 企業和個人基于業務知識和代碼庫增強的大模型生成代碼實踐
企業和個人基于業務知識和代碼庫增強的大模型生成代碼實踐

1.源起
李明是今年剛加入某互聯網公司的研發新人,滿懷期待地開始了他的職業生涯。然而,短短兩周后,他的熱情就被現實澆了一盆冷水。
第一周: 當他第一次接手需求時,mentor只是簡單交代了幾句:“這個功能之前做過類似的,你參考下歷史代碼。”可當他打開代碼倉庫,卻發現注釋寥寥,變量名像密碼一樣難懂,更找不到任何需求文檔。他硬著頭皮修改,結果上線后引發了線上故障——原來有個隱藏的業務規則,只有老員工才知道。
第二周: 測試同事小張跑來問:“這次改動會影響訂單狀態流轉嗎?”李明愣住了,他根本不知道系統里還有這樣一條鏈路。小張無奈地說:“上次變更時沒留文檔,現在只能靠猜。”
第三周: 產品經理突然要求緊急修復一個“歷史遺留問題”,但翻遍Confluence,只找到三年前零散的會議記錄。運維團隊更頭疼:每天要花大量時間重復解答“這個報錯是什么意思”“服務依賴誰”這類問題。
某天深夜加班時,李明對著屏幕發呆:
?為什么每次變更都像在挖雷?
?為什么系統做這么久,代碼煙囪式設計越來越多,知識卻只維護在老員工的腦子里?新人學習成本為什么這么大?
?如果有AI能直接告訴我這段代碼對應什么需求,或者自動生成業務邏輯說明該多好…
這時,他想如果利用大模型將——它似乎能關聯代碼、需求文檔和運維手冊。一個念頭閃過:或許,打破這座“代碼迷宮”的鑰匙,就藏在AI與知識庫的結合中?
2.解題思路
連續幾周的挫折讓李明意識到,這些問題不是他一個人能解決的。他決定主動尋找解決方案。
深夜的辦公室里,李明盯著屏幕上復雜的代碼,突然萌生了一個想法:如果能把這些零散的知識點都串聯起來,是不是就能解決現在的問題?
第一次嘗試: 他想起mentor提到過的大模型技術。抱著試試看的心態,他寫了個簡單的腳本,把公司文檔庫里的需求文檔和代碼提交記錄做了關聯索引。雖然粗糙,但至少能通過關鍵詞搜索到相關文檔了。他又想如果把這種基于索引的代碼結果,放到大模型訓練會碰撞出什么火花呢?
初步驗證: 當李明訓訓練好一個基本的智能體后,當產品經理再次詢問某個歷史功能時,李明腿間了這個智能體,產品經理查到了兩年前的需求,并且還可以做解釋。雖然不夠完善,但比之前漫無目的地翻找強多了。
系統升級: 受到初步成果的鼓舞,李明開始思考更系統的解決方案。他梳理出三個關鍵點:
1.基礎查詢:讓新人產品和研發能快速找到常見業務問題的標準答案
2.知識關聯:把代碼變更和需求文檔、故障記錄打通,做針對于需求的知識庫
3.智能提示:在新需求開發時自動關聯歷史經驗
