 利用Calibre RVE高效篩選大型DRC結果數據庫
利用Calibre RVE高效篩選大型DRC結果數據庫
您是否有過這樣的經歷,為了完成一個錯誤較多的大型芯片級設計上運行的設計規則檢查 (DRC),您苦等了幾個小時,結果發現得到的 DRC 結果數據庫 (RDB) 文件大小竟然達到數百GB,其中更有數百萬條需要審查的錯誤結果,然后,您還需要編輯設計,使其符合晶圓代工廠的設計規則要求?在傳統的調試流程中,審查大量 DRC RDB 可能是一個非常耗時的階段,這主要是因為與這些大型數據集相關的加載、篩選和顯示時間過長。即使應用定制篩選器或使用豁免來減少必須調試的結果數量,要加載整個 RDB 并處理每個結果,所需的時間也會耗費掉大部分的任務時間。
現在,您終于有了更好的選擇。工程師可以將這些巨大的 RDB 劃分為更小的 RDB,然后再將它們加載到結果查看器中,僅僅選擇和加載那些需要立即關注的高優先級問題的結果,從而避免加載完整 RDB 所造成的性能損失。
1傳統篩選
不過,讓我們首先來看看篩選大型 RDB 的現有方法,通過 Calibre RVE 結果可視化環境來演示這些方法的使用過程。工程師可以利用 Calibre RVE 界面加載 RDB,然后在其設計工具中直觀地檢查和分析錯誤標記(圖 1)。
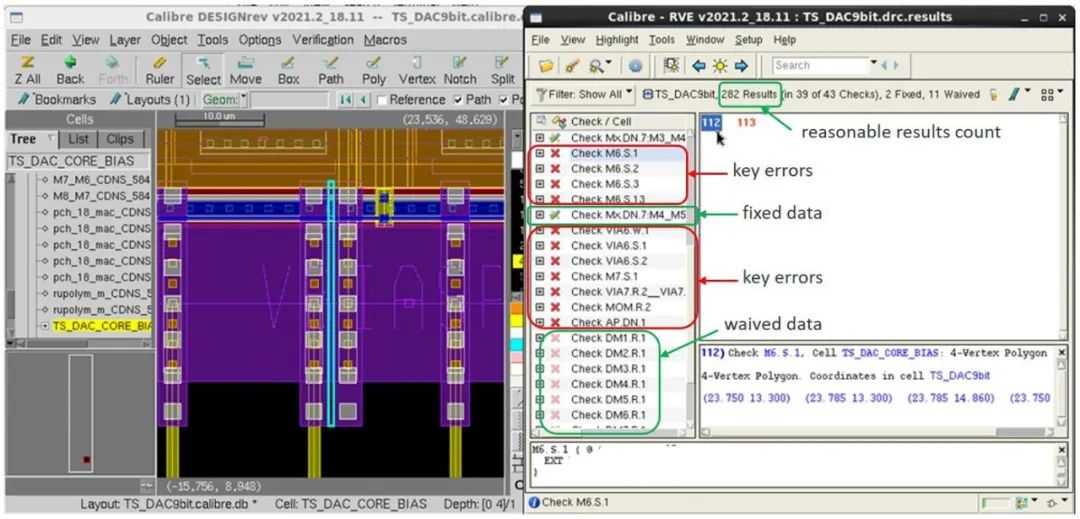
圖 1. 與 Calibre DESIGNrev 芯片完工修整平臺集成的
Calibre RVE 結果顯示
定制篩選器
工程師通常通過將結果篩選成組來管理大型 RDB,這樣他們就能集中精力,一次處理一組結果。我們的目標是查看檢查名稱與 “M1*” 匹配的結果。在我們的示例中,我們將使用一個 110GB 的 Calibre nmDRC RDB,其中包含 1.2G 的結果。Calibre RVE 界面需要 25 分鐘來加載此 RDB 文件并在 Calibre DESIGNrev 界面顯示結果。
