") 研究人員為多模態(tài)NER任務(wù)提出新穎的關(guān)系增強(qiáng)圖卷積網(wǎng)絡(luò)
研究人員為多模態(tài)NER任務(wù)提出新穎的關(guān)系增強(qiáng)圖卷積網(wǎng)絡(luò)
命名實(shí)體識別(NER)是信息抽取的一項(xiàng)基本任務(wù),它的目的是識別文本片段中的實(shí)體及類型,如人名(PER),地名(LOC)和組織名(ORG)。命名實(shí)體識別在許多下游任務(wù)都有著廣泛的應(yīng)用,如實(shí)體鏈接和關(guān)系抽取。
最近,大多數(shù)關(guān)于NER的研究只依靠文本模態(tài)來推斷實(shí)體標(biāo)簽[3,4,5],然而,當(dāng)文本中包括多義實(shí)體時(shí),只依賴文本模態(tài)的信息來識別命名實(shí)體就變得非常困難[6,7]。一種有希望的解決方案是引入其他模態(tài)(比如圖像)作為文本模態(tài)的補(bǔ)充。如圖1所示,Twitter文本中出現(xiàn)的單詞“Alibaba”可以被識別為多種類型的實(shí)體,例如人名或組織名,但當(dāng)我們將單詞“Alibaba”與圖片中的視覺對象person對齊后,組織名就會被過濾掉。
從上面的例子中可以看出,將文本中的單詞與圖片中的視覺對象對齊是多模態(tài)命名實(shí)體識別任務(wù)(MNER)的核心。為此做了很多努力,大致可以分為以下三個(gè)方面:(1)將整張圖片編碼為一個(gè)全局特征向量,然后設(shè)計(jì)有效的注意力機(jī)制來提取與文本相關(guān)的視覺信息[6];(2)將整張圖片平均地分為多個(gè)視覺區(qū)域,然后顯式地建模文本序列與視覺區(qū)域之間的相關(guān)性[7,8,9,10,11,12];(3)僅保留圖片中的視覺對象區(qū)域,然后將其與文本序列進(jìn)行交互[13,14,15,16]。
盡管取得了很好的效果,但上述研究獨(dú)立地建模了一對圖片和文本中的內(nèi)部匹配關(guān)系,忽略了不同(圖片、文本)對之間的外部匹配關(guān)系。在這項(xiàng)工作中,我們認(rèn)為這種外部關(guān)系對于緩解 MNER 任務(wù)中的圖片噪聲至關(guān)重要。具體來說,我們探索了數(shù)據(jù)集中的兩種外部匹配關(guān)系:
模態(tài)間關(guān)系(Inter-modal relation):從文本的角度來看,一段文本可能與數(shù)據(jù)集中的多張圖片存在關(guān)聯(lián),當(dāng)文本中的命名實(shí)體沒有出現(xiàn)在相應(yīng)的圖片中時(shí),其它相關(guān)圖片通常對識別文本中的命名實(shí)體是有幫助的。如圖2(b)所示,句子S2中的命名實(shí)體"Trump"沒有出現(xiàn)在相應(yīng)的圖片中,因此僅僅依靠非正式的句子S2很難推斷出命名實(shí)體標(biāo)簽。然而,當(dāng)考慮到與句子 S2 密切相關(guān)的其他圖片時(shí)(例如圖2(a)和2(c)),句子S2中的命名實(shí)體標(biāo)簽大概率是“PER”,因?yàn)檫@些相關(guān)的圖片中都包含了視覺對象person。因此,一個(gè)可行且自然的方法是建立不同(圖片、文本)對中圖片與文本之間的關(guān)聯(lián);
