") 展望PostgreSQL 18的新特性
展望PostgreSQL 18的新特性

作者: xiongcc,來(lái)源:PostgreSQL學(xué)徒
前言
距離 PostgreSQL 17 正式發(fā)布已近半年,按照每年發(fā)布一個(gè)大版本的慣例,PostgreSQL 18 預(yù)計(jì)將在 2025 年底發(fā)布。距離正式發(fā)布還有一段時(shí)間,社區(qū)的開(kāi)發(fā)工作仍在如火如荼地進(jìn)行中。
雖然本文中列舉的許多新特性最終可能會(huì)有變化,但這并不妨礙我們展望 PostgreSQL 18 中可能引入的新特性,讓我們一覽為快 ~
可觀測(cè)性
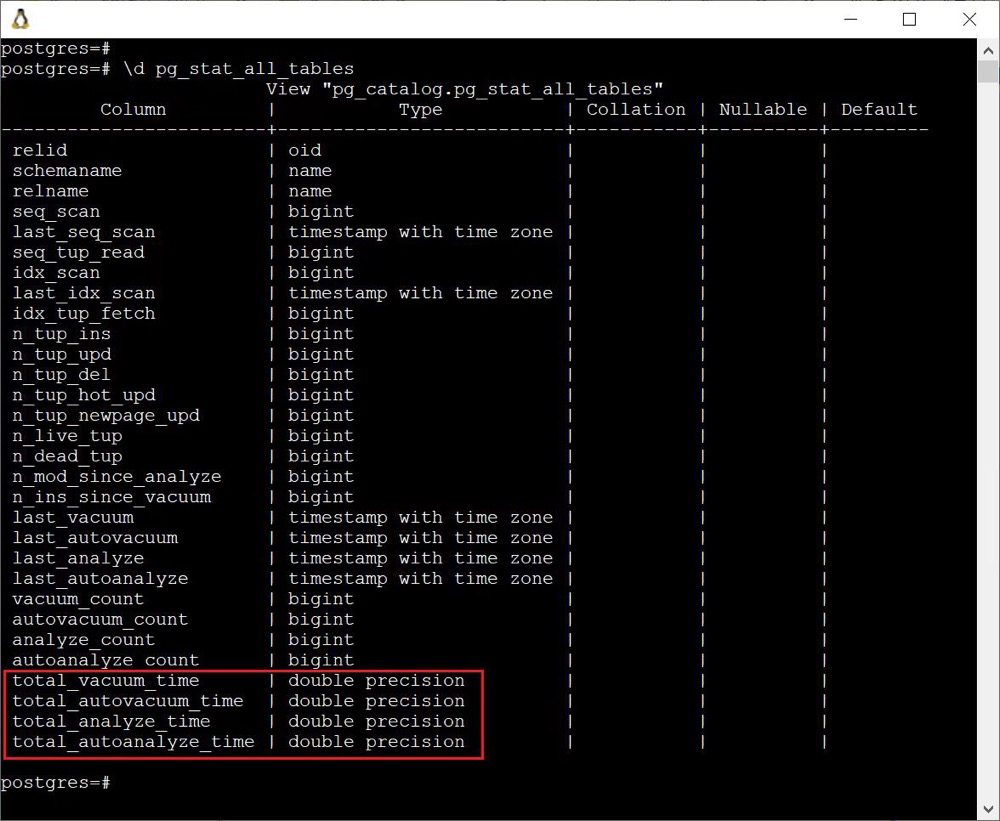
pg_stat_all_tables
在 pg_stat_all_tables 中新增了 (auto) vacuum 和 (auto) analyze 的相關(guān)耗時(shí)指標(biāo),這對(duì)于我們?cè)\斷 VACUUM 問(wèn)題的時(shí)候無(wú)疑大有裨益。
內(nèi)存上下文
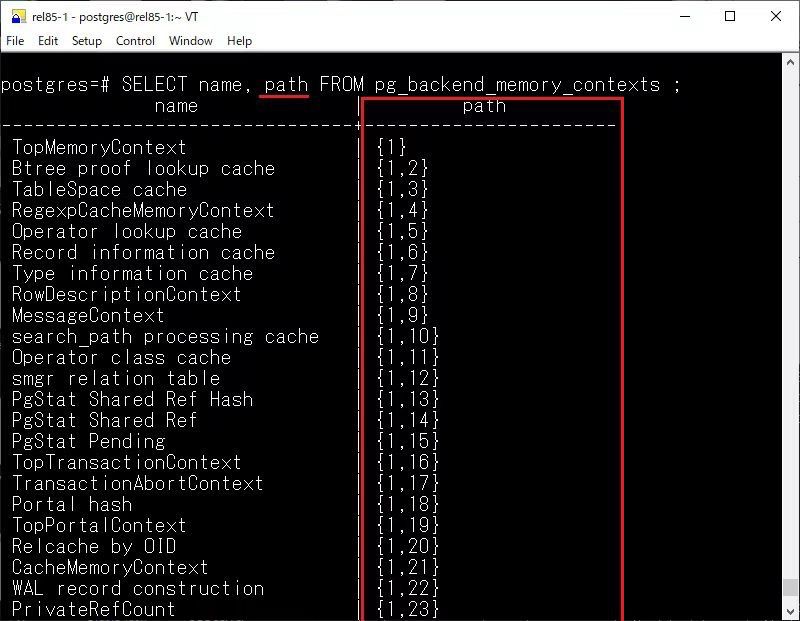
在 pg_backend_memory_contexts 視圖中新增了 type、path 和 parent 三個(gè)字段,關(guān)于內(nèi)存上下文就不再贅述,感興趣的可以閱讀:https://smartkeyerror.com/PostgreSQL-MemoryContext[1]

pg_stat_checkpointer
在 pg_stat_checkpointer 視圖中,新增了 num_done 字段,pg_stat_checkpointer 中現(xiàn)有的 num_timed 和 num_requested 計(jì)數(shù)器用于跟蹤已完成和跳過(guò)的檢查點(diǎn),但無(wú)法僅計(jì)數(shù)已完成的檢查點(diǎn)。
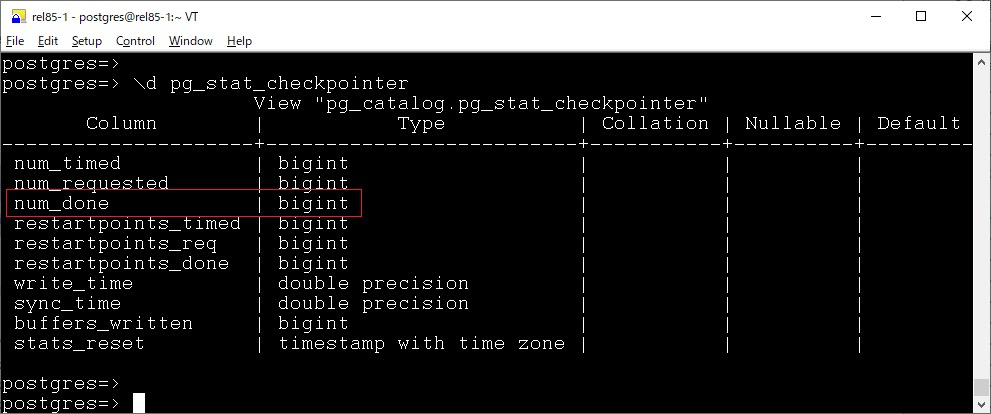
因?yàn)樵?PostgreSQL 中,檢查點(diǎn)也有 skip 機(jī)制,當(dāng)非停庫(kù)、REDO 完成或者強(qiáng)制觸發(fā)檢查點(diǎn)時(shí),如果數(shù)據(jù)庫(kù)沒(méi)有寫(xiě)入操作,則直接返回,不需要再去遍歷一下 shared buffer 去刷臟,提升檢查點(diǎn)的性能。
/*
* If this isn't a shutdown or forced checkpoint, and if there has been no
* WAL activity requiring a checkpoint, skip it. The idea here is to
* avoid inserting duplicate checkpoints when the system is idle.
