控制硬件
深入了解YOLO World
后續(xù)方向
致謝
附錄:使用網(wǎng)絡(luò)攝像頭
所需物品
要跟隨本指南進(jìn)行操作,你需要準(zhǔn)備以下物品:
樹莓派5 - 4GB或8GB型號均可。雖然理論上也可以在樹莓派4上完成,但速度遠(yuǎn)慢于樹莓派5,體驗不佳,因此我們未在樹莓派4上進(jìn)行測試。
樹莓派攝像頭 - 我們使用的是攝像頭模塊V3
轉(zhuǎn)接線 - 樹莓派5配備的是不同尺寸的CSI攝像頭線,而你的攝像頭可能配備的是較舊的較粗線,因此請仔細(xì)檢查。攝像頭模塊V3肯定需要轉(zhuǎn)接線
散熱方案 - 我們使用的是主動散熱器(計算機(jī)視覺會讓你的樹莓派達(dá)到性能極限)
Micro SD卡 - 容量至少為16GB
顯示器和Micro-HDMI轉(zhuǎn)HDMI線
鼠標(biāo)和鍵盤
*所需物品可以直接聯(lián)系我們進(jìn)行購買。
硬件組裝
硬件組裝過程相對簡單。將線纜較粗的一端連接到攝像頭,較細(xì)的一端連接到樹莓派5。這些連接器上有一個標(biāo)簽 - 將其抬起,然后將線纜插入插槽。確保線纜插入整齊后,將標(biāo)簽壓回原位以固定線纜。

注意,這些連接器只能以一個方向插入,且較為脆弱,因此請避免過度彎曲(稍微彎曲一點沒問題)。
安裝樹莓派操作系統(tǒng)
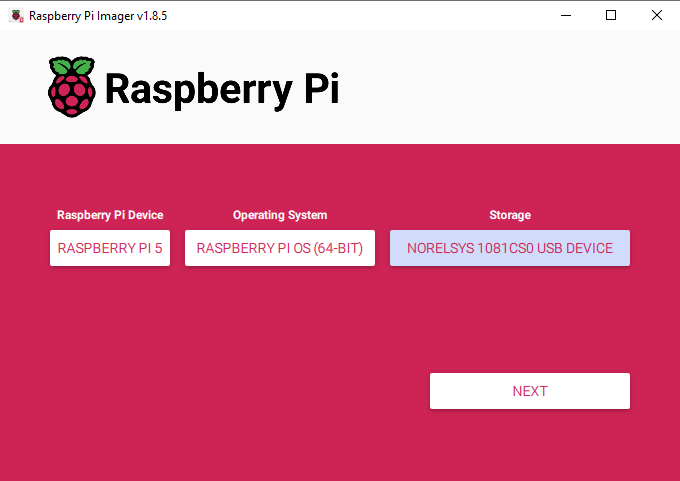
首先,我們需要將樹莓派操作系統(tǒng)安裝到Micro SD卡上。使用樹莓派成像工具,選擇樹莓派5作為設(shè)備,樹莓派操作系統(tǒng)(64位)作為操作系統(tǒng),以及你的MicroSD卡作為存儲設(shè)備。
下載樹莓派操作系統(tǒng):https://www.raspberrypi.com/software/
注意:將樹莓派操作系統(tǒng)安裝到MicroSD卡上會清除卡上的所有數(shù)據(jù)。
此過程可能需要幾分鐘時間來下載操作系統(tǒng)并安裝。安裝完成后,將其插入樹莓派并啟動。樹莓派將進(jìn)行首次安裝設(shè)置,請確保將其連接到互聯(lián)網(wǎng)。
你還需要記住在此創(chuàng)建的用戶名,因為本指南中涉及的文件位置會用到它。為簡單起見,你可以直接將其命名為“pi”。
設(shè)置虛擬環(huán)境并安裝YOLO
隨著2023年Bookworm操作系統(tǒng)的推出,我們現(xiàn)在需要使用虛擬環(huán)境(或venv)。虛擬環(huán)境是隔離的虛擬空間,我們可以在其中運行項目,而不會破壞樹莓派操作系統(tǒng)的其余部分和軟件包——換句話說,我們可以在這里隨心所欲地操作,而不會損壞樹莓派操作系統(tǒng)的其余部分。這是一個需要學(xué)習(xí)的額外部分,但非常簡單。
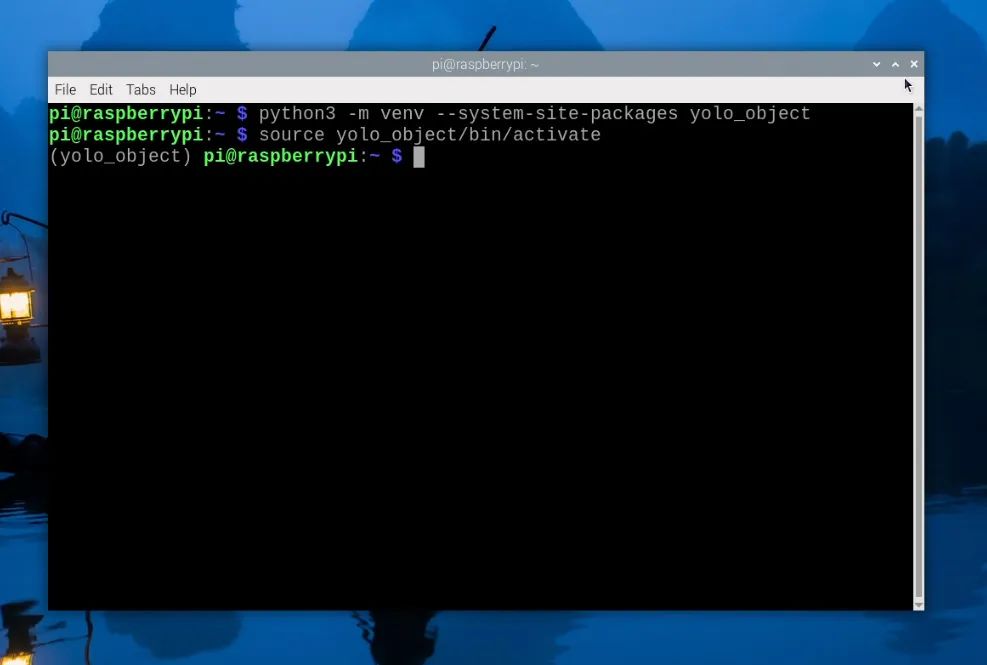
要創(chuàng)建虛擬環(huán)境,請打開一個新的終端窗口并輸入:
python3 -m venv--system-site-packagesyolo_object
這將創(chuàng)建一個名為“yolo_object”的新虛擬環(huán)境。你可以在home/pi下找到此虛擬環(huán)境的文件夾,它將被稱為“yolo_object”。
創(chuàng)建venv后,通過輸入以下命令進(jìn)入:
sourceyolo_object/bin/activate
執(zhí)行上述操作后,你會在綠色文本的左側(cè)看到虛擬環(huán)境的名稱 - 這意味著我們正在其中正確工作。如果你需要重新進(jìn)入此環(huán)境(例如,如果你關(guān)閉了終端窗口,你將退出環(huán)境),只需再次輸入上述source命令即可。
現(xiàn)在,我們處于虛擬環(huán)境中,可以開始安裝所需的軟件包。首先,通過輸入以下三行命令確保PIP(Python軟件包管理器)是最新的:
sudoapt updatesudo apt install python3-pip -ypip install -U pip
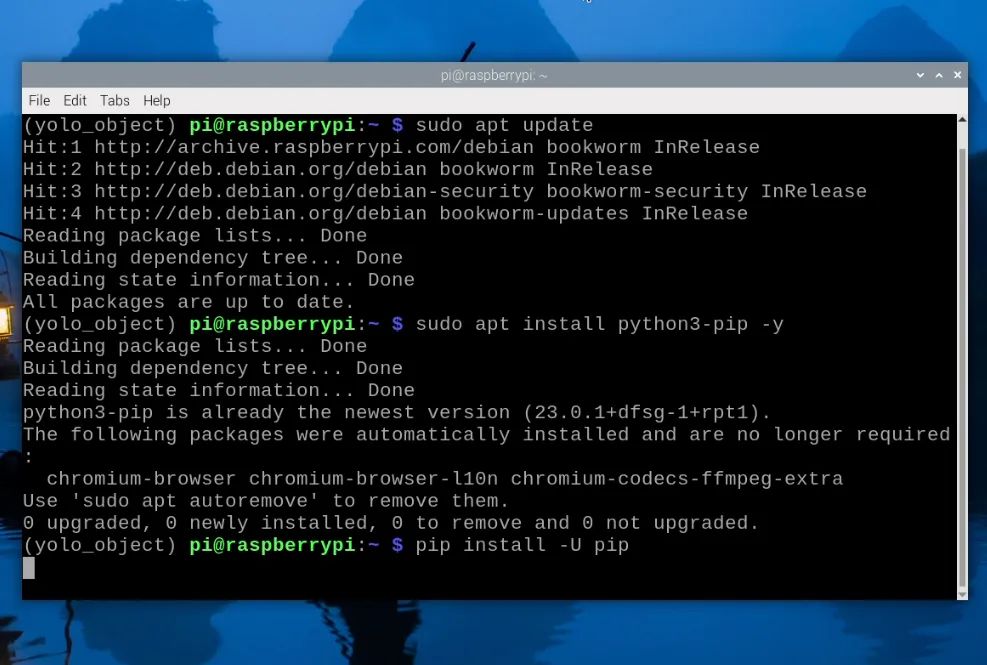
然后,使用以下命令安裝Ultralytics軟件包:
pip install ultralytics[export]
Ultralytics的優(yōu)秀團(tuán)隊是最新YOLO模型的主要開發(fā)者和維護(hù)者之一。他們的這個軟件包將承擔(dān)大部分繁重的工作,并安裝OpenCV以及我們運行YOLO所需的所有基礎(chǔ)設(shè)施。