Calibre RVE 提供了一個直觀的篩選器編輯器,供工程師創建定制篩選器。然后,他們可以將這些定制篩選器應用于 RDB,僅顯示與給定標準匹配的錯誤(圖 2)。定制篩選器可以保存并用于多個 RDB,因而成為一種非常有效的解決方案,專門處理設計團隊日常感興趣的錯誤類型。
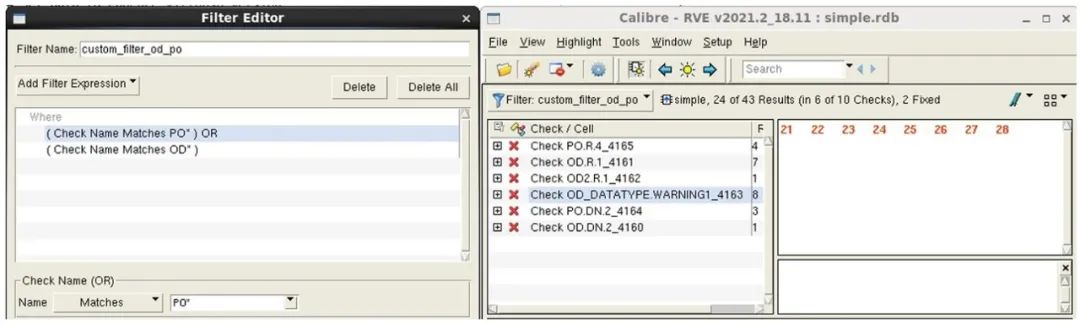
圖 2. 具有定制篩選器的 Calibre RVE
但是,Calibre RVE 仍須加載 RDB 并在內存中處理每個結果,才能創建經篩選的結果。因此,這種方法適合中小型 RDB,而對于像我們示例所示的大型 RDB,仍可能需要大量的時間。
此外,篩選器編輯器僅適合創建采用樹結構的簡單篩選器。工程師如果需要更復雜的篩選器,可能會發現此解決方案不夠用。
豁免
另一個選項允許工程師篩掉允許的(被豁免的)違規,以便他們可以專注于確實必須調試的結果。工程師使用晶圓代工廠 Calibre PDK 團隊和 / 或 CAD 團隊提供的 DRC 前期豁免文件執行 Calibre nmDRC 運行,以生成包含豁免和未豁免結果的 RDB。
然后,工程師可以在 Calibre RVE 中將內置的 “顯示未豁免” 篩選器應用于此 RDB,使其僅僅關注未豁免的錯誤(圖 3)。與定制篩選器方法一樣,豁免方法適用于中小型 RDB,但不適用于大型 RDB。Calibre RVE 仍須加載并處理整個 RDB,然后才能篩選并且僅顯示未豁免的結果。
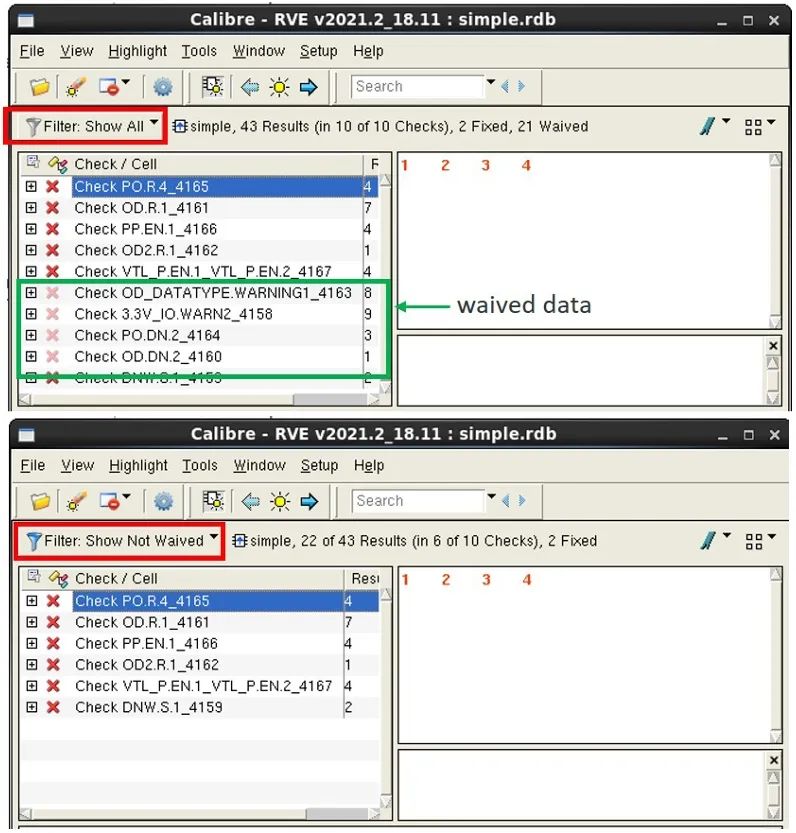
圖 3. Calibre nmDRC 豁免方法
使用定制篩選器的豁免