*/
if((flags & (CHECKPOINT_IS_SHUTDOWN | CHECKPOINT_END_OF_RECOVERY |
CHECKPOINT_FORCE)) ==0)
{
if(last_important_lsn == ControlFile->checkPoint)
{
END_CRIT_SECTION();
ereport(DEBUG1,
(errmsg_internal("checkpoint skipped because system is idle")));
return;
}
}
但是現(xiàn)有的 num_timed 是無(wú)法區(qū)分的,所以此次提交引入了 num_done 計(jì)數(shù)器,它僅跟蹤已完成的檢查點(diǎn),從而更容易查看實(shí)際執(zhí)行了多少個(gè)檢查點(diǎn)。
Note that checkpoints may be skipped if the server has been idle since the last one, and this value counts both completed and skipped checkpoints
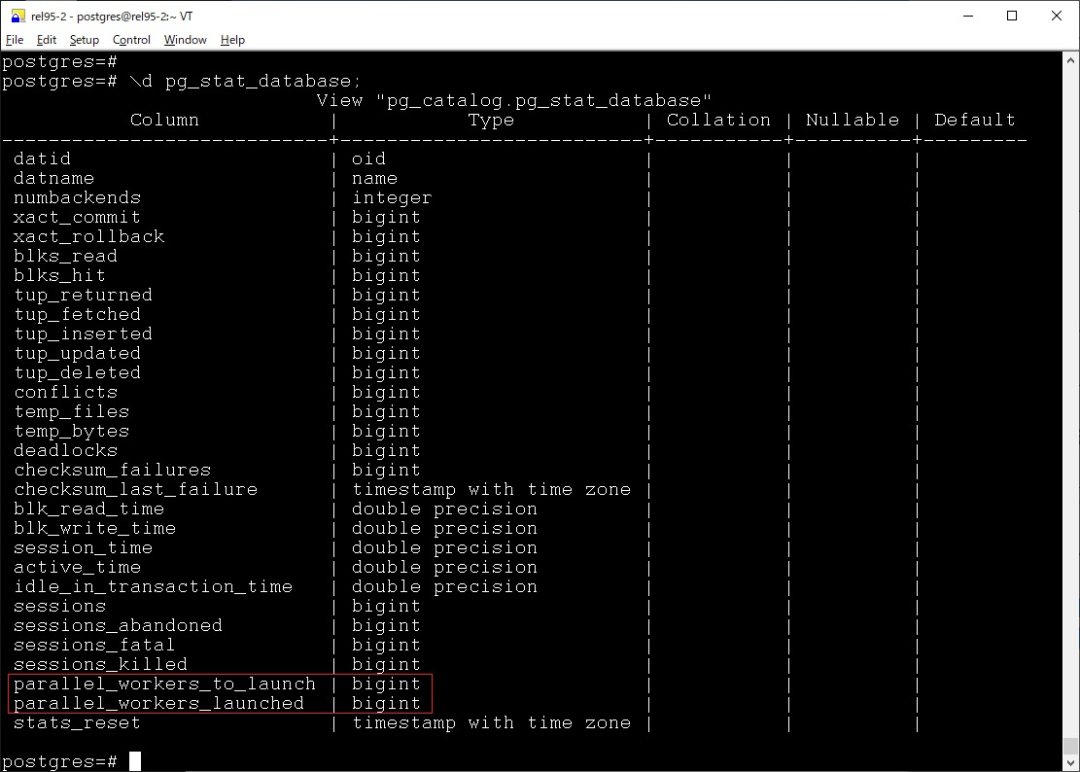
pg_stat_database
pg_stat_database 中新增了如下兩個(gè)字段
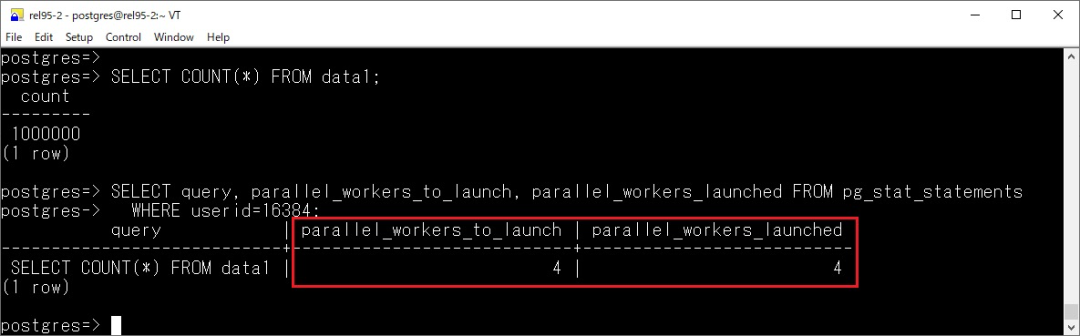
?parallel_workers_to_launch?parallel_workers_launched
顧名思義,看到這個(gè)數(shù)據(jù)庫(kù)中并行的使用情況。
另外,在 pg_stat_statements 中也新增了額外兩個(gè)類似指標(biāo)
pg_stat_subscription_stats
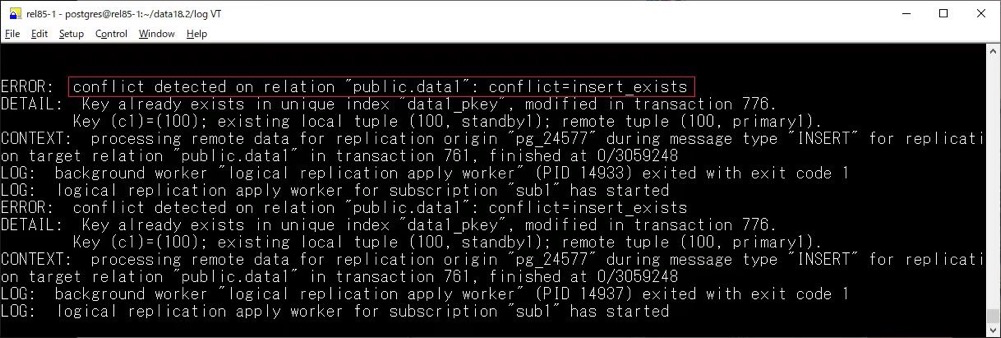
主要新增了一些用于觀察沖突的列:
?confl_insert_exists?confl_update_origin_differs?confl_update_exists?confl_update_missing?confl_delete_origin_differs?confl_delete_missing
在日志中也有所體現(xiàn):
pg_stat_get_backend_io
新增了 pg_stat_get_backend_io 函數(shù),用于返回指定后端進(jìn)程的 I/O 統(tǒng)計(jì)信息
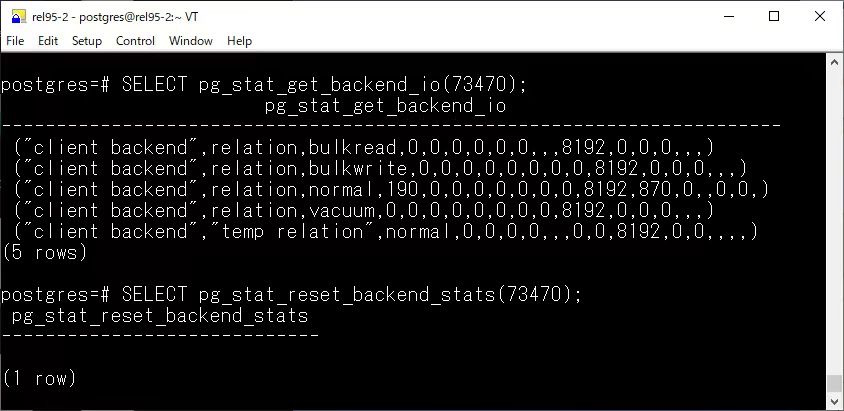
結(jié)合 pg_stat_activity,如虎添翼:
postgres=#SELECT*
FROMpg_stat_get_backend_io( pg_backend_pid() )
WHEREbackend_type='client backend'
ANDobject='relation'
ANDcontext='normal';
-[ RECORD1]--+---------------
backend_type | client backend
object | relation
context | normal
reads | 122
read_time | 0
writes | 0
write_time | 0
writebacks | 0
writeback_time | 0
extends | 49
extend_time | 0
op_bytes | 8192
hits | 11049
evictions | 0
reuses |
fsyncs | 0
fsync_time | 0
stats_reset |
統(tǒng)計(jì)信息
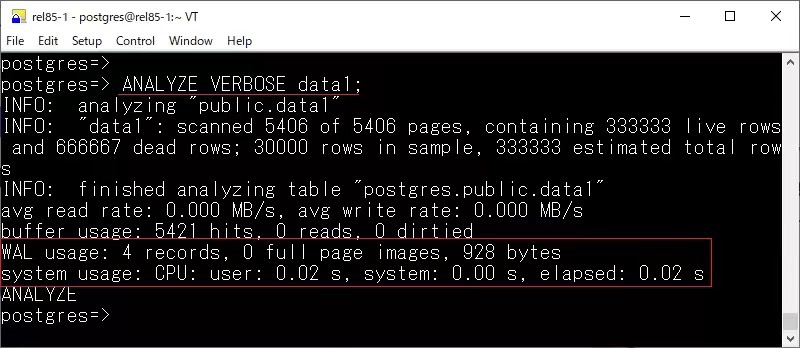
對(duì)于 ANALYZE,在 18 版本中可以看到資源消耗情況以及 WAL 的使用情況