此過程還將安裝大量其他軟件包,因此可能會失敗。如果你的安裝失敗(會顯示一大片紅色文本),只需再次輸入Ultralytics安裝命令,它應(yīng)該會繼續(xù)。在極少數(shù)情況下,安裝命令可能需要重復(fù)幾次。
安裝完成后,重啟樹莓派。如果你想成為高級用戶,可以在shell中輸入:
reboot
我們還有一件事要做,那就是設(shè)置Thonny以使用我們剛剛創(chuàng)建的虛擬環(huán)境。Thonny是我們將運行所有代碼的程序,我們需要讓它從同一個venv中運行,以便它可以訪問我們安裝的庫。
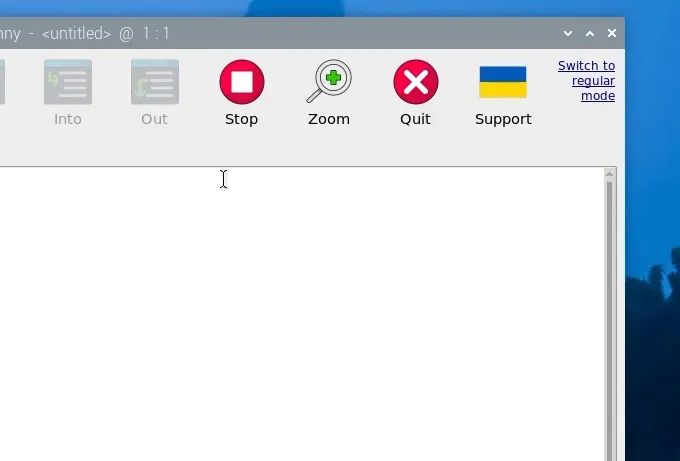
首次打開Thonny時,它可能處于簡化模式,你會在右上角看到“切換到常規(guī)模式”。如果存在此選項,請點擊它并關(guān)閉Thonny以重新啟動。
現(xiàn)在,通過選擇“運行”>“配置解釋器”進(jìn)入解釋器選項菜單。在“Python可執(zhí)行文件”選項下,有一個帶三個點的按鈕。選擇它并導(dǎo)航到我們剛剛創(chuàng)建的虛擬環(huán)境中的Python可執(zhí)行文件。
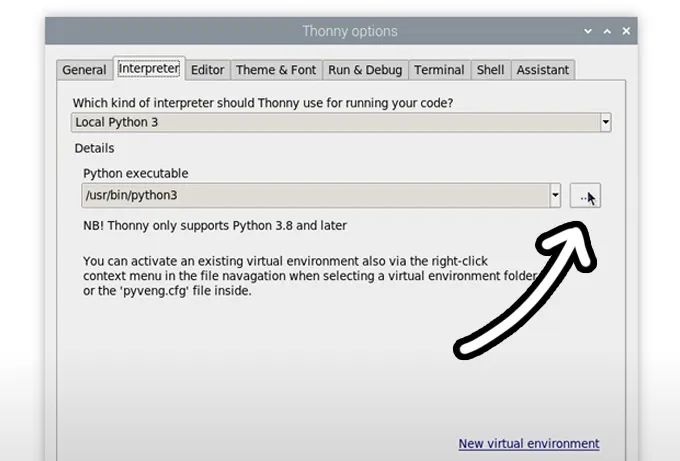
該文件位于home/pi/yolo_object/bin下,在此文件中,你需要選擇名為“python3”的文件。點擊確定,你現(xiàn)在將在此venv中工作。
無論何時打開Thonny,它都將自動在此環(huán)境中運行。你可以通過從同一解釋器選項菜單中“Python可執(zhí)行文件”下的下拉菜單中選擇它來更改工作環(huán)境。如果你想退出虛擬環(huán)境,請選擇bin/python3選項。
運行YOLOv8
在Thonny中創(chuàng)建一個新腳本,并粘貼以下代碼:
importcv2from picamera2 import Picamera2from ultralytics import YOLO# Set up the camera with Picampicam2= Picamera2()picam2.preview_configuration.main.size = (1280,1280)picam2.preview_configuration.main.format ="RGB888"picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# Load YOLOv8model= YOLO("yolov8n.pt")whileTrue: # Capture a frame from the camera frame= picam2.capture_array() # Run YOLO model on the captured frame and store the results results= model(frame) # Output the visual detection data, we will draw this on our camera preview window annotated_frame= results[0].plot() # Get inference time inference_time= results[0].speed['inference'] fps=1000/ inference_time # Convert to milliseconds text= f'FPS: {fps:.1f}' # Define font and position font= cv2.FONT_HERSHEY_SIMPLEX text_size= cv2.getTextSize(text, font,1,2)[0] text_x= annotated_frame.shape[1] - text_size[0] -10 #10pixels from the right text_y= text_size[1] +10 #10pixels from the top # Draw the text on the annotated frame cv2.putText(annotated_frame, text, (text_x, text_y), font,1, (255,255,255),2, cv2.LINE_AA) # Display the resulting frame cv2.imshow("Camera", annotated_frame) # Exit the program if q is pressed ifcv2.waitKey(1) == ord("q"): break# Close all windowscv2.destroyAllWindows()
