 電子發燒友App
電子發燒友App


從歷史背景、數據模型、客戶端接口、存儲、分布式以及維護等多層面分析 etcd 與 PostgreSQL 的差異。
作者羅錦華,API7.ai 技術專家/技術工程師,開源項目 pgcat,lua-resty-ffi,lua-resty-inspect 的作者。
歷史背景
PostgreSQL 的實現始于 1986 年,由伯克利大學的 Michael Stonebraker 教授領導。經過幾十年的發展,PostgreSQL 堪稱目前最先進的開源關系型數據庫。它有自由寬松的許可證,任何人都可以免費使用、修改和分發 PostgreSQL,不管是私用、商用還是學術研究目的。
PostgreSQL 全方位支持 OLTP 和 OLAP,具有強大的 SQL 查詢能力和大量擴展,能滿足幾乎所有商業需求,所以近年來越來越被受到重視。事實上,PostgreSQL 強大的擴展性和高性能使得它能模擬任何其他不同類型數據庫的功能。? ??
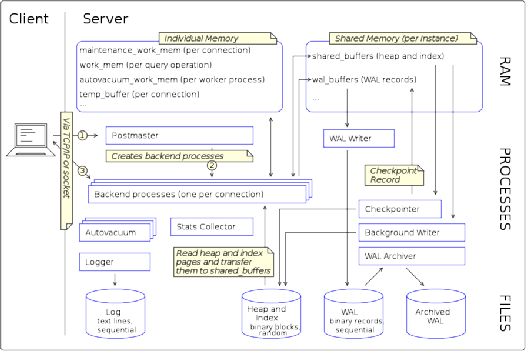
*圖片來源(遵循 CC 3.0 BY-SA 版權協議)
而 etcd 又是如何誕生的呢?它解決了什么問題?
2013 年,有一個叫 CoreOS 的創業團隊,他們構建了一個產品:Container Linux。它是一個開源、輕量級的操作系統,側重自動化、快速部署應用服務,并要求應用程序都在容器中運行,同時提供集群化的管理方案,用戶管理服務就像單機一樣方便。
他們希望在重啟任意一節點的時候,用戶的服務不會因此而宕機,導致無法提供服務,因此需要運行多個副本。但是多個副本之間如何協調,如何避免變更的時候所有副本不可用呢?
為了解決這個問題,CoreOS 團隊需要一個協調服務來存儲服務配置信息、提供分布式鎖等能力。怎么辦呢?當然是分析業務場景、痛點、核心目標,然后是基于目標進行方案選型,評估是選擇社區開源方案還是自己造輪子。這其實就是我們遇到棘手問題時的通用解決思路,CoreOS 團隊同樣如此。
一個協調服務,理想狀態下大概需要滿足以下五個目標:
1.高可用,數據多副本
2?.數據一致性,數據副本之間的版本校對
3.低容量、僅存儲關鍵元數據配置。協調服務保存的僅僅是服務、節點的配置信息(屬于控制面配置),而不是與用戶相關的數據,所以存儲上不需要考慮數據分片,無需過度設計
4.功能:增刪改查,監聽數據變化的機制。協調服務保存了服務的狀態信息,若服務有變更或異常,相比控制端定時去輪詢檢查一個個服務狀態,若能快速推送變更事件給控制端,則可提升服務可用性、以及減少協調服務不必要的性能開銷
5.運維復雜度
從 CAP 理論上來說,etcd 屬于 CP 系統。
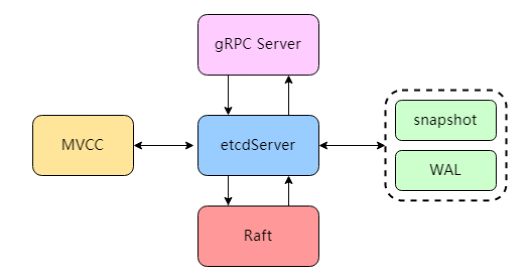
作為 kubernetes 集群的中樞組件 kube-apiserver 正是采用 etcd 作為底層存儲。
一方面,k8s 集群中資源對象的創建都需要借助 etcd 來持久化;另一方面,正是 etcd 的數據 watch 機制,驅動著整個集群的 Informer 工作,從而達到源源不斷的容器編排!因此,從技術角度說,Kubernetes 采用 etcd 的核心理由有:
1.etcd 采用 go 語言編寫,和 k8s 技術棧一致,資源占用率低,部署異常簡單。
2.etcd 的強一致性、watch、lease 等特性是 k8s 的核心依賴。
總而言之,etcd 是針對配置管理和分發這個特定需求而設計出來的分布式 KV 數據庫,它是云原生軟件,
開箱即用和高性能使得它在這個需求上優于傳統數據庫。
要比對 etcd 和 PostgreSQL 這兩個不同類型的數據庫,需要在同一個需求上去看才客觀。
所以本文只針對配置管理這個需求來闡述兩者的差異。
數據模型
不同數據庫對用戶所呈現的數據模型有所不同,它決定了數據庫的適用場景。
key-value vs SQL
key-value 是 nosql 里面很流行的模型,也是 etcd 所采納的設計,相比 SQL,它有什么好處呢?
