") 中科馭數(shù)DPU助力大模型訓(xùn)練和推理
中科馭數(shù)DPU助力大模型訓(xùn)練和推理

隨著深度學(xué)習(xí)技術(shù)的快速發(fā)展,大模型(如GPT、BERT等)在自然語言處理、計算機視覺等領(lǐng)域取得了顯著成果。然而,大模型的參數(shù)量和計算量極其龐大,傳統(tǒng)的硬件架構(gòu)或者單臺設(shè)備(如單個GPU)難以滿足其計算需求。大模型的特點如下:
1. DeepSeek-R1模型的參數(shù)量高達(dá)6710億,訓(xùn)練過程需要數(shù)萬臺GPU協(xié)同工作。
2. 計算需求:大模型的前向傳播、反向傳播和梯度更新涉及大規(guī)模的矩陣運算,單設(shè)備無法在合理時間內(nèi)完成。
3. 內(nèi)存需求:大模型的參數(shù)和中間結(jié)果需要大量內(nèi)存存儲,單設(shè)備的內(nèi)存容量有限。
4. 數(shù)據(jù)需求:大模型的訓(xùn)練需要海量數(shù)據(jù),單設(shè)備難以高效處理。
為提高大模型的計算效率,必須充分利用矩陣和向量運算的內(nèi)在并行性。大模型訓(xùn)練的核心流程:前向傳播、反向傳播和梯度更新,均依賴大規(guī)模矩陣計算,這為分布式并行提供了天然優(yōu)勢。目前,主要的并行計算策略包括:
a)數(shù)據(jù)并行(Data Parallelism):將訓(xùn)練數(shù)據(jù)拆分成多個批次或子集,分配到多個設(shè)備上執(zhí)行局部計算。各設(shè)備獨立計算梯度后,通過梯度同步或聚合機制實現(xiàn)全局參數(shù)更新。
b)模型并行(Model Parallelism):將模型按照參數(shù)或模塊劃分,分布到多臺設(shè)備上進(jìn)行計算。當(dāng)模型單個設(shè)備內(nèi)存難以容納時,模型并行可以有效擴(kuò)展計算規(guī)模。
c)流水線并行(Pipeline Parallelism):將模型按照層級或階段劃分成多個片段,各設(shè)備依次負(fù)責(zé)不同層的計算。數(shù)據(jù)在設(shè)備間依次傳遞,形成一條類似流水線的處理路徑,從而在不同處理階段實現(xiàn)并行性。
分布式計算通過多種并行策略的協(xié)同應(yīng)用,不僅可以突破單設(shè)備算力和內(nèi)存的限制,還能顯著加速大規(guī)模深度學(xué)習(xí)模型的訓(xùn)練。
在大模型訓(xùn)練和推理中,GPU雖然是核心計算單元,但其計算能力往往受到數(shù)據(jù)管理、通信和存儲等任務(wù)的限制。DPU(Data Processing Unit,數(shù)據(jù)處理單元)作為一種新型硬件加速器,正在成為大模型訓(xùn)練和推理的重要助力。DPU的出現(xiàn)正是為了解決這些問題:
a)卸載GPU的計算負(fù)擔(dān):GPU主要負(fù)責(zé)矩陣運算等核心計算任務(wù),但數(shù)據(jù)加載、預(yù)處理、通信等任務(wù)會占用其資源。DPU可以接管這些任務(wù),通過高速I/O接口直接從存儲設(shè)備讀取數(shù)據(jù),減少CPU的介入。大模型訓(xùn)練需要頻繁讀取和寫入大量數(shù)據(jù)(如模型參數(shù)、中間結(jié)果、數(shù)據(jù)集等),傳統(tǒng)的存儲系統(tǒng)可能成為瓶頸。DPU支持NVMe over Fabric/RDMA等高速存儲協(xié)議,能夠直接從遠(yuǎn)程存儲設(shè)備讀取數(shù)據(jù)。讓GPU專注于計算,從而提高整體效率。
b)優(yōu)化數(shù)據(jù)預(yù)處理與檢索:大模型在訓(xùn)練階段需要大量的預(yù)處理(如圖像增強、文本分詞等),在推理階段也需要通過知識庫進(jìn)行檢索增強,這些操作通過遠(yuǎn)程訪問分布式文件系統(tǒng)來完成。在CPU處理模式下,遠(yuǎn)端存儲訪問協(xié)議的處理成為瓶頸。我們通過DPU進(jìn)行遠(yuǎn)端存儲訪問協(xié)議的卸載,提高數(shù)據(jù)讀寫的效率,提供比CPU更高的吞吐量和更低的延遲。
c)加速分布式訓(xùn)練中的通信:分布式訓(xùn)練中,GPU之間的通信(如梯度同步)會消耗大量時間。DPU可以優(yōu)化通信任務(wù),支持高效的All-Reduce操作,減少通信延遲。DPU內(nèi)置專用的通信引擎,使能GPU Direct RDMA,減少CPU的干預(yù),實現(xiàn)超高帶寬、低延遲的GPU間通信。
d)提高能效比:DPU專門針對數(shù)據(jù)管理和通信任務(wù)進(jìn)行了優(yōu)化,能夠以更低的功耗完成這些任務(wù),從而降低整體能耗
中科馭數(shù)作為國內(nèi)領(lǐng)軍的DPU芯片和產(chǎn)品供應(yīng)商,憑借多年在DPU領(lǐng)域的積累,不斷推陳出新,基于公司全自研的國產(chǎn)芯片K2-Pro,推出應(yīng)用于智算中心的系列產(chǎn)品和方案。

