 進迭時空第三代高性能核X200研發進展
進迭時空第三代高性能核X200研發進展
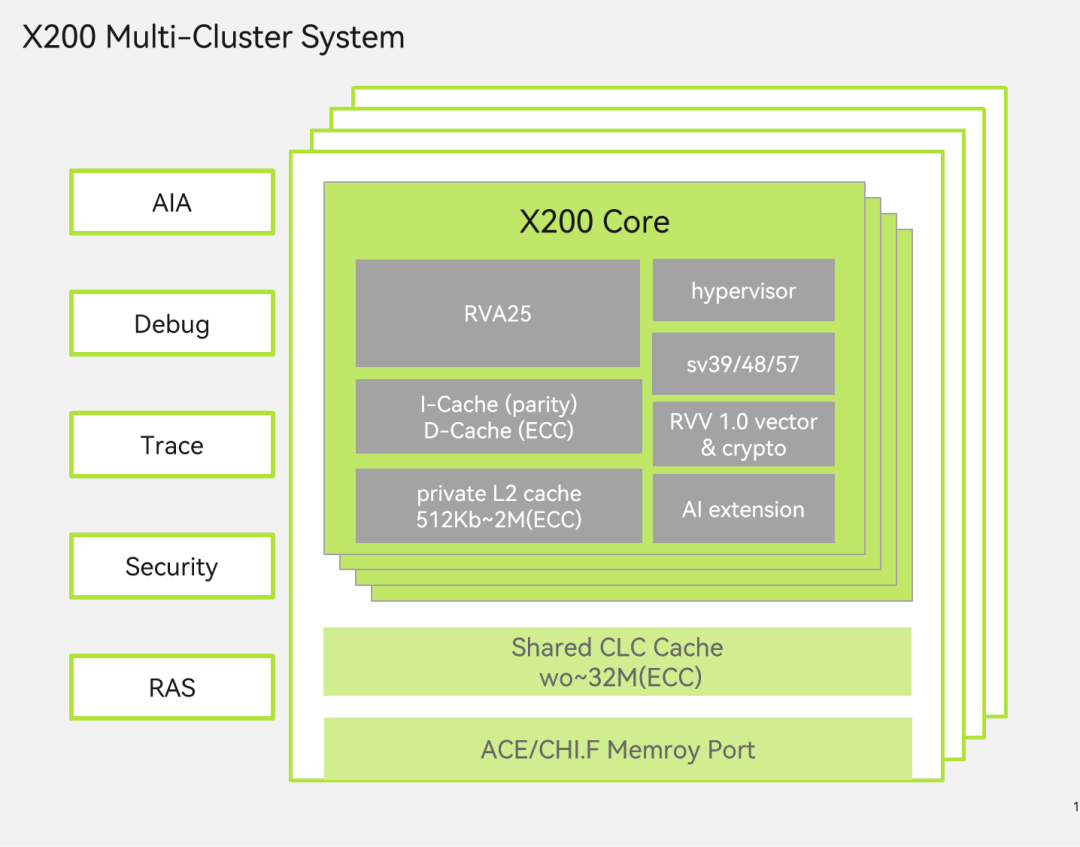
繼X60和X100之后,進迭時空正在基于開源香山昆明湖架構研發第三代高性能處理器核X200。與進迭時空的第二代高性能核X100相比,X200的單位性能提升75%以上,達到了16 SpecInt2006/GHz,單核性能提升125%以上,達到了50 SpecInt2006/Core,主要應用于超級AI計算機、云計算、高階自動駕駛等高性能計算場景。
X200是一款6發射、14級流水線的超標量亂序高性能RISC-V核。X200的整體特性如下:
▲
SpecInt2006 > 16分/GHz,單核頻率可達3.2GHz @ 7nm
▲
支持RVV1.0,Vector Crypto 擴展以及進迭時空 IME 擴展
▲
支持RVH,AIA技術,并且能夠與進迭時空自研IOMMU配合實現完整的虛擬化
▲
支持安全隔離技術,與進迭時空自研 IOPMP配合實現云計算級別的機密計算安全方案
▲
支持服務器級別RAS,Trace特性
▲
支持全芯片高效CHI互聯,與進迭時空自研NoC總線配合最大128核心的并行互聯
▲
將支持2025年定稿的最新 Profile 規范(RVA25)
X200 架構與微架構創新
基于開源香山,快速迭代
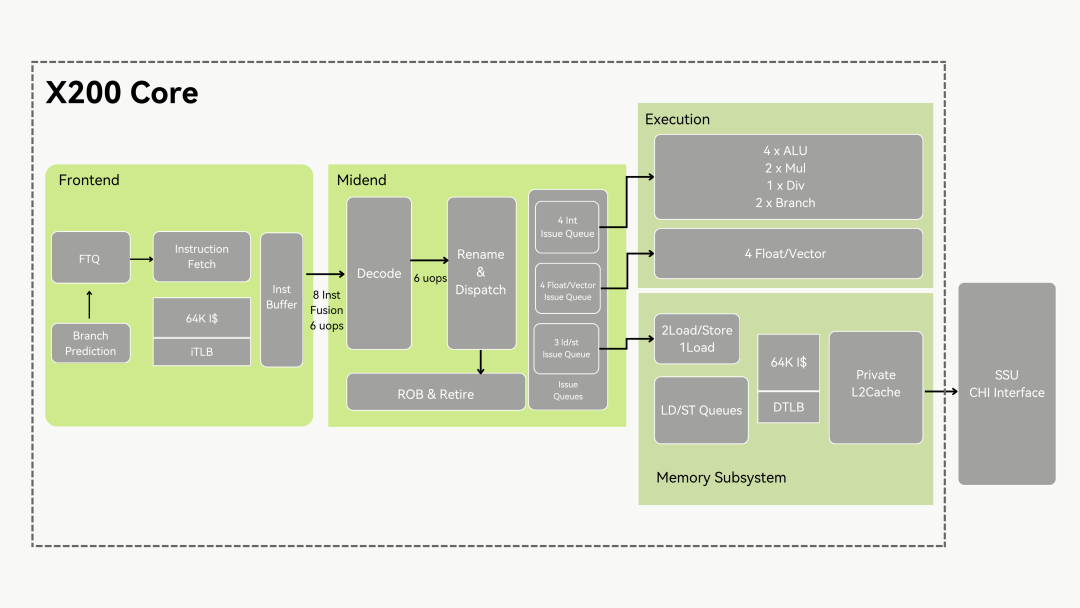
“昆明湖”是開芯院開發的第三代高性能核,整體性能對標 Arm N2,達到 SpecInt2006 性能15分/GHz。開芯院不僅開源了昆明湖全部的設計代碼,還提供了昆明湖的驗證環境、Golden model、性能分析工具(如完整的Simpoint Flow)以及經過部分對齊的昆明湖Gem5模型。基于開源的昆明湖性能模型和架構設計,可以大大減少了處理器設計過程中架構探索的時間,并在開源性能模型的基礎上進一步做微架構創新和性能迭代。
取指前端:昆明湖采用了分支預測和指令緩存訪問解耦(下稱Decouple)的架構,最大限度減少分支指令對高帶寬取指需求的影響。分支主預測器采用兩級FTB 加TAGE-SC結構,配合XS-Gem5的前端建模,設計了合理的參數規格;
