 完整指南:如何使用樹莓派5、Hailo AI Hat、YOLO、Docker進行自定義數據集訓練?
完整指南:如何使用樹莓派5、Hailo AI Hat、YOLO、Docker進行自定義數據集訓練?

今天,我將展示如何使用令人印象深刻的Hailo AI Hat在樹莓派5上訓練、編譯和部署自定義模型。注意:文章內的鏈接可能需要科學上網。
Hailo AI Hat
根據你的設置,在樹莓派5的CPU上運行YOLO每秒可以提供1.5到8幀(FPS)。盡管對于這樣一個小設備來說,這一性能已經相當出色,但對于許多實時應用來說,這還不夠快。如果你需要更高的性能,就需要外部硬件。目前,Hailo為樹莓派5設計的AI Hat是一個極佳的選擇。
Hailo是一家專注于開發人工智能硬件的芯片制造商。在這個故事中,我感興趣的是他們專門為樹莓派5打造的AI Hat+設備:

我的樹莓派 5帶AI Hat+ Hailo8,還有Camera Noir v2
這款AI Hat有兩個版本,一個搭載Hailo-8芯片,據說可以提供26 TOPS(每秒萬億次運算),另一個搭載Hailo-8L芯片,提供13 TOPS。
在這個故事中,我將使用搭載Hailo8架構的AI Hat版本。
為什么選擇Docker?
準備好下載并安裝千兆字節的第三方庫吧。我們將使用Docker容器作為隔離環境,來配置和安裝所需的一切,而無需修改主機。
也就是說,我們需要設置兩個不同的Docker容器:
YOLOv5容器:這個容器有兩個任務。首先,我們將使用自定義數據集訓練模型。其次,我們將模型轉換為ONNX格式。
Hailo容器:這個容器用于將ONNX文件轉換為Hailo的HEF格式。
嘗試使用同一個Docker容器來完成這兩項任務,會因為庫(如numpy)的沖突而帶來不必要的麻煩。相信我,使用Docker來做它設計的事情,可以節省你的時間!
第一個Dockerfile由Hailo提供。第二個Dockerfile將在這個故事的后面部分提供。
本例中使用的數據集
我將使用Tech Zizou標記口罩數據集。你可以在這里找到它。
nature中發現的Tech Zizou標簽口罩數據
從Kaggle下載文件,并按照以下方式解壓:
mkdirsourceunzip -qq archive.zip -dsource/
source/obj中的文件結構不符合YOLO的預期。希望下面的代碼能解決這個問題:
importos, shutil, random# preparing the folder structurefull_data_path ='source/obj/'extension_allowed ='.jpg'split_percentage =90images_path ='datasets/images/'ifos.path.exists(images_path): shutil.rmtree(images_path)os.mkdir(images_path)labels_path ='datasets/labels/'ifos.path.exists(labels_path): shutil.rmtree(labels_path)os.mkdir(labels_path)training_images_path = images_path +'train/'validation_images_path = images_path +'val/'training_labels_path = labels_path +'train/'validation_labels_path = labels_path +'val/'os.mkdir(training_images_path)os.mkdir(validation_images_path)os.mkdir(training_labels_path)os.mkdir(validation_labels_path)files = []ext_len =len(extension_allowed)forr, d, f in os.walk(full_data_path): forfile in f: iffile.endswith(extension_allowed): strip = file[0:len(file) - ext_len] files.append(strip)random.shuffle(files)size =len(files) split =int(split_percentage * size /100)print("copying training data")fori inrange(split): strip = files[i] image_file = strip + extension_allowed src_image = full_data_path + image_file shutil.copy(src_image, training_images_path) annotation_file = strip +'.txt' src_label = full_data_path + annotation_file shutil.copy(src_label, training_labels_path)print("copying validation data")fori inrange(split, size): strip = files[i] image_file = strip + extension_allowed src_image = full_data_path + image_file shutil.copy(src_image, validation_images_path) annotation_file = strip +'.txt' src_label = full_data_path + annotation_file shutil.copy(src_label, validation_labels_path)print("finished")
這段代碼假設數據在source/obj/文件夾中,并將輸出數據放入datasets文件夾中。將文件命名為tidy_data.py,并按照以下方式運行:
mkdirdatasetspython tidy_data.py
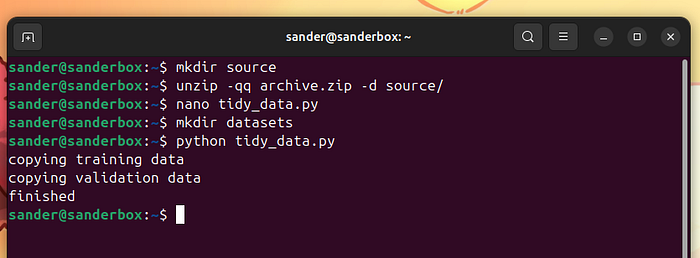
準備數據
我們最終得到以下結構:
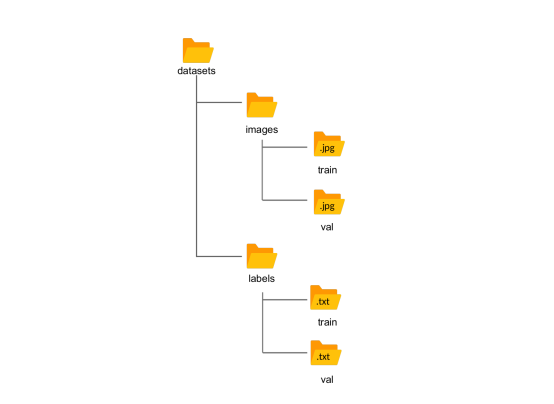
Yolo預期的文件夾結構
這里有一些需要注意的事項:
這個數據集只有兩個類別:戴口罩和不戴口罩。
只有1359張訓練圖像和151張驗證圖像。
訓練數據量很小。僅使用這些數據從頭開始訓練模型將產生非常差的模型,這種情況稱為過擬合。
我們在這里不深入探討建模細節。無論如何,為了簡化事情,我們將使用一種稱為遷移學習的技術,即在訓練開始前,將預訓練的權重輸入到模型中。特別是,我們將使用Ultralytics提供的使用COCO數據庫訓練的權重。
YOLOv5
Ultralytics的最新YOLO版本是11。
它比YOLOv5更快、更準確。但這并不意味著YOLOv5已經過時。實際上,Ultralytics明確表示,在某些特定場景下,YOLOv5是更優的選擇。
在這個故事中,我有充分的理由避免使用YOLO 11:Hailo堆棧目前還不支持YOLO 11。
如果你真的不想使用YOLOv5,你可以輕松地將這個故事改編為使用YOLO 8。
Linux,朋友,Linux!
這個故事使用Linux,具體來說是Ubuntu LTS。
對于人工智能開發,我推薦使用Ubuntu 20.04或22.04。LTS一路相伴!
任務簡報
整個過程由三個簡單的步驟組成:
步驟1:訓練自定義模型:在這一步中,我們使用自定義數據加上預訓練的YOLOv5權重來訓練模型,以執行我們的檢測任務(在我們的例子中,是檢測戴或不戴口罩的臉)。這一步的輸出是一個pytorchbest.pt文件。這個文件只包含我們模型的參數值。
步驟2:將best.pt轉換為ONNX格式:ONNX是一種用于機器學習模型的開放格式。這一步的輸出是一個best.onnx文件。
步驟3:將best.onnx轉換為HEF格式:Hailo可執行格式是一種專門為在Hailo芯片上運行而高度優化的模型。在這一步中,我們將ONNX文件轉換為HEF文件。
一旦我們有了.hef格式的模型,我們只需將其部署到樹莓派上并進行測試。
步驟1:訓練你的自定義數據
為Hailo架構訓練模型并沒有什么新奇之處。你可以像往常一樣訓練你的模型。
如果你已經有了模型,就跳過這一步。否則,請繼續閱讀。
首先,如果系統中還沒有安裝Docker,請安裝它。
同時,安裝NVIDIA Container Toolkit。
Hailo在GitHub上共享了一個包含所需資源的倉庫。克隆它:
gitclonehttps://github.com/hailo-ai/hailo_model_zoo
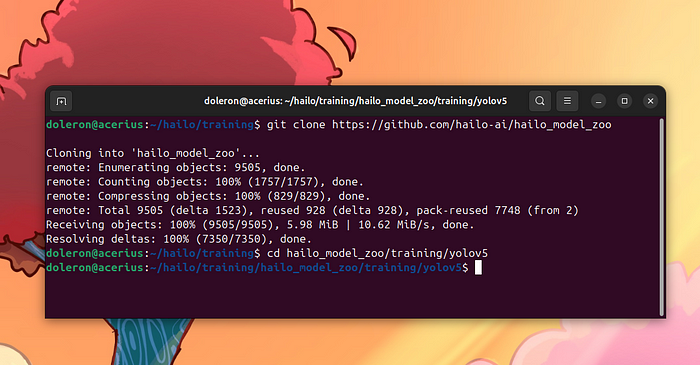
克隆 the hailo_model_zoo 倉庫
我們在hailo_model_zoo/training/yolov5文件夾中尋找YOLOv5訓練的Dockerfile。移動到這個文件夾,并使用以下命令構建鏡像:
cdhailo_model_zoo/training/yolov5docker build -t yolov5:v0 .