結果篩選功能最常見的用途是結合定制篩選器和豁免(圖 4),以便僅顯示對修復設計至關重要的關鍵錯誤(圖 5)。如您所料,這種方法雖然從結果篩選的角度來看非常有用,但非常耗時。
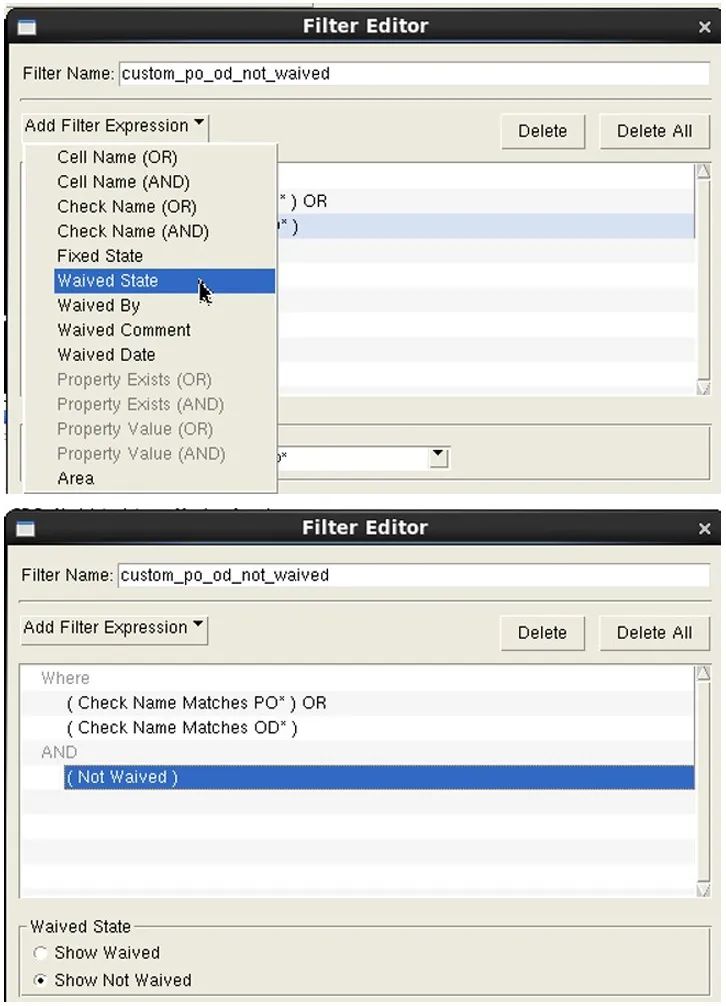
圖 4. 將篩選器編輯器的定制篩選器與豁免相結合
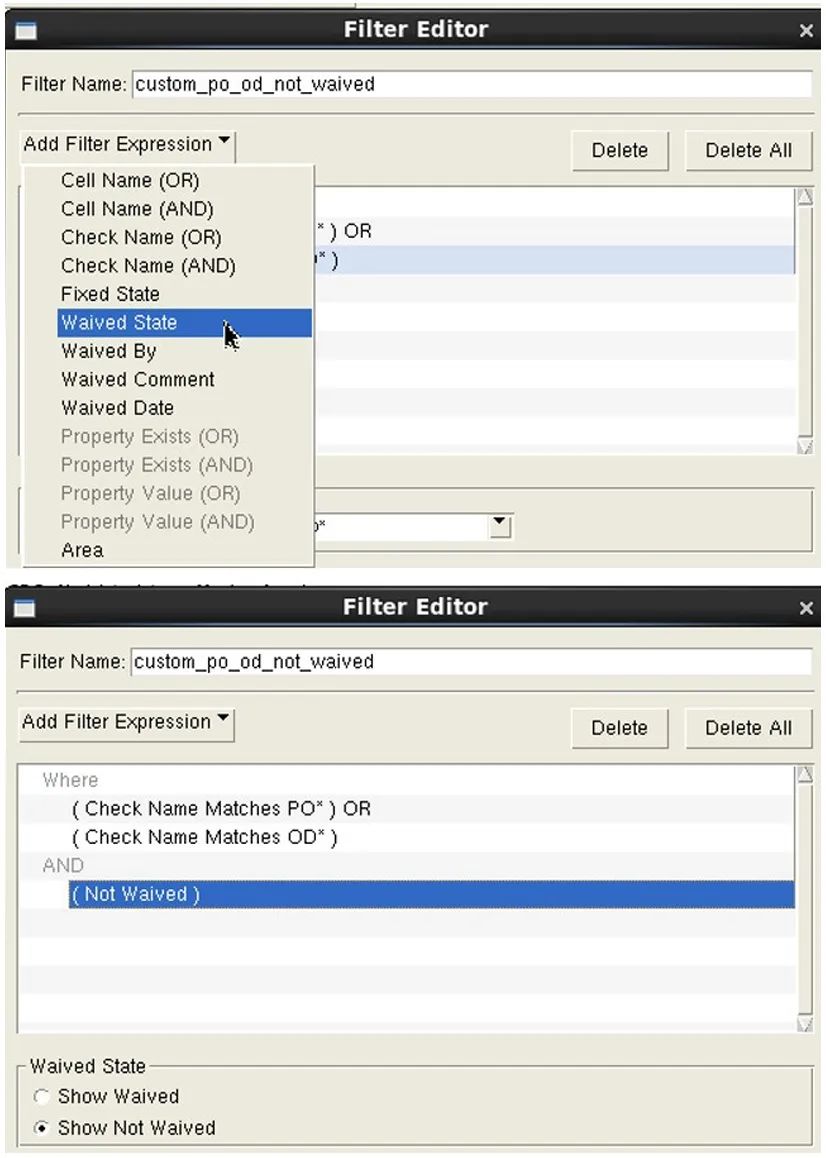
圖 5. 將定制篩選器與豁免相結合,
提供一組定向的需要修復的嚴重錯誤結果
鑒于上述現有方法的局限性,設計和驗證團隊需要一種選項,讓他們能夠在更短的時間內使用更少的內存資源來篩選非常大的 RDB。
2批量篩選
批量篩選是一種創新技術,工程師可利用該技術在 RDB 上應用篩選器表達式,并使用批處理 Calibre RVE 運行創建更小的 RDB——換言之,無需將完整的 RDB 加載到內存中。篩選器表達式使用與定制篩選器方法相同的篩選器編輯器表達式關鍵字,而 Calibre RVE 則將這些篩選器表達式用作命令行參數。利用這種方法,設計人員可以開發他們的定制篩選器表達式,并通過共享他們的 Calibre RVE 命令和參數輕松地與其他設計人員分享:
calibre -rve -drc
讓我們來看幾個示例,以展示批量篩選器流程是如何工作的。我們從原始 RDB 文件開始(圖 6)。
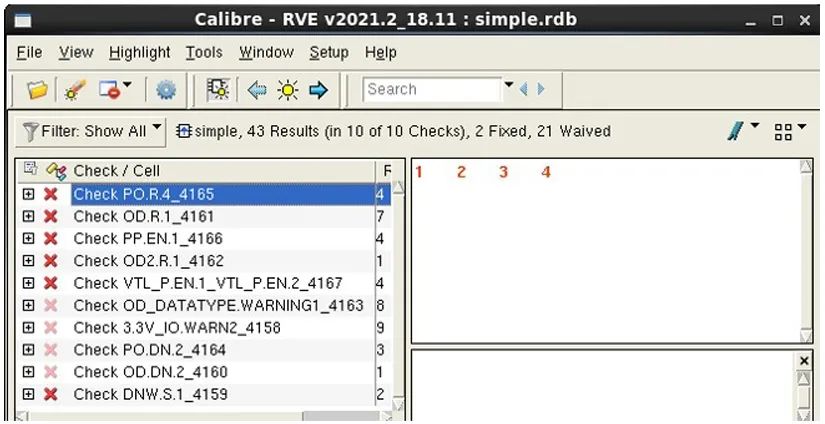
圖 6. 原始 RDB 文件
在我們的第一個示例中,我們創建了一個 RDB 文件,其中僅包含檢查名稱帶有 “OD” 或 “PO” 前綴的錯誤。我們為批處理 Calibre RVE 命令設置了一條篩選器約束,創建一個新的 RDB 文件 “od_po.rdb”,其中僅包含帶有前綴 “OD” 和 “PO” 的檢查名稱。
