") 命名實(shí)體識(shí)別(NER)是自然語(yǔ)言處理(NLP)中的基本任務(wù)之一
命名實(shí)體識(shí)別(NER)是自然語(yǔ)言處理(NLP)中的基本任務(wù)之一

什么是命名實(shí)體識(shí)別(NER)?
命名實(shí)體識(shí)別(NER)是自然語(yǔ)言處理(NLP)中的基本任務(wù)之一。NLP的一般流程如下:

句法分析是NLP任務(wù)的核心,NER是句法分析的基礎(chǔ)。NER任務(wù)用于識(shí)別文本中的人名(PER)、地名(LOC)等具有特定意義的實(shí)體。非實(shí)體用O來(lái)表示。我們以人名來(lái)舉例:
王 B-PER
文 I-PER
和 O
小 B-PER
麗 I-PER
結(jié) O
婚 O
了。 O
(IOB是塊標(biāo)記的一種表示。B-表示開(kāi)始,I-表示內(nèi)部,O-表示外部)
首先明確的是NER是個(gè)分類(lèi)任務(wù),具體稱(chēng)為序列標(biāo)注任務(wù),即文本中不同的實(shí)體對(duì)應(yīng)不同的標(biāo)簽,人名-PER,地名-LOC,等等,相似的序列標(biāo)注任務(wù)還有詞性標(biāo)注、語(yǔ)義角色標(biāo)注。傳統(tǒng)的解決此類(lèi)問(wèn)題的方法,包括:(1)基于規(guī)則的方法。根據(jù)語(yǔ)言學(xué)上預(yù)定義的規(guī)則。但是由于語(yǔ)言結(jié)構(gòu)本身的不確定性,規(guī)則的制定上難度較大。(2)基于統(tǒng)計(jì)學(xué)的方法。利用統(tǒng)計(jì)學(xué)找出文本中存在的規(guī)律。主要有隱馬爾可夫(HMM)、條件隨機(jī)場(chǎng)(CRF)模型和Viterbi算法。文末會(huì)簡(jiǎn)要介紹比較流行的CRF模型。(3)神經(jīng)網(wǎng)絡(luò)。深度學(xué)習(xí)(多層神經(jīng)網(wǎng)絡(luò))這么流行,當(dāng)然不會(huì)放過(guò)nlp,之前我的一篇帖子(《深度學(xué)習(xí)在機(jī)器翻譯中的應(yīng)用》)里提到過(guò)循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)及其變種LSTM。因?yàn)槲谋镜纳舷挛囊蕾?lài)性,LSTM這種能夠存儲(chǔ)上下文信息的序列模型是較好的選擇(本文側(cè)重于CRF,LSTM的基本知識(shí)可參考《深度學(xué)習(xí)在機(jī)器翻譯中的應(yīng)用》)。
LSTM+CRF模型
語(yǔ)言文本的特殊之處在于其具有一定的結(jié)構(gòu),主謂賓定狀補(bǔ),狀語(yǔ)后置,非限制性定語(yǔ)從句等等。這些結(jié)構(gòu)的存在代表著每個(gè)單詞的前后是有著一定的詞性限制的。比如:
我現(xiàn)在回家 //這是常見(jiàn)的(主+狀+謂+賓)結(jié)構(gòu)的句子
我今天家 //這樣的文本就不能稱(chēng)為一個(gè)句子,少了必要的語(yǔ)法結(jié)構(gòu)