我們先來看 SQL。
關系數據庫維護表中的數據,提供了一種高效、直觀和靈活的方式來存儲和訪問結構化信息。
表(也稱為關系)由包含一個或多個數據類別的列和包含該類別定義的一組數據的行(也稱為表記錄)組成。應用程序通過指定查詢來訪問數據,這些查詢使用諸如 project 之類的操作來標識屬性、選擇來標識元組以及連接來組合關系。數據庫管理的關系模型是由 IBM 計算機科學家埃德加·科德在1970年開發的。
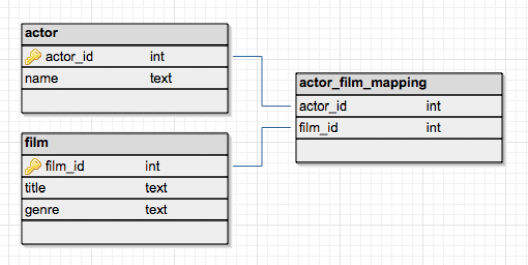
*圖片來源(遵循 CC 3.0 BY-SA 版權協議)
每個表里面的記錄沒有唯一標識符,因為表被設計為可容納多個重復行。如果需要做到 KV 查詢,需要為表里面用作 key 的字段加上唯一索引。PostgreSQL 的索引默認是 btree,跟 etcd 一樣,可以做 key 的范圍查詢。
結構化查詢語言 (SQL) 是一種編程語言,用于在關系數據庫中存儲和處理信息。關系數據庫以表格形式存儲信息,行和列分別表示不同的數據屬性和數據值之間的各種關系。您可以使用 SQL 語句從數據庫中存儲、更新、刪除、搜索和檢索信息。您還可以使用 SQL 來維護和優化數據庫性能。
PostgreSQL 對 SQL 做了很多擴展,使得它是圖靈完備的語言,使用 SQL 可以做任何復雜的操作,使得數據處理邏輯完全在服務端進行。
而 etcd 的定位是配置管理,配置數據一般是哈希表,所以將數據模型定位為 key-value,相當于只有全局一張大表,你可以對這張表進行增刪查改。這張表只有兩個字段,一個 key,一個 value,key 必須是唯一的,而且帶有版本信息,而 value 的類型不做任何假設,所以客戶端需要獲取全量的 value 做進一步處理。
總的來說,etcd 的 kv 是而對 SQL 的簡化,對于配置管理這個特定需求,更加方便和直觀。
MVCC(多版本并發控制)
對于配置管理,數據版本化是其中一個剛需:
1.查詢歷史數據
2.通過比較版本可以知道數據的新舊
3.watch 數據需要以版本為根據,以便實現增量通知
etcd 和 PostgreSQL 都有 MVCC,但是它們的差異在哪里呢?
etcd 維護了一個全局遞增的 64 位版本計數器(無需擔心計數器溢出,因為即便一秒鐘產生百萬次更新,也需要幾十萬年才能用完),每個 key-value 在創建和更新的時候都會賦予版本。刪除 key-value 時會創建一個墓碑,版本重置為0,也就是說,每次變更都產生新的版本,而不是原地更新。同時,etcd 保留了一個 key-value 的所有版本,并且對用戶可見。此外,etcd 實現 MVCC 最大的好處是讀寫分離,讀取數據無需加鎖,滿足了 etcd 以讀為主的定位。
與 etcd 不同,PostgreSQL 的 MVCC 不是為了提供遞增版本號,而是為了實現事務,也就是各類隔離級別,它對用戶是透明的。MVCC 是一種樂觀鎖,它允許并發更新。表的每一行都有事務 ID 的記錄,與 etcd 類似,xmin 對應了創建事務 ID,xmax 對應了更新事務 ID。
1.每個事務只能讀取在它之前已經 commit 的事務
2.更新如果遇到版本沖突,會進行匹配重試,以決定是否更新
但是事務 ID 不能用于配置的版本控制,原因如下:
1.同一個事務內涉及到的所有行都被賦予同一個事務 ID,也就是說,它不是行級別的
2.只能讀取最新版本的行,無法做歷史查詢
3.事務 ID 會變,因為事務 ID 是32位計數器,容易溢出,在 vacuum 的時候會被重置
4.無法根據事務 ID 實現 watch
所以 PostgreSQL 要做配置數據的版本控制,需要用其他形式來替代,沒有開箱即用的支持。
客戶端接口
接口設計決定了客戶端的使用成本和資源消耗,通過分析接口差異,可以幫助我們如何選型。
etcd 提供了 kv/watch/lease API,實踐證明它們特別滿足配置管理的操作需求,那么在 PostgreSQL 上這些接口又如何實現呢?