calibre -rve -drc simple.rdb -filter -check “OD* PO*” -output od_po.rdb
圖 7 顯示了相應結果。由批處理運行創建的經篩選的 RDB 中包含 24 個錯誤結果。
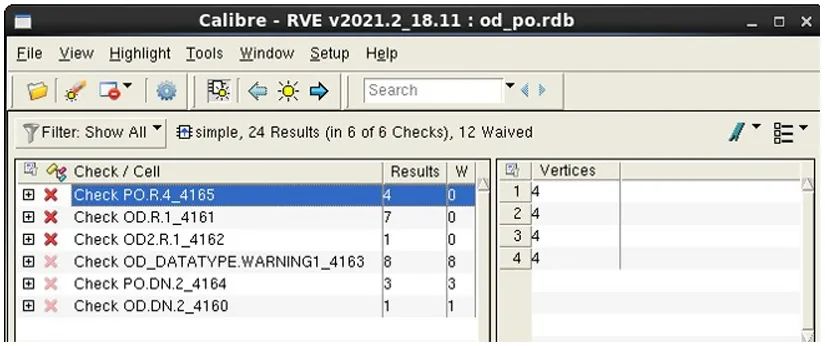
圖 7. RVE 批量篩選結果僅包含 OD* 和 PO* 檢查
在這些結果中,我們注意到,有 12 個豁免的結果。在我們的示例中,讓我們更進一步,創建一個 RDB 文件,其中僅包含帶有前綴 “OD” 或 “PO” 的檢查名稱的錯誤,并排除所有豁免的結果。現在,我們的批處理 Calibre RVE 命令運用篩選器約束創建了一個新的 RDB 文件 “rve_filter.rdb”,其中僅包含帶有前綴 “OD” 和 “PO” 的檢查名稱,并從文件中清除了所有豁免的結果。
calibre -rve -drc simple.rdb -filter -check “OD* PO*” -unwaived -output rve_filter.rdb
如圖 8 所示,結果計數現在顯示沒有豁免的結果。這個經篩選的 RDB 中包含 12 個未豁免的結果。
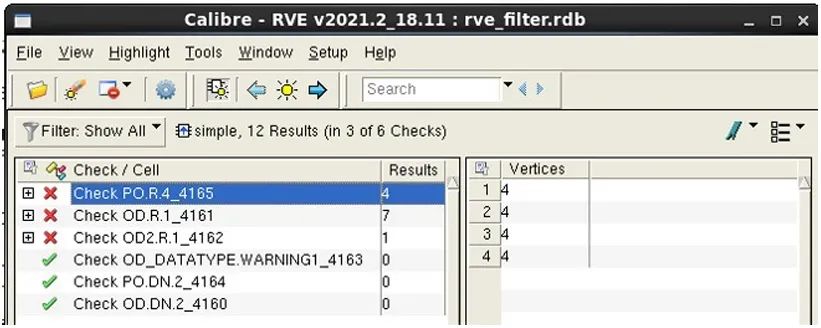
圖 8. 不含豁免結果的 RVE 篩選器結果
在下一個示例中,我們想要創建一個 RDB 文件,其中僅包含特定直線邊區域中的錯誤,而將其余結果放在另一個 RDB 中。以下批處理 Calibre RVE 命令運用篩選器約束創建一個 RDB 文件 “area.filter.rdb”,其中僅包含指定區域的結果,并創建另一個 RDB 文件 “other.filter.rdb”,其中包含剩余的結果。