圖1 : 中科馭數(shù)K2-Pro
K2-Pro芯片的網(wǎng)絡(luò)處理能力,可以很好的支撐國產(chǎn)化推理集群的各種應(yīng)用需求,在中科馭數(shù)自建的全國產(chǎn)化推理集群中,很好的承擔(dān)了高通量網(wǎng)絡(luò)傳輸,云化流表卸載與分布式資源快速加載的任務(wù)。
同時,在AI模型訓(xùn)練方向,中科馭數(shù)完全自主研發(fā)的RDMA網(wǎng)卡助力數(shù)據(jù)中心高速網(wǎng)絡(luò)連接,確保大規(guī)模模型的數(shù)據(jù)傳輸效率,減少通信延遲,提升整體計算性能。RDMA性能達(dá)到200Gbps。釋放CPU算力,彌補國產(chǎn)CPU性能不足問題。提供微秒級時延和百G級帶寬以及千萬級別的IOPS存儲訪問能力,滿足模型計算對數(shù)據(jù)快速加載的性能要求。
近日,中科馭數(shù)基于全國產(chǎn)化CPU、GPU、DPU 三U一體設(shè)備本地化部署了DeepSeek模型,系統(tǒng)中通過國產(chǎn)CPU實現(xiàn)整體業(yè)務(wù)調(diào)度與主要服務(wù)進(jìn)程運行,采用國產(chǎn)GPU完成模型推理運算,由中科馭數(shù)DPU進(jìn)行設(shè)備裸金屬業(yè)務(wù)管理以及云化網(wǎng)絡(luò)/存儲能力卸載提速。該系統(tǒng)底層采用全國產(chǎn)化的3U一體服務(wù)器搭建,在兼顧安全性與低成本的同時,可以高效運行DeepSeek-V3與DeepSeek-R1等多個AI推理模型系統(tǒng)。中科馭數(shù)通過這種方式完成多個AI模型適配,打通全國產(chǎn)化三U一體算力底層支撐,能夠幫助AI應(yīng)用在落地過程中實現(xiàn)更好的數(shù)據(jù)隱私性保護(hù)與抵御外部風(fēng)險的能力,同時也積極推動產(chǎn)業(yè)鏈協(xié)同與資源優(yōu)化整合。
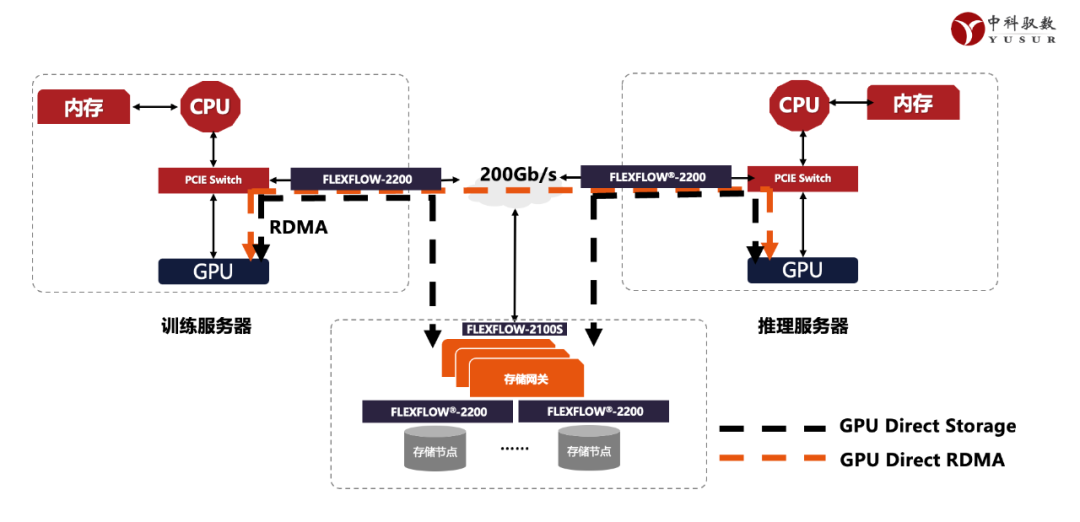
圖2 :中科馭數(shù)智算中心解決方案
