 DeepSeek V3/R1架構解讀:探討其是否具有國運級創新
DeepSeek V3/R1架構解讀:探討其是否具有國運級創新
DeepSeek的最新模型DeepSeek-V3和DeepSeek-R1都屬于MoE(混合專家)架構,并在開源世界產生了較大的影響力。特別是2025 年 1 月開源的DeepSeek-R1,模型性能可挑戰OpenAI閉源的 o1 模型。
隨著熱度的提升,DeepSeek也被大模型行業之外的各路媒體不斷提起,“打破CUDA壟斷”,“挖了NVLink的墻角”,“引發英偉達市值大跌”,“證明大模型算力建設浪費”,“算力霸權轉移”,“國運級的創新”,似乎有用皮衣卡住老黃脖子的架勢。
那么,從技術和架構的角度深入最新的V3和R1模型,是否真的有“國運級的創新”,又有哪些誤傳?
下面我們從V3與R1的架構分析開始,分層解讀DeepSeek的創新。


1 V3與R1的主要特征
DeepSeek-R1的模型架構來自于V3,甚至可以說R1是具有推理(Reasoning)能力的V3。下面先分別分析V3和R1的架構特征。
1.1 V3/R1架構特征
DeepSeek-V3是一個混合專家 (MoE)語言模型,具有 6710 億(671B)參數,其中每個Token(詞元)的計算約激活 370 億(37B)參數。這個模型參數量與GPT-4大致在同一數量級。
| ?MoE(Mixture of Experts)是組合多個專家模型提升深度學習模型性能和效率的架構。?其核心思想是通過引入多個專家模型(Experts),每個輸入數據只選擇和激活其中的一部分專家模型進行處理,從而減少計算量,提高訓練和推理速度。?MoE的概念在1991年就已提出,訓練不容易收斂是其在大模型領域應用的主要障礙。 |
|---|
MoE模型基本結構示意(來源:網絡)
DeepSeek-V3 采用了多頭潛注意力 (MLA,對傳統多頭注意力機制的改進) 和DeepSeekMoE架構(對傳統MoE架構的改進),無輔助損失的負載平衡策略等創新技術,基于 14.8 萬億Token的數據進行訓練,在代碼生成、分析等任務中表現出色。
其中多頭潛注意力 (MLA) 機制和DeepSeekMoE是V3和R1模型提高計算效率,減少算力浪費的關鍵。其中MLA大概貢獻了2-4倍的計算效率提升,MoE大概貢獻了4倍以上的計算效率提升。
1)MLA(Multi-Head Latent Attention)
在“All you need is attention”的背景下,傳統的多頭注意力(MHA,Multi-Head Attention)的鍵值(KV)緩存機制事實上對計算效率形成了較大阻礙。縮小KV緩存(KV Cache)大小,并提高性能,在之前的模型架構中并未很好的解決。DeepSeek引入了MLA,一種通過低秩鍵值聯合壓縮的注意力機制,在顯著減小KV緩存的同時提高計算效率。低秩近似是快速矩陣計算的常用方法,在MLA之前很少用于大模型計算。在這里我們可以看到DeepSeek團隊的量化金融基因在發揮關鍵作用。當然實現潛空間表征不止低秩近似一條路,預計后面會有更精準高效的方法。
從大模型架構的演進情況來看,Prefill和KV Cache容量瓶頸的問題正一步步被新的模型架構攻克,巨大的KV Cache正逐漸成為歷史。(事實上在2024年6月發布DeepSeek-V2的時候就已經很好的降低了KV Cache的大小)
2)DeepSeekMoE
為了讓1991年就提出的MoE架構更好的融入大模型體系,克服傳統MoE模型的訓練難題。DeepSeek采用了細粒度專家+通才專家的思路,不再使用少數大專家的結構,而是使用大量極小的專家結構。這個思路的本質在于將知識空間進行離散細化,以更好的逼近連續的多維知識空間,是一個非常好的方法。
無輔助損失的負載平衡策略可在不依賴輔助損失函數的情況下平衡分配計算/訓練負載,更好的提高訓練穩定性。
基于以上關鍵的改進,V3實現了更高的訓練效率,比性能類似的Llama3.1 405B 少了大約 10 倍的訓練計算量。
1.2 R1在CoT的進化
廣義上的DeepSeek-R1 不是一個單一的模型,還包括了R1的初始階段模型DeepSeek-R1-Zero,以及幾個基于R1蒸餾的較小的大模型。在這里我們主要討論R1-Zero和R1。
1.2.1 DeepSeek-R1-Zero
DeepSeek-R1-Zero最大的特點在于,該模型僅使用強化學習進行的訓練,通過各種思維鏈(CoT,Chain of Thought)數據特別是Long CoT數據來激活模型的推理能力。