calibre -rve -drc simple.rdb -split -filter -include_area “simple - 76.700 233.700 38.500 233.700 38.500 120.800 -8.400 120.800 -8.400 174.900 -76.700 174.900” -output area. filter.rdb -filter -other -output other.filter.rdb
圖 9 顯示了此批量篩選器運行創建的兩個 RDB。
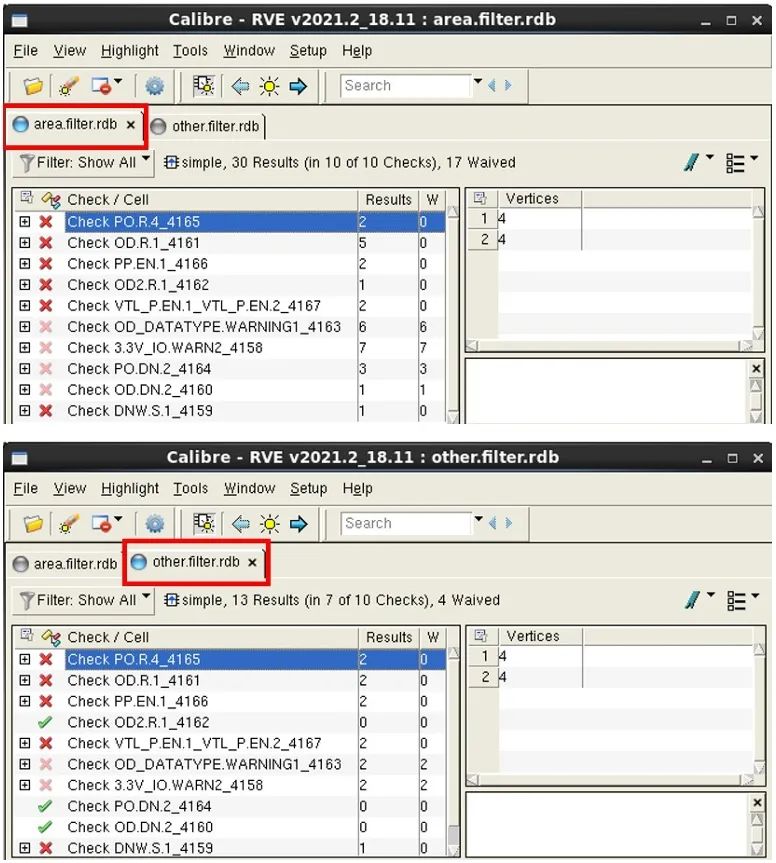
圖 9. 在多個 RDB 文件之間
拆分 RVE 批量篩選結果
在下一個示例中,讓我們來看看批量篩選器過程如何處理更復雜的篩選條件。我們將使用篩選器,通過檢查名稱和屬性范圍的布爾組合創建一個 RDB。以下批處理 Calibre RVE 命令運用篩選器約束創建了一個 RDB “boolean.rdb”,其中包含檢查名稱 “default” 且屬性 “CD” 的值大于 200、小于 250 的結果,以及檢查名稱 “short_ports” 且屬性 “CD” 的值大于 250、小于 300 的結果。
calibre -rve -drc input.rdb -filter -check “default” -property “200 < CD < 250” -OR -check “short_ports” -property “250 < CD < 300” -output boolean.rdb
圖 10 顯示了批量篩選器創建的 RDB。其中僅包含符合指定標準的結果。
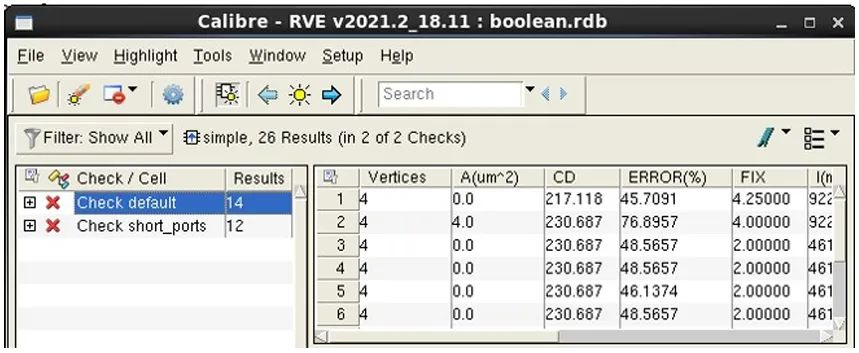
圖 10. CD 屬性在某個范圍內的
RVE 批量篩選結果
3性能比較