實際應用: 在開發一個新功能時,李明嘗試著把相關歷史需求、代碼和運維記錄都整理到一起。他發現,這樣不僅自己理解得更透徹,組內新來的實習生同學都可以用這個快速上手
?
?
?
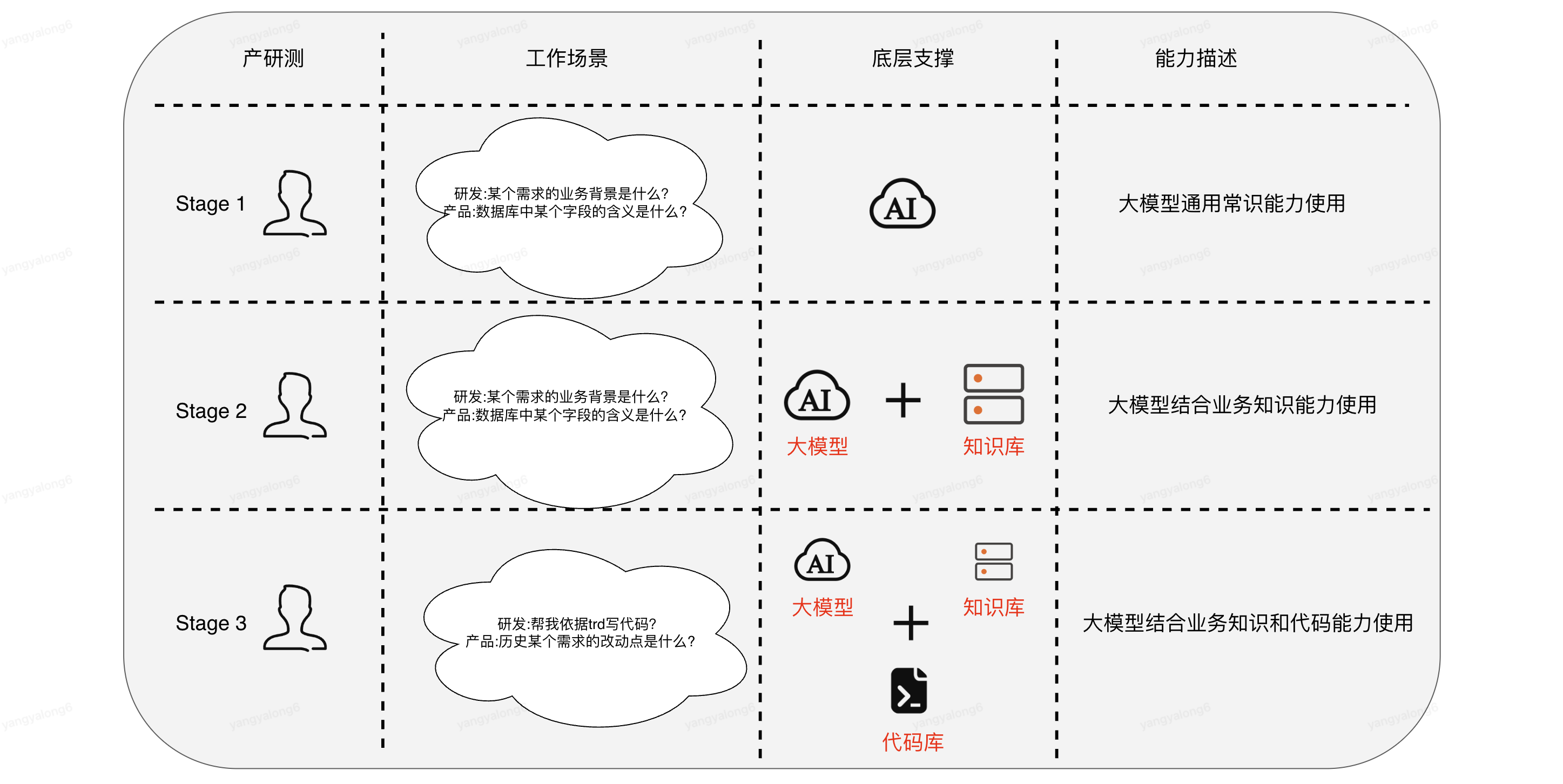
3.大模型應用STAGE-1
此階段不贅述,作為一個基本常識,能夠運用基本的提示詞對大模型提問一些常見的工作問題
4.大模型應用STAGE-2
4.1架構圖
?
?
4.2技術路線
ps:此處以DIFY(大模型工作流平臺)為例,對于在企業內部的小伙伴要注意權限敏感問題,強烈建議使用各自的內部的大模型平臺工具 此處技術路線參考5.2,與5.2類似,此處不贅述
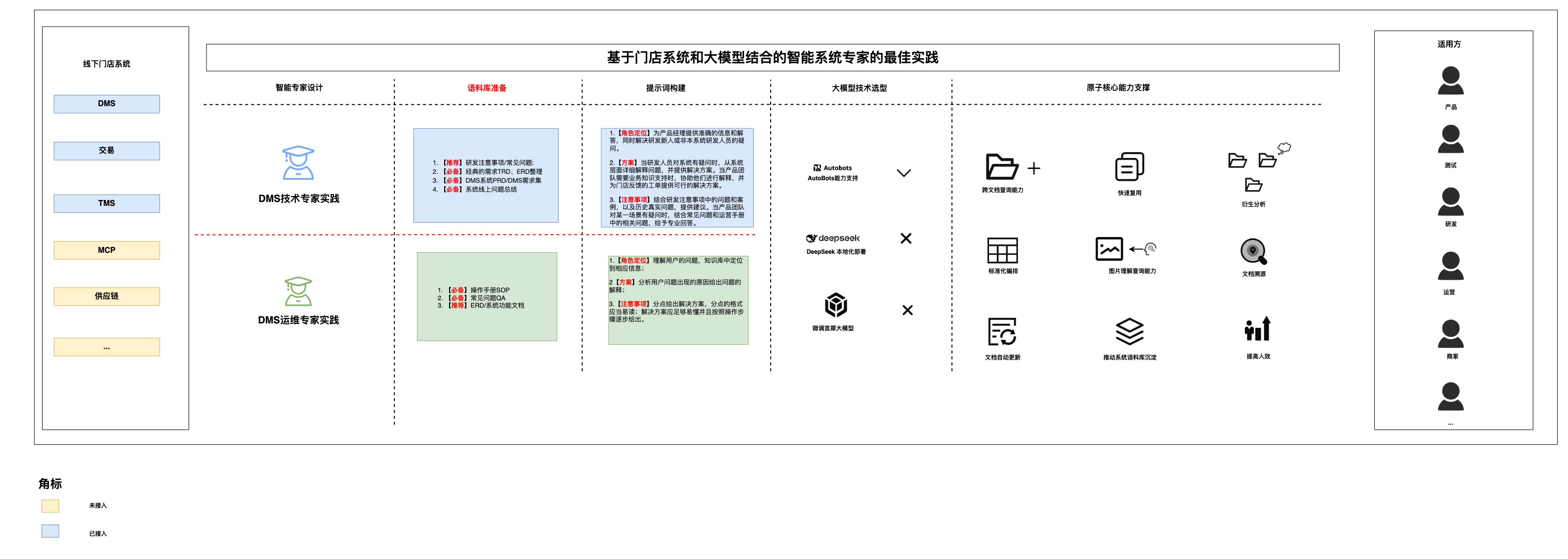
4.3 結果展示-DMS技術專家實踐
4.3.1推薦語料庫
示例文檔添加 擴充文檔作用 細化 給出具體范例
1.【必備】經典的需求TRD、ERD整理
ERD文檔: 系統文檔的梳理可以有助于模型快速熟悉系統,并且可以解釋業務方面的知識
TRD文檔: 模型可以結合TRD(技術文檔),可以從技術角度提出專業意見,并且對系統/技術知識進行解答
系統梳理文檔: 可以從數據庫設計/系統設計/系統業務功能分享等角度,對系統文檔進行補充
1.【推薦】研發注意事項/常見問題:
技術專家可以結合常見問題的文檔,給出專業的解釋,并且結合歷史案例,預防事故的發生。
例如:
(1)歷史出現的線上問題,避免線上問題的再次發生
(2)研發/產品整理的Q/A文檔,協助產研快速定位并且解決問題
1.【必備】DMS系統PRD/DMS需求集
通過PRD文檔,可以幫助模型理解業務,并且結合具體需求,對需求的特定問題進行解答
1.【必備】系統常見的坑合集
通過常見系統問題,例如上線前需要預熱,redis共用一套風險,某些MQ流量大消費可能時常積壓,
4.3.2推薦提示詞
【實踐】1.問題解答:為產品經理提供準確的信息和解答,處理他們關于門店工單或系統功能的問題,同時解決研發新人或非本系統研發人員的疑問。
2.方案指引:當研發人員對系統有疑問時,從系統層面詳細解釋問題,并提供解決方案。當產品團隊需要業務知識支持時,協助他們進行解釋,并為門店反饋的工單提供可行的解決方案。
3.系統的詳細介紹:針對任何人提出的系統設計問題,結合ERD、TRD等文檔,詳細解釋數據庫設計、系統設計或業務流程設計,并通過可能的使用場景進行說明。
4.注意事項:在研發提出注意事項或建議時,結合研發注意事項中的問題和案例,以及歷史真實問題,提供建議。當產品團隊對某一場景有疑問時,結合常見問題和運營手冊中的相關問題,給予專業回答。
4.3.3范例
?