PostgreSQL 對這些 API 沒有開箱即用的功能,需要通過封裝來實現,這里使用筆者開發的 pg_watch_demo 項目來做分析:
grpc/http vs tcp
PostgreSQL 是多進程架構,每個進程只能處理一個 tcp 連接,使用自定義協議通過 SQL 提供功能,采用一問一答的交互模型
(同一時間只能有一個查詢執行中,類似 http1的同一時間只能處理一個請求,多個請求需要形成 pipeline),資源消耗大且比較低效,對于 QPS 大的場景需要前置連接池代理(例如 pgbouncer)來提高性能。
而 etcd 是 golang 的多協程架構,提供 grpc 和 restful 兩種接口,使用方便,客戶端容易集成;
資源消耗小,每條 grpc 連接可并發多個查詢。
數據定義
etcd
?
?
message KeyValue {
bytes key = 1;
// 創建 key 的 revision
int64 create_revision = 2;
// 更新 key 的 revision
int64 mod_revision = 3;
// 版本遞增計數器,每次更新遞增,但是 delete 時會被清零用作墓碑
int64 version = 4;
bytes value = 5;
// key 使用的 lease 對象,用作 ttl,如果是0則沒有 ttl
int64 lease = 6;
}
?
?
PostgreSQL
PostgreSQL 需要使用一個 table 來模擬 etcd 的全局數據空間:
?
?
CREATE TABLE IF NOT EXISTS config ( key text, value text, -- 等價于 `create_revision` 和 `mod_revision` -- 這里使用大整數的遞增序列類型來模擬 revision revision bigserial, -- 墓碑 tombstone boolean NOT NULL DEFAULT false, -- 組合索引,先搜索 key,然后是 revision primary key(key, revision) );
?
?
get
etcd
etcd 的 get 參數比較豐富:
1.范圍查詢,例如 key 為 /abc,而 range_end 為 /abd,那么就可以獲取以 /abc 為前綴的所有 key-value
2.歷史查詢,指定 revision,或者指定 mod_revision 范圍
3.排序、限定返回數目
?
?
message RangeRequest {
...
bytes key = 1;
// 范圍查詢
bytes range_end = 2;
int64 limit = 3;
// 歷史查詢
int64 revision = 4;
// 排序
SortOrder sort_order = 5;
SortTarget sort_target = 6;
bool serializable = 7;
bool keys_only = 8;
bool count_only = 9;
// 歷史查詢
int64 min_mod_revision = 10;
int64 max_mod_revision = 11;
int64 min_create_revision = 12;
int64 max_create_revision = 13;
}
?
?
PostgreSQL
postgres 可以通過 SQL 完成 etcd 的 get 功能,甚至提供更多復雜的功能,因為 SQL 本身是語言,不是固定參數的接口可比擬的,這里簡單展示只獲取最新 revision 的 key-value。由于主鍵是組合索引,本身可以按范圍搜索,所以速度會很快。
CREATE FUNCTION get1(kk text) RETURNS table(r bigint, k text, v text, c bigint) AS $$ SELECT revision, key, value, create_time FROM config where key = kk and tombstone = false ORDER BY key, revision desc limit 1 $$ LANGUAGE sql;
put
etcd
message PutRequest {
bytes key = 1;
bytes value = 2;
int64 lease = 3;
// 是否返回修改前的 kv
bool prev_kv = 4;
bool ignore_value = 5;
bool ignore_lease = 6;
}
PostgreSQL
類似 etcd,更改不是原地執行,而是插入一個新行,賦予新的 revision。
CREATE FUNCTION set(k text, v text) RETURNS bigint AS $$ insert into config(key, value) values(k, v) returning revision; $$ LANGUAGE SQL;
delete
etcd
message DeleteRangeRequest {
bytes key = 1;
bytes range_end = 2;
bool prev_kv = 3;
}
PostgreSQL
類似 etcd,刪除不是原地修改,而是插入一個新行,將 tombstone 字段設置為 true 以表示是墓碑。
CREATE FUNCTION del(k text) RETURNS bigint AS $$ insert into config(key, tombstone) values(k, true) returning revision; $$ LANGUAGE SQL;
watch
etcd
message WatchCreateRequest {
bytes key = 1;
// 指定 key 的范圍
bytes range_end = 2;
// watch 的起始 revision
int64 start_revision = 3;
...