為了將傳統篩選器技術與批量篩選器過程的性能進行比較,我們使用批量篩選器過程將定制篩選器應用于我們的 110GB RDB,以創建 RDB “m1.rdb”,其中包含前綴為 “M1i” 的檢查名稱的結果,以及 RDB “m2.rdb”,其中包含前綴為 “M2i” 的檢查名稱的結果。
calibre -rve -drc 110GB.rdb -split -filter -check “M1i*” -output m1.rdb -filter -check “M2i*” -output m2.rdb
表 1 顯示了相應結果。

表 1:批處理 RVE 篩選運行匯總
然后,我們比較了加載 RDB 文件并應用內置篩選器以刪除豁免結果所需的運行時間性能和內存使用量。
表 2 顯示了相應結果。

表 2:加載 RDB 文件并應用內置篩選器所用的時間
使用傳統方法,Calibre RVE 界面需要 25 分鐘加載原始 RDB,使用了 77.7GB 內存。然后需要一個小時將 “顯示未豁免” 篩選器應用于結果。
使用批量篩選過程,Calibre RVE 需要 47 分鐘創建兩個較小的 RDB。然后需要 14 秒鐘加載第一個 RDB,內存使用量為 1.5GB,需要 6 分鐘加載第二個 RDB,使用了 10.5GB 內存。加載后,第一個 RDB 用了 2 秒鐘的篩選時間刪除豁免的結果,而第二個 RDB 則需要 18 秒鐘。整個過程的總時間不到一小時,總內存使用量為 12GB。
找到有效的方法來篩選結果數據,對于優化結果調試時間和資源使用量有著重要的意義。雖然設計團隊在 Calibre nmDRC 運行期間可以生成經篩選的較小 RDB 文件,但它需要修改晶圓代工廠的規則集,而這通常是不可取的。此外,加載時間耗費了總體運行時間的很大一部分,而且使用了大量的內存資源。在圖形界面應用程序中快速加載較小的數據庫時可以利用內置的篩選器,但更大的數據庫可能會影響計劃和資源。
