") 行業(yè)觀察——邊緣AI芯片架構的思考:為何可擴展GPU架構值得關注
行業(yè)觀察——邊緣AI芯片架構的思考:為何可擴展GPU架構值得關注
作者:北京華興萬邦管理咨詢有限公司 翔煜 商瑞
隨著大模型在不斷演進的同時將推理應用大規(guī)模推向邊緣和端點設備,以及物聯(lián)網(wǎng)智化、具身智能、AI智能體(AI Agent)和物理AI等新的AI應用場景和模式的快速涌現(xiàn),AI賦能設備的主控芯片設計師正面臨著全新的挑戰(zhàn)。尤其是對于邊緣和端點設備,它們既可能成為大模型的承載設備,也可能是用智能去為應用提供更好的核心功能,新的產(chǎn)品定義方向使主芯片架構師不得不去思考,其芯片在如何應對大模型快速演進的同時,還能實現(xiàn)用智能手段賦能傳統(tǒng)應用和實現(xiàn)新興功能。
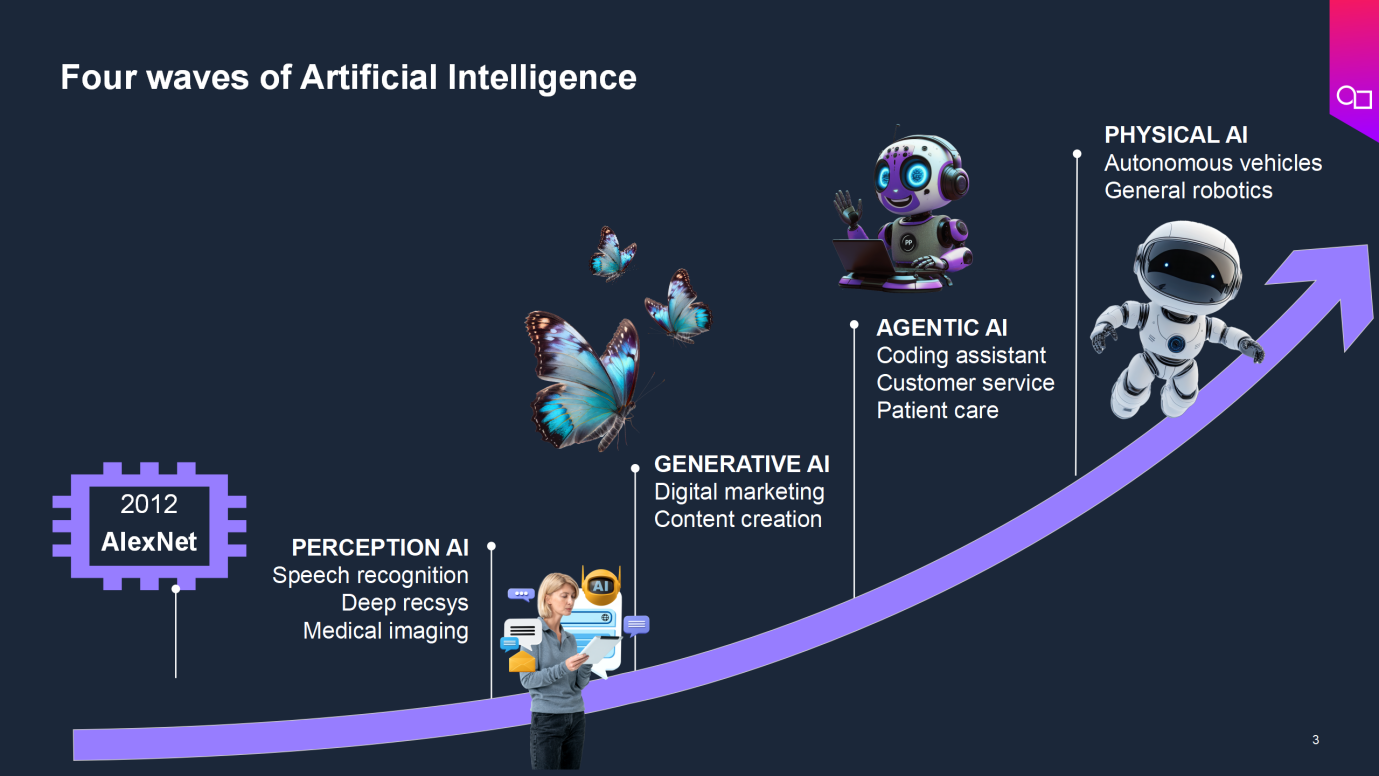
因此,在追求極致性能、功耗和面積(PPA)的模式之外,架構師們需要富有前瞻性地去選擇高性能、高靈活性、可升級和開發(fā)者(生態(tài))友好的架構。我們不妨先回顧AI發(fā)展的歷程,從感知AI到生成式AI,再到智能體AI和物理AI,其應用場景不斷拓展。在感知AI階段,Al技術在語音識別、深度推薦系統(tǒng)和醫(yī)學影像等領域取得顯著進展;生成式AI在數(shù)字營銷和內(nèi)容創(chuàng)作方面發(fā)揮了重要作用;智能體AI為編程、客戶服務、患者護理提供助力;物理AI推動了自動駕駛汽車和通用機器人發(fā)展。
伴隨著AI技術的發(fā)展,在傳統(tǒng)的CPU、GPU和FPGA等計算技術之外,諸如TPU、NPU 和DPU等專門針對特定算法或者模型的新型硬件數(shù)據(jù)處理加速器也開始出現(xiàn),它們帶來高效率因而在許多場景中得到了應用。與此同時,AI技術不斷向新的場景和應用廣泛滲透,使得面向特定模型和場景的NPU等架構難以應對模型的變化和場景的多樣化,從而使傳統(tǒng)的 靈活性更高的CPU和GPU架構依舊在計算領域占據(jù)重要地位。