運行YOLO代碼通常涉及下載模型,這些模型將保存到腳本所在的位置,因此,創(chuàng)建一個文件夾并將腳本保存在其中以保持整潔可能是個明智的選擇。我們只是在桌面上創(chuàng)建了一個文件夾并將所有內(nèi)容保存到了那里。保存YOLO代碼時,請確保將其保存為“.py”Python文件。
現(xiàn)在,點擊綠色播放按鈕運行代碼,下載模型后,應(yīng)該會彈出一個窗口顯示攝像頭畫面以及YOLO檢測到的任何物體。
它會自動在檢測到的物體周圍繪制一個框,標(biāo)注物體名稱,并給出檢測置信度評分(1.0為最高)。
這就是我們基礎(chǔ)級別的YOLO模型在工作!雖然現(xiàn)在的FPS可能不高(約為1.5 FPS),但我們很快將探討如何改進(jìn)。
要停止此腳本,只需按下Q鍵。

讓我們快速了解一下這段代碼的工作原理,以便我們大致了解其內(nèi)部機(jī)制。
首先,我們導(dǎo)入所需的庫;cv2是OpenCV,Picamera2是我們用來將攝像頭的視頻流導(dǎo)入代碼的庫,Ultralytics是我們的YOLO模型來源。
importcv2frompicamera2importPicamera2fromultralyticsimportYOLO
然后,我們通過使用Picamera2初始化攝像頭并加載YOLOv8模型來結(jié)束設(shè)置階段。
# Set up the camera with Picampicam2= Picamera2()picam2.preview_configuration.main.size = (1280,1280)picam2.preview_configuration.main.format ="RGB888"picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# Load YOLOv8model= YOLO("yolov8n.pt")
接下來,我們進(jìn)入一個循環(huán)的While True循環(huán),該循環(huán)從攝像頭獲取圖像,將其輸入到Y(jié)OLOv8模型中,然后獲取模型輸出的數(shù)據(jù)。
whileTrue: # Capture a frame from the camera frame = picam2.capture_array() # Run YOLO model on the captured frame and store the results results = model(frame) # Output the visual detection data, we will draw this on our camera preview window annotated_frame = results[0].plot()
接下來的這段代碼是一些計算我們正在處理的FPS的數(shù)學(xué)運算,然后是一些OpenCV相關(guān)的代碼,用于將FPS附加到模型的輸出數(shù)據(jù)上。
# Get inference timeinference_time= results[0].speed['inference']fps=1000/ inference_time # Convert to millisecondstext= f'FPS: {fps:.1f}'
# Define font and positionfont= cv2.FONT_HERSHEY_SIMPLEXtext_size= cv2.getTextSize(text, font,1,2)[0]text_x= annotated_frame.shape[1] - text_size[0] -10 #10pixels from the righttext_y= text_size[1] +10 #10pixels from the top
# Draw the text on the annotated framecv2.putText(annotated_frame, text, (text_x, text_y), font,1, (255,255,255),2, cv2.LINE_AA)
然后,我們最終在攝像頭畫面窗口上疊加輸出數(shù)據(jù)和FPS計數(shù)器。
# Display the resulting framecv2.imshow("Camera", annotated_frame)
最后,我們通過按下“q”鍵退出。如果按下該鍵,則腳本將跳出當(dāng)前的while True循環(huán)并關(guān)閉所有窗口。