DPU通過卸載GPU的計算負(fù)擔(dān)、優(yōu)化數(shù)據(jù)預(yù)處理、加速通信和存儲任務(wù),正在成為大模型訓(xùn)練和推理的重要助力。馭數(shù)的DPU產(chǎn)品憑借其高性能、低功耗和可擴(kuò)展性,為大模型訓(xùn)練和推理提供了強有力的支持。隨著深度學(xué)習(xí)技術(shù)的進(jìn)一步發(fā)展,類似DeepSeek大模型的興起,以及由此帶來對智算資源的大幅優(yōu)化,給國產(chǎn)GPU和CPU實現(xiàn)高效大模型訓(xùn)練和推理的大規(guī)模部署帶來巨大可能和期盼。
同時,智算租賃因為DeepSeek模型對于部署資源的優(yōu)化,讓最終從“看著挺美”變成“用著挺美”。很多用戶開始嘗試租賃智能算資源,這要求智算資源可以按需快速部署。中科馭數(shù)的DPU產(chǎn)品,通過流程簡化和存儲卸載,實現(xiàn)了裸金屬部署時間從傳統(tǒng)的30分鐘優(yōu)化到3分鐘,大大便利了資源的反復(fù)利用,也極大地提升了客戶訂閱的體驗。
-
DPU
+關(guān)注
關(guān)注
0文章
393瀏覽量
24928 -
中科馭數(shù)
+關(guān)注
關(guān)注
0文章
134瀏覽量
4346 -
大模型
+關(guān)注
關(guān)注
2文章
3139瀏覽量
4064
原文標(biāo)題:中科馭數(shù)DPU助力大模型訓(xùn)練和推理
文章出處:【微信號:yusurtech,微信公眾號:馭數(shù)科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
中科馭數(shù)攜DPU全棧產(chǎn)品亮相福州數(shù)博會,賦能智算時代算力基建

中關(guān)村泛聯(lián)院一行來訪中科馭數(shù)
中科馭數(shù)受邀出席2025中關(guān)村論壇
中科馭數(shù)受邀參與華泰證券春季投資峰會 分享DPU在AI領(lǐng)域的應(yīng)用
鄭州市領(lǐng)導(dǎo)蒞臨中科馭數(shù)調(diào)研
中科馭數(shù)K2-Pro芯片助力智算中心創(chuàng)新
中科馭數(shù)獲批設(shè)立博士后科研工作站 加強DPU產(chǎn)學(xué)研合作

中科馭數(shù)憑借在DPU芯片領(lǐng)域的積累被認(rèn)定為北京市知識產(chǎn)權(quán)優(yōu)勢單位






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論