但是,AI技術的進步和新場景的出現(xiàn),正在迫使半導體知識產(chǎn)權(IP)提供商和芯片設計公司快速做出變化,無論是采用傳統(tǒng)架構的廠商,還是新的xPU提供商都需要尊重產(chǎn)業(yè)規(guī)律。華興萬邦亦認為,從技術經(jīng)濟學和企業(yè)實際經(jīng)營來看,高額的研發(fā)費用和市場營銷費用是多數(shù)芯片設計企業(yè)面臨的最重要費用,而靈活可擴展的架構可以覆蓋更廣的市場并可以實現(xiàn)更長的產(chǎn)品生命周期,它們是攤銷這些費用以提升盈利能力的重要手段。
架構創(chuàng)新迫在眉睫
Imagination Technologies中國業(yè)務發(fā)展負責人黃音在慕尼黑電子展AI技術創(chuàng)新論壇演講中分析道:“當前主芯片設計不僅需要芯片企業(yè)投入大量研發(fā)資源,更需要協(xié)調(diào)生態(tài)合作伙伴的技術路線。面對AI算法快速迭代的挑戰(zhàn),行業(yè)在探索創(chuàng)新架構的同時,仍需重視經(jīng)過長期驗證的基礎計算架構價值。以GPU為例,其架構在保持高并行計算優(yōu)勢的同時,新一代設計正通過模塊化擴展能力(如可配置Shader集群、彈性內(nèi)存子系統(tǒng))來適應不同AI工作負載需求。作為專注圖形計算領域的IP廠商,Imagination觀察到,理想的AI加速架構需要在三個維度取得平衡:支持細粒度并行的計算單元設計、滿足算法動態(tài)調(diào)整的可配置性,以及維持開發(fā)工具鏈的持續(xù)兼容性。”

“擴展能力是Imagination GPU開發(fā)演進的方向:在具備強大的渲染能力的同時,融合AI并行計算能力,在邊緣AI的場景下能提供靈活又高效的算力。所以,Imagination將幫助芯片設計人員發(fā)現(xiàn)真正的破局點,幫助他們?nèi)嫿ㄒ粋€可以持續(xù)適配模型和算法演進、以及支持新興應用的架構平臺——而不是為某個模型做一次性的‘專用硬件定制’,從而避免硬件(處理器)總是費力費錢跟著算法跑的問題。”黃音補充道。