執行后端:昆明湖實現了基于推測的指令喚醒與發射、Move指令消除、基于Checkpoint檢測點的指令恢復等多項機制,有效降低后端指令執行延遲,并提升推測錯誤時的恢復速度;
訪存單元:昆明湖探索了多種預取機制,基于第一級數據緩存實現了Stride, Stream, SMS, SPB的混合預取算法,基于私有的二級緩存L2 Cache實現了BOP與Temporal的算法,在SpecInt2006基準測試上取得了出色的效果。
因為香山核的全套開源以及出色的微架構設計,進迭時空X200選擇基于開源昆明湖研發第三代高性能CPU核。在昆明湖的架構上,進迭時空根據面向的計算場景,對部分模塊進行了優化,進一步平衡了部分模塊的PPA指標。X200 SpecInt2006能夠達到16分/GHz,相較前代X100提升75%以上。
取指前端升級
取指前端作為CPU核流水線的起點,其效率直接決定了后級流水線的運行負荷,是影響指令吞吐量的關鍵瓶頸。近年來,Apple M2, AMD Zen4 等處理器架構均在取指前端進行了大量的優化。
X200的取指前端,基于 Decouple 架構,進一步改進了FTB的結構,提升分支指令的存儲利用率;擴展了對2-Taken Branch 場景的支持,可實現每周期至多預測2個跳轉分支。
相應的,X200優化了指令Cache的組織結構,支持兩個獨立的取指塊并行取指。通過調整指令Cache Tag和Data的訪問流水級,緩解了指令Cache的訪問沖突,進一步提升整體的取指帶寬。
訪存及互聯設計優化
訪存及互聯往往是CPU核中最復雜的部分,訪存單元的設計也極大地影響了CPU核的性能。
X200的訪存單元優化了整體訪存流水線,支持了Load/Store復用流水線,平衡了性能和資源的消耗。針對整個訪存通路,通過指令提前喚醒和流水線優化,極致優化訪存延遲,L1 Cache的Load To Use Latency控制在4個周期,2M Priave L2 Cache控制在10個周期,Cluster Level Cache控制在~30個周期;針對應用場景,進一步調優預取算法;核級別和簇級別均支持超深的Outstanding能力,面向AI等大數據量搬運場景,允許更多事務在下個層次的內存系統中并行,減少整體內存的訪問延遲。