其次還新增了 ONLY 關(guān)鍵字,目的是解決在處理分區(qū)表時(shí),VACUUM 和 ANALYZE 操作的一些不便之處。默認(rèn)情況下,Autovacuum 進(jìn)程不會(huì)自動(dòng)對(duì)分區(qū)表執(zhí)行 ANALYZE,用戶必須手動(dòng)執(zhí)行。然而手動(dòng)執(zhí)行時(shí),又會(huì)遞歸去分析每個(gè)分區(qū),對(duì)于較大的分區(qū)表無(wú)疑會(huì)十分耗時(shí),尤其是當(dāng)表的列數(shù)很多時(shí)。為了解決這個(gè)問(wèn)題,18 中引入了 ONLY 關(guān)鍵字,指定僅對(duì)主表進(jìn)行操作,跳過(guò)對(duì)分區(qū)的處理。這樣,用戶可以避免在分區(qū)表上執(zhí)行遞歸分析,節(jié)省時(shí)間。
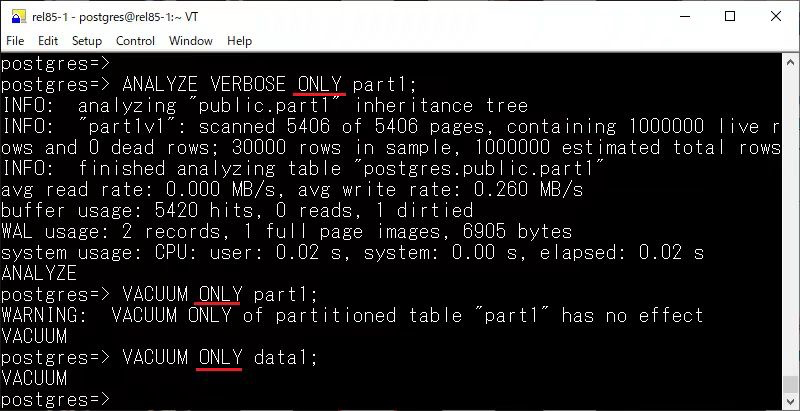
這個(gè)行為讓我想起了在 Greenplum 中,有個(gè)針對(duì)根分區(qū)的 optimizer_analyze_root_partition 參數(shù)。
對(duì)于分區(qū)表,當(dāng)在表上運(yùn)行 ANALYZE 命令時(shí)收集根分區(qū)的統(tǒng)計(jì)信息。GPORCA 使用根分區(qū)統(tǒng)計(jì)信息來(lái)生成一個(gè)查詢計(jì)劃。而遺傳查詢優(yōu)化器并不使用這些數(shù)據(jù)。
性能
Hash Right Semi Join
在 18 中,支持了 Hash Right Semi Join (也支持并行),是的 Richard Guo 大佬。
以下是 17 中的例子,優(yōu)化器選擇了基于大表 ticket_flights 進(jìn)行 HASH,這無(wú)疑會(huì)消耗更多資源
=# EXPLAIN (costs off, analyze) SELECT*FROMflights WHEREflight_idIN(SELECTflight_idFROMticket_flights); QUERY PLAN ------------------------------------------------------------------------------------------------ Hash Join (actual time=2133.122..2195.619 rows=150588 loops=1) Hash Cond: (flights.flight_id = ticket_flights.flight_id) -> Seq Scan on flights (actual time=0.018..10.301 rows=214867 loops=1) -> Hash (actual time=2132.969..2132.970 rows=150588 loops=1) Buckets: 262144 (originally 131072) Batches: 1 (originally 1) Memory Usage: 7343kB -> HashAggregate (actual time=1821.476..2114.218 rows=150588 loops=1) Group Key: ticket_flights.flight_id Batches: 5 Memory Usage: 10289kB Disk Usage: 69384kB -> Seq Scan on ticket_flights (actual time=7.200..655.356 rows=8391852 loops=1) Planning Time: 0.325 ms Execution Time: 2258.237 ms (11 rows)
在 18 中,第四行我們可以看到,優(yōu)化器選擇了 Parallel Hash Right Semi Join,基于 flights 去構(gòu)建了 HASH,執(zhí)行時(shí)間也有倍數(shù)的提升。