# Exit the program if q is pressed ifcv2.waitKey(1) == ord("q"): break# Close all windowscv2.destroyAllWindows()
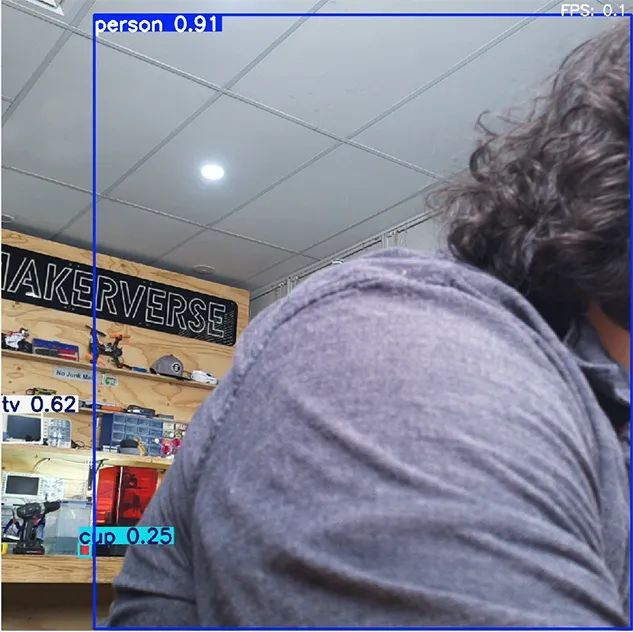
在繼續(xù)改進(jìn)YOLO之前,有一個限制值得指出。現(xiàn)在,你的樹莓派可能能夠檢測到坐在它前面的人,以及椅子、電視和杯子等常見物品。然而,它無法檢測到所有物品。在右側(cè)的圖片中,有許多物品未被檢測到,這是由于COCO庫的限制。

YOLOv8是在COCO庫上進(jìn)行訓(xùn)練的,該庫將對象分類為大約88個不同的類別——這意味著你只能檢測到88種不同類型的物品。這聽起來可能不多,但當(dāng)你考慮到其中一些類別非常常見且廣泛,如“汽車”或“運動球”時,它能檢測到的物品就相當(dāng)多了。然而,如果某個對象不是其訓(xùn)練庫的一部分(如眼鏡),它將無法識別。這預(yù)示著YOLO World將讓我們克服這一限制。
運行其他YOLO模型
到目前為止,我們一直在運行YOLOv8,而這個ultralytics軟件包的美妙之處在于,我們只需在代碼中替換一行即可完全更改模型,我們可以使用它來運行更高級的v8模型,甚至是舊模型。你只需要更改設(shè)置中的這一行:
# Load YOLOv8model= YOLO("yolov8n.pt")
此行當(dāng)前使用的是nano模型,它是YOLOv8中最小、功能最弱但速度最快的模型。我們可以通過更改“v8”后面的單個字母來更改此行以運行此模型的不同尺寸版本,如下所示。如果你更改此行并運行它,腳本將自動下載新模型(對于較大的模型,可能達(dá)到數(shù)百MB)。

正如你所猜到的,圖像處理性能和FPS之間存在權(quán)衡。如果你運行超大模型,F(xiàn)PS應(yīng)低于0.1(我們很快將改進(jìn)這一點),但你也應(yīng)該注意到檢測性能有了顯著提升。這些較大的模型更擅長識別遠(yuǎn)離攝像頭的物品,如右側(cè)圖像所示,并且能夠更可靠地以更高的準(zhǔn)確度識別物體。如果你手里拿著一個杯子,nano模型可能會在識別為手機(jī)和杯子之間跳躍,但超大模型將更一致地識別為杯子。
在我們的廚房類比中,這就像告訴“廚師”(YOLOv8)應(yīng)該花多長時間準(zhǔn)備一道菜,nano是花費時間最少的,可能會產(chǎn)生一些粗糙的結(jié)果,而超大則是“不惜一切代價”的情況。
我們還可以使用這些尺寸之間的不同模型,它們在處理性能和FPS之間存在不同程度的權(quán)衡,因此你可以嘗試一下,看看哪個既準(zhǔn)確又足夠快,滿足你的需求。
我們可以更改的另一件事是模型版本。YOLO從v1開始,現(xiàn)在已經(jīng)發(fā)展到v10(我們使用的是v8,因為在撰寫本文時,它與v10一樣快,并且可以針對樹莓派進(jìn)行更好的優(yōu)化)。這些版本提高了模型的速度和功能,在我們的廚房類比中,就像使用更熟練和經(jīng)驗豐富的“廚師”。
更改此版本同樣簡單,例如,如果我們出于遺留原因想使用v5,我們只需將同一行修改為:
# Load YOLOv8model= YOLO("yolov5n.pt")
如果你想嘗試v10,只需寫:
# Load YOLOv8model= YOLO("yolov10n.pt")
本指南最終會過時,但如果在本指南發(fā)布后發(fā)布了v11或v12或其他版本,你很有可能只需簡單地更改那一行即可使用最新模型運行此代碼。
更新:在我們發(fā)布本指南的當(dāng)天,Ultralytics發(fā)布了YOLO11。要使用新模型,只需將該行更改為以下內(nèi)容。請注意,他們似乎已經(jīng)放棄了“V”命名方案。
# Load our YOLO11 modelmodel= YOLO("yolo11n.pt")
提高處理速度
我們可以通過兩種方法來提高樹莓派上的FPS,而最有效的方法是將模型轉(zhuǎn)換為稱為NCNN的格式。這是一種更優(yōu)化以在基于ARM的處理器(如樹莓派的處理器)上運行的模型格式。打開名為“ncnn conversion.py”的腳本,你將找到以下內(nèi)容:
fromultralyticsimportYOLO# Load a YOLOv8n PyTorch modelmodel = YOLO("yolov8n.pt")# Export the model to NCNN formatmodel.export(format="ncnn", imgsz=640) # creates 'yolov8n_ncnn_model'
要使用此腳本,首先指定你要轉(zhuǎn)換的模型。這使用我們在上一節(jié)中討論的相同命名約定。然后,指定模型格式“ncnn”作為輸出格式以及分辨率。目前,請保持默認(rèn)的640。首次運行此腳本時,它將下載更多所需的內(nèi)容,但實際轉(zhuǎn)換應(yīng)該只需幾秒鐘。
完成后,在腳本所在的文件夾中,你將找到一個名為“yolov8n_ncnn_model”之類的新文件夾。復(fù)制此文件名并返回到我們之前的演示腳本。
現(xiàn)在,你需要通過將模型行更改為它剛剛創(chuàng)建的文件夾的名稱來告訴腳本使用我們創(chuàng)建的模型。它應(yīng)該如下所示:
# Load our YOLOv8 modelmodel= YOLO("yolov8n_ncnn_model")
如果你運行腳本,它應(yīng)該與之前完全一樣地工作,但由于NCNN轉(zhuǎn)換,F(xiàn)PS提高了4倍。
我們可以做的另一件事來提高FPS是降低處理分辨率。這是我們將運行YOLO模型的分辨率,像素越少意味著處理每幀所需的時間越少。
雖然轉(zhuǎn)換為NCNN是免費的FPS提升,但降低分辨率確實會犧牲一些能力。較低的分辨率會略微降低姿態(tài)估計的準(zhǔn)確性(雖然不太明顯),并且最大的影響是它會降低可以估計姿態(tài)的距離。默認(rèn)分辨率為640時,范圍相當(dāng)遠(yuǎn),因此我們可以適當(dāng)降低一點。
為此,請打開我們剛剛使用的NCNN轉(zhuǎn)換腳本并在以下行中指定你想要的分辨率:
# Export the model to NCNN formatmodel.export(format="ncnn", imgsz=320) # creates 'yolov8_ncnn_model'
注意:這必須是32的倍數(shù)。因此,你不能將其設(shè)置為300,但可以設(shè)置為320。
我們發(fā)現(xiàn),160到320范圍內(nèi)的分辨率在性能和速度之間取得了良好的平衡。
運行轉(zhuǎn)換代碼,它將導(dǎo)出具有所需分辨率的模型。這樣做也會覆蓋任何之前導(dǎo)出的同名模型。
在演示腳本中,確保你像之前一樣指定了NCNN模型。還有一件重要的事情我們必須做,那就是告訴腳本要向模型輸入什么分辨率。在while true循環(huán)中,你將找到以下行。確保它與模型的分辨率匹配,對于此示例,我們導(dǎo)出的是320:
# Run YOLO model on the captured frame and store the results results= model.predict(frame, imgsz =320)
如果一切順利,你應(yīng)該會看到FPS再次顯著提高。根據(jù)需要調(diào)整此分辨率,但請記住:
它必須是32的倍數(shù)
你必須更改主腳本中的名稱以使用導(dǎo)出的模型
你必須設(shè)置主腳本中的分辨率以匹配模型

控制硬件
現(xiàn)在,我們可以識別物體并根據(jù)需要優(yōu)化此過程,但如何使用它呢?我們只有一個攝像頭預(yù)覽窗口,上面疊加了檢測結(jié)果。
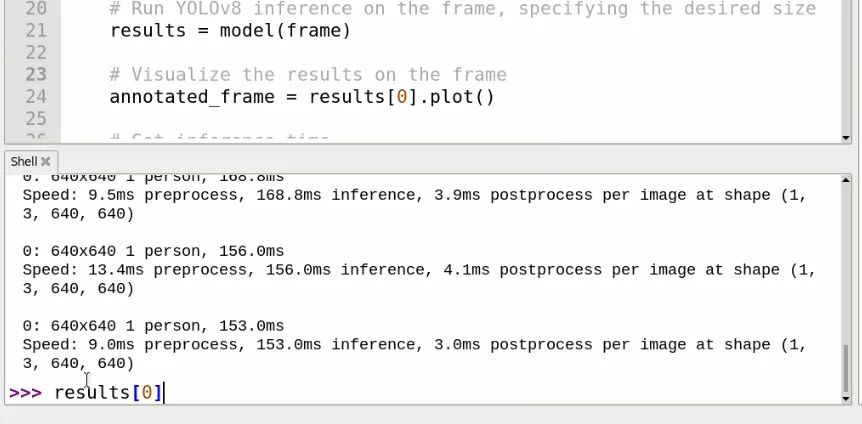
所有這些數(shù)據(jù)都是從results變量中檢索的。如果你運行腳本幾秒鐘,然后按“q”停止它,以便在shell中顯示幾個條目(如右側(cè)圖像所示),你可以在shell中輸入:
results[0]
你將能夠看到檢測結(jié)果的內(nèi)部信息。“[0]”在末尾表示你正在獲取最新分析幀的結(jié)果。如果你滾動查看此內(nèi)容,應(yīng)該能夠看到一個名為names的部分,其中包含COCO庫可以檢測到的所有對象的名稱以及與這些對象關(guān)聯(lián)的ID(例如,人為0,自行車為1,汽車為2等)。如果你想手動獲取此列表,可以輸入:
results[0].names
在results[0]中,我們還可以獲取屏幕上檢測到的所有內(nèi)容的列表。如果你輸入:
results[0].boxes.cls
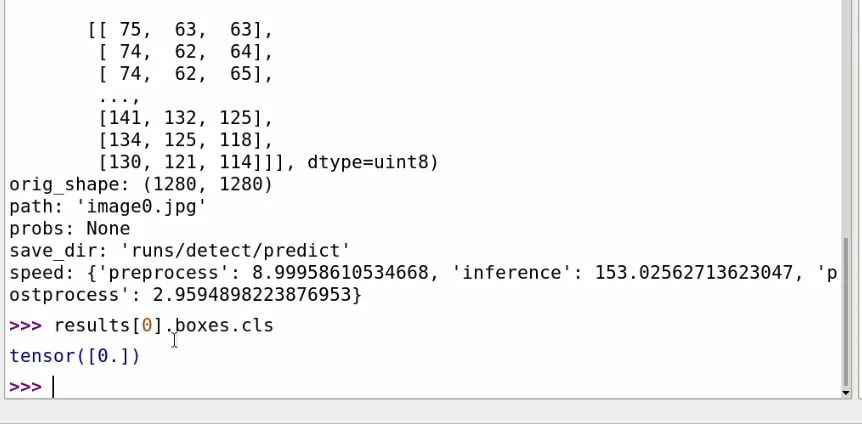
你將獲得正在檢測的對象的所有ID列表。在我右側(cè)的示例中,我們只檢測到了一個人,其ID為0。這將成為我們利用檢測結(jié)果的主要方法。