模態(tài)內(nèi)關(guān)系(Intra-modal relation):從圖片的角度來看,不同的圖片中往往包含著相同類型的視覺對象,清晰的視覺對象區(qū)域比模糊的視覺對象區(qū)域更容易識別命名實(shí)體標(biāo)簽。例如,圖2(d)與2(e)中都包含了視覺對象person,雖然通過圖2(d)中模糊的視覺對象區(qū)域來推斷句子 S4 中的命名實(shí)體標(biāo)簽相對困難,但我們根據(jù)圖2(e)可以推斷出句子S4中的命名實(shí)體標(biāo)簽很可能是“PER”,因?yàn)閳D2(e)中清晰的視覺對象更容易推斷出命名實(shí)體標(biāo)簽"PER"。因此,一個(gè)可行且自然的方法是建立不同(圖片、文本)對中圖片之間的關(guān)聯(lián);
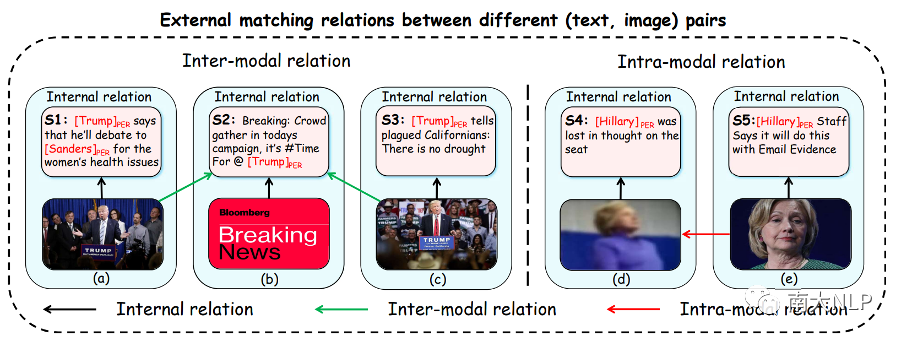
圖:每個(gè)藍(lán)色框包含數(shù)據(jù)集中的一對圖片和文本。命名實(shí)體及其對應(yīng)的實(shí)體類型在文本中突出顯示。黑色箭頭表示圖像-文本對中的內(nèi)部匹配關(guān)系。綠色箭頭表示不同圖文對中圖片和文本之間的模態(tài)間關(guān)系,紅色箭頭表示不同圖文對中圖片之間的模態(tài)內(nèi)關(guān)系
為了更好地建模上述兩種外部匹配關(guān)系,我們提出了一個(gè)用于多模態(tài)NER任務(wù)的關(guān)系增強(qiáng)圖卷積網(wǎng)絡(luò)(R-GCN)。具體來說,R-GCN主要包括兩個(gè)模塊:第一個(gè)模塊構(gòu)建了一個(gè)模態(tài)內(nèi)關(guān)系圖和一個(gè)模態(tài)間關(guān)系圖分別來收集數(shù)據(jù)集中與當(dāng)前圖片和文本最相關(guān)的圖片信息。第二個(gè)模塊執(zhí)行多模態(tài)交互和融合,最終預(yù)測 NER 的標(biāo)簽序列。廣泛的實(shí)驗(yàn)結(jié)果表明,我們的R-GCN網(wǎng)絡(luò)在兩個(gè)基準(zhǔn)數(shù)據(jù)集上始終優(yōu)于當(dāng)前最先進(jìn)的工作。
貢獻(xiàn)
1.據(jù)我們所知,我們是第一個(gè)提出利用不同(圖片、文本)對之間的外部匹配關(guān)系來提升MNER任務(wù)性能的工作;
2. 我們設(shè)計(jì)了一個(gè)關(guān)系增強(qiáng)的圖卷積神經(jīng)網(wǎng)絡(luò)來同時(shí)建模模態(tài)間關(guān)系和模態(tài)內(nèi)關(guān)系;