QUERY PLAN
---------------------------------------------------------------------------------------------------
Gather (actualtime=56.771..943.233rows=150590loops=1)
Workers Planned:2
Workers Launched:2
-> Parallel Hash Right Semi Join (actualtime=41.754..909.894rows=50197loops=3)
Hash Cond: (ticket_flights.flight_id = flights.flight_id)
-> Parallel Seq Scan on ticket_flights (actualtime=0.047..221.511rows=2797284loops=3)
-> Parallel Hash (actualtime=40.309..40.309rows=71622loops=3)
Buckets:262144 Batches:1 Memory Usage:23808kB
-> Parallel Seq Scan on flights (actualtime=0.008..6.631rows=71622loops=3)
Planning Time:0.555ms
Execution Time:949.831ms
(11rows)
Self-Join Elimination
當(dāng)查詢中的表與自身進(jìn)行內(nèi)連接時(shí),如果可以證明該連接在查詢結(jié)果中沒(méi)有實(shí)際作用,可以用掃描操作代替這個(gè)自連接。這種優(yōu)化有助于減少查詢計(jì)劃的復(fù)雜度,特別是在涉及分區(qū)表時(shí)。該優(yōu)化的主要效果包括:
?減少范圍表的長(zhǎng)度:特別是對(duì)于分區(qū)表,消除不必要的自連接有助于減少表列表中的項(xiàng)數(shù)。?減少限制條件的數(shù)量:從而減少了選擇性估算,并可能提高查詢計(jì)劃的預(yù)測(cè)準(zhǔn)確性。
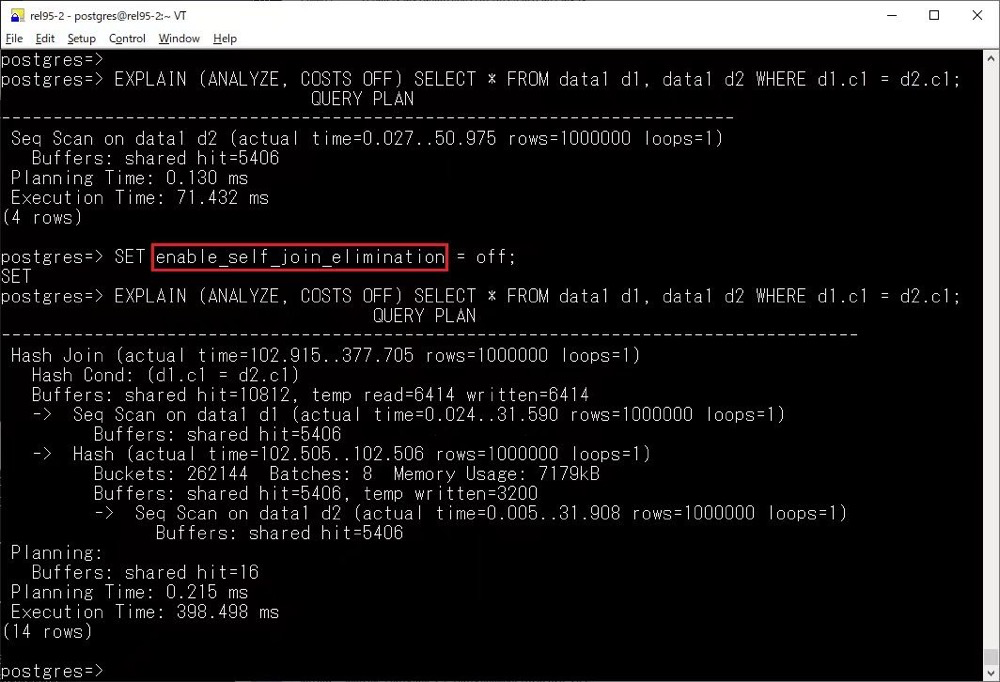
這項(xiàng)優(yōu)化通過(guò)替代自連接為更高效的掃描操作來(lái)減少查詢計(jì)劃的復(fù)雜性,尤其在處理分區(qū)表時(shí)具有顯著的性能優(yōu)勢(shì)。搭配上 Hash Right Semi Join,使得 18 中的優(yōu)化器能力更上一層樓。
UUID v7
在 18 中,另一個(gè)比較令人驚喜的是 v7 UUID 的支持 — 結(jié)合了以毫秒為單位的 Unix 時(shí)間戳和隨機(jī)位,提供唯一性和可排序性,UUID v7 采用時(shí)間戳作為生成 UUID 的核心部分,這意味著它是有序的。與 UUID v4 的隨機(jī)性不同,UUID v7 生成的 UUID 在時(shí)間上具有自然的順序。這樣的有序性在數(shù)據(jù)庫(kù)和分布式系統(tǒng)中具有重要優(yōu)勢(shì),特別是在數(shù)據(jù)插入、索引和查詢時(shí),有序的 UUID 使得數(shù)據(jù)可以更好地分布和排序,避免了 UUID v4 生成的隨機(jī)分布可能導(dǎo)致的性能問(wèn)題。
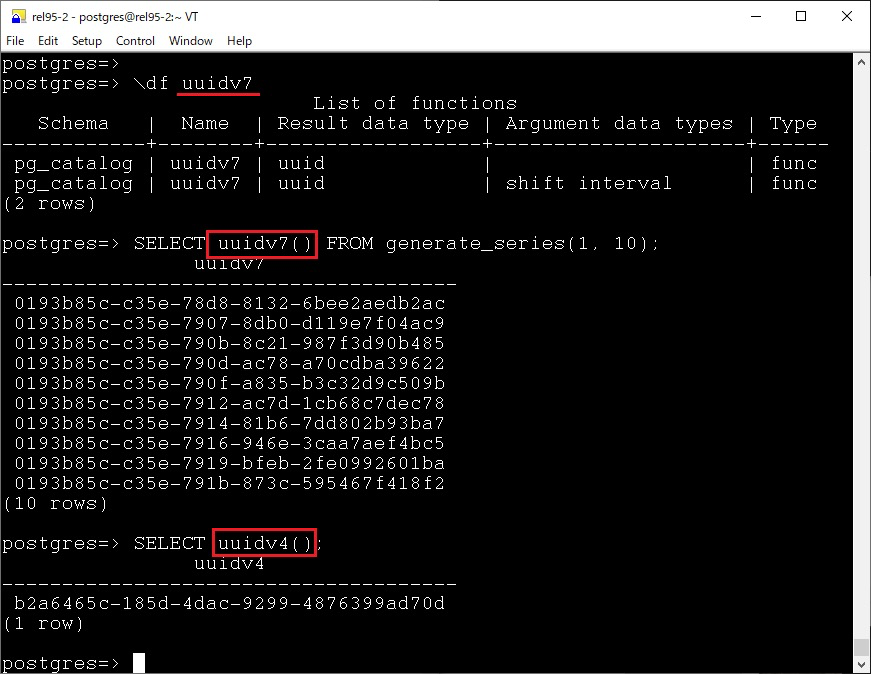
非 V7 的 UUID 其危害我已經(jīng)寫(xiě)過(guò)不少文章進(jìn)行闡述了,那么在 18 以前如何實(shí)現(xiàn) v7 呢?可以參照 Howtos 里面的相關(guān)文章:
?https://postgres-howto.cn/#/./docs/64?id=how-to-use-uuid[2]?https://postgres-howto.cn/#/./docs/65?id=uuid-v7-and-partitioning-timescaledb[3]