}
message WatchResponse {
ResponseHeader header = 1;
...
// 為了提高效率,可返回多個事件
repeated mvccpb.Event events = 11;
}
PostgreSQL
PostgreSQL 沒有內置的 watch 功能,需要結合觸發器和 channel 來實現。pg_notify 能將數據發送到偵聽某個 channel 的所有應用程序
-- 觸發器,用于 put/delete 事件的分發
CREATE FUNCTION notify_config_change() RETURNS TRIGGER AS $$
DECLARE
data json;
channel text;
is_channel_exist boolean;
BEGIN
IF (TG_OP = 'INSERT') THEN
-- 將改動用 JSON 編碼
data = row_to_json(NEW);
-- 從 key 提取分發的 channel name
channel = (select SUBSTRING(NEW.key, '/(.*)/'));
-- 如果當前有應用在 watch,則通過 channel 發送事件
is_channel_exist = not pg_try_advisory_lock(9080);
if is_channel_exist then
PERFORM pg_notify(channel, data::text);
else
perform pg_advisory_unlock(9080);
end if;
END IF;
RETURN NULL; -- result is ignored since this is an AFTER trigger
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER notify_config_change
AFTER INSERT ON config
FOR EACH ROW EXECUTE FUNCTION notify_config_change();
由于是封裝出來的 watch,所以需要客戶端應用也要實現配合邏輯,以 golang 為例:
1.發起 listen。一旦 listen,所有 notify 數據會緩存起來(在 PostgreSQL 和 golang 的 channel 層面都可能存在緩存)
2.get_all(key_prefix, revision)。讀取從指定 revision 開始的所有存量數據,每一個 key 只會返回最新 revision 數據,已刪除的數據自動去除。也可以不指定 revision(這是最常見的情形),它會讀取 key_prefix 前綴的所有 key 的最新數據。
3.watch 新數據,包括在第一步和第二步之間可能緩存起來的 notification,使得不錯過這個時間窗口可能產生的新數據。對于已經在第二步讀取過的 revision,在這步忽略掉。
func watch(l *pq.Listener) {
for {
select {
case n := <-l.Notify:
if n == nil {
log.Println("listener reconnected")
log.Printf("get all routes from rev %d including tombstones...
", latestRev)
// 重連的時候根據斷開前的 revision 斷點續傳
str := fmt.Sprintf(`select * from get_all_from_rev_with_stale('/routes/', %d)`, latestRev)
rows, err := db.Query(str)
...
continue
}
...
// 應用要維護一個狀態,里面記錄已經接受到的最新的 revision
updateRoute(cfg)
case <-time.After(15 * time.Second):
log.Println("Received no events for 15 seconds, checking connection")
go func() {
// 長時間沒收到事件,則檢查一下連接是否健康
if err := l.Ping(); err != nil {
log.Println("listener ping error: ", err)
}
}()
}
}
}
log.Println("get all routes...")
// 應用在初始化的時候應該全量獲取當前所有的 key-value,然后通過 watch 來增量監控更新
rows, err := db.Query(`select * from get_all('/routes/')`)
...
go watch(listener)
transaction
etcd
etcd 的事務是帶有判斷條件的多個操作的集合,事務做出的修改是原子提交的。
message TxnRequest {
// 指定事務執行條件
repeated Compare compare = 1;
// 條件滿足要執行的多個操作
repeated RequestOp success = 2;
// 條件不滿足要執行的多個操作
repeated RequestOp failure = 3;
}
PostgreSQL
用 DO 命令可以執行任何命令,包括存儲過程,它支持很多語言,例如自帶的 plpgsql、python 等,用這些語言可以實現任何條件判斷、循環等控制邏輯,比 etcd 更豐富。
DO LANGUAGE plpgsql $$
DECLARE
n_plugins int;
BEGIN
SELECT COUNT(1) INTO n_plugins FROM get_all('/plugins/');
IF n_plugins = 0 THEN
perform set('/routes/1', 'foobar');
perform set('/upstream/1', 'foobar');
...
ELSE
...
END IF;
END;
$$;
lease
etcd
在 etcd 里面,可以創建 lease 對象,應用要定期去續約這個 lease 對象,使得它不過期。
每個 key-value 可以綁定一個 lease 對象,當 lease 對象過期時,所有綁定它的 key-value 都會過期,相當于自動被刪除了。
message LeaseGrantRequest {
// lease 的存活時間
int64 TTL = 1;
int64 ID = 2;
}
// lease 續約
message LeaseKeepAliveRequest {
int64 ID = 1;
}
message PutRequest {
bytes key = 1;
bytes value = 2;
// lease ID,用于實現 ttl
int64 lease = 3;
...