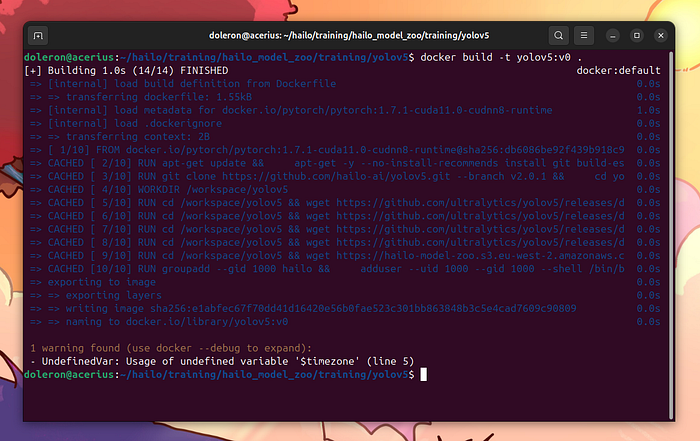
構建鏡像
現在,運行容器:
docker run-it--name custom_training--gpus all--ipc=host-v/home/doleron/hailo/shared:/home/hailo/shared yolov5:v0
簡而言之,-it標志要求Docker以交互模式運行容器,這對于后續執行命令是必要的。
參數-v /home/doleron/hailo/shared:/home/hailo/shared將我機器上的/home/doleron/hailo/shared文件夾映射到容器機器上的/home/hailo/shared文件夾。
--gpus all指示Docker使用主機上可用的任何GPU。
現在,我們在容器內部。我們可以檢查/home/hailo/shared的內容,以確保我們的數據集文件在那里:
ls/home/hailo/shared/ -als
使用交互模式運行容器
這個容器沒有nano編輯器。除非你是Vim用戶,否則我建議按照以下方式安裝nano:
sudoapt updatesudo apt install nano -y
安裝完nano后,我們可以繼續并設置我們的訓練。將datasets文件夾復制到workspace文件夾中:
cp-r /home/hailo/shared/datasets ..
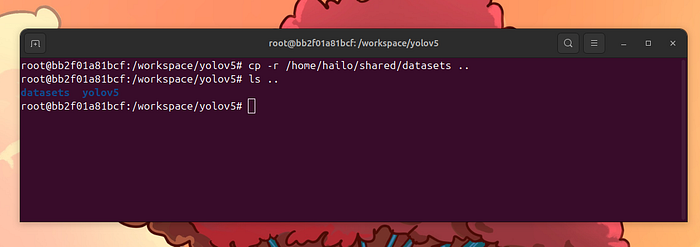
現在,編寫data/dataset.yaml文件:
nano data/dataset.yaml
這是data/dataset.yaml的內容:
train: ../datasets/images/trainval: ../datasets/images/valnc: 2names: 0:'using mask' 1:'without mask'
按control-x,y,然后Enter保存文件并退出nano。
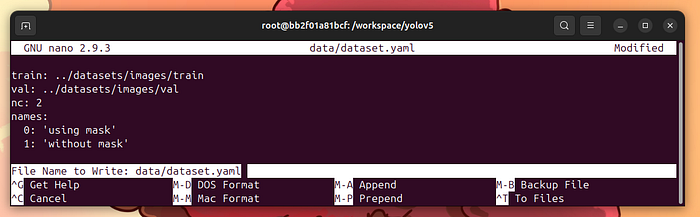
創建data/dataset.yaml文件