?
?
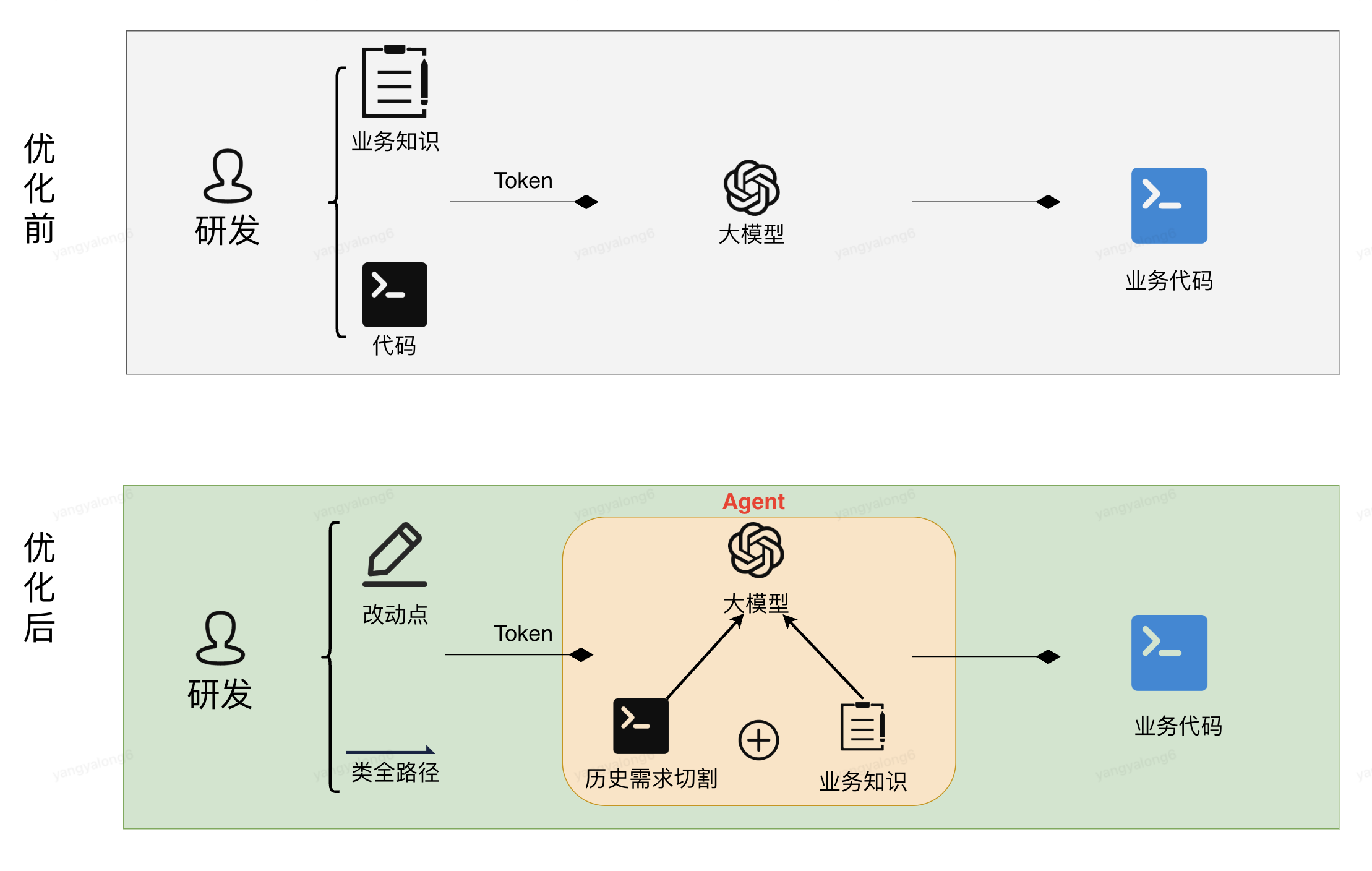
5.大模型應用STAGE-3
5.1架構圖
?