使用這個“results[0].boxes.cls”,我們可以編寫代碼來使用樹莓派控制硬件。以下是一些實現(xiàn)此功能的演示代碼:
importcv2from picamera2importPicamera2from ultralyticsimportYOLOfrom gpiozeroimportLED# Initialize the camerapicam2 = Picamera2()picam2.preview_configuration.main.size = (1280,1280)picam2.preview_configuration.main.format="RGB888"picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# initialise output pinoutput = LED(14)# Load the YOLO modelmodel = YOLO("yolov8n.pt")# List of class IDs we want to detectobjects_to_detect = [0,73] # You can modify this listwhileTrue: # Capture a frame from the camera frame = picam2.capture_array() # Run object detection on the frame results = model(frame, imgsz =160) # Get the classes of detected objects detected_objects = results[0].boxes.cls.tolist() # Check if any of our specified objects are detected object_found =False forobj_idinobjects_to_detect: ifobj_idindetected_objects: object_found =True print(f"Detected object with ID{obj_id}!") # Control the Pin based on detection ifobject_found: output.on() # Turn on Pin print("Pin turned on!") else: output.off() # Turn off Pin print("Pi turned off!") # Display the frame with detection results annotated_frame = results[0].plot() cv2.imshow("Object Detection", annotated_frame) # Break the loop if 'q' is pressed ifcv2.waitKey(1) ==ord("q"): break# Clean upcv2.destroyAllWindows()
這段代碼與我們之前的腳本類似,但有一些添加。首先,我們導(dǎo)入控制樹莓派引腳所需的庫,并使用以下行設(shè)置引腳14:
fromgpiozeroimportLED# initialise output pinoutput = LED(14)
然后,我們定義要控制引腳的對象ID。如果其中任何一個出現(xiàn),則引腳將打開。現(xiàn)在它有0 - 人和73 - 書。你可以將其更改為任何你想要的ID,或者通過簡單地用逗號分隔添加另一個ID來添加更多:
# List of class IDs we want to detectobjects_to_detect= [0,73] # You can modify this list
然后,我們獲取檢測到的對象列表,并查看上一行中指定的任何ID是否與當(dāng)前幀中檢測到的內(nèi)容匹配:
# Get the classes of detected objects detected_objects = results[0].boxes.cls.tolist() # Check if any of our specified objects are detected object_found =False forobj_idinobjects_to_detect: ifobj_idindetected_objects: object_found =True print(f"Detected object with ID{obj_id}!")