使用唯一索引檢測(cè)冗余的 GROUP BY 列
原本在 GROUP BY 包含關(guān)系表的所有主鍵列時(shí),所有其他不屬于主鍵的列可以從 GROUP BY 子句中移除,因?yàn)檫@些列在功能上依賴于主鍵,并且主鍵本身足以確保組的唯一性。這個(gè)優(yōu)化特性被擴(kuò)展到不僅適用于主鍵索引,還支持任何唯一索引。也就是說(shuō),如果表上存在一個(gè)唯一索引,優(yōu)化器可以使用該索引來(lái)移除 GROUP BY 中冗余的列。
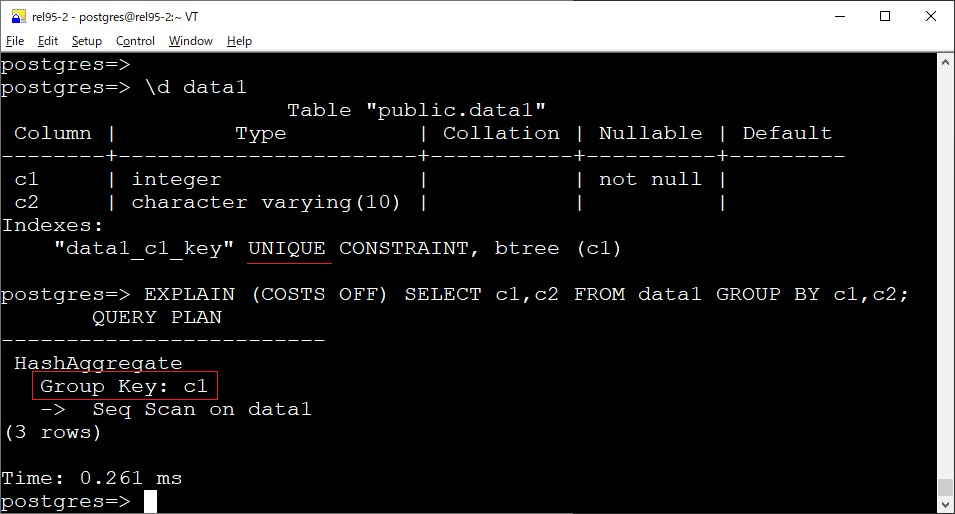
針對(duì)這個(gè),讓我想起了另一個(gè)內(nèi)核知識(shí)點(diǎn),我們知道,對(duì)于 group by,非聚合列必須包含在 group by 子句中,否則會(huì)報(bào)如下錯(cuò)誤 xxx must appear in the GROUP BY clause or be used in an aggregate function
postgres=#createtabletest(idintprimarykey,info text); CREATETABLE postgres=#insertintotestvalues(1,'hello'); INSERT01 postgres=#insertintotestvalues(2,'world'); INSERT01 postgres=#insertintotestvalues(3,'postgres'); INSERT01 postgres=#insertintotestvalues(4,'postgres'); INSERT01 postgres=#select*fromtest; id| info ----+---------- 1 | hello 2 | world 3 | postgres 4 | postgres (4 rows)
當(dāng)非聚合列不包含在 group by 子句中會(huì)報(bào)錯(cuò),但是如果按照主鍵的話,就不會(huì)報(bào)錯(cuò)
postgres=#selectid,count(*)fromtestgroupbyinfo;
ERROR: column"test.id" must appearintheGROUPBYclauseorbe usedinan aggregatefunction
LINE1:selectid,count(*)fromtestgroupbyinfo;
^
postgres=#selectid,info,count(*)fromtestgroupbyid;
id| info |count
----+----------+-------
2 | world | 1
3 | postgres | 1
4 | postgres | 1
1 | hello | 1
(4 rows)
postgres=# select id,info,count(*) from test group by id,info;
id | info | count
----+----------+-------
2 | world | 1
3 | postgres | 1
4 | postgres | 1
1 | hello | 1
(4 rows)
因?yàn)槿绻前凑罩麈I進(jìn)行分組,由于主鍵的原因,那么該行必然是唯一的,即使加上其他的列,也是固定的分組。但是比較可惜的是,截止目前只能是主鍵,唯一約束 + not null 也不行,雖然語(yǔ)義是一樣的,代碼里有說(shuō)明
/*
* remove_useless_groupby_columns
* Remove any columns in the GROUP BY clause that are redundant due to
* being functionally dependent on other GROUP BY columns.