DeepSeek-R1-Zero 是一個獨特的通過大規模強化學習 (RL,Reinforcement Learning) 訓練的模型,無需有監督微調 (SFT,Supervised Fine-Tuning) ,具備較強的推理(Reasoning)能力。
| ?首先要區分兩個容易混淆的概念:Reasoning(推理)?:通過對事實的考慮和分析來得出結論的過程。推理強調的是思考和決策的過程,比“推斷”具有更多的邏輯和分析過程。 ??Inference?(推斷):基于已有信息或數據推導出新的信息或結論的過程。推斷側重于通過既定的算法或模型來實現,與“推理”相比,更強調形式化和計算過程。? |
|---|
R1-Zero展示出自我驗證、反思和長鏈思維推理能力,甚至在推理方面得分略微超過R1。雖然R1-Zero有一些明顯的局限性,特別是在輸出可讀性和語言一致性方面,仍需要解決可讀性差和語言混合等問題。
這大概是第一個公開驗證大模型的推理(Reasoning)能力可以僅通過 強化學習來完成訓練。在我們看來,R1-Zero的價值遠超R1。按照NLP領域對語言的理解,人類的自然語言并不是最完美的推理語言。在R1-Zero的進一步進化過程中,或許可以構建出更適合推理的混合語言IR,建立更高效的推演體系。
1.2.2 DeepSeek-R1
相比之下,DeepSeek-R1采用了多階段訓練方法,加入了SFT,而不是采用純粹的強化學習,R1從一小組精心挑選的示例數據(稱為“冷啟動數據”)進行有監督微調(SFT),再進入強化學習。這種方法改善了 DeepSeek-R1-Zero 的語言可讀性和連貫性,同時在推理之外的測試中實現了更好的性能。
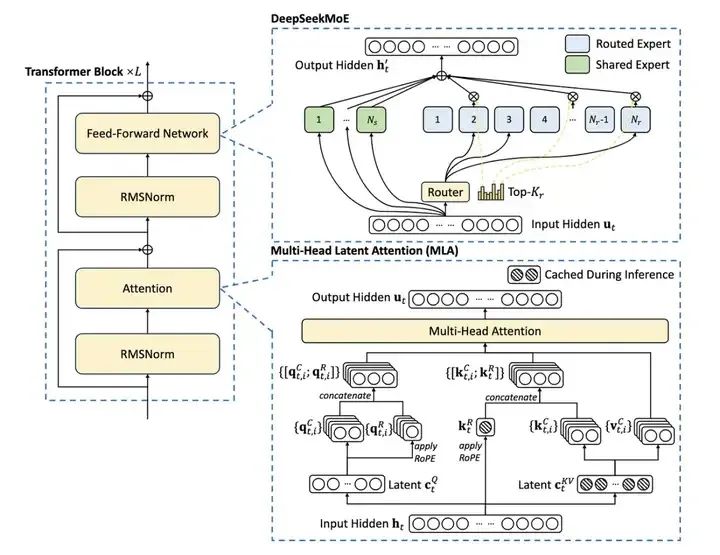
DeepSeek-V3整體架構(來源:DeepSeek)
2 V3/R1的架構提升
2.1 多頭潛注意力 (MLA)
2.1.1 從KV Cache(KV緩存)說起
當使用傳統Transformer在推斷(Inference)過程中計算并生成 Token(詞元)時,模型需要讀入所有過去 Token 的上下文,以決定接下來輸出什么Token。最直觀的方法就是簡單的再次進行一次包括所有過去 Token 的前向傳播(計算)。
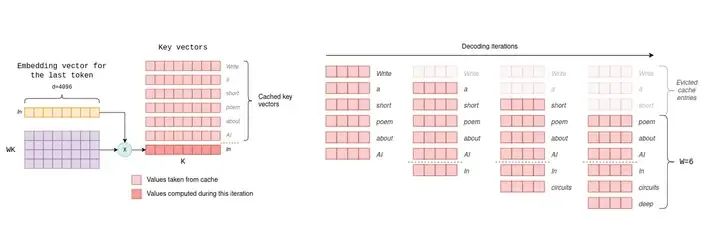
KV Cache(來源:互聯網)
傳統的基于 Transformer 的模型在推理過程中會計算每個鍵值 (KV) 對,但事實上這種方法效率并不高,因為大部分過去的 Token 已經在上一次計算中處理過了,重復計算會產生大量的浪費。
目前常用的方法是緩存所有過去 Token 的相關內部狀態,主要是注意力機制中的鍵(Key)和值(Value)向量。這也是鍵值緩存(簡稱 KV 緩存)名稱的由來。
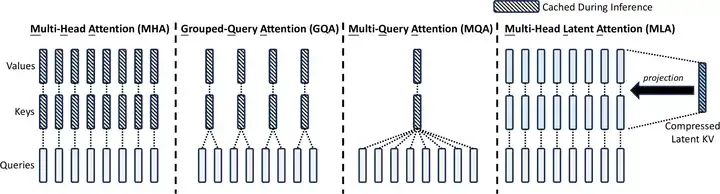
不同注意力機制的對比(來源:DeepSeek V2)
目前開源大模型中的主流方法是分組查詢注意力(Grouped-Query Attention)機制。在這種機制中,為每對鍵和值頭分配多個查詢頭,將查詢頭有效的分組在一起。在 Llama 3.3 70B 和 Mistral Large 2 等模型中,僅分組查詢注意力機制就將 KV 緩存大小減少了大約一個數量級。
2.1.2 MLA的原理與優勢
DeepSeek使用的Multi-Head Latent Attention技術可大大節省KV緩存,從而顯著降低了計算成本。
MLA的本質是對KV的有損壓縮,提高存儲信息密度的同時盡可能保留關鍵細節。該技術首次在 DeepSeek-V2 中引入,與分組查詢和多查詢注意力等方法相比,MLA是目前開源模型里顯著減小 KV 緩存大小的最佳方法。
MLA的方法是將KV矩陣轉換為低秩形式:將原矩陣表示為兩個較小矩陣(相當于潛向量)的乘積,在推斷過程中,僅緩存潛向量,而不緩存完整的鍵KV。這規避了分組查詢注意力和多查詢注意力的查詢的信息損失,從而在降低KV緩存的前提下獲得更好的性能。
矩陣的低秩近似(來源:互聯網)
另外為了與MLA技術的低秩KV壓縮兼容,DeepSeek也將編碼方式RoPE進行了改進,使V2/V3/R1獲得了長上下文的外延能力。

MLA方法有效降低KV Cache和訓練成本(來源:DeepSeek)