}PostgreSQL
1.在 PostgreSQL 里面可以通過外鍵來維護 lease,查詢的時候,如果有關聯的 lease 對象且過期,則視為墓碑。
2.keepalive 請求更新 lease 表里面的 last_keepalive 時間戳。
CREATE TABLE IF NOT EXISTS config ( key text, value text, ... -- 通過外鍵來指定其綁定的 lease 對象 lease int64 references lease(id), ); CREATE TABLE IF NOT EXISTS lease ( id text, ttl int, last_keepalive timestamp; );
性能對比
PostgreSQL 需要通過封裝來模擬 etcd 的各類 API,那么性能如何呢?
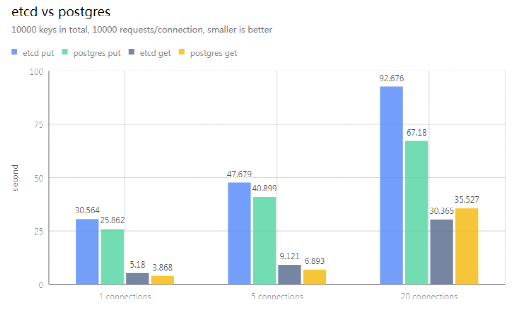
從結果可見,讀寫性能相差無幾,而 PostgreSQL 甚至比 etcd 更快。
另外,一個更新從發生到應用接收到事件的延時決定了更新的分發效率,PostgreSQL 和 etcd 也是相差無幾,客戶端和服務端都在同一個機器測試時,watch 延時小于1毫秒。
但是 PostgreSQL 有如下缺陷值得說明:
1.每個更新對應的 WAL 日志更大,磁盤 IO 比 etcd 多一倍
2.CPU 耗費比 etcd 多
3.基于 channel 的 notify 是事務級別的概念,對同一類資源進行更新,就會將更新發往同一個 channel,更新請求之間會搶奪互斥鎖,導致請求串行化,也就是說,通過 channel 實現 watch,會影響 put 的并行化
從這里也可以看到,為了實現同樣的需求,我們對 PostgreSQL 需要更多的學習成本和優化成本。
存儲
底層存儲決定了性能,數據如何落地決定了數據庫對內存、磁盤等資源的需求。
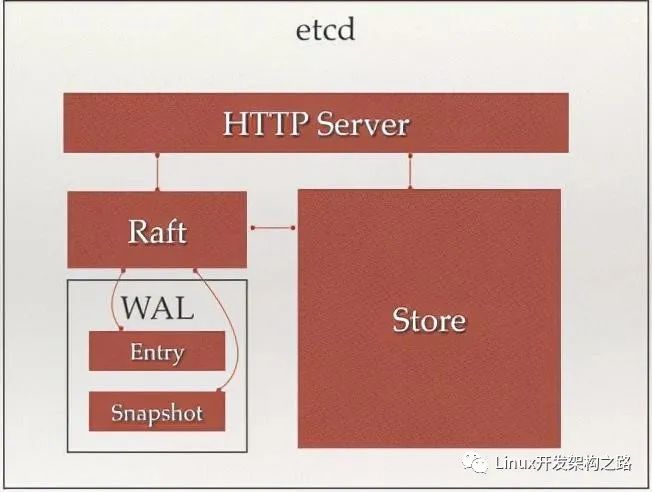
etcd
etcd 存儲架構圖:
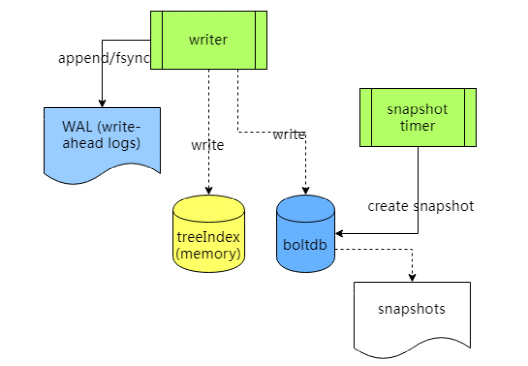
etcd 首先將更新寫入日志(WAL,write-ahead log),并且刷到磁盤,以保證這筆更新不會丟失,一旦日志成功寫入且經過大多數節點確認,就可以返回結果給客戶端了。etcd 還會異步更新 treeIndex 和 boltdb。
為了避免日志的無限增長,etcd 定期對存儲做快照,快照之前的日志可以被刪掉。
etcd 對所有的 key 都在內存里面做索引(treeIndex),在其中記錄每個 key 的版本信息,但是 value 只是保留對 boltdb 的指針(revision)。
而 key 對應的 value 則是保存在磁盤里面,使用 boltdb 來維護。
treeIndex 和 boltdb 都使用 btree 數據結構,眾所周知,btree 對于查找和范圍查找是高效的。
treeIndex 的結構圖:
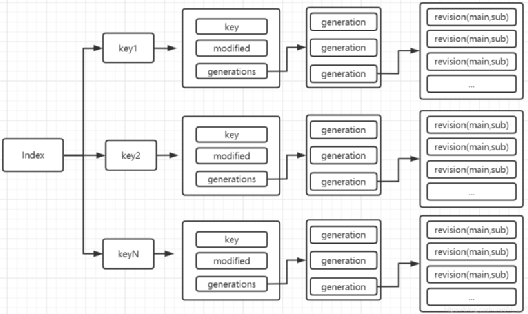
*圖片來源(遵循 CC 4.0 BY-SA 版權協議):https://blog.csdn.net/H_L_S/article/details/112691481*
每個 key 被分為不同的 generation,每次刪除結束一個 generation。
value 的指針由兩個整數構成,第一個整數 main 是 etcd 的事務 ID,而第二個整數 sub 表示在該事務里對這個 key 的更新 ID。
boltdb 支持事務和快照,里面保存的是 revision 對應的值。
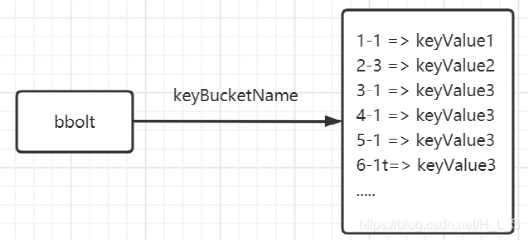
*圖片來源(遵循 CC 4.0 BY-SA 版權協議)
寫入數據示例:
寫入 key="key1", revision=(12,1),value="keyvalue5",注意 treeIndex 和 boltdb 的紅色部分變化:

*圖片來源(遵循 CC 4.0 BY-SA 版權協議):https://blog.csdn.net/H_L_S/article/details/112691481*
刪除 key="key",revision=(13,1),treeIndex 產生新的空的 generation,在 boltdb 生成一個空值,key="13_1t",
這里的 t 表示 tombstone(墓碑)。
這也暗含了你無法讀取墓碑,因為 treeIndex 里面的指針是 (13,1),但 boltdb 里是 13_1t,無法匹配。

*圖片來源(遵循 CC 4.0 BY-SA 版權協議)
值得注意的是,etcd 對 boltdb 的讀寫都由一個單獨的 goroutine 來調度,以減少對磁盤的隨機讀寫,提高 IO 性能。
PostgreSQL
PostgreSQL 的存儲架構圖:
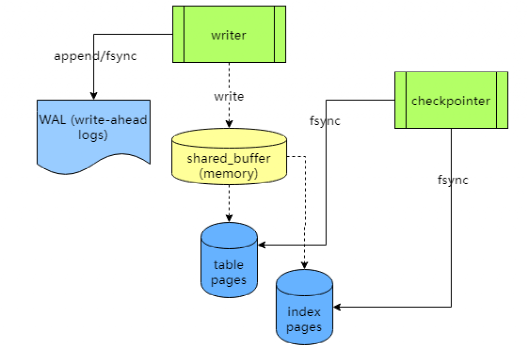
與 etcd 類似,PostgreSQL 首先將更新追加到日志文件,日志刷盤成功才表示事務完成,同時將更新寫入 shared_buffer 內存。
shared_buffer 由所有表共享,它映射了表和索引。
PostgreSQL 里面每張表都由多個表頁(page)文件組成,每個表頁 8 KB,一個表頁包含多個行。
除了表,索引(例如 btree 索引)也是由同樣格式的表頁文件組成,只不過這些表頁文件比較特殊,互相關聯形成樹結構。
PostgreSQL 有一個 checkpointer 進程,會定時將所有表和索引的被更改的表頁文件刷進磁盤,每個 checkpoint 之前的日志文件可以被刪掉回收,避免日志無限增長。
表頁結構:
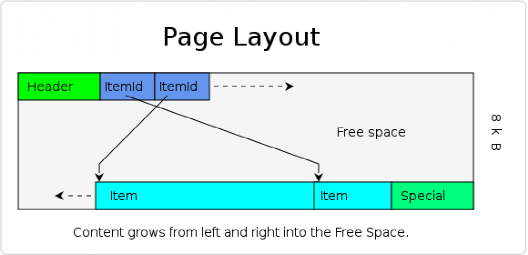
*圖片來源(遵循 CC 3.0 BY-SA 版權協議)
索引的表頁結構:
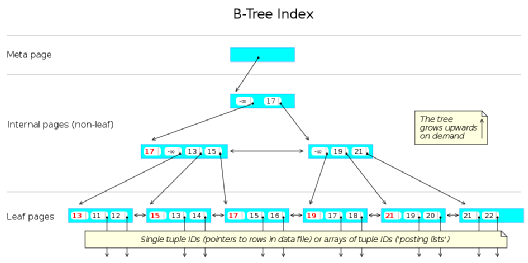
*圖片來源(遵循 CC 3.0 BY-SA 版權協議)
由于表頁文件的分散,為了提高讀性能,某些 SQL 語句的查詢計劃會考慮通過位圖使得表頁讀取被順序化,提高 IO 性能:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100;
QUERY PLAN
------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=5.07..229.20 rows=101 width=244)
Recheck Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0)
Index Cond: (unique1 < 100)
結論
PostgreSQL 和 etcd 的存儲充分考慮了 IO 性能,而 etcd 更是將所有 key 的索引置于內存,它們也都考慮了磁盤順序讀寫的批量操作優化。
所以你可以看到在上面的性能對比里面,PostgreSQL 和 etcd 的讀寫性能相差無幾。
但是相比 PostgreSQL,etcd 要求更大的內存容量和更快的磁盤。
分布式
去中心化和數據一致性是 etcd 的特色,也是云原生的需求,而傳統數據庫如何滿足這點?
etcd
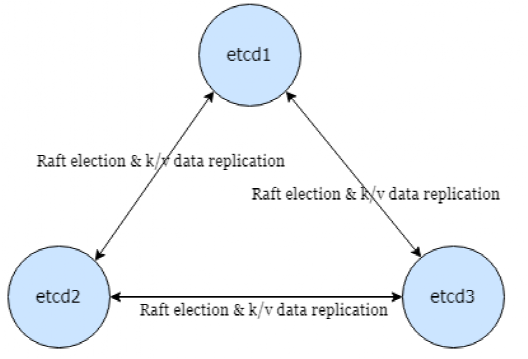
Raft是很流行的分布式協議,etcd 通過 raft 分發更新到多個節點,保證已提交數據被大多數節點確認過。
raft 有嚴謹正確的角色定義,角色切換圖如下:
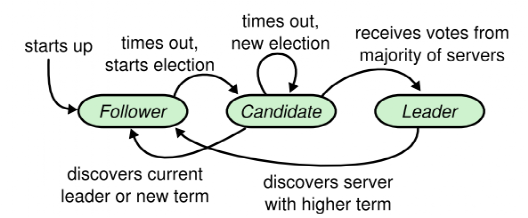
*圖片來源(遵循 CC 3.0 BY-SA 版權協議)