*
* Since some other DBMSes do not allow references to ungrouped columns, it's
* not unusual to find all columns listed in GROUP BY even though listing the
* primary-key columns would be sufficient. Deleting such excess columns
* avoids redundant sorting work, so it's worth doing. When we do this, we
* must mark the plan as dependent on the pkey constraint (compare the
* parser's check_ungrouped_columns() and check_functional_grouping()).
*
* In principle, we could treat any NOT-NULL columns appearing in a UNIQUE
* index as the determining columns. But as with check_functional_grouping(),
* there's currently no way to represent dependency on a NOT NULL constraint,
* so we consider only the pkey for now.
*/
staticvoid
remove_useless_groupby_columns(PlannerInfo *root)
{
Query *parse = root->parse;
Bitmapset **groupbyattnos;
Bitmapset **surplusvars;
ListCell *lc;
int relid;
值得一提的是,在 16 中支持了 any_value,用于解決這種問(wèn)題。
pg_set_relation_stats
截止最新版 17,PostgreSQL 中還沒(méi)有官方方法來(lái)手動(dòng)調(diào)整優(yōu)化器統(tǒng)計(jì)信息,在 18 中已經(jīng)可以初步做到了
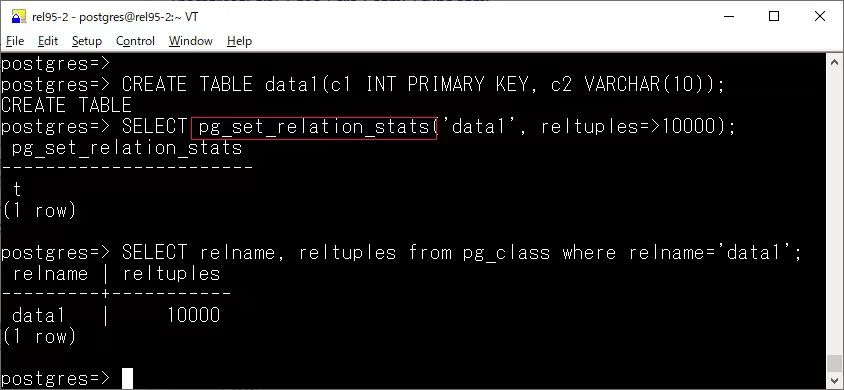
以這篇文章的例子為例https://www.dbi-services.com/blog/postgresql-18-tweaking-relation-statistics/[4]
postgres=#createtablet ( aint, b text );
CREATETABLE
postgres=#insertintotvalues(1,'aa');
INSERT01
postgres=#insertintotselecti,'bb'fromgenerate_series(2,100) i;
INSERT099
postgres=# analyze t;
ANALYZE
postgres=#createindex iont(b);
CREATEINDEX
postgres=# d t
Table"public.t"
Column| Type |Collation|Nullable|Default
--------+---------+-----------+----------+---------
a | integer | | |
b | text | | |
Indexes:
"i" btree (b)
postgres=# select relpages,reltuples from pg_class where relname = 't';
relpages | reltuples
----------+-----------
1 | 100
(1 row)
postgres=# explain select * from t where b = 'aa';
QUERY PLAN
-------------------------------------------------
Seq Scan on t (cost=0.00..2.25 rows=1 width=7)
Filter: (b = 'aa'::text)
(2 rows)
雖然有索引,但是只有一個(gè)數(shù)據(jù)塊并且只有一行滿足條件,優(yōu)化器認(rèn)為走順序掃描更快,現(xiàn)在可以通過(guò) pg_set_relation_stats 調(diào)整統(tǒng)計(jì)信息 (臨時(shí)的,手動(dòng)或自動(dòng)分析都會(huì)覆蓋),讓優(yōu)化器走了索引掃描。
postgres=# select * from pg_set_relation_stats('t'::regclass,1,1000000);
pg_set_relation_stats
-----------------------
t
(1row)
postgres=# x
Expanded displayisoff.