?
?
5.2實踐路線
5.2.1 步驟1:綁定需求名稱和代碼之間的關聯關系
1. 通過 Issue/PR 編號關聯代碼
場景:如果代碼提交時在 Commit Message 中引用了 Issue/PR 編號(如 Fix #123),可以通過以下步驟獲取關聯代碼:
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/repos/{owner}/{repo}/issues/{issue_number}"
?返回的 JSON 中會包含 pull_request 字段(如果是 PR)或 timeline_url(通過事件查詢關聯提交)。
Step 2: 使用 GitHub Commit API 獲取具體代碼變更:
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/repos/{owner}/{repo}/commits/{commit_sha}"
方法2. 通過 Search API 直接搜索代碼
場景:如果代碼文件或提交信息中明確包含需求標識(如 [REQ-123]):
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/search/commits?q=repo:{owner}/{repo}+[REQ-123]+in:message"
搜索代碼文件內容:
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/search/code?q=repo:{owner}/{repo}+REQ-123+in:file"
?注:需啟用 GitHub Advanced Security 才支持代碼內容搜索。
3. 通過 Pull Request 獲取關聯代碼
場景:如果需求通過 PR 實現,直接獲取 PR 的代碼變更:
?Step 1: 獲取 PR 詳情(包含分支和提交):
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/repos/{owner}/{repo}/pulls/{pr_number}"
?Step 2: 獲取 PR 的差異文件(Diff):
curl -H "Authorization: token YOUR_TOKEN"
"https://api.github.com/repos/{owner}/{repo}/pulls/{pr_number}/files"
4. 如果是相關企業
Step 1: 通過內部的代碼平臺分頁獲取該應用的歷次變更信息
Step 2: 遍歷獲取唯一id對應的代碼變更然后轉換成KEY/VALUE格式
6.2.2 步驟2:將獲取的數據進行清洗標注上傳知識庫
ps:此處以DIFY(大模型工作流平臺)為例,對于在企業內部的小伙伴要注意權限敏感問題,強烈建議使用各自的內部的大模型平臺工具,否則會有法律風險,涉及代碼安全
1. 創建空的知識庫