LSTM網(wǎng)絡(luò)是整體思路同樣是先對(duì)給定的訓(xùn)練樣本進(jìn)行學(xué)習(xí),確定模型中的參數(shù),再利用該模型對(duì)測(cè)試樣本進(jìn)行預(yù)測(cè)得到最后的輸出。由于測(cè)試輸出的準(zhǔn)確性現(xiàn)階段達(dá)不到100%,這就意味著,肯定存在一部分錯(cuò)誤的輸出,這些輸出里很可能就包含類(lèi)似于上述第二句話(huà)這種不符合語(yǔ)法規(guī)則的文本。因此,這就是為什么要將CRF模型引入進(jìn)來(lái)的原因。條件隨機(jī)場(chǎng)(CRF)是一種統(tǒng)計(jì)方法。其用于文本序列標(biāo)注的優(yōu)點(diǎn)就是上文所說(shuō)的對(duì)于輸出變量可以進(jìn)行約束,使其符合一定的語(yǔ)法規(guī)則。常見(jiàn)的神經(jīng)網(wǎng)絡(luò)對(duì)訓(xùn)練樣本的學(xué)習(xí),只考慮訓(xùn)練樣本的輸入,并不考慮訓(xùn)練樣本的輸出之間的關(guān)系。
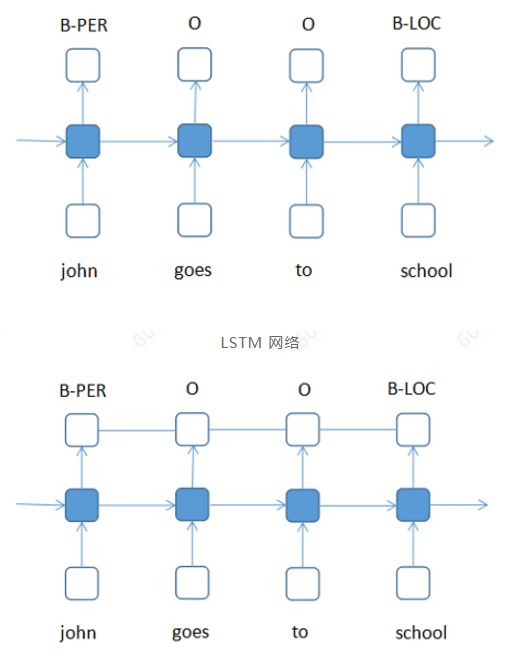
LSTM+CRF 網(wǎng)絡(luò)
LSTM 網(wǎng)絡(luò)可以看作是一個(gè)多分類(lèi)問(wèn)題,給定B、I、O等標(biāo)簽作為訓(xùn)練輸出,”john goes to school”等句子作為輸入,根據(jù)網(wǎng)絡(luò)模型計(jì)算的概率大小確定句子中的每個(gè)單詞屬于哪個(gè)標(biāo)簽(類(lèi)別),概率最大的即為該單詞最后所屬的標(biāo)簽(類(lèi)別),標(biāo)簽與標(biāo)簽之間是獨(dú)立的。LSTM+CRF則是在分類(lèi)問(wèn)題的基礎(chǔ)上,加上輸出之間的約束關(guān)系。比如”B”標(biāo)簽之后還是”B”,這種不符合語(yǔ)法規(guī)則的情況,通過(guò)CRF機(jī)制是可以排除的。目前,tensorflow 已支持LSTM+CRF的配置。(LSTM+CRF是深度學(xué)習(xí)中比較經(jīng)典的模型,當(dāng)前還有LSTM+cnn+CRF等其他的經(jīng)過(guò)優(yōu)化的模型)。
附:條件隨機(jī)場(chǎng)(CRF)原理
要完全搞懂CRF的原理,可以參考李航的《統(tǒng)計(jì)學(xué)習(xí)方法》的第11章。這里作簡(jiǎn)要說(shuō)明。CRF的基礎(chǔ)是馬爾可夫隨機(jī)場(chǎng),或者稱(chēng)為概率無(wú)向圖。
延伸
概率無(wú)向圖:用無(wú)向圖表示隨機(jī)變量的概率分布。
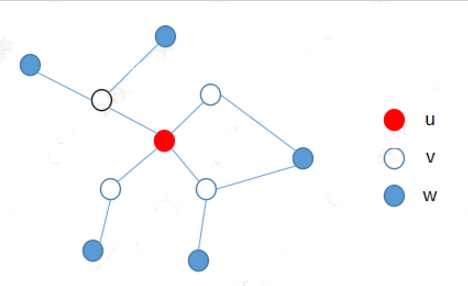
上圖就是滿(mǎn)足局部馬爾可夫性的概率無(wú)向圖。每個(gè)結(jié)點(diǎn)都代表著一個(gè)隨機(jī)變量,邊代表著隨機(jī)變量之間的關(guān)系。
局部馬爾可夫性:P(Yu|Yv)=P(Yu|Yv,Yw)簡(jiǎn)單理解,因?yàn)閅u和Yw之間沒(méi)有邊連接,則在給定隨機(jī)變量Yv條件下的Yu的概率,跟多加了一個(gè)Yw無(wú)關(guān)。