是時候訓練我們的模型了!確保你在/workspace/yolov5文件夾中,并輸入:
python train.py--img640--batch16--epochs100--datadataset.yaml--weightsyolov5s.pt
如果你遇到類似RuntimeError: CUDA out of memory的錯誤,嘗試將--batch 16減少到--batch 8或更少。
我希望你熟悉基本的機器學習術語:batches、epoch等。你可以按照這份指南調整這些超參數。
https://docs.ultralytics.com/zh/guides/hyperparameter-tuning/
如果一切順利,你的GPU將開始全力運轉:
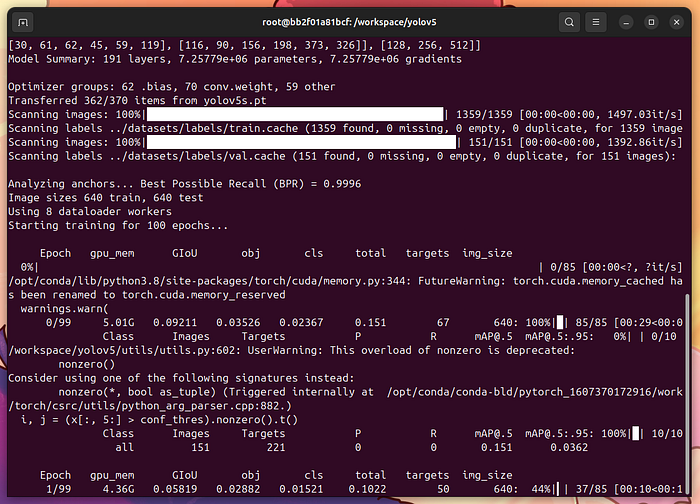
我的RTX 4070在燃燒!
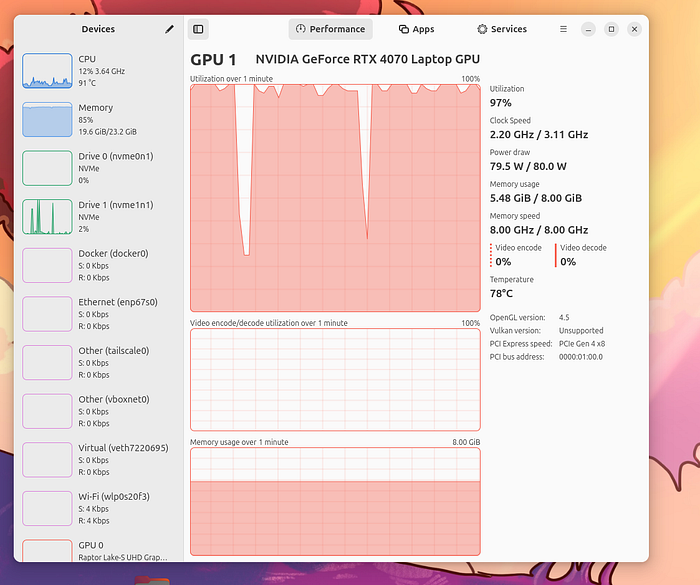
保持溫度在81°C以下,你就沒事。
在我的情況下,這次訓練大約用了40分鐘。
作為參考,使用另一臺配備GTX 1080的機器大約需要2小時。
最后,你會得到類似這樣的結果:
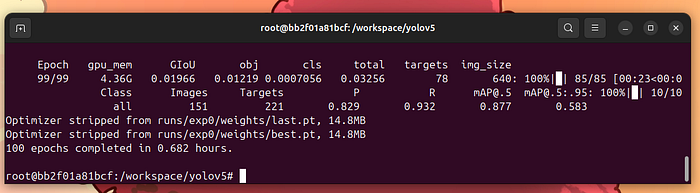
訓練結束
這意味著訓練已經完成。我們可以在runs/exp0文件夾中檢查結果。將這個文件夾復制到共享區域:
mkdir/home/hailo/shared/runscp-r runs/exp0 /home/hailo/shared/runs/
你最終會得到一個這樣的文件夾:
訓練結果文件夾
我們可以檢查訓練結果:
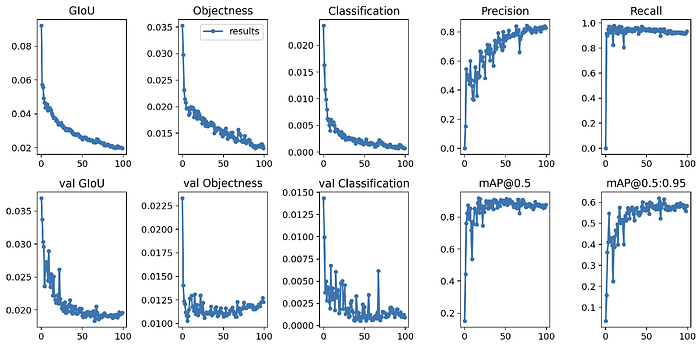
訓練結果
比較第一行圖表(訓練性能)和第二行圖表(驗證性能),我們發現模型沒有過擬合。
值得一提的是,使用不同的驗證實例集是評估模型質量的首要要求。
可以使用常規的機器學習工程技術來改進模型,以達到更高的性能。然而,這并不是我們現在的重點。
記住:我們的重點是學習如何在樹莓派/Hailo AI Hat上使用這樣的模型。
讓我們進入下一步!