curl --location --request POST 'https://api.dify.ai/v1/datasets'
--header 'Authorization: Bearer {api_key}'
--header 'Content-Type: application/json'
--data-raw '{"name": "name", "permission": "only_me"}'
2. 添加分段(代碼-需求對)
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/documents/{document_id}/segments'
--header 'Authorization: Bearer {api_key}'
--header 'Content-Type: application/json'
--data-raw '{
"segments": [
{
"content": "需求描述1的詳細內容",
"answer": "對應的代碼實現1",
"keywords": ["關鍵詞1", "關鍵詞2"]
},
{
"content": "需求描述2的詳細內容",
"answer": "對應的代碼實現2",
"keywords": ["關鍵詞3", "關鍵詞4"]
}
]
}'
方案二:使用元數據增強搜索(高級方案)
1. 創建元數據字段
curl --location 'https://api.dify.ai/v1/datasets/{dataset_id}/metadata'
--header 'Content-Type: application/json'
--header 'Authorization: Bearer {api_key}'
--data '{
"type": "string",
"name": "code_language"
}'
2. 上傳文檔并附加元數據
curl --location --request POST 'https://api.dify.ai/v1/datasets/{dataset_id}/document/create_by_text'
--header 'Authorization: Bearer {api_key}'
--header 'Content-Type: application/json'
--data-raw '{
"name": "Python代碼示例",
"text": "[代碼內容]",
"indexing_technique": "high_quality",
"metadata": {
"code_language": "python"
}
}'
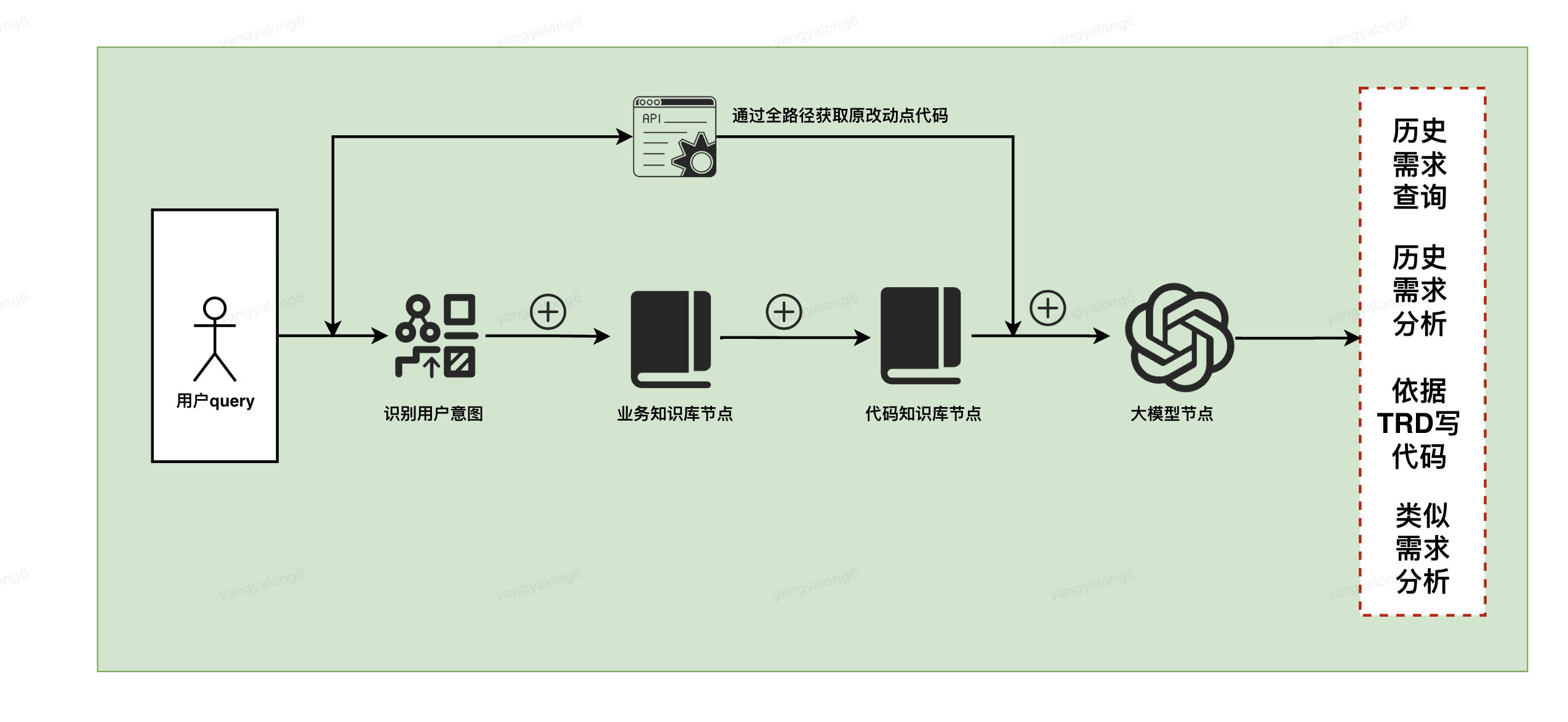
5.2.3 步驟3配置工作流 (此處僅給出示意圖)
?
?
?
5.3結果展示
5.3.1歷史變動檢索
現在想要結合<交易歷史需求變更>知識庫 拼拼融合華冠改了什么 給出改動代碼
?
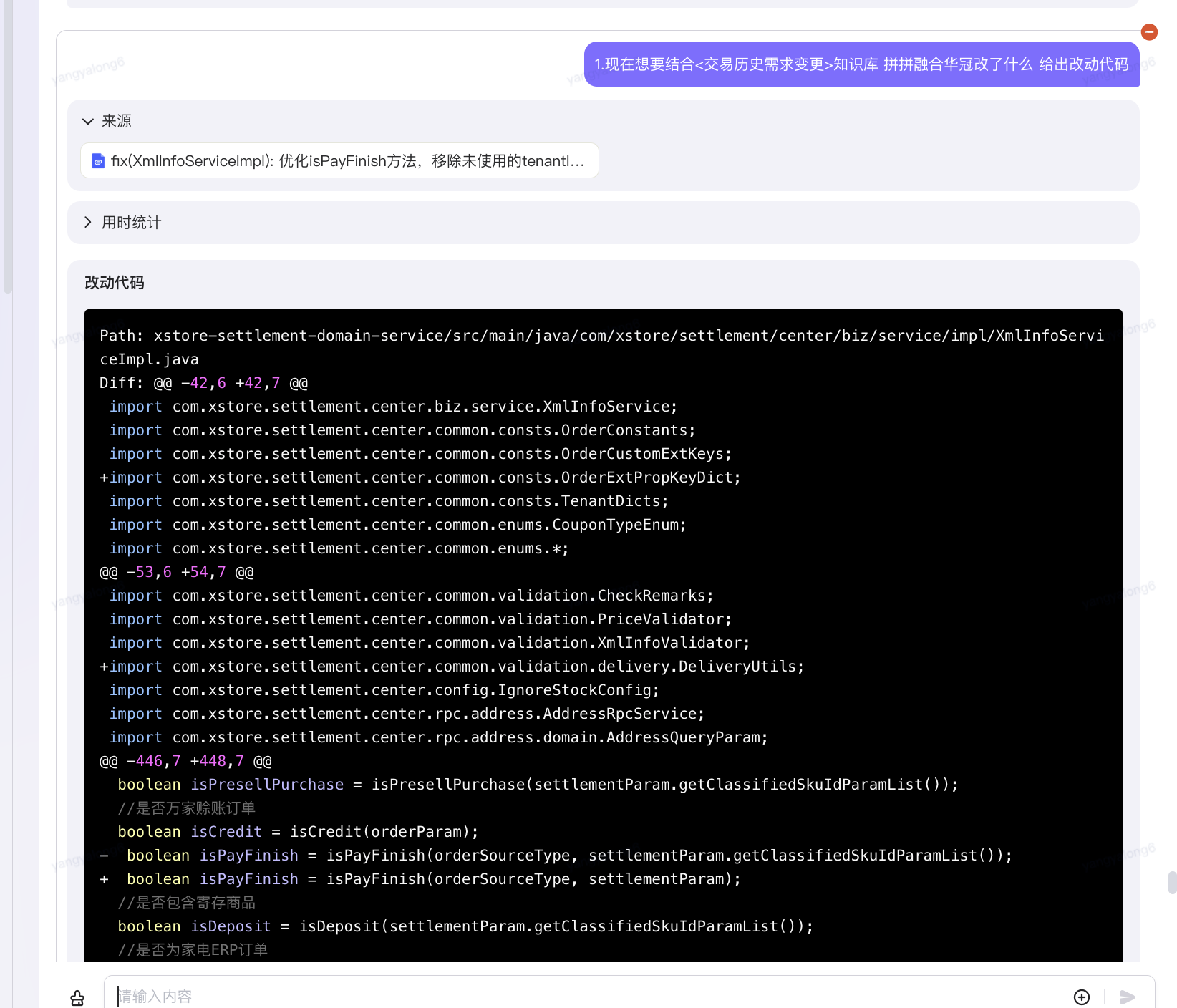
?