postgres=# select relpages,reltuples from pg_classwhererelname= 't';
relpages|reltuples
----------+-----------
1 | 1e+06
(1row)
postgres=# explain select * from twhereb ='aa';
QUERY PLAN
-----------------------------------------------------------------
Index Scan using i on t (cost=0.17..183.18rows=10000width=7)
Index Cond: (b ='aa'::text)
(2rows)
真不錯(cuò),看似一小步,實(shí)則是一大步!在德哥的吐槽大會(huì)上,有一期[5]也是吐槽優(yōu)化器的,有一段內(nèi)容如下:

VACUUM
autovacuum_vacuum_max_threshold
新增了一個(gè) autovacuum_vacuum_max_threshold 參數(shù),PostgreSQL 默認(rèn)使用 autovacuum_vacuum_threshold 和 autovacuum_vacuum_scale_factor 兩個(gè)參數(shù)來(lái)計(jì)算何時(shí)對(duì)表進(jìn)行自動(dòng)清理。這兩個(gè)參數(shù)通常適用于小型表,使其更頻繁地進(jìn)行 VACUUM 操作,以確保性能。然而,對(duì)于非常大的表,即使更新操作的絕對(duì)數(shù)量較多,按照比例計(jì)算,更新操作所占的比例仍然可能較低,導(dǎo)致這些表不太可能觸發(fā)自動(dòng)清理。
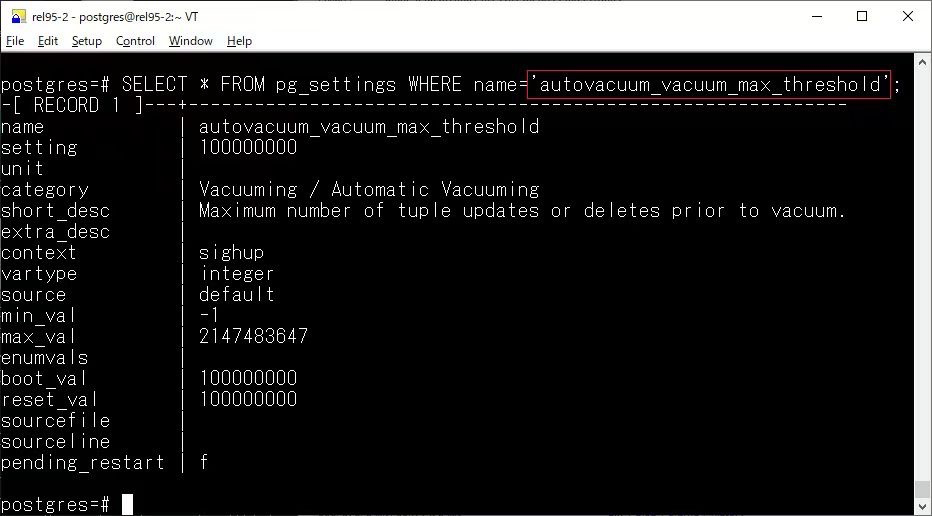
autovacuum_vacuum_max_threshold 解決了這個(gè)問(wèn)題,簡(jiǎn)單粗暴,允許指定一個(gè)絕對(duì)的更新次數(shù)閾值,一旦表中的更新次數(shù)達(dá)到該閾值,就會(huì)觸發(fā)自動(dòng)清理操作。這可以確保對(duì)于那些更新數(shù)量很大的表,VACUUM 操作不會(huì)因?yàn)楸淼南鄬?duì)更新比例較低而被推遲。
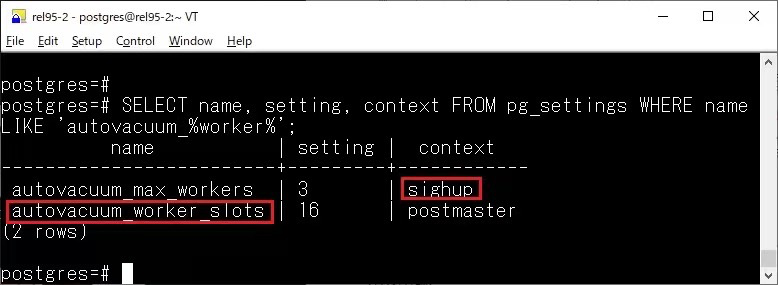
autovacuum_max_workers
現(xiàn)在修改 autovacuum_max_workers 不需要重啟了,直接 reload 即可
其次在日志中可以看到 delay time 了
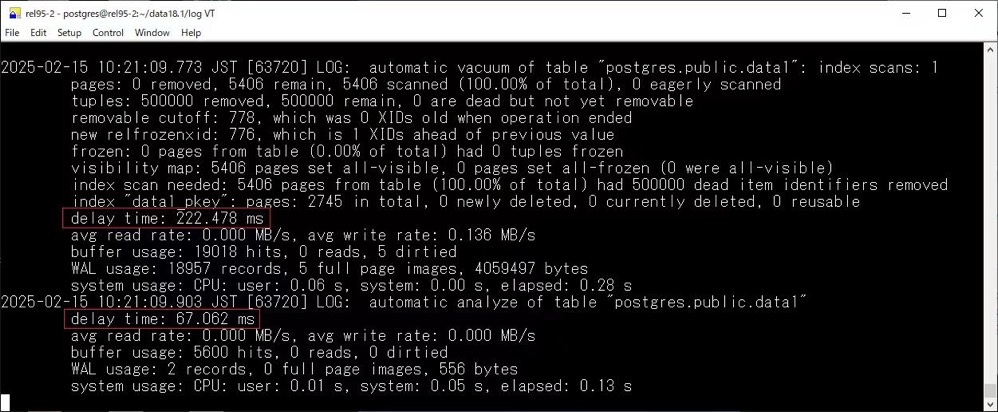
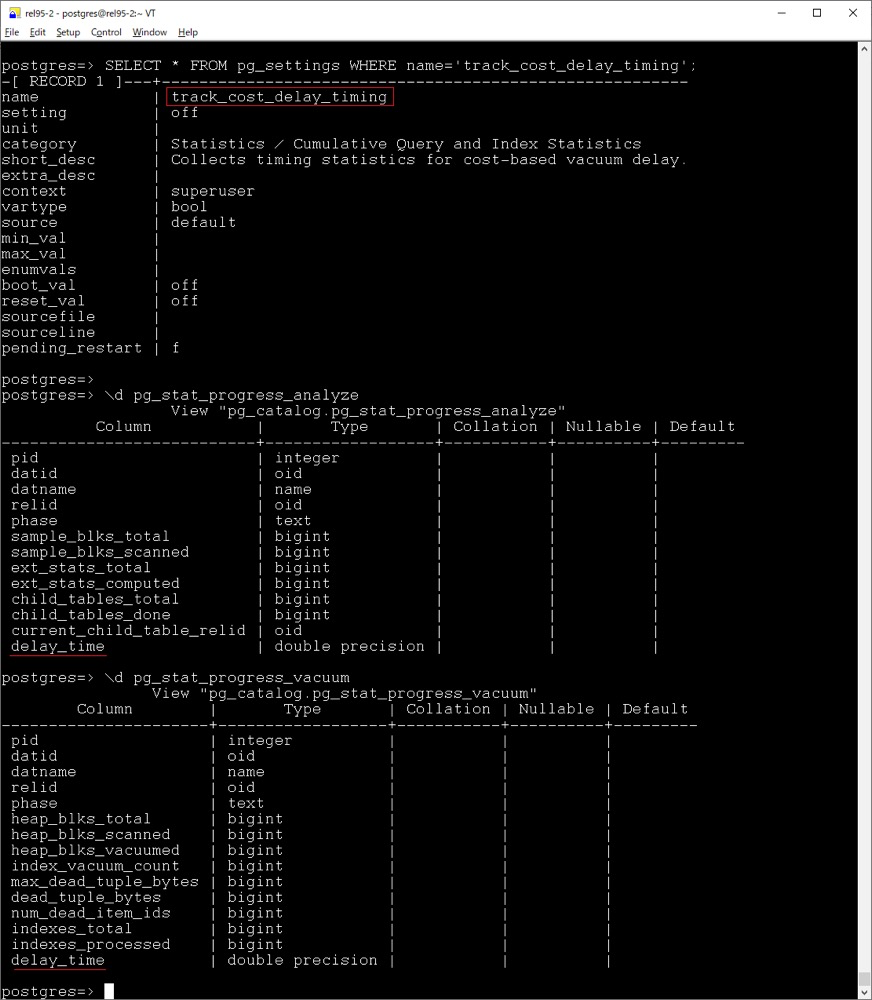
track_cost_delay_timing
另外新增了一個(gè) track_cost_delay_timing 參數(shù),啟用后,將記錄基于成本的清理延遲統(tǒng)計(jì)信息的時(shí)間,用于清理和分析操作,并將在 pg_stat_progress_analyze 和 pg_stat_progress_vacuum 中的 delay_time 列中可見(jiàn),不過(guò)在計(jì)時(shí)較差的平臺(tái)上,也可能會(huì)造成較大的性能影響,因此默認(rèn)是關(guān)閉的。