最后,我們控制14號引腳,如果檢測到物體,就將其打開或關(guān)閉:
# Control the Pin based on detection ifobject_found: output.on() # Turn on Pin print("Pin turned on!") else: output.off() # Turn off Pin print("Pi turned off!")
至此,我們就可以隨心所欲地操作了。你可以像視頻指南中那樣控制電磁閥,也可以控制伺服電機(jī)或普通電機(jī)。
深入了解YOLO World
YOLO World是一個功能極其強(qiáng)大的物體識別模型,值得為其單獨開辟一個章節(jié)來介紹。通常,模型都是基于訓(xùn)練數(shù)據(jù)庫構(gòu)建的。YOLOv8使用的COCO庫經(jīng)過訓(xùn)練可以識別貓,因此它能夠識別貓。但它沒有經(jīng)過識別眼鏡的訓(xùn)練,所以無論你多么清晰地將眼鏡展示給攝像頭,它都無法識別。要讓YOLOv8識別眼鏡,通常的方法是重新訓(xùn)練它,這涉及到一個漫長且處理密集的過程(對于我們的小樹莓派來說負(fù)擔(dān)過重),你需要給眼鏡貼上標(biāo)簽并輸入眼鏡圖像。只有經(jīng)過整個過程,YOOLOv8才能檢測到眼鏡。
而YOLO World的卓越之處在于,它是一個開放詞匯模型,這意味著你可以描述或提示它要尋找什么,它會盡力去找到它。所以,你只需告訴它尋找眼鏡,正如你在右邊圖像中看到的,即使無需重新訓(xùn)練,它也能夠檢測到眼鏡。
不過,這并不是一個能識別所有物體的神奇法寶,它仍然有一套有限的訓(xùn)練數(shù)據(jù)可供使用,但簡而言之,它從整張圖像中學(xué)習(xí),而不僅僅是學(xué)習(xí)識別圖像中的某一個物體。因此,如果某個物體是照片中常見的物體,比如相機(jī)、眼鏡、筆、電池等,它很有可能能夠檢測到它們。對于不常見、不常被拍照的物體,比如算盤和蓋革計數(shù)器,它可能就無法識別了。

此外,它在檢測常見物體時也可能存在一些問題,例如,我們無法讓它檢測到畫筆或鑰匙。
要使用YOLO World,我們需要稍微修改一下腳本,以下是示例代碼:
importcv2from picamera2 import Picamera2from ultralytics import YOLO# Set up the camera with Picampicam2= Picamera2()picam2.preview_configuration.main.size = (1280,1280)picam2.preview_configuration.main.format ="RGB888"picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# Load our YOLOv8 modelmodel= YOLO("yolov8s-world.pt")# Define custom classesmodel.set_classes(["person","glasses"])whileTrue: # Capture a frame from the camera frame= picam2.capture_array() # Run YOLO model on the captured frame and store the results results= model(frame, imgsz =640) # Output the visual detection data, we will draw this on our camera preview window annotated_frame= results[0].plot() # Get inference time inference_time= results[0].speed['inference'] fps=1000/ inference_time # Convert to milliseconds text= f'FPS: {fps:.1f}' # Define font and position font= cv2.FONT_HERSHEY_SIMPLEX text_size= cv2.getTextSize(text, font,1,2)[0] text_x= annotated_frame.shape[1] - text_size[0] -10 #10pixels from the right text_y= text_size[1] +10 #10pixels from the top # Draw the text on the annotated frame cv2.putText(annotated_frame, text, (text_x, text_y), font,1, (255,255,255),2, cv2.LINE_AA) # Display the resulting frame cv2.imshow("Camera", annotated_frame) # Exit the program if q is pressed ifcv2.waitKey(1) == ord("q"): break# Close all windowscv2.destroyAllWindows()
注意:首次運行此腳本時,可能需要幾分鐘時間,因為YOLO World模型較大,并且需要下載額外的所需軟件包,總計約400 Mb。
目前,此腳本正在查找“眼鏡”和“人”這兩個詞,但我們可以通過修改這一行來立即更改查找內(nèi)容。你所需要做的就是將你要查找的物體放在引號內(nèi),并用逗號分隔:
# Define custom classesmodel.set_classes(["person","glasses","yellow lego man head"])
在上面的這行代碼中,我們使用了YOLO World的另一個很酷的功能,即通過描述而非單個單詞來提示它。正如你在右邊看到的,它正在檢測我們的黃色樂高人偶頭部。檢測結(jié)果有點時靈時不靈,它可能更多地識別黃色,但這是一個很酷的示例,展示了YOLO World可以實現(xiàn)的功能。
不過,關(guān)于YOLO World,有幾點需要注意。首先,它只會檢測你在上面那行代碼中指定的內(nèi)容。如果列表中沒有描述某個物體,它將無法識別。如果你刪除整行代碼,它會查找所有能查找的物體,行為更類似于YOLOv8。

YOLO World也只有三種尺寸——小、中和大。上面的示例腳本使用的是小尺寸,你可以通過將“s”替換為“m”或“l(fā)”來替換為中等或大型模型。如果你想要大型模型,可以這樣寫:
# Load our YOLOv8 modelmodel= YOLO("yolov8l-world.pt")
此外,YOLO World不能轉(zhuǎn)換為NCNN格式。這有點遺憾,但我們至少仍然可以降低分辨率來提高性能。而且你可能需要這樣做,因為它的運行速度會比默認(rèn)的YOLOv8模型慢很多。
總而言之,在你的項目中嘗試一下YOLO World吧。根據(jù)提示檢測自定義物體或物體的功能提供了很大的靈活性和定制性。即便只是為了好玩,也值得一試。
后續(xù)方向?