2.1.4 MLA是顛覆性創新嗎?
我們認為MLA是個非常有趣且先進的創新,這一工作建立在對注意力機制深度理解的之上,并且需要進行大膽謹慎的驗證。限于算力條件和個人ROI,能夠獨立完成這一創新的團隊并不多。能做出MLA這樣的工作,確實是達到國際一線架構水平了。換一個角度看,MLA也是建立在DeepSeek團隊的量化金融基因之上,不禁讓我們聯想到優秀的量化碼農對每個矩陣計算的FPGA底層優化。
MLA之外的KV Cache優化方法(來源:武漢大學)
我們認為,MLA之后,應該還會有QMLA(量化MLA)或者CMLA(壓縮MLA),甚至是超越現有Attention模式的技術出現,而用了很多年的Transformer也將經歷大的變革。真正的顛覆創新可能,正擺在DeepSeek和國內其他大模型團隊的面前。
2.2 MoE架構與輔助無損負載均衡
2.2.1 MoE與Dense模型的混戰
目前的主流的大模型架構可以分為Dense(稠密)架構和MoE架構。
| ?Dense模型?在深度學習中通常指的是一種全部神經元都參與計算的網絡結構。這種結構使得模型能夠充分利用數據特征,并且訓練過程中參數共享,減少了計算量和過擬合的風險。 |
|---|
一般來說,Dense模型可以視為僅有一個專家的MoE模型。在大模型領域,Dense模型和MoE各有各的應用場景和優勢,MoE還無法代替Dense模型的行業應用。
| Dense模型 | MoE模型 | |
|---|---|---|
| 優勢 | 在專業領域計算參數量更少,更節省計算資源 | 在通用計算領域激活的參數少,更節省計算資源 |
| 劣勢 | 在通用領域需要激活更多的參數,計算資源消耗大 | 在專業領域無需多位專家,容易產生大量參數冗余,浪費資源 |
相比Dense模型,MoE主要增加了專家路由,通過門控(開或關)的方法,負責將數據流引向不同的專家模塊。專家路由事實上引入了一個不連續的門控函數(對梯度計算不友好),這導致梯度下降優化方法在 MoE 訓練中表現不佳,甚至出現“路由崩潰”,即模型容易陷入始終為每個 Token 激活相同的少數專家的窘境,而不是將計算合理的傳播到所有的可用專家。這也是MoE模型訓練的難點。
2.2.2 無輔助損耗負載均衡
傳統的規避路由崩潰的方法是強制“平衡路由”,即通過訓練策略讓每個專家在足夠大的訓練批次中被激活的次數大致相等。這一策略也就是“輔助損失”。但這種強制性的輔助損失會由于訓練數據的結構不均衡特征,導致同領域的專家能力分散到不同的專家模塊之中,極度損害MoE模型的性能。理想的 MoE 應該有一些經常訪問高頻通用信息,并具備其他訪問較少的專業領域專家。如果強制平衡路由,將失去實現此類路由設置的能力,并且必須在不同的專家之間冗余地復制信息。
DeekSeek采用了“增加共享專家+無輔助損耗負載平衡”的方法解決這一問題。
DeepSeek將專家分為兩類:共享專家和路由專家。共享專家始終會被路由,在訓練中重點確保路由專家的路由均衡。
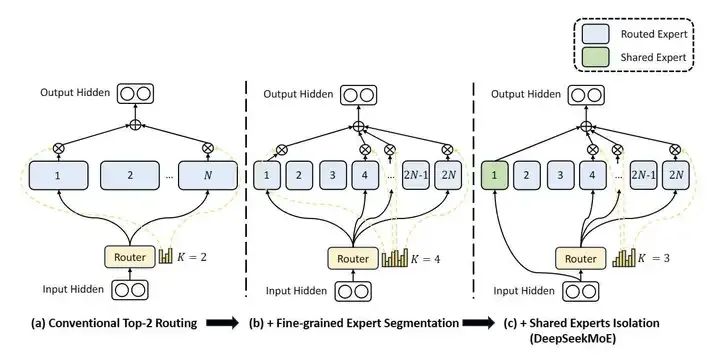
DeepSeekMoE與傳統的多路由和細粒度專家MoE對比(來源:DeepSeek)
無輔助損耗負載均衡(Auxiliary-Loss-Free Load Balancing)方法是將特定于專家的偏差項添加到路由機制和專家親和力中。偏差項不會通過梯度下降進行更新,而是在整個訓練過程中持續監控并進行調整以確保負載平衡。如果訓練中某個專家沒有獲得合理的命中次數,可以在每個梯度步驟中微調偏差項增加命中概率。