步驟2:將best.pt文件轉換為ONNX
回到容器中,最好的權重文件是runs/exp0/weights/best.pt。我們可以使用以下命令將其轉換為ONNX:
python3 models/export.py --weights runs/exp0/weights/best.pt --img 640
注意,best.onnx已經生成:
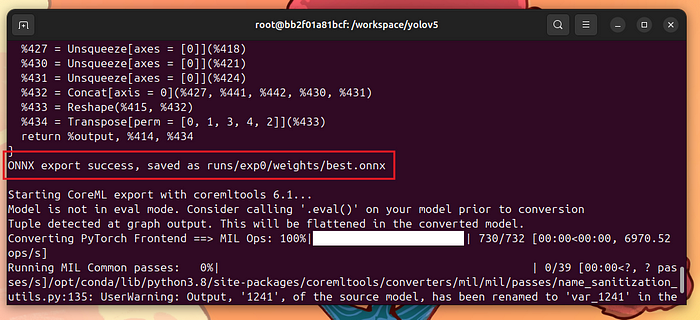
將best.pt轉換成best.onnx
將best.onnx復制到主機機器上:
cpruns/exp0/weights/best.onnx /home/hailo/shared/
我們已經完成了這個容器的任務。如果你想退出,就退出吧。
步驟3:將ONNX轉換為HEF
本教程中最簡單的部分是使用YOLOv5訓練自定義模型并將結果文件轉換為ONNX。現在,是時候將ONNX文件編譯成專有的Hailo可執行格式(HEF)了。
在任何地方啟動一個新的終端,并編寫這個Dockerfile:
# using a CUDA supported Ubuntu 22.04 image as baseFROM nvidia/cuda:12.4.1-cudnn-runtime-ubuntu22.04 AS base_cudaENV DEBIAN_FRONTEND=noninteractiveENV PYTHONDONTWRITEBYTECODE=1ENV PYTHONUNBUFFERED=1RUN apt-get update && \ apt-get install -y \ # see: the Hailo DFC user guide python3.10 \ python3.10-dev \ python3.10-venv \ python3.10-distutils \ python3-pip \ python3-tk \ graphviz \ libgraphviz-dev \ libgl1-mesa-glx \ # utilities python-is-python3 \ build-essential \ sudo \ curl \ git \ nano && \ # clean up rm-rf /var/lib/apt/lists/*# update pipRUN python3 -m pip install --upgrade pip setuptools wheelWORKDIR /workspaceARG user=hailoARG group=hailoARG uid=1000ARG gid=1000RUN groupadd --gid$gid$group&& \ adduser --uid$uid--gid$gid--shell /bin/bash --disabled-password --gecos""$user&& \ chmodu+w /etc/sudoers &&echo"$userALL=(ALL) NOPASSWD: ALL">> /etc/sudoers &&chmod-w /etc/sudoers && \ chown-R$user:$group/workspace
將其保存為Dockerfile,并使用以下命令構建鏡像:
dockerbuild -t hailo_compiler:v0 .
一旦鏡像構建完成,按照以下方式啟動容器:
docker run-it--name compile_onnx_file--gpus all--ipc=host-v/home/doleron/hailo/shared:/home/hailo/shared hailo_compiler:v0
這個命令會給我們一個容器機器內的命令提示符:
運行新Docker容器
這看起來像是似曾相識。我們在上一節中剛剛執行了類似的步驟。那又怎樣?
關鍵在于:我們正在掛載第二個隔離容器來安裝Hailo的東西,而不用擔心與其他庫的沖突。特別是,我們需要安裝三個包:
Hailort:Hailo運行時平臺
Hailort Wheel:Hailort Python庫
Hailo DFC:Hailo數據流編譯器
FOSS社區習慣了開源生態系統。在這個上下文中,一切都可以從公開可用的倉庫中安裝。然而,Hailo在人工智能市場這個充滿挑戰和野性的商業世界中運作。因此,他們的軟件還不是開源的。希望Hailo的軟件至少是免費的。
要使用Hailo的東西,我們必須在Hailo Network上創建一個賬戶.