CRF的理解
CRF可以理解為在給定隨機(jī)變量X的條件下,隨機(jī)變量Y的馬爾可夫隨機(jī)場(chǎng)。其中,線(xiàn)性鏈CRF(一種特殊的CRF)可以用于序列標(biāo)注問(wèn)題。CRF模型在訓(xùn)練時(shí),給定訓(xùn)練序列樣本集(X,Y),通過(guò)極大似然估計(jì)、梯度下降等方法確定CRF模型的參數(shù);預(yù)測(cè)時(shí),給定輸入序列X,根據(jù)模型,求出P(Y|X)最大的序列y(這里注意,LSTM輸出的是一個(gè)個(gè)獨(dú)立的類(lèi)別,CRF輸出的是最優(yōu)的類(lèi)別序列,也就是CRF全局的優(yōu)化要更好一些)。
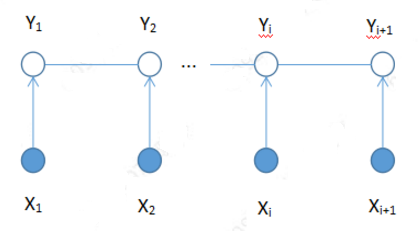
線(xiàn)性鏈條件隨機(jī)場(chǎng)(可以比較一下與上面LSTM+CRF網(wǎng)絡(luò)圖的區(qū)別與聯(lián)系)
為何CRF可以表示輸出序列內(nèi)各元素(Y1,Y2,…,Yi,Yi+1)之間的聯(lián)系?這里就是要聯(lián)系到馬爾可夫性。這也就是為什么CRF的基礎(chǔ)是馬爾可夫隨機(jī)場(chǎng)。CRF如何求解P(Y|X),有具體的數(shù)學(xué)公式,這里就不詳細(xì)列出了。
-
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122793 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
292瀏覽量
13654 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22621
原文標(biāo)題:干貨 | 深度學(xué)習(xí)在NLP的命名實(shí)體識(shí)別中(NER)的應(yīng)用
文章出處:【微信號(hào):ZTEdeveloper,微信公眾號(hào):中興開(kāi)發(fā)者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
自然語(yǔ)言基礎(chǔ)技術(shù)之命名實(shí)體識(shí)別相對(duì)全面的介紹
自然語(yǔ)言處理技術(shù)介紹
基于結(jié)構(gòu)化感知機(jī)的詞性標(biāo)注與命名實(shí)體識(shí)別框架
HanLP-命名實(shí)體識(shí)別總結(jié)
【推薦體驗(yàn)】騰訊云自然語(yǔ)言處理
基于神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)在命名實(shí)體識(shí)別中應(yīng)用的分析與總結(jié)

自然語(yǔ)言處理(NLP)的學(xué)習(xí)方向
思必馳中文命名實(shí)體識(shí)別任務(wù)助力AI落地應(yīng)用
命名實(shí)體識(shí)別的遷移學(xué)習(xí)相關(guān)研究分析

基于字語(yǔ)言模型的中文命名實(shí)體識(shí)別系統(tǒng)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論