通過動態調整,DeepSeek-V3 在訓練過程中獲得了比有輔助損失均衡模型更好的性能。
從模型架構分析看,我們認為這種分配策略可能還不是理論最優的,但該方法已經比強制輔助損失有了顯著的改進。
2.2.3 MoE會是大模型的終局嗎?
MoE架構自1991年提出后,就一直在與Dense架構共生發展。
DeepSeek R1的推出確實大大推動了開源MoE大模型的發展,并為MoE的落地應用提供了更多可能。但是我們也應看到,MoE模型與應用領域高度和TOC(Total Owning Cost,總擁有成本)密切相關,很多場景MoE未必比Dense模型好。
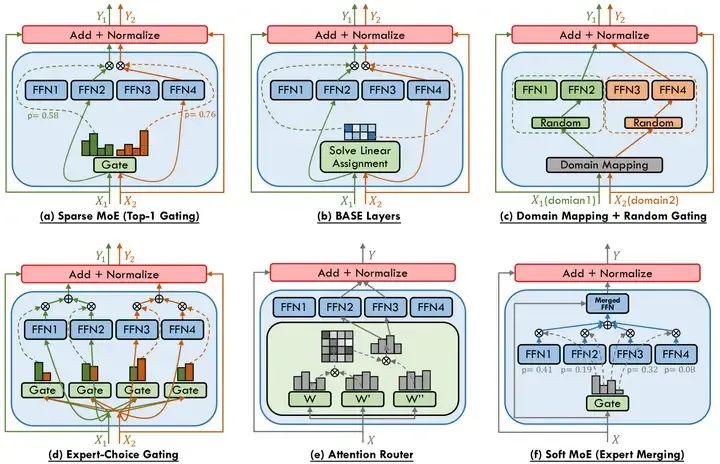
不同的MoE架構(來源:香港科技大學)
另外,MoE模型也有不同的細分架構類型。不是所有的MoE的參數量都遠大于計算帶寬要求。
MoE架構的本質是模型參數分布式存儲,MoE減少計算量的代價可能是不同專家模型的參數重復和總參數量增加,這往往也意味著更大更貴的HBM成本。外界傳言的MoE模型可以更小,其實是指的MoE模型蒸餾的Dense模型可以兼顧參數量和推理(Reasoning)性能。
不同應用場景對Dense和MoE模型的需求
| To B計算場景 | To C云計算場景 | To C邊緣/端側計算場景 | |
|---|---|---|---|
| 特點 | 專業領域應用多,對RAG高度依賴,不需要多專家 | 通用領域多,對檢索和訓練數據更新時間敏感,需要多專家 | 通用領域多,可不需要高性能/精度回答,不需要多專家 |
| 主力架構 | 行業大模型,主要是Dense架構 | 通用基礎模型,主要是MoE或MoA架構 | 限于成本,主要是Dense架構 |
| 占有率 | 較高 | 較低 | 目前較低 |
按照上表的分析,基于成本考慮,目前只有To C云計算場景(類似OpenAI的網頁版服務)才會真正用上MoE這種多專家的模型架構。
3 V3/R1訓練架構的獨特優勢
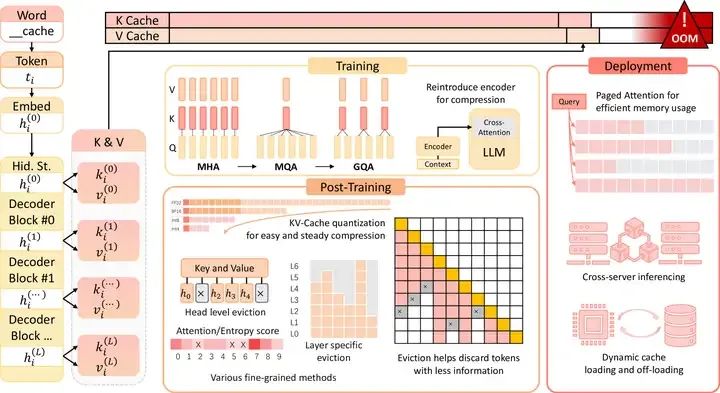
DeepSeek 的優勢不僅僅來自于其模型架構。從低比特FP8訓練到All-to-All通信優化,其專用訓練框架旨在盡可能提高訓練的速度,以最高效率在解空間中找到較優的MoE參數集。
國內很多人在看DeepSeek團隊時,更多關注了他們做Training的能力,但實際上DeekSeek的AI Infra能力,特別時軟硬件協同優化能力,才是他們超越國內其他大模型團隊的關鍵。
這一架構的核心優勢包括:
1)引入了FP8混合精度訓練框架,并首次在超大規模大模型訓練上驗證了這一框架的有效性。通過對FP8低比特計算和存儲的支持,實現了訓練的加速和GPU內存使用的減少。
2)設計了DualPipe算法來實現更高效的流水線并行,并通過計算-通信重疊隱藏了大模型訓練過程中的大部分通信開銷。
3)開發了高效的跨節點All-to-All通信內核,以充分利用InfiniBand(IB)和NVLink帶寬;對顯存使用進行了優化,無需使用昂貴的張量并行即可訓練DeepSeek-V3。
3.1 HAI-LLM框架的軟硬件協同設計
V3 的訓練基于DeepSeek自研的HAI-LLM 框架。HAI-LLM是一個高效、輕量級的訓練框架,其設計充分考慮了多種并行策略,包括DP、PP、TP、EP和FSDP的并行模式。
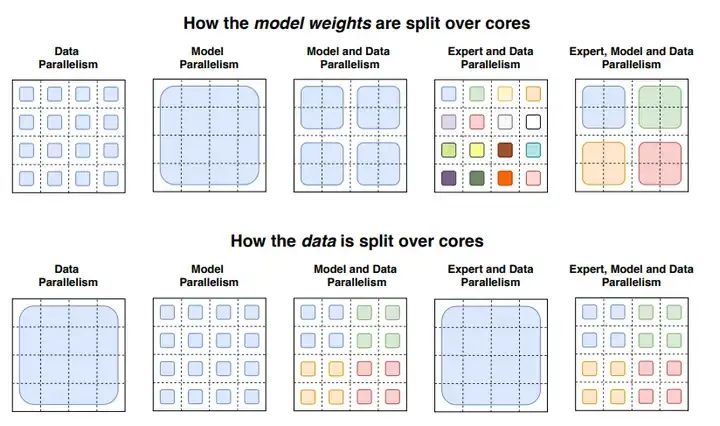
并行模式對比(來源:互聯網)
3.1.1 軟件層面的并行優化
HAI-LLM框架在軟件層面所作的并行改進和效率提升如下表所示:
HAI-LLM框架所作的并行改進(來源:中存算)
| 縮寫 | 簡介 | DeepSeek所做的工作或優化 |
|---|---|---|
| TP | 張量并行 (Tensor Parallelism):將模型層放置在并行執行計算的多個設備(計算芯片)上,包括逐行和逐列并行, | 將NVLink Bridge集成到系統中,在每對 GPU之間建立了 600GB/s 的帶寬,增加TP效率 |
| PP | 流水線并行 (Pipeline Parallelism):每個設備(計算芯片)都包含一部分模型層,每個訓練批次分為串行的小批次以進行流水線執行 | 通過配置數據并行排隊,規避單個節點(服務器)8個GPU共享一個 IB NIC流水線并行 (PP) 期間出現的網絡帶寬競爭,實現GPU的交替通信和91%的并行效率 |
| FSDP | 全共享數據并行 (Fully Sharded Data Parallel) 基于 ZeRO Stage 3 算法,對模型的參數、優化器狀態和梯度分布到不同的設備(計算芯片)上。在正向傳播期間,FSDP 執行allgather作來組裝完整的參數,并正向傳播完成后釋放;反向傳播期間,FSDP 執行 allgather獲取完整參數,并進行反向梯度計算,然后執行reduce-scatter以同步所有設備之間的梯度,每個設備只保留部分梯度、參數和優化器更新 | 基于 ZeRO Stage-3 算法實現FSDP。將 allgather 和 reduce-scatter 通信與前向和反向傳播計算重疊,拆分反向傳播步驟以增強重疊,減少通信量。與PyTorch的 FSDP 相比,HAI-LLM 的 FSDP 將訓練時間縮短了近一半 |
| DP | 數據并行 (Data Parallelism):模型和優化器的狀態在多個設備(計算芯片)之間復制,數據均勻分布給所有設備進行并行計算 | 對PCIe進行工程優化,提升DP |
| EP | 專家并行 (Expert Parallelism):在MoE 訓練期間,MoE 模型的不同專家分布在不同的設備(計算芯片)上,由門控單元將輸入的Token分配給不同的專家 | 對PCIe進行工程優化,提升EP |
根據DeepSeek的論文,V3 應用了 16 路流水線并行 (PP)、跨越 8 個(服務器)節點的 64 路專家并行 (EP)和 ZeRO-1 數據并行 (DP)。
3.1.2 針對軟件并行策略的硬件優化
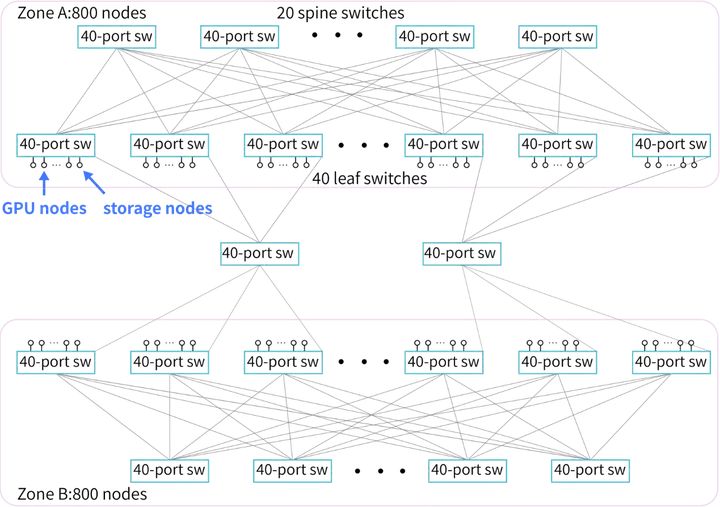
低成本的萬卡集群架構(來源:DeepSeek)
為了配合HAI-LLM訓練框架(軟件),DeepSeek采用兩層Fat-Tree拓撲+ InfiniBand (IB)作為集群架構(硬件)。這一集群架構的核心思路是減少互連層次,降低訓練的綜合成本。相對DGX-A100 的標準萬卡集群三層Fat-Tree的1320個交換機,DeepSeek的同規模集群僅僅需要122臺交換機,至少節省了40%的互連成本。
3.1.3 針對硬件架構的軟件優化
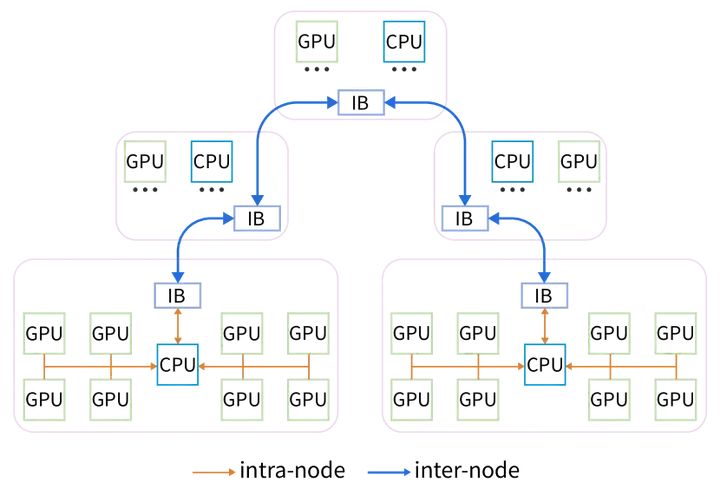
針對硬件架構優化的HFReduce(來源:DeepSeek)
針對所采用的硬件架構特點,DeekSeek開發了HFReduce(針對不使用NVLink的方案),以執行高效的 allreduce操作。 HFReduce會首先執行節點內 reduce,然后通過 CPU 執行節點間 allreduce,最后將 reduced 數據傳輸到 GPU 。這樣的優化需要DeepSeek團隊對硬件互連有非常深刻的理解。