訪問軟件下載頁面,并下載三個包:
hailort_4.21.0_amd64.deb
hailort-4.21.0-cp310-cp310-linux_x86_64.whl
hailo_dataflow_compiler-3.31.0-py3-none-linux_x86_64.whl
Hailo 網絡下載頁面
將它們保存在共享文件夾的某個地方,并將它們復制到容器中:
cp/home/hailo/shared/libs/* .
在安裝軟件之前,為Python創建一個虛擬環境并激活它:
python -m venv .venvsource.venv/bin/activate
然后,安裝Hailo RT包:
dpkg-i ./hailort_4.21.0_amd64.deb
安裝Hailo RT
接下來,安裝Hailo RT Python API:
pipinstall ./hailort-4.21.0-cp310-cp310-linux_x86_64.whl
現在,安裝Hailo DFC:
pipinstall ./hailo_dataflow_compiler-3.31.0-py3-none-linux_x86_64.whl
注意,包版本表示在這個故事編寫時Hailo軟件的當前階段。它們必須與容器Python版本(3.10)匹配。
我們還沒完成。我們必須克隆并安裝hailo_model_zoo:
gitclonehttps://github.com/hailo-ai/hailo_model_zoo.gitcdhailo_model_zoopip install -e .
檢查hailomz是否正確設置:
hailomz--version
安裝Hailo內容
堅持住!最困難的部分現在來了:將best.onnx文件編譯成best.hef文件。
要使這工作,我們需要將hailo_model_zoo/cfg/postprocess_config/yolov5s_nms_config.json中的類別數更改為2:
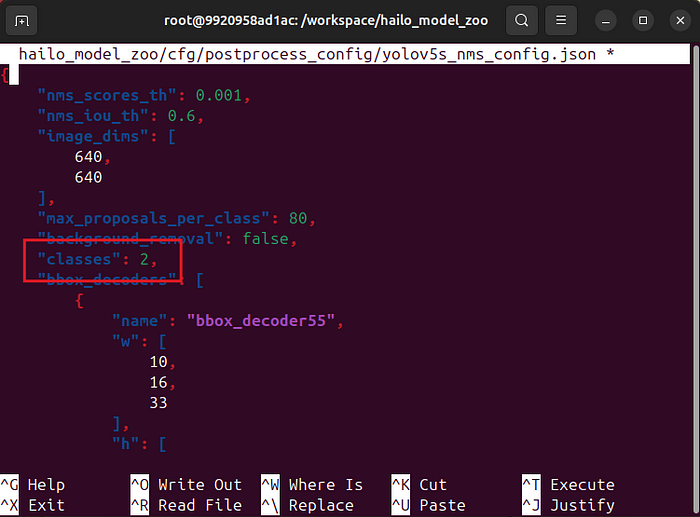
請注意,在hailo_model_zoo倉庫中有一個hailo_model_zoo文件夾!