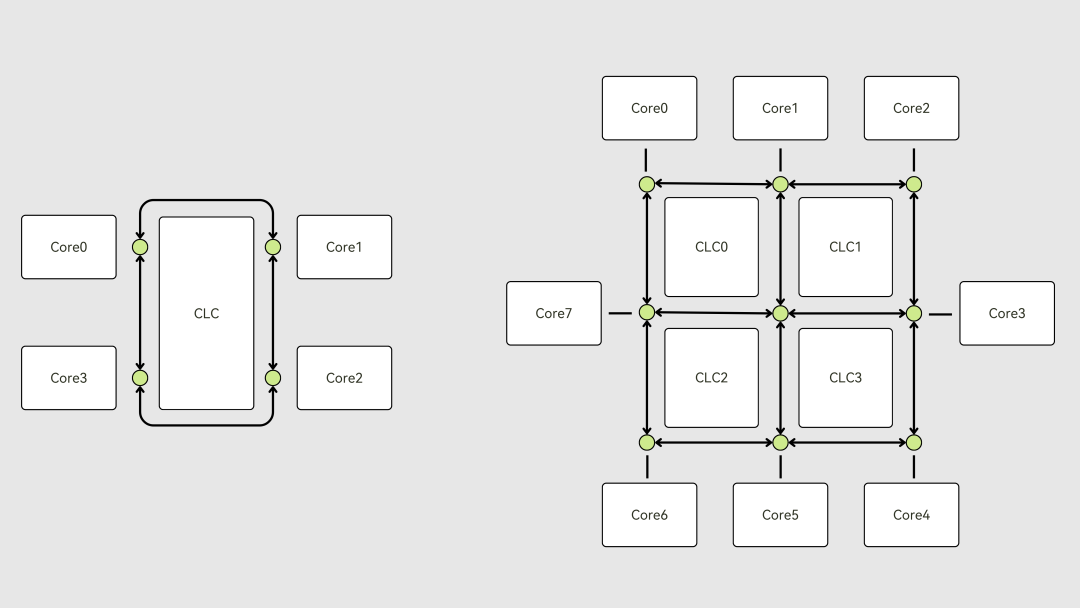
在互聯的設計上,從核互聯成簇以及多簇之間的互聯,均使用了CHI的標準協議,最高可支持到CHI.F協議,核間根據簇中核的規模,使用 Ring/Mesh Bus進行互聯,在提升可擴展性的同時,進一步提升簇內總線的頻率與帶寬。支持Cache Stash的功能,能夠通過主動的緩存預存,降低關鍵數據包的獲取延遲。
向量及AI單元優化
X200支持RISC-V Vector1.0及Vector Crypto指令集,VLEN支持256/512/1024可配,數據處理寬度支持4x128/4x256可配。矢量整型指令支持SEW=8/16/32/64;矢量浮點指令支持SEW=FP16/BF16/FP32/FP64。訪存處理寬度上支持3x128/3x256的可配,并支持矢量訪存指令的非對齊訪問。
同時,X200支持符合RV規范的IME擴展的 AI 增強指令
(INT4/INT8/FP8/FP16/BF16/FP32),提供靈活易用的融合 AI 算力。此外,X200可配地通過接口擴展的方式支持AME擴展,以提供更加定制化的AI算力。
在此基礎上,X200針對常見的應用場景,結合算法特點,對向量/AI處理能力和能效進行優化,并重點對向量訪存和向量計算資源的均衡和協同、復雜訪存pattern以及復雜元素置換操作在亂序核中的的實現等方面進行深度調優。同時,考慮到大帶寬向量帶來的龐大資源投入,X200基于對大量算法的模擬分析,評估并權衡不同指令對資源/功耗開銷以及性能回報,做了不同層次的向量可配性,以滿足不同應用場景的性能和PPA需求。
新擴展指令集支持
RISC-V是一個高速發展、充滿活力的指令集,2024年,RISC-V共批準(Ratified)了23個規范,RISC-V正快速在各個場景下,拉近與x86、Arm之類成熟指令集的距離。X200面向應用領域的需求,進一步對RISC-V最新的擴展進行了支持:
▲
支持QoS規范(CBQRI, QoSID),進一步提升高優先級數據的延遲表現,增強系統的穩定性和實時性
▲
支持Svadu, Zacas擴展,分別降低多核間頁表更新的代價,減少多核搶鎖的概率,提升多核系統的效率