當然DeepSeek團隊也開發了基于NVLink的HFReduce with NVLink,在將梯度傳遞給 CPU 之前,先在NVLink 互連的GPU 之間執reduce減作;當 CPU 返回結果時,會將數據切分并分別返回給 NVLink 連接的配對 GPU,再通過 NVLink 執行allgather。
3.2 FP8 訓練框架體系
3.2.1 低比特訓練框架的構建
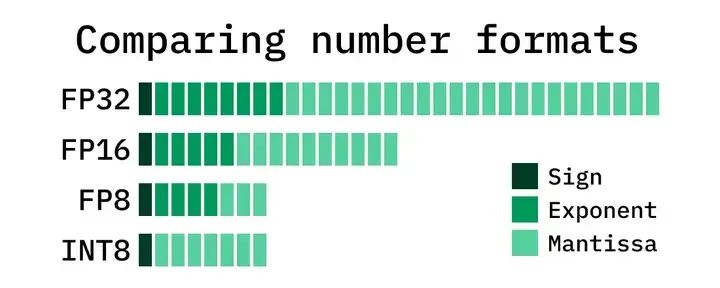
FP8與其他數據格式占據空間對比(來源:互聯網)
通常的大模型訓練會采用BF16(16位浮點)或FP32/TF32(32位浮點)精度作為數據計算和存儲的格式,來確保較高的訓練精度。相比之下,FP8占用的數據位寬僅為FP32的1/4,可以有力的提升計算速度,降低對存儲的消耗。當然,FP8也存在精度不高,容易導致訓練失敗的潛在問題。
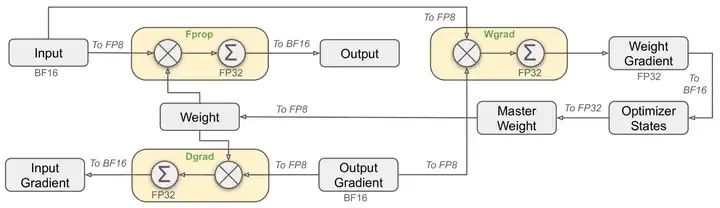
FP8訓練框架局部方案(來源:DeepSeek)
DeepSeek-V3 使用 FP8(8 位浮點數)來提高計算速度并減少訓練期間的顯存使用量。為了讓FP8更好的完成訓練,DeepSeek專門設計了針對FP8的訓練框架體系。當然,就在撰寫本文的時候,微軟已經跑通了FP4(4位浮點數)的完整模型訓練。
使用FP8框架進行訓練的主要挑戰在于精度與誤差的處理。
DeepSeek為其FP8低比特訓練框架做了以下優化:
1)細粒度量化
將數據分解成更小的組,每個組都使用特定乘數進行調整以保持高精度。這一方法類似于Tile-Wise或Block-Wise。對于激活,在 1x128 大小的基礎上對計算數據進行分組和縮放;對于權重, 以128x128 大小對計算數據進行分組和縮放。該方法可以根據最大或最小數據調整縮放系數,來更好的適應計算中的異常值。
2)在線量化
為了提高精度并簡化框架,該框架在線計算每個 1x128 激活塊或 128x128 權重塊的最大絕對值,在線推算縮放因子,然后將激活或權重在線轉化為 FP8 格式,而不是采用靜態的歷史數據。相對靜態的量化方法,該方法可以獲得更高的轉換精度,減小誤差的累積。
3)提高累加精度
FP8在大量累加時會累積出現隨機誤差。例如FP8 GEMM在英偉達 H800 GPU上的累加精度保留 14 位左右,明顯低于 FP32 累加精度。以 K = 4096 的兩個隨機矩陣的 GEMM 運算為例,Tensor Core 中的有限累加精度可導致最大相對誤差接近 2%。
DeepSeek將中間結果儲存計算升級為 FP32(32位浮點),實行高精度累加,然后再轉換回 FP8,以降低大量微小誤差累加帶來的訓練偏差。
4)低精度/混合精度存儲與通信
為了進一步減少 MoE 訓練中的顯存和通信開銷,該框架基于FP8 進行數據/參數緩存和處理激活,以節省顯存與緩存空間并提升性能,并在 BF16(16位浮點數)中存儲低精度優化器狀態。
該框架中以下組件保持原始精度(例如 BF16 或 FP32):嵌入模塊、MoE 門控模塊、歸一化算子和注意力算子,以確保模型的動態穩定訓練。為保證數值穩定性,以高精度存儲主要權重、權重梯度和優化器狀態。
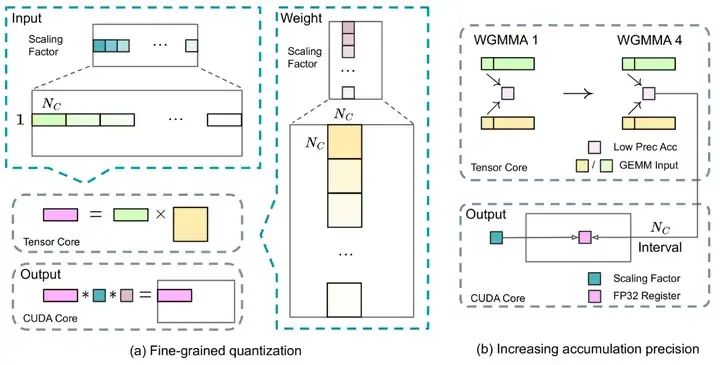
細粒度量化與提高累加精度(來源:DeepSeek)
以上這些針對FP8訓練的優化設計,都是精雕細作的工作,需要框架設計人員對GPU硬件架構和訓練誤差具有很強的整合分析能力。從DeepSeek的FP8訓練框架來看,這個團隊具有很強的技術和工程整合能力,已經不是單純的大模型算法或AI Infra團隊。
3.2.2 對英偉達GPU市場有巨大影響?