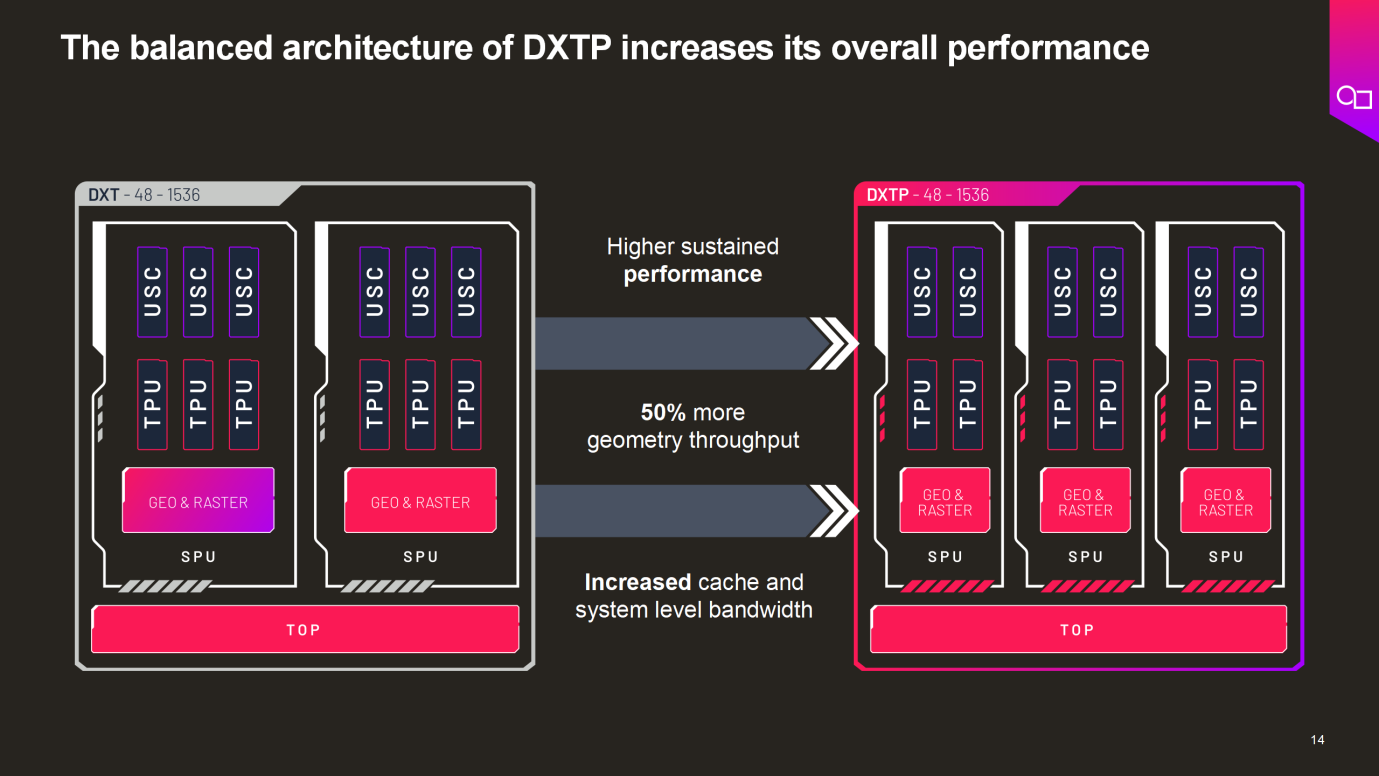
Imagination正在幫助客戶導入更加靈活的架構。以該公司不久前發(fā)布的Imagination DXTP GPU IP為例,它采用了先進的平衡架構,增加了緩存和系統(tǒng)級帶寬,實現(xiàn)了更高的持續(xù)性能,幾何吞吐量提高50%,不僅能夠輕松同時處理圖形和計算任務,而且其功率效率還較其前序產(chǎn)品提升了20%,為邊緣AI提供了理想的GPU平臺。DXTP GPU已經(jīng)被全球知名科技公司采用,用于對AI 多數(shù)據(jù)類型處理、計算任務加速和本地內(nèi)存的支持。
三個落地是成功的關鍵
當然,對于芯片設計師而言,這需要做到三個必須“落地”,即模型算法落地、垂直功能落地和開放生態(tài)落地。針對模型算法落地,Imagination的突破點是堅持構建一個通用可編程的并行架構平臺,并通過開放的編譯器和推理后端(backend),支持客戶軟硬件協(xié)同設計和提供適配路徑,幫助其客戶把諸如Transformer、Diffusion類模型和前沿算法快速落地到GPU上。為此該公司將幫助客戶認識到在算法不斷演化的時代,架構的“適配力”遠比一時的TOPS值更重要。
在垂直功能落地方面,Imagination在移動、汽車、云和桌面等領域深耕了數(shù)十年,積累了豐富的經(jīng)驗和許多創(chuàng)新的支撐性技術,可以幫助客戶去避開其中的潛在風險和快速在領域內(nèi)創(chuàng)造優(yōu)勢,這可以從該公司的D系列GPU IP的產(chǎn)品功能創(chuàng)新上可以看出其垂直領域功能落地能力。例如,DXT GPU是Imagination面向移動應用、高端游戲和專業(yè)圖形設計等應用推出的新一代GPU IP,它不僅率先在移動平臺上提供了可擴展的光線追蹤功能,還有2D雙速率紋理映射等多項可以提升處理速度和優(yōu)化內(nèi)存帶寬的技術。