默認情況下,所有讀寫都在 master 節點執行。
寫要一致性這個好理解,但這里值得說明的是一致性讀,它確保了讀來自已提交數據,并且是數據的最新版本,每次讀到的版本都等于或大于上一次讀的版本。
一致性讀的實現簡單來說,就是 slave 節點從 master 節點獲取最新版本,如果 slave 節點版本比 master 節點舊,則等待同步。
可見,etcd 的讀寫負擔都落在 master 節點上,分布式只是保證可用副本和數據一致性,但是沒有負載均衡。
PostgreSQL
PostgreSQL 是傳統數據庫出身,沒有自帶 raft 等分布式協議的實現,
但是它具備了集群化所需的數據復制特性,并且結合第三方的 raft 組件,
可以實現和 etcd 一模一樣的分布式系統。
原生的 PostgreSQL 已經包含了以下基礎特性:
1.synchronous commit
2.quorum replication
3.failover trigger
4.hot-standby
在主節點上的事務提交可配置為需要多個節點都確認才算提交成功,并且確認節點數可配置為大多數節點(quorum)。
數據復制的角色可以被切換(failover trigger),也有 pg_rewind 等工具可截除未被大多數節點確認的數據,以便重新加入集群。
hot-standby 則提供類似 etcd 那樣的 serializable read,也就是能在從節點上讀取已提交數據,但不保證是最新版本。
相關配置示例:
-- set quorum sync replication in postgresql.conf -- assume you have 5 nodes, then at least 2 standbys must be committed -- then you could tolerate 2 nodes failures synchronous_commit on synchronous_standby_names ="ANY 2 (*)" -- if master fails, check flushed lsn of each standby -- promote a standby with max lsn to master select flushed_lsn from pg_stat_wal_receiver;
PostgreSQL 在數據面上已經全面支持集群化,只需要在控制面提供 raft 組件即可實現去中心化的集群。筆者曾為多個商業客戶提供 pg_raft 組件,該組件作為 PostgreSQL 的 worker process 運行,基于 raft 協議為 PostgreSQL 提供選主等集群管理功能。
維護
etcd 是為特定需求而設計的數據庫,所以本身不需要怎么維護,這也是它的賣點之一。
另一方面,由于優秀的設計,PostgreSQL 相比其他關系數據庫,
需要 DBA 維護的點比較少,而且類似 etcd,很多維護工作都是 PostgreSQL 內置和自動進行的。
數據庫有很多維護的例行任務,這里只關注兩點,compaction 和快照備份。
compaction
數據多版本化會使得數據庫變得臃腫,讀寫效率變低,很多舊版本的數據當沒有讀取需要的時候應該要刪除,并且要將刪除后的空洞部分合并,這就是 compaction。
etcd 在 API 上提供了 compact 和 defrag 兩個操作。
compact 用于刪除某個 revision 之前的所有舊版本數據,注意如果覆蓋了某些 key 的最新版本,則會保留最新版本,例如 compact 100,但是前面有一個 key=foo, revision=87 的 key-value,那么會保留它,但是會刪除 key=foo, revision=65 的 key-value,說白了,compact 不會丟每個 key 的當前數據版本。