vacuum_max_eager_freeze_failure_rate
新增 vacuum_max_eager_freeze_failure_rate 參數(shù),參數(shù)設(shè)定了一個(gè)失敗比例閾值,表示在掃描過(guò)程中,如果超過(guò)這個(gè)比例的頁(yè)面無(wú)法成功凍結(jié),VACUUM 將停止使用提前凍結(jié)方式,并回退到正常的凍結(jié)過(guò)程。這有助于避免因?yàn)榇罅績(jī)鼋Y(jié)失敗導(dǎo)致的性能下降。
其他
元命令
現(xiàn)在分區(qū)表不再允許 ALTER TABLE ... SET [UN]LOGGED 的操作:
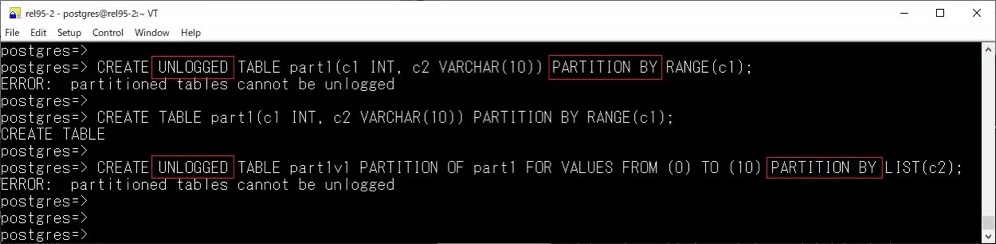
COPY 新增 REJECT_LIMIT 選項(xiàng):
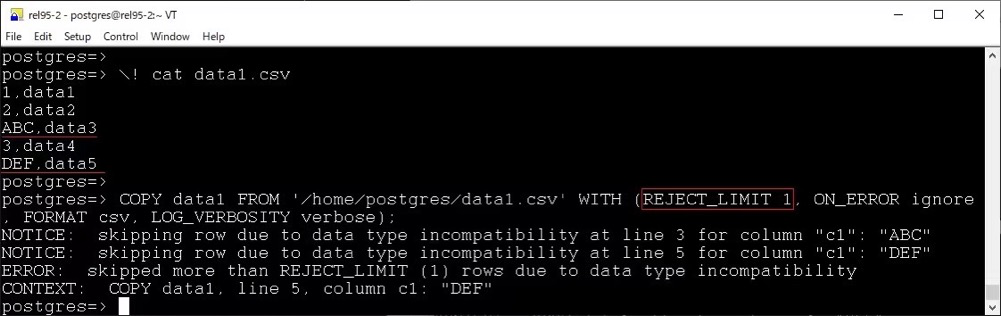
file_fdw 也新增了一個(gè) REJECT_LIMIT 選項(xiàng) (還新增了on_error 和 log_verbosity)。
temporal FOREIGN KEY contraints:https://www.depesz.com/2024/10/03/waiting-for-postgresql-18-add-temporal-foreign-key-contraints/[6]
小結(jié)
簡(jiǎn)而言之,18 也是一個(gè)值得期待的大版本,讓我們拭目以待!
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3124瀏覽量
75263 -
postgresql
+關(guān)注
關(guān)注
0文章
24瀏覽量
382
原文標(biāo)題:PostgreSQL 18新特性前瞻
文章出處:【微信號(hào):OSC開(kāi)源社區(qū),微信公眾號(hào):OSC開(kāi)源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Linux PostgreSQL操作
PostgreSQL的常見(jiàn)問(wèn)題總結(jié)
云棲干貨回顧 | 更強(qiáng)大的實(shí)時(shí)數(shù)倉(cāng)構(gòu)建能力!分析型數(shù)據(jù)庫(kù)PostgreSQL 6.0新特性解讀
RDS for PostgreSQL的插件的創(chuàng)建/刪除和使用方法
PostgreSQL 13正式發(fā)布
PolarDB for PostgreSQL云原生數(shù)據(jù)庫(kù)

多層面分析 etcd 與 PostgreSQL數(shù)據(jù)存儲(chǔ)方案的差異
Devart:PostgreSQL GUI工具2023(下)
PostgreSQL 插件那么多,怎樣管理最高效?
如何快速完成PostgreSQL數(shù)據(jù)遷移?

為什么選擇 PostgreSQL
MySQL還能跟上PostgreSQL的步伐嗎

利用SSIS源、查找及目標(biāo)組件集成PostgreSQL數(shù)據(jù)至ETL流程





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論