為了幫助桌面和數(shù)據(jù)中心客戶實現(xiàn)高性能的云端GPU創(chuàng)新解決方案,Imagination推出了DXD GPU IP,首次將Imagination的API覆蓋擴展至DirectX,這一舉措顯著提升了DXD與Windows平臺上的應用程序和游戲的兼容性。同時,Imagination的硬件虛擬化技術 HyperLane支持在單個GPU上安全且獨立地運行多個操作系統(tǒng),極大地提升了服務器的使用效率,降低了云游戲的運營成本,并為云游戲行業(yè)的發(fā)展帶來了創(chuàng)新的運營模式。
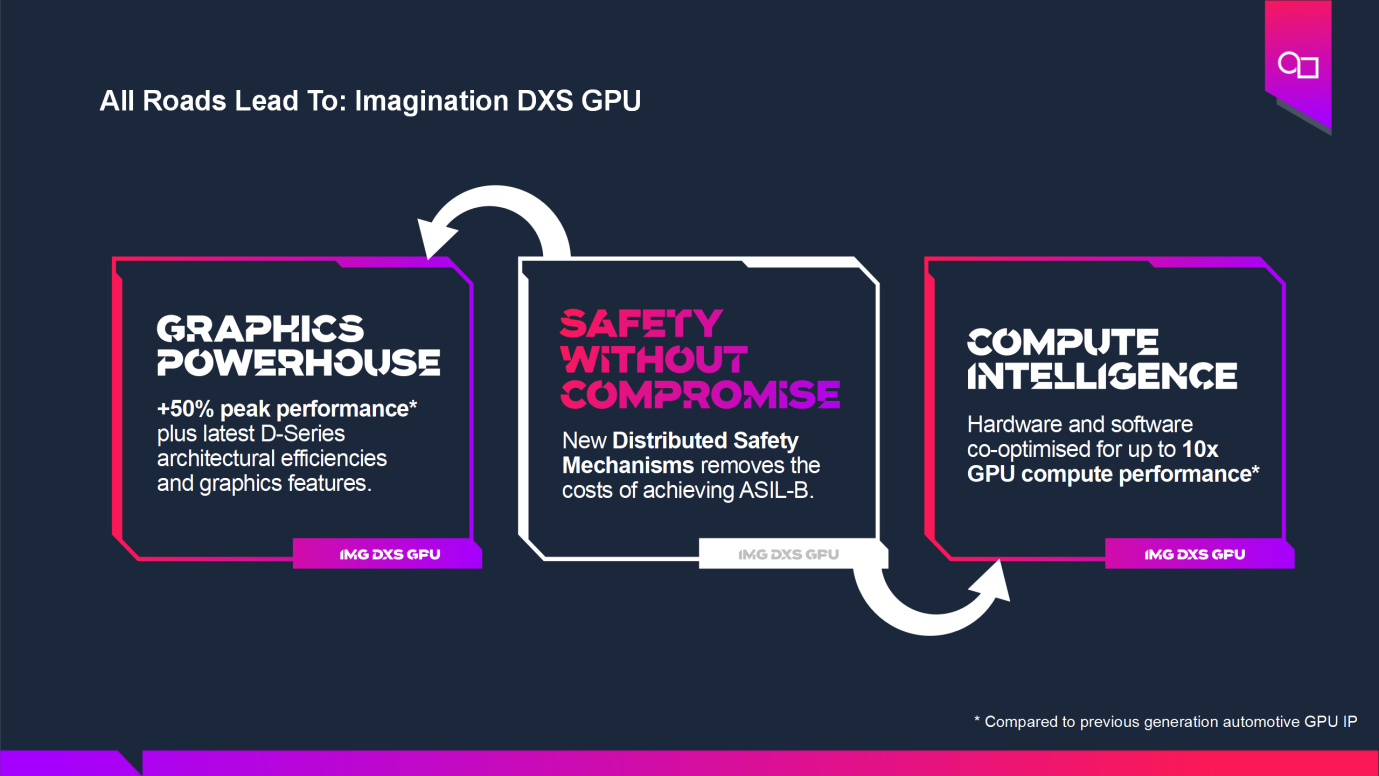
Imagination為汽車智駕芯片提供的專用IP是該公司支持芯片設計企業(yè)垂直功能落地的又一個典范,血的教訓換來了更加嚴格的安全法規(guī),使智駕芯片設計公司在算力、生態(tài)和生命周期之外,必須去認真去考慮功能安全性。為了幫助芯片設計企業(yè)滿足全球汽車智能化需求,Imagination推出了DXS系列GPU,該系列IP不僅為智能駕駛艙和先進駕駛輔助(ADAS)等應用所需SoC帶來匹配的算力,而且專為諸如汽車處理器等對功能安全性要求極為嚴苛的應用,開發(fā)了結(jié)合GPU的計算模式特點并大幅降低成本的分布式功能安全機制(DSM)并通過了ASIL-B認證。這為汽車和工業(yè)等越來越多需要GPU的圖形處理能力和計算能力的電子系統(tǒng)帶來了巨大的創(chuàng)新。
Imagination在支持客戶實現(xiàn)產(chǎn)業(yè)生態(tài)落地方面也同樣頗費心機,其GPU IP全面支持OpenCL、SYCL、Vulkan Compute等開放標準,與PyTorch、TensorFlow等主流框架完美兼容。如Imagination通過與安卓生態(tài)系統(tǒng)合作,優(yōu)化對LiteRT的支持,為開發(fā)者提供豐富工具和示例,便于開發(fā)高性能AI應用,充分展現(xiàn)了其GPU架構的適配能力。這種開放生態(tài)簡化了新硬件與設備的集成流程,避免供應商鎖定問題,使客戶能在不同平臺輕松部署。通過整合多方資源,Imagination可幫助客戶實現(xiàn)協(xié)同優(yōu)化,提升資源利用率和執(zhí)行效率,鞏固了其在GPU市場的領先地位,為企業(yè)應對AI算法和產(chǎn)品快速迭代提供堅實支持。