2025年1月27日,英偉達股價暴跌近17%,市值蒸發近6000億美元,創下美國歷史上單日最大市值跌幅紀錄。AI領域的明星公司普遍遭受重創:博通(Broadcom)下跌17.4%,AMD下跌6.4%。微軟下跌2.1%。此外,AI產業鏈的衍生板塊也未能幸免,電力供應商Constellation Energy下跌近21%,Vistra下跌28%。國內很多媒體認為這是DeepSeek的崛起,引起投資者對于英偉達等半導體企業估值過高的擔憂。
英偉達估值是否過高不好說,畢竟MoE架構的發展已經展現出“存力重要性優于算力+對存儲帶寬瓶頸下降”的傾向。但從技術角度看,DeepSeek的大模型目前依然存在對英偉達GPU的路徑依賴。
1)目前英偉達仍在低比特計算方面領先。包括DeepSeek使用的FP8和微軟使用的FP4,都是由英偉達率先產品化并推向市場的。FP8訓練最早也是在英偉達內部開始驗證的。英偉達之外,暫時還沒有企業有這樣的生態推動力和落實能力。
2)MoE模型仍屬于大模型演進的常規路徑,并不會因為MoE模型的路徑切換導致GPU應用不及預期。目前主要的MoE模型依然是基于英偉達生態構建的,在算力單價昂貴、模型性能仍需提升的現在,MoE的應用事實上是基于有限的算力成本,進一步提升通用大模型(以to C為主)性能的有效路徑。這個路線早已有之,不管DeepSeek的影響力是否擴大,目前通用大模型都在朝著這個方向發展。過于夸大DeepSeek對AI產業的影響,只會加速美國商務部對DeepSeek的封禁速度,對DeepSeek自身反而不利。
3)DeepSeek使用的一些訓練成本優化技術屬于定制化技術,其他競品企業未必有類似的定制能力。例如前面提到的混合精度存儲/計算,與模型本身的特征高度綁定,遷移起來并不簡單,屬于DeepSeek內部的定制化技術,與量化交易中的FPGA優化有原理類似之處。這類定制化技術一般難以簡單的復制,其他企業短期內難以復盤,進行規模化成本降低的概率不高。有這個AI Infra能力的早就已經做了,沒有這個能力也不會冒著成本不可控的風險冒然進入。
我們認為DeepSeek的V3/R1模型事實上為英偉達GPU開拓了除Llama開源系列Dense模型之外的MoE開源模型新大陸,等同于為蘋果的IOS市場增加了新的免費Killer App。
DeepSeek本身對英偉達的股價影響,看起來更像是駱駝背上的最后一根稻草,大概不會超過以下幾個因素:
1)美國貿易關稅風險。
2)B200/5090不達市場預期的風險。
3)大陸高成本GPU(主要是H100)算力過剩的風險。
4)對大陸禁運加強的風險。
3.3 DualPipe優化
V3/R1的訓練框架中引入DualPipe算法以實現高效的流水線并行性。
與現有的流水線并行(PP)方法相比,DualPipe具備以下優勢:
1)DualPipe的流水線氣泡更少,信道使用效率更高。
2)DualPipe將前向和后向傳播中的計算和通信重疊,解決了跨節點專家并行(EP)帶來的繁重通信開銷問題.
3)在確保計算與通信比例恒定的情況下,具有很好的Scale-out能力。
DualPipe算法將每個數據塊分為四個部分:attention(圖中ATTN)、all-to-alldispatch(圖中DISPATCH)、MLP 和 all-to-all combine(圖中COMBINE)。對于后向塊,attention和 MLP 都進一步分為后向輸入、后向權重。對于一對前向和后向塊,針對通信和計算的過程和瓶頸進行優化。DualPipe采用雙向流水線調度,同時從流水線發送前向和后向數據,盡可能提高使用率。

DualPipe的流水線(來源:DeepSeek)
3.4 跨節點 All-to-All 通信與顯存優化
V3/R1的訓練框架還定制了高效的跨節點All-to-All通信內核,以充分利用IB 和 NVLink 帶寬,并節約流式多處理器 (SM,(Stream Multiprocessor)。DeepSeek還優化了顯存分配,以在不使用或少使用張量并行 (TP) 的情況下訓練 V3/R1。
3.4.1 對于SM與NVLink的優化
為了保證 DualPipe的計算性能不被通信影響,DeepSeek定制了高效的跨節點 All-to-All 通信內核(包括dispatching和 combining),以節省專用于通信的 SM數量。
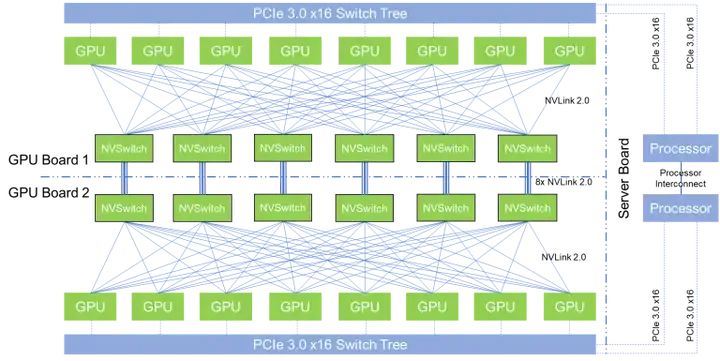
傳統的基于NVSwitch的All-to-All通信結構(來源:互聯網)
通信內核(通信SM控制代碼)的實現與MoE 門控算法和集群網絡拓撲是按照軟硬件協同的思路來進行設計的。具體來說,在集群中,跨節點 GPU與 IB 完全互連,節點內(單臺服務器內)通信通過NVLink完成。NVLink 提供 160 GB/s 的帶寬,約是 IB 的 3.2 倍 (50 GB/s)。
為了有效利用IB 和NVLink的不同帶寬,DeepSeek將每個Token(詞元)的分發限制為最多4 個節點,從而減少IB流量限制的影響。 對于每個Token,在做節點間路由決策時,先通過IB傳輸到目標節點上具有相同節點內索引的GPU;到達目標節點后,再通過NVLink 轉發到托管目標專家的特定GPU。通過這種方式,通過IB和NVLink的通信重疊,平均每個Token可以在每個節點選擇3.2名專家,而不會產生額外的NVLink開銷。
實際算法中,V3/R1只通過路由選擇了8個專家,但在保持相同通信成本的情況下,該架構可以擴展到最多13 個專家(4 個節點x3.2個專家/節點)。
DeepSeek還采用了warp(線程束)專用化技術,將20個SM劃分為10個通信信道。
1)在調度過程中,(a)IB 發送、(b)IB 到NVLink 轉發、(c) NVLink 接收由相應的warp處理。分配給每個通信任務的warp數量會根據所有SM的實際工作負載動態調整。
2)在合并過程中,(a) NVLink 發送、(b)NVLink到IB的轉發和累積、(c)IB接收和累積也由動態調整的warp處理。
3)dispatching 和combining kernel都與計算流重疊,采用定制的PTX(Parallel Thread Execution)指令以自動調整通信塊大小,減少了對L2緩存的使用和對其他 SM 的干擾。
3.4.2 顯存節省技術
為了減少訓練期間的內存占用,V3/R1還采用了以下技術節省顯存:
DeepSeek采用的顯存節省技術(來源:中存算)
| 技術 | 方法說明 | 優勢 |
|---|---|---|
| RMSNorm 和MLA Up-Projection 的重新計算 | 在反向傳播期間重新計算所有MSNorm操作和MLA Up-Projection,無需持久存儲其輸出激活 | 以算代存,充分利用GPU內算力充沛但緩存不足的特點 |
| 在CPU內存中保存指數平均數指標(EMA) | 在CPU 內存中保存EMA,并在每個訓練步驟后異步更新 | 把EMA從GPU顯存占用改為CPU內存占用,釋放動態存儲空間 |
| 在多標記預測(MTP)中共享嵌入和輸出頭 | 使用DualPipe 策略,將模型最淺的層(包括嵌入層)和最深的層(包括輸出頭)部署在相同的PP等級上 | 允許MTP模塊和主模型之間物理共享參數、梯度、嵌入和輸出頭,提升顯存效率 |
3.4.3 打破了CUDA生態壁壘?