?
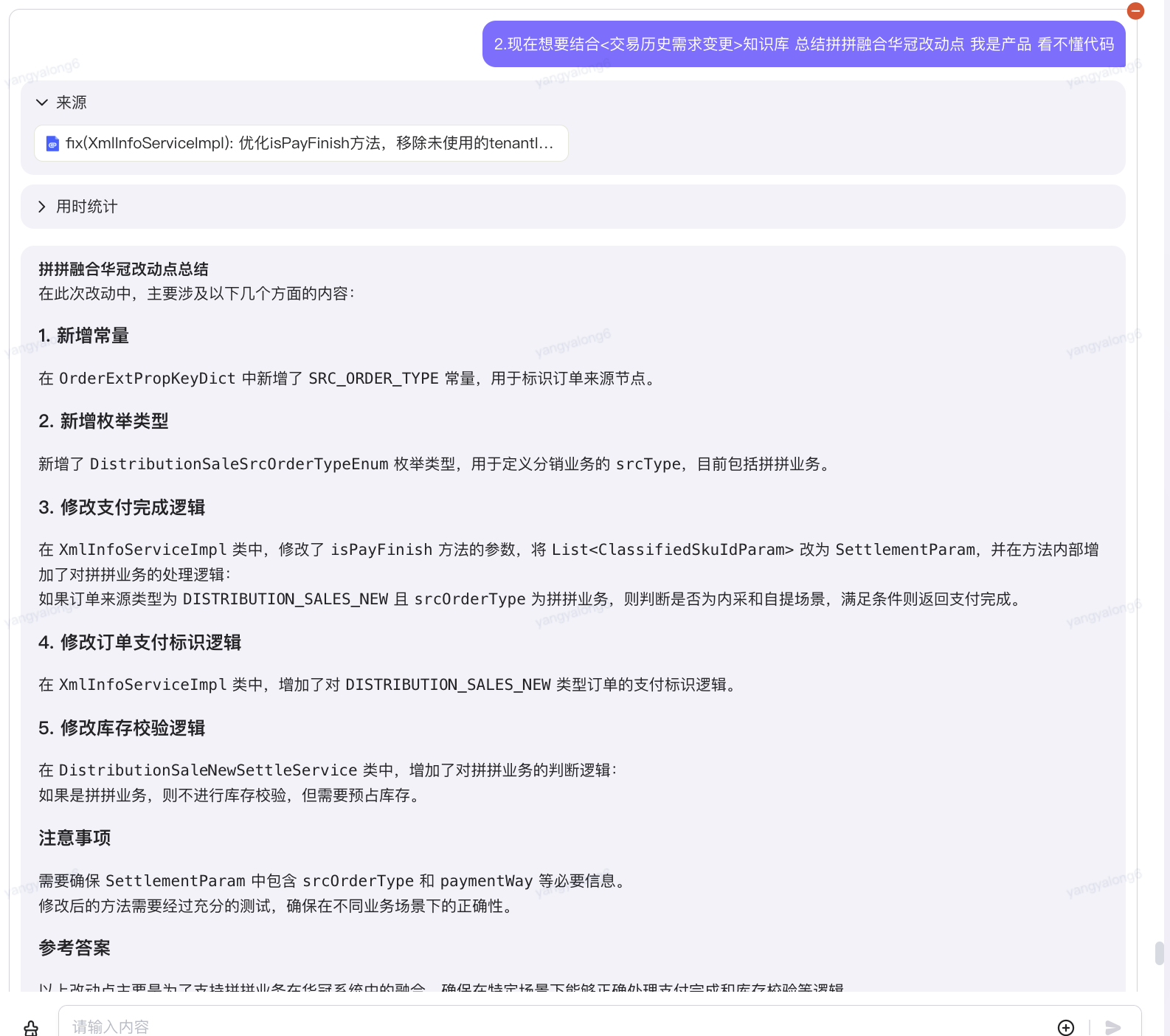
5.3.2歷史變更分析
現在想要結合<交易歷史需求變更>知識庫 總結拼拼融合華冠改動點 我是產品 看不懂代碼 給出
?
?
?