▲
支持CFI擴展,使用Shadow Stack和 Landing Pad技術保護內存,降低系統被攻破的概率
X200 也將持續跟進RISC-V的最新擴展以及 Profile,將會支持今年定稿的最新Profile(預計為 RVA25)。
服務器級特性優化
X100已經實現了完整虛擬化、符合云計算場景的安全功能、符合計算機7*24小時穩定工作的RAS特性等。X200在X100的基礎上,在完整實現這些功能的同時,也將做進一步增強。重點面向云服務應用場景,通過優化TLB及Walk Cache的組織形式,減少虛擬化多級地址翻譯帶來的性能損失;擴展Trace以及HPM(高性能計數器)功能,配合自研總線進行系統級優化,提升性能分析、問題定位的跟蹤效率;支持更多RAS信息上報,配合全通路CHI總線支持,進一步提升總線的穩定性,配合進迭時空服務器管理固件,能夠提升服務器系統可發現錯誤、可糾正錯誤、可管理錯誤能力。
借助于香山昆明湖出色的架構和微架構基礎,進迭時空開展了X200的研發工作,并實現了對第二代處理器核X100的大幅性能提升。當前,X200已經完成了代碼開發并進入了持續的PPA優化階段,預計將在2025年Q4季度研發完畢,基于X200的高性能計算芯片將在2026年底面市。
更多X200的設計細節將在后續的公司微信公眾號中陸續做介紹,敬請大家期待。
-
處理器
+關注
關注
68文章
19812瀏覽量
233607 -
進迭時空
+關注
關注
0文章
29瀏覽量
73
發布評論請先 登錄
迎接泛機器人時代:進迭時空如何以RISC-V架構數智未來

第三代半導體的優勢和應用領域
英飛凌發布第三代3D霍爾傳感器TLE493D-x3系列

金升陽推出高性能第三代插件式單路驅動電源

進迭時空完成A+輪數億元融資 加速RISC-V AI CPU產品迭代
第三代半導體器件封裝:挑戰與機遇并存


進迭時空亮相RISC-V產業發展大會:新AI CPU引領大模型時代

第三代半導體對防震基座需求前景?
第三代半導體產業高速發展
高通第三代驍龍8移動平臺解鎖沉浸式游戲體驗
Banana Pi BPI-F3 進迭時空RISC-V架構下,AI融合算力及其軟件棧實踐





 工商網監
工商網監
評論