3. 我們在兩個(gè)基準(zhǔn)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果都達(dá)到了最先進(jìn)的性能,進(jìn)一步的實(shí)驗(yàn)分析驗(yàn)證了我們方法的有效性;
解決方案
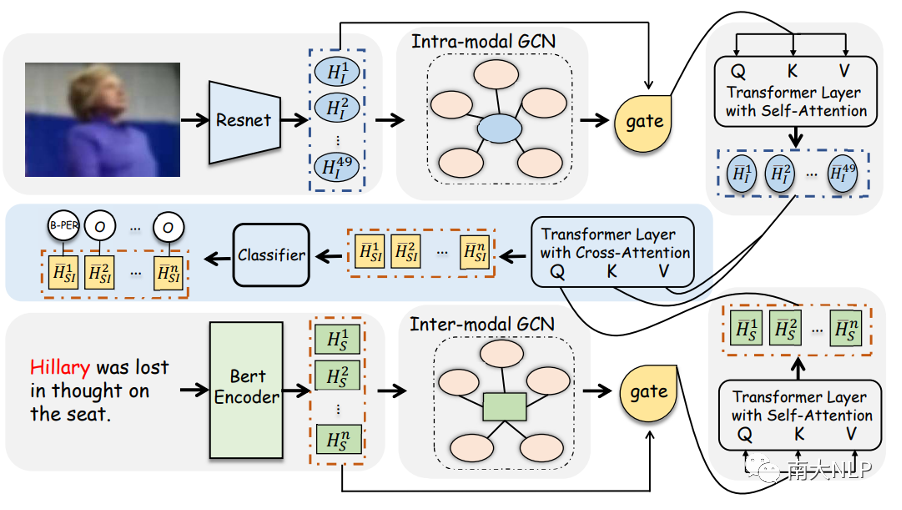
圖3:R-GCN模型的整體架構(gòu)
在本文中,我們提出了關(guān)系增強(qiáng)的圖卷積神經(jīng)網(wǎng)絡(luò)R-GCN來建模兩種外部匹配關(guān)系,圖3展示了該模型的整體架構(gòu)。它主要由四個(gè)模塊組成:(1) 模態(tài)間關(guān)系模塊;(2) 模態(tài)內(nèi)關(guān)系模塊;(3)多模態(tài)交互模塊;(4)CRF解碼模塊。下面,我們主要介紹前兩個(gè)核心模塊。
模態(tài)間關(guān)系:根據(jù)我們的觀察,一段文本可能與數(shù)據(jù)集中的多張圖片存在關(guān)聯(lián),當(dāng)文本中的命名實(shí)體沒有出現(xiàn)在相應(yīng)的圖片中時(shí),其它相關(guān)圖片通常對識別文本中的命名實(shí)體是有幫助的。為此,我們提出了模態(tài)間關(guān)系圖從數(shù)據(jù)集中收集與輸入句子具有相似含義的其他圖片。下面,我們將詳細(xì)介紹如何構(gòu)建模態(tài)間關(guān)系圖的頂點(diǎn)和邊:
頂點(diǎn):模態(tài)間關(guān)系圖中有兩種類型的頂點(diǎn),分別是文本節(jié)點(diǎn)和圖片節(jié)點(diǎn)。文本結(jié)點(diǎn)作為中心節(jié)點(diǎn),它通過將句子輸入到預(yù)訓(xùn)練模型BERT中得到,而圖片節(jié)點(diǎn)是從預(yù)訓(xùn)練模型 ResNet [17]中提取的圖片表示,旨在為中心節(jié)點(diǎn)提供輔助信息。
邊:我們的目標(biāo)是衡量數(shù)據(jù)集中其他圖片是否包含輸入句子中提及的相似場景。然而,由于圖片與文本之間存在天然的語義鴻溝,因此實(shí)現(xiàn)這個(gè)目標(biāo)并不容易。為此,我們首先利用image caption模型[18]將圖片轉(zhuǎn)化為文本描述,然后將輸入句子和文本描述之間的cos相似度視為文本節(jié)點(diǎn)和圖片節(jié)點(diǎn)之間的邊。
模態(tài)內(nèi)關(guān)系:就像前面提到的,當(dāng)不同的圖片中包含著相同類型的視覺對象時(shí),清晰的視覺對象區(qū)域比模糊的視覺對象區(qū)域更容易識別文本中的命名實(shí)體標(biāo)簽。為此,我們建立了一個(gè)模態(tài)內(nèi)關(guān)系圖從數(shù)據(jù)集中收集與輸入圖片包含相同類型視覺對象的其它圖片。下面,我們將詳細(xì)介紹如何構(gòu)建模態(tài)內(nèi)關(guān)系圖的頂點(diǎn)和邊:
頂點(diǎn):對于數(shù)據(jù)集中的每張圖片,我們將從預(yù)訓(xùn)練ResNet中提取的圖片特征作為圖片節(jié)點(diǎn),其中當(dāng)前輸入圖片對應(yīng)的特征表示作為中心節(jié)點(diǎn)。
邊:我們的目標(biāo)是衡量數(shù)據(jù)集中的其他圖片是否包含與輸入圖片相同類型的視覺對象。顯然,ResNet沒有能力獲得圖片中的視覺對象區(qū)域。因此,我們首先利用目標(biāo)檢測模型Faster-RCNN為每張圖片生成一組視覺對象,然后將輸入圖片和數(shù)據(jù)集中其它圖片的視覺對象表示之間的余弦相似度作為圖片節(jié)點(diǎn)之間的邊。
我們使用圖卷積神經(jīng)網(wǎng)絡(luò)來建模這兩種外部匹配關(guān)系,為每個(gè)模態(tài)生成關(guān)系增強(qiáng)的特征向量。此外,和以前的方法一樣,我們通過多模態(tài)交互模塊建模了圖片和文本之間的內(nèi)部匹配關(guān)系,最后,我們使用條件隨機(jī)場[4]對文本表示進(jìn)行解碼,識別出文本序列中包含的命名實(shí)體。
實(shí)驗(yàn)
我們在兩個(gè)公開的數(shù)據(jù)集Twitter2015和Twitter2017上進(jìn)行實(shí)驗(yàn),結(jié)果如表 1 所示,我們報(bào)告了整體的Precision, Recall和F1 score,以及每種實(shí)體類型的F1 score。與之前的工作一樣,我們主要關(guān)注整體的F1 score。實(shí)驗(yàn)結(jié)果表明,與UMT和UMGF等多模態(tài)NER模型相比,R-GCN在兩個(gè)數(shù)據(jù)集上都取得了有競爭力的結(jié)果。值得一提的是,我們的R-GCN模型在F1 score上分別超出了目前性能最好的模型UMGF 1.48%和1.97%。此外,從單個(gè)實(shí)體類型來看,R-GCN在Twitter2015數(shù)據(jù)集上最多超過UMGF 1.86%,在Twitter2017數(shù)據(jù)集上最多超過UMGF 5.08%。這些結(jié)果驗(yàn)證了我們模型的有效性。
表1:主實(shí)驗(yàn)結(jié)果
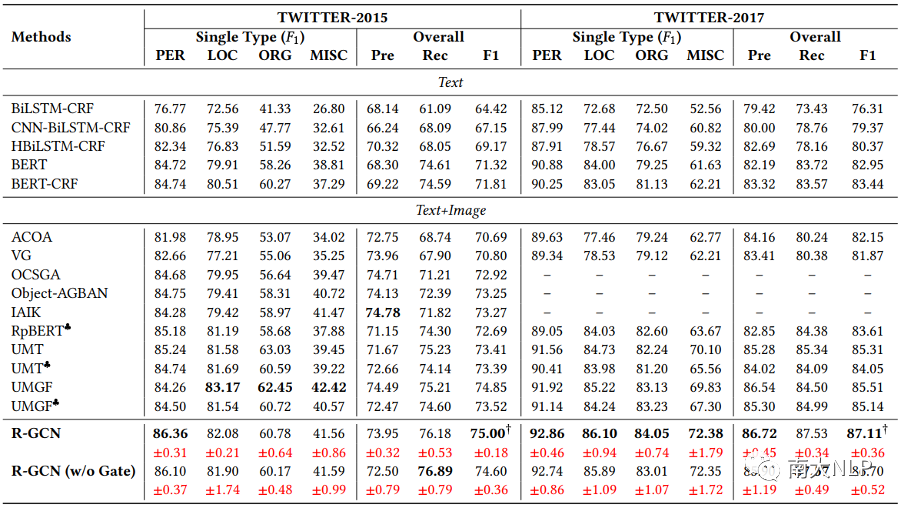
表2:模態(tài)內(nèi)關(guān)系模塊和模態(tài)間關(guān)系模塊的消融實(shí)驗(yàn)結(jié)果

為了研究單個(gè)模塊和多個(gè)模塊的組合對模型整體效果的影響,我們對 R-GCN 中的兩個(gè)模塊進(jìn)行了消融研究,即模態(tài)內(nèi)關(guān)系模塊(IntraRG)和模態(tài)間關(guān)系模塊(InterRG),從表2中我們可以得出以下結(jié)論:
1. 移除任意一個(gè)模塊都會使總體性能變差,這驗(yàn)證了利用數(shù)據(jù)集中不同(圖片,文本)對中的外部匹配關(guān)系來提升MNER任務(wù)性能的合理性。同時(shí)移除IntraRG和InterRG模塊后性能進(jìn)一步下降,這說明IntraRG和InterRG這兩個(gè)模塊從不同的視角提升了MNER任務(wù)的性能;
2. 與Intra-RG相比較,Inter-RG對R-GCN模型的影響更大。這是因?yàn)槲覀冎饕揽课谋拘蛄衼眍A(yù)測NER標(biāo)簽。因此,將相似的圖片信息聚集到文本序列中對我們模型的貢獻(xiàn)更大,這與我們的期望是一致的。
案例分析
為了更好的理解IntraRG模塊和InterRG模塊的作用,我們定性地比較了我們的方法與當(dāng)前性能最好的兩個(gè)方法UMT和UMGF的結(jié)果。在圖4(a)中,句子中的命名實(shí)體“KyrieIrving”沒有出現(xiàn)在對應(yīng)的圖片中,所以UMT和UMGF錯(cuò)誤地將該實(shí)體預(yù)測為了“MISC”。然而,在InterRG模塊的幫助下,該句子可以與數(shù)據(jù)集中的其他圖片建立聯(lián)系,考慮到這些相關(guān)的圖片中都包含了視覺對象person,因此模型給出了正確的標(biāo)簽預(yù)測“PER”。在圖4(b)中,顯然視覺對象區(qū)域是模糊的,這為命名實(shí)體的識別帶來了很大的挑戰(zhàn),因此UMT和UMGF都認(rèn)為句子中沒有命名實(shí)體。但是在 IntraRG 的幫助下,我們將包含清晰視覺對象區(qū)域的相似圖片聚合到當(dāng)前圖片中從而做出正確的預(yù)測,因?yàn)檫@些清晰的視覺對象區(qū)域降低了識別命名實(shí)體的難度。
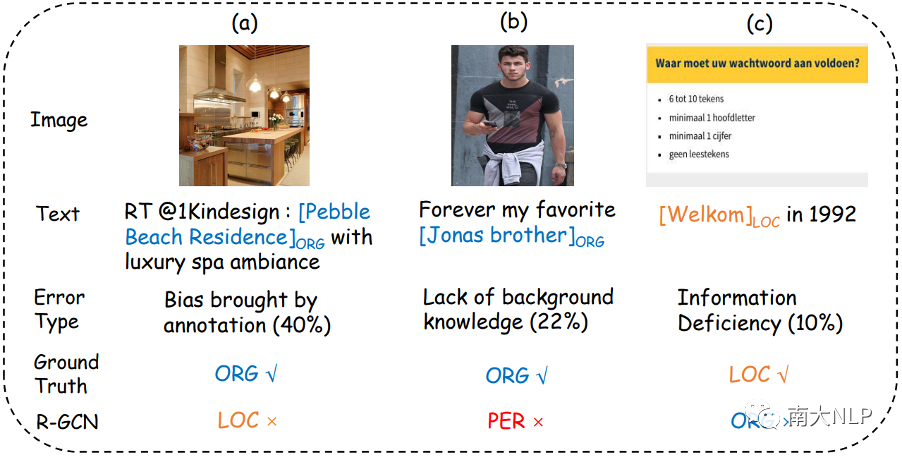
圖:錯(cuò)誤類型分析
此外,我們還對模型進(jìn)行了錯(cuò)誤分析。具體來說,我們隨機(jī)抽取了R-GCN模型預(yù)測錯(cuò)誤的100個(gè)樣例,并將其歸納為三種錯(cuò)誤類型。圖5展示了每種錯(cuò)誤類型的比例以及一些代表性示例。
1. 第一類為標(biāo)注帶來的偏差,在圖5(a)中,命名實(shí)體“Pebble Beach Residence”被標(biāo)注為“ORG”,但如果我們將其標(biāo)注為“LOC”也是合理的,在這種情況下,我們的模型很難區(qū)分它們,因?yàn)樗鼈兌际钦_的。
2.第二類為背景知識缺乏,在圖5(b)中,命名實(shí)體“Jonas brother”是一個(gè)著名樂隊(duì)的名字,在缺乏背景知識的情況下,模型很容易將該實(shí)體識別為“PER”
3. 第三類為信息缺失,在圖5(c)中,句子非常的短,圖片中的內(nèi)容也很簡單,它們不能為模型提供足夠的信息來判斷實(shí)體類型。
對于這幾類典型的錯(cuò)誤,未來應(yīng)該會有更先進(jìn)的自然語言處理技術(shù)來解決它們。
總結(jié)