在開始編譯器之前,設置USER環境變量:
exportUSER=hailo
現在,按照以下方式調用hailomz:
hailomz compile--ckpt/home/hailo/shared/best.onnx--calib-path/home/hailo/shared/datasets/images/train/--yaml hailo_model_zoo/cfg/networks/yolov5s.yaml
慢慢來。等待10分鐘,讓hailomz優化并編譯你的模型:
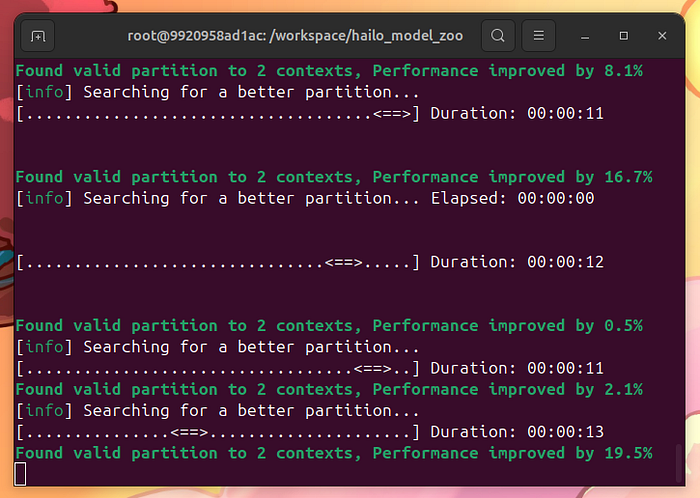
用hailomz編譯模型
如果一切順利,你會得到以下消息:
HEF 編譯
注意,將ONNX轉換為HEF包括一個新元素:校準圖像。校準圖像是Hailo編譯器用于優化模型的特性空間的示例。我在這里沒有找到任何文檔,但一旦hailomz編譯器警告我使用超過1024個實例,使用相同的訓練集似乎就能工作。
將yolov5s.hef復制到共享區域:
cpyolov5s.hef /home/hailo/shared/
最困難的部分已經完成。我們可以退出容器實例。
在樹莓派5上部署模型
將yolov5s.hef復制到樹莓派上。
在樹莓派上運行Hailo應用程序的細節超出了這個故事的范圍。
在樹莓派上,運行以下命令:
gitclonehttps://github.com/hailo-ai/hailo-rpi5-examples.gitcdhailo-rpi5-examplessourcesetup_env.shpython basic_pipelines/detection.py --labels-json custom.json --hef-path /home/pi/Documents/yolov5s.hef --input /home/pi/Documents/videoplayback.mp4 -f
其中custom.json是:
{ "detection_threshold":0.5, "max_boxes":200, "labels":[ "unlabeled", "with mask", "without mask" ]}
使用這個視頻的結果是:
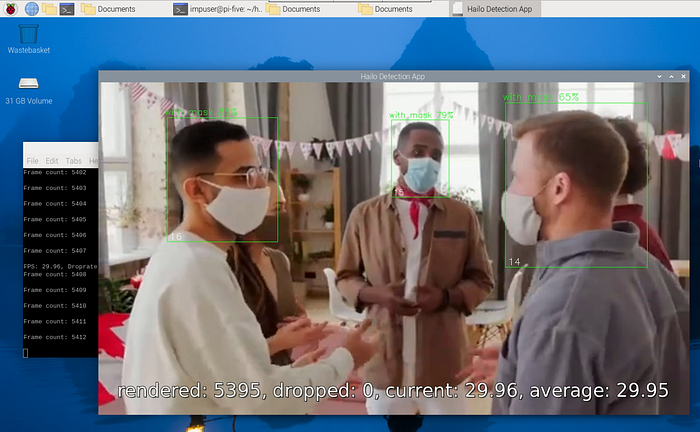
即使在高清分辨率下,對象檢測也能達到30 fps。這是令人印象深刻的!您可以探索其他輸入類型,例如:
python basic_pipelines/detection.py --labels-json custom.json --hef-path /home/pi/Documents/yolov5s.hef --input usb -f
或者
python basic_pipelines/detection.py --labels-json custom.json --hef-path /home/pi/Documents/yolov5s.hef --input rpi -f
查看Hailo RPI示例倉庫以獲取更多參數和用法示例。
https://github.com/hailo-ai/hailo-rpi5-examples
使用其他YOLO版本
值得注意的是,在撰寫本文時,Hailo模型編譯器僅與YOLO3、YOLO4、YOLOv5、YOLOv8和YOLOX進行了測試。
查看Hailo開發者專區,了解Hailo編譯器何時將支持更早的YOLO版本。
結論
我們展示了使用Hailo AI Hat在樹莓派5上訓練自定義數據集、編譯和部署模型的完整步驟序列。
我期待著弄清楚AI Hat能做什么。但這是另一個故事的話題了。
原文地址:
https://pub.towardsai.net/custom-dataset-with-hailo-ai-hat-yolo-raspberry-pi-5-and-docker-0d88ef5eb70f
-
AI
+關注
關注
88文章
34781瀏覽量
277117 -
樹莓派
+關注
關注
121文章
1978瀏覽量
107216 -
Docker
+關注
關注
0文章
515瀏覽量
12857
發布評論請先 登錄
基于YOLOv8實現自定義姿態評估模型訓練

MCC基于樹莓派的HAT模塊
如何在TensorFlow2里使用Keras API創建一個自定義CNN網絡?
自定義視圖組件教程案例
自定義算子開發
NVIDIA 加快企業自定義生成式 AI 模型開發







 工商網監
工商網監
評論