5.3.3依據TRD寫代碼
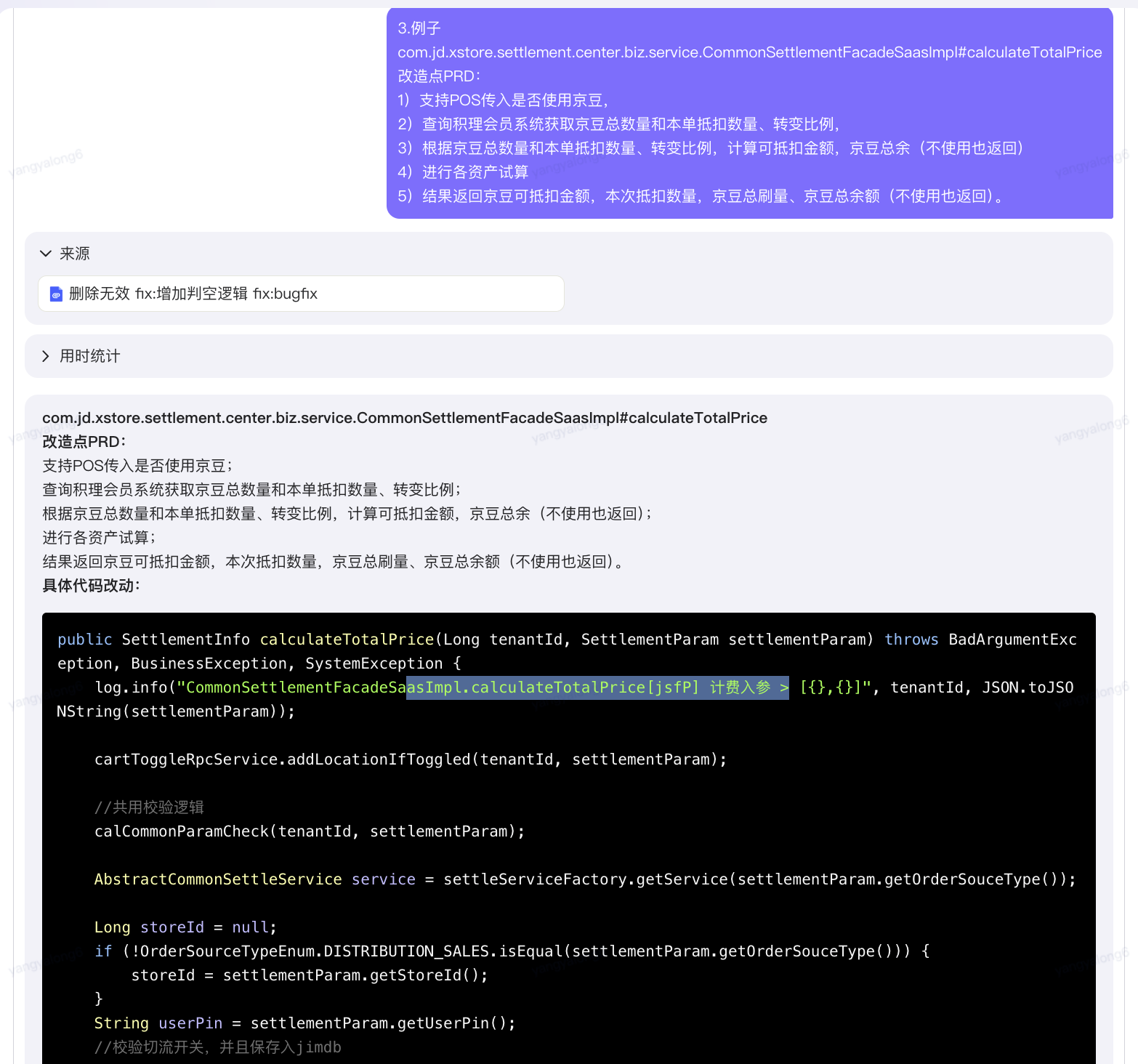
類的全路徑com.jd.xstore.settlement.center.biz.service.CommonSettlementFacadeSaasImpl#calculateTotalPrice
改造點PRD:
1)支持POS傳入是否使用京豆,
2)查詢積理會員系統獲取京豆總數量和本單抵扣數量、轉變比例,
3)根據京豆總數量和本單抵扣數量、轉變比例,計算可抵扣金額,京豆總余(不使用也返回)
4)進行各資產試算
5)結果返回京豆可抵扣金額,本次抵扣數量,京豆總刷量、京豆總余額(不使用也返回)。
?
?
?
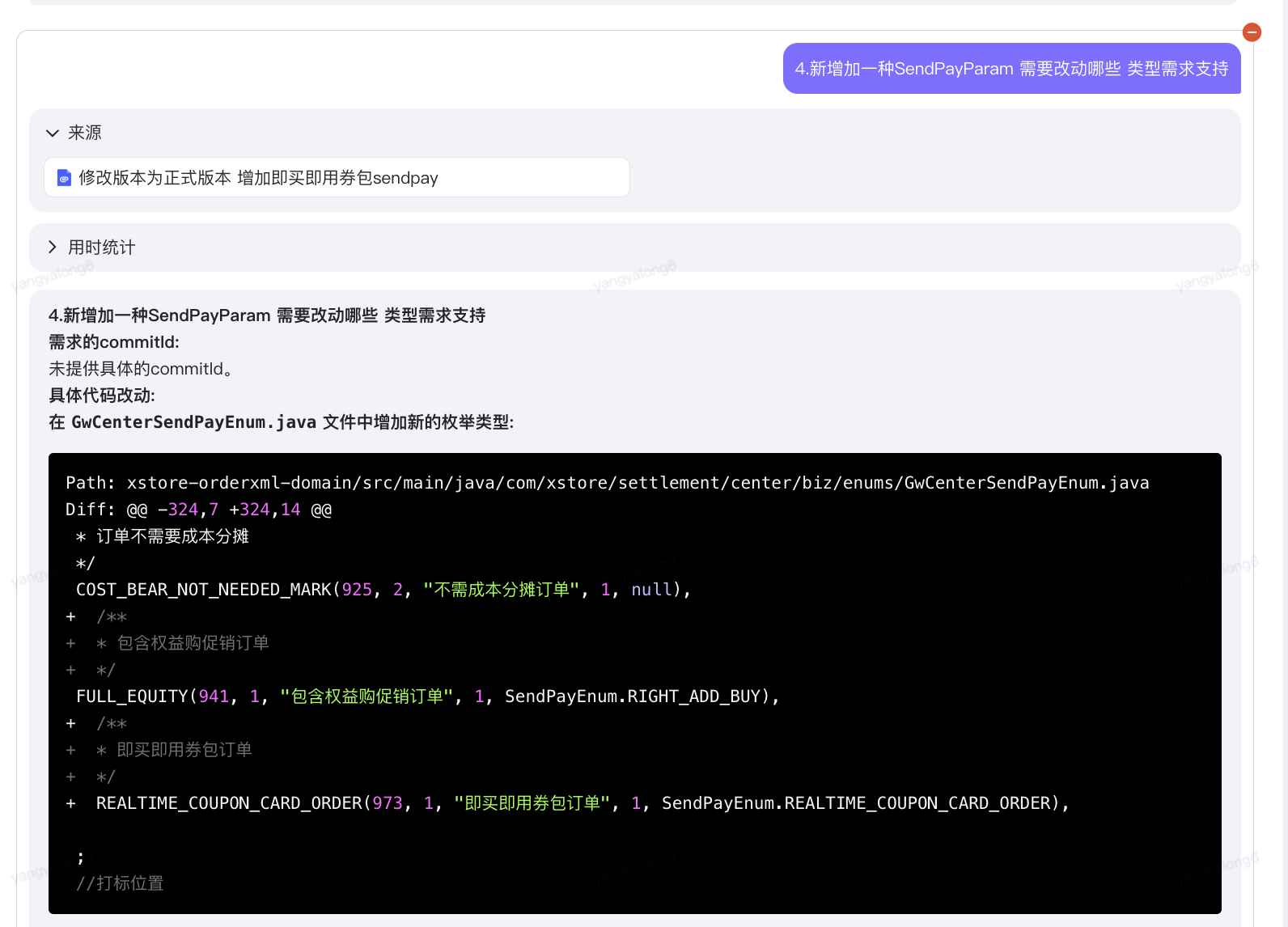
5.3.4做過的類似的需求設計
新增加一種SendPayParam 需要改動哪些 類型需求支持
?
?
?
6.總結
階段1 - 基礎應用 李明首先整理了團隊日常使用大模型的常見場景:
?研發人員用AI生成基礎代碼片段
?測試人員用AI編寫測試用例
?產品經理用AI輔助撰寫需求文檔 這些基礎應用雖然簡單,但確實提高了部分工作效率。
階段2 - 知識整合 在取得初步成效后,李明開始著手解決更深層的問題:
1.建立了系統維度的知識庫模版,確保關鍵文檔都能被有效收錄
2.開發了智能檢索功能,不僅能給出答案,還能定位到具體文檔位置
3.通過知識庫建設,反向推動了各部門完善文檔沉淀
4.系統能夠結合已有知識,給出更貼近實際的解決方案
階段3 - 深度應用 隨著系統不斷完善,李明團隊實現了更高級的功能:
1.代碼變更追溯:可以查詢任意代碼段的歷史修改記錄
2.需求分析:新人產品可以快速了解系統的演進歷程
3.開發輔助:研發人員可以基于需求文檔自動生成基礎代碼
4.經驗傳承:系統可以提供類似需求的實現思路和關鍵點
這個逐步推進的方案,讓團隊的知識管理從碎片化走向系統化,有效解決了新人上手難、知識傳承難的問題。最重要的是,它建立了一個可持續優化的知識沉淀機制。