總結(jié)與展望
大模型的下沉、算法創(chuàng)新和邊緣及端側(cè)AI的崛起為基于 GPU的主控芯片帶來了新的發(fā)展契機,在AI一體機、新物聯(lián)網(wǎng)、智能安防和自動駕駛等領域已經(jīng)出現(xiàn)了巨大的需求,這些設備對高性能的圖形處理和AI推理同時都有越來越多的需求,因此更靈活和可擴展的架構可以使芯片設計公司的產(chǎn)品覆蓋更廣泛的市場領域,同時可以擁有更長的產(chǎn)品生命周期,也就有了更高的潛在盈利能力。
審核編輯 黃宇
-
gpu
+關注
關注
28文章
4909瀏覽量
130649 -
AI
+關注
關注
87文章
34178瀏覽量
275341 -
AI芯片
+關注
關注
17文章
1968瀏覽量
35689
發(fā)布評論請先 登錄
GPU架構深度解析

iTOP-3588S開發(fā)板四核心架構GPU內(nèi)置GPU可以完全兼容0penGLES1.1、2.0和3.2。
北京市最值得去的十家半導體芯片公司
AI賦能邊緣網(wǎng)關:開啟智能時代的新藍海
芯原發(fā)布新一代Vitality架構GPU IP系列
芯原推出新一代高性能Vitality架構GPU IP系列
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
GPU服務器AI網(wǎng)絡架構設計

《算力芯片 高性能 CPUGPUNPU 微架構分析》第二篇閱讀心得:芯片拓撲學:并行擴展與CPU設計的巨頭對決
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
AI芯片的混合精度計算與靈活可擴展
自動駕駛?cè)笾髁?b class='flag-5'>芯片架構分析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論