至此,我們應(yīng)該已經(jīng)在樹莓派上運行了YOLO物體檢測,無論是YOLOv8、v5還是YOLO World。不過,本指南只是一個起點,我們希望你能夠開始將計算機(jī)視覺添加到你的項目中。但最重要的是,我們希望你學(xué)到了新知識,并在這個過程中獲得了樂趣。
如果你正在尋找一些擴(kuò)展工作或探索方向,可以看看results變量內(nèi)部,你可以找到很多很酷的東西,比如正在繪制的方框的xy坐標(biāo)。很有可能從中找到被檢測物體的中心,并連接伺服電機(jī)來跟蹤該物體。
如果你希望長時間運行此系統(tǒng),它將在MicroSD卡上進(jìn)行大量讀寫操作,因此設(shè)置NVME SDD以提高耐用性可能是一個有益的舉措。我們有一篇很棒的初學(xué)者指南,介紹了如何操作!
https://core-electronics.com.au/guides/how-to-add-an-ssd-to-your-raspberry-pi-5-with-the-m.2-hat/
如果你想深入了解YOLO,可以查看Ultralytics文檔頁面。他們有一系列其他很酷的模型可供探索,而且因為我們已經(jīng)設(shè)置了使用其模型所需的基礎(chǔ)架構(gòu),所以只需復(fù)制粘貼你在那里找到的演示代碼即可!
https://docs.ultralytics.com/zh/
致謝
首先,我們要感謝OpenCV和COCO庫的眾多貢獻(xiàn)者、開發(fā)者和維護(hù)者。現(xiàn)代計算機(jī)視覺領(lǐng)域的許多成果都建立在他們的努力之上。
我們還要感謝Joseph Redmon和Ultralytics開發(fā)并維護(hù)了這里使用的許多YOLO模型。這些模型功能強(qiáng)大,能夠在樹莓派等低功耗硬件上運行,這絕非易事!
附錄:使用網(wǎng)絡(luò)攝像頭
本指南是基于使用插入CSI端口的樹莓派攝像頭模塊編寫的。不過,也可以使用USB網(wǎng)絡(luò)攝像頭。本指南中演示的代碼應(yīng)該能夠直接與大多數(shù)網(wǎng)絡(luò)攝像頭配合使用,但存在一些問題。樹莓派上的網(wǎng)絡(luò)攝像頭存在很大的變數(shù)(這就是我們在本指南中選擇攝像頭模塊的原因),但常見的問題之一是色彩不匹配。如果網(wǎng)絡(luò)攝像頭畫面中的顏色看起來混合或色調(diào)不正確,請嘗試以下代碼:
importcv2from picamera2 import Picamera2from ultralytics import YOLO# Initialize the Picamera2picam2= Picamera2()picam2.preview_configuration.main.size = (1280,1280)picam2.preview_configuration.main.format ="BGR888" # Change to BGR888picam2.preview_configuration.align()picam2.configure("preview")picam2.start()# Load the YOLOv8 modelmodel= YOLO("yolov8s-worldv2.pt")model.set_classes(["spray bottle"])whileTrue: # Capture frame-by-frame frame= picam2.capture_array() # Convert BGR to RGB frame_rgb= cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # Run YOLOv8 inference on the frame, specifying the desired size results= model(frame_rgb, imgsz=320) # Visualize the results on the frame annotated_frame= results[0].plot() # Get inference time inference_time= results[0].speed['inference'] fps=1000/ inference_time # Convert to milliseconds text= f'FPS: {fps:.1f}' # Define font and position font= cv2.FONT_HERSHEY_SIMPLEX text_size= cv2.getTextSize(text, font,1,2)[0] text_x= annotated_frame.shape[1] - text_size[0] -10 #10pixels from the right text_y= text_size[1] +10 #10pixels from the top # Draw the text on the annotated frame cv2.putText(annotated_frame, text, (text_x, text_y), font,1, (255,255,255),2, cv2.LINE_AA) # Display the resulting frame cv2.imshow("Camera", annotated_frame) # Break the loop if 'q' is pressed ifcv2.waitKey(1) == ord("q"): break# Close windowscv2.destroyAllWindows()
雖然不能保證這段代碼一定有效,但對于大多數(shù)網(wǎng)絡(luò)攝像頭品牌來說應(yīng)該是可行的。如果有效,你可以根據(jù)指南中的說明根據(jù)需要修改此代碼。
原文地址:
https://core-electronics.com.au/guides/raspberry-pi/getting-started-with-yolo-object-and-animal-recognition-on-the-raspberry-pi/
-
計算機(jī)視覺
+關(guān)注
關(guān)注
9文章
1709瀏覽量
46777 -
樹莓派
+關(guān)注
關(guān)注
121文章
2007瀏覽量
107463
發(fā)布評論請先 登錄
「EDATEC」如何在樹莓派4上安裝64位操作系統(tǒng)

完整指南:如何使用樹莓派5、Hailo AI Hat、YOLO、Docker進(jìn)行自定義數(shù)據(jù)集訓(xùn)練?

樹莓派5,Raspberry Pi 5 評測
樹莓派權(quán)威用戶指南
樹莓派做人臉識別
樹莓派入門套裝
如何快速入門樹莓派
比較全的樹莓派入門介紹
樹莓派入門教程之新手使用樹莓派做系統(tǒng)的教程資料說明

樹莓派簡單入門

在樹莓派上部署YOLOv5進(jìn)行動物目標(biāo)檢測的完整流程
樹莓派分類器:用樹莓派識別不同型號的樹莓派!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論