7.未來優化
在推進的過程中,李明也發現了一些需要持續改進的問題:
1.代碼生成質量依賴需求變動頻率李明注意到,對于那些需求變動較少的模塊,系統生成的代碼往往比較基礎,缺乏深度。比如訂單核心流程這樣長期穩定的模塊,生成的代碼只能覆蓋最基礎的場景,難以應對復雜業務邏輯。
2.知識關聯的準確性有待提升當前系統對代碼變更記錄和需求文檔的關聯還不夠精準。特別是在處理歷史數據時,經常出現匹配錯誤的情況。李明發現,如果能嚴格要求每次代碼提交都必須關聯明確的需求文檔,系統的準確率會有顯著提升。
3.他發現,由于采用了RAG技術,生成代碼后比較依賴于對于query識別到需求的準確度,比較依賴召回的準確度。
李明意識到,這些問題都需要通過持續優化算法,嚴格卡控需求和代碼綁定來逐步解決。他計劃將這些優化點納入下一階段的改進計劃中。不過他堅信,道阻且長,行則將至,他一次又一次對自己說,"我知道的,我做什么都會成功的"~
審核編輯 黃宇
-
代碼
+關注
關注
30文章
4900瀏覽量
70732 -
大模型
+關注
關注
2文章
3141瀏覽量
4066
發布評論請先 登錄
代碼革命的先鋒:aiXcoder-7B模型介紹

AI知識庫的搭建與應用:企業數字化轉型的關鍵步驟
RAKsmart企業服務器上部署DeepSeek編寫運行代碼
為什么MotorControl Workbench無法生成代碼?
《AI Agent 應用與項目實戰》閱讀心得3——RAG架構與部署本地知識庫

聚云科技榮獲亞馬遜云科技生成式AI能力認證 助力企業加速生成式AI應用落地
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
【「基于大模型的RAG應用開發與優化」閱讀體驗】+第一章初體驗
STM32CubeMX生成的代碼,是怎樣的HAL架構?

借助浪潮信息元腦企智EPAI高效創建大模型RAG

阿里云開源Qwen2.5-Coder代碼模型系列
探索設計稿自動生成Flutter代碼的技術方案





 工商網監
工商網監
評論