etcd 提供了 Auto Compaction 功能,例如可以指定每隔多少小時 compact 一次。
compact 會在 boltdb 留下空洞,所以需要 defrag 來整合它們,但是 defrag 會涉及大量 IO 和阻塞讀寫,需要謹慎進行。
另一方面,PostgreSQL 的 compact 也很簡單,例如使用以下 SQL 刪除 revision 為100之前的舊數據:
with alive as (
select r as revision from get_all('/routes/')
)
delete from config
where revision < 100 and not exists (
select 1 from alive where alive.revision = config.revision limit 1
);
如果需要定時執行,可使用 crontab 或者 pg_cron 來實現。
而數據庫自身的 MVCC 清理,PostgreSQL 有自帶的 vacuum 命令(vacuum full 對應 etcd 的 defrag),也有自動化的 autovacuum。
快照備份
快照備份可用于應急恢復,是數據庫維護的剛需任務。
etcd 提供了 API 創建和恢復快照,例如:
$ etcdctl snapshot save backup.db $ etcdctl --write-out=table snapshot status backup.db +----------+----------+------------+------------+ | HASH | REVISION | TOTAL KEYS | TOTAL SIZE | +----------+----------+------------+------------+ | fe01cf57 | 10 | 7 | 2.1 MB | +----------+----------+------------+------------+ $ etcdctl snapshot restore backup.db
PostgreSQL 也有很完善的備份工具:
1.pg_basebackup 為新建 pg 從節點做數據準備
2.pgdump 在線克隆數據庫實例,可選擇備份哪些表
事實上,基于 WAL 和邏輯復制,PostgreSQL 還支持更高級的備份機制,
結論
PostgreSQL 是通用型的傳統 SQL 數據庫,etcd 是專用的分布式 KV 數據庫。
相比 etcd 這類純粹的數據存取系統,PostgreSQL 起碼有如下額外好處:
1.豐富的鑒權機制,能實現完整的 RBAC 和細粒度的權限控制,支持多租戶(多數據庫實例),能過濾 IP,無需額外代理
2.SQL 自帶 schema,支持外鍵,無需提供額外的控制面邏輯去保證數據的完備性
3.支持 JSON 類型的字段,支持基于 JSON 的索引和各類 JSON 操作,例如對路由配置進行索引以便做路由匹配
4.支持數據加密,也支持通過 fdw 訪問 hashicorp vault 獲取 secret
5.邏輯復制可實現多套獨立集群之間的數據同步
6.有存儲過程加持,可實現額外的功能,例如實現上游的慢啟動
從功能上看,PostgreSQL 是 etcd 的超集,所以 PostgreSQL 可以通過其自帶的豐富的基礎功能和第三方組件來重現 etcd 的功能,也可以云化。
用 PostgreSQL 來實現 etcd 的功能,相當于將航母改造為巡航艦,技術上完全沒問題,但如果沒有超出 etcd 能力范圍的需求,那么這種做法的性價比很低,因為開發成本和維護成本是不可忽視的事實。
etcd 最大的好處是開箱即用,滿足了云原生時代對配置分發的需求,etcd 還可以用作應用選主、分布式鎖、任務調度等功能的核心組件。
編輯:黃飛
?















 工商網監
工商網監
評論