當處理千兆級數據庫時,設計團隊可以利用 Calibre RVE 批量篩選過程等外部篩選操作,以節省大量時間和資源,并創建更高效的調試流程。設計人員可以利用 Calibre RVE 批量篩選過程將篩選表達式應用于 RDB,以更少的內存將匹配的結果寫入到更小的輸出文件。設計團隊可以在任何文本編輯器中創建定制篩選器,然后輕松地對其他 RDB 文件重復使用這些篩選器,以及與團隊成員或其他團隊分享篩選器。通過更快地創建較小的定向 RDB,設計團隊可以集中他們的時間和資源,更快、更高效地調試關鍵錯誤,從而改善結果,同時縮短流片時間。
-
芯片
+關注
關注
459文章
52321瀏覽量
438194 -
數據庫
+關注
關注
7文章
3906瀏覽量
65910 -
DRC
+關注
關注
2文章
155瀏覽量
36996 -
編輯器
+關注
關注
1文章
820瀏覽量
31882
原文標題:批量篩選器:更好更快地篩選大型 DRC 結果數據庫
文章出處:【微信號:Mentor明導,微信公眾號:西門子EDA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
《Visual C# 2008程序設計經典案例設計與實現》---利用水晶報表篩選數據庫中的數據
labview根據時間篩選數據庫的內容
calibre跑完后調不出RVE視窗的問題該如何去解決?
怎樣去改用calibre過DRC時的錯誤?
大型無縫影像數據庫管理系統的設計與實現
大型數據庫實驗指導
一個大規模分布式原生XML數據庫原型系統
Calibre DRC報告自動做修復的教程分享
oracle是大型數據庫嗎
數據庫數據恢復—未開啟binlog的Mysql數據庫數據恢復案例





 工商網監
工商網監
評論