在本文中,我們?yōu)槎嗄B(tài)NER任務(wù)提出了一個(gè)新穎的關(guān)系增強(qiáng)圖卷積網(wǎng)絡(luò)。我們方法的主要思想是利用不同(圖像、文本)對中的兩種外部匹配關(guān)系(即模態(tài)間關(guān)系和模態(tài)內(nèi)關(guān)系)來提高識別文本中命名實(shí)體的能力。大量實(shí)驗(yàn)的結(jié)果表明,我們的模型比其他先進(jìn)的方法具有更好的性能。進(jìn)一步的分析也驗(yàn)證了R-GCN模型的有效性。
在未來,我們希望將我們的方法應(yīng)用到其他多模態(tài)任務(wù)中,比如多模態(tài)對話或者多模態(tài)蘊(yùn)含。
-
模型
+關(guān)注
關(guān)注
1文章
3477瀏覽量
49922 -
NER
+關(guān)注
關(guān)注
0文章
7瀏覽量
6289 -
圖卷積網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
8瀏覽量
1556
原文標(biāo)題:ACMMM2022 | 從不同的文本圖片對中學(xué)習(xí):用于多模態(tài)NER的關(guān)系增強(qiáng)圖卷積網(wǎng)絡(luò)
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
卷積神經(jīng)網(wǎng)絡(luò)模型發(fā)展及應(yīng)用
卷積神經(jīng)網(wǎng)絡(luò)的振動(dòng)信號模態(tài)參數(shù)識別
如何使用多尺度多任務(wù)卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行人群計(jì)數(shù)的詳細(xì)資料說明

什么是圖卷積網(wǎng)絡(luò)?為什么要研究GCN?
研究人員們提出了一系列新的點(diǎn)云處理模塊

使用多尺度多任務(wù)卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行人群計(jì)數(shù)的資料說明
用圖卷積網(wǎng)絡(luò)解決語義分割問題
基于圖卷積的層級圖網(wǎng)絡(luò)用于基于點(diǎn)云的3D目標(biāo)檢測
研究人員研發(fā)一種讓自動(dòng)駕駛汽車免受網(wǎng)絡(luò)攻擊的系統(tǒng)
如何使用多尺度和多任務(wù)卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)人群計(jì)數(shù)
基于三維密集卷積網(wǎng)絡(luò)的多模態(tài)手勢識別方法
基于深度圖卷積膠囊網(wǎng)絡(luò)融合的圖分類模型
基于多列卷積神經(jīng)網(wǎng)絡(luò)的人群計(jì)數(shù)算法
一種基于因果路徑的層次圖卷積注意力網(wǎng)絡(luò)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論