網上很多人,看到DeepSeek使用了PTX指令,而沒有直接使用CUDA進行SM編程,就認為DeepSeek打破了CUDA生態的壟斷。
但實際上,
1)PTX指令集也是CUDA生態的一環,是CUDA生態的基礎。
2)PTX指令比CUDA更底層,與英偉達的綁定比CUDA更深。
3)CUDA是以PTX指令集為基礎構建的,是PTX的外殼和泛化。
4)PTX的移植比CUDA移植挑戰更大,難以在國產GPU上直接移植。
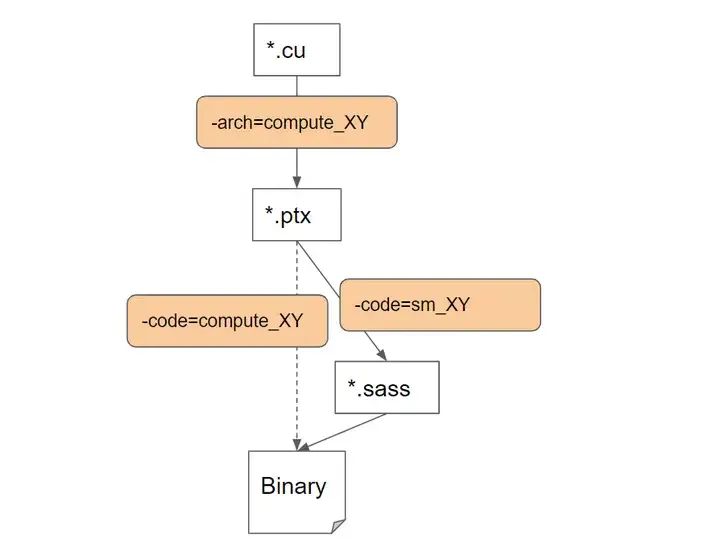
CUDA與PTX、SASS的層次關系(來源:互聯網)
如果把CUDA理解為C語言的話,PTX相當于CUDA的高級匯編語言,可以在不同的GPU上運行。另一種更加底層的指令集是Streaming Assembly(SASS),與GPU的型號深度幫綁定。無論PTX還是SASS都是英偉達的根基,其他GPU廠家很難插手。
DeepSeek在訓練過程中使用PTX,感覺就是量化碼農用C語言寫交易代碼,發現優化效率不夠,那么就嘗試在C語言中嵌入匯編語言來提高硬件調度效率。難道這就等于打破了C語言的江湖地位?
3.4.4 挖了NVLink的墻角?
有傳言說DeepSeek主要使用Infiniband,以EP(專家并行)代替TP(張量并行),挖了NVLink的墻角,從而堅定的認為以PCIe(節點內互連)+IB(節點間互連)就足以進行大模型的訓練。
在這里面,NVLink主要負責芯片間(C2C)的通信,而Infiniband負責節點間(服務器間)通信。如果使用PCIe進行C2C通信,帶寬遠不如NVLink。
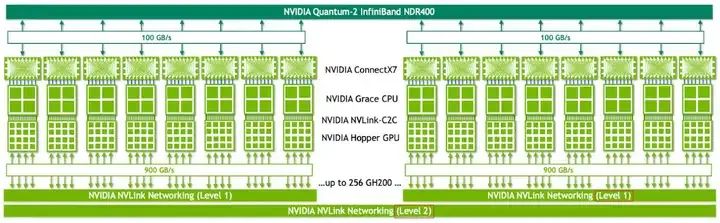
NVLink+Infinband互連(來源:英偉達)
規避NVLink的想法很美好,但現實很骨感。按照DeepSeek發表的論文描述,只是在早期沒有加入NVSwitch的時候用過PCIe+InfiniBand實現HFReduce,當具備NVSwitch后就立刻增加了HFReduce with NVLink。特別是在V3的論文中,明確寫了針對NVLink信道加入了定制PTX優化,好讓更多的有效SM參與計算。
這就好比學校的教學高樓里沒有大電梯,怕樓梯上孩子太多出危險,就先用“算法+樓梯”代替,拿到“算法許可”的小孩才能到不同樓層去報道。但不能說這樣就挖了“電梯”的墻角,卡住了“電梯”的脖子。一個高效的訓練系統,依然需要大量的C2C或D2D互連實現更優的拓撲結構。咱不能因為玄奘法師能克服艱難險阻走到古印度取到真經,就認為需要反思火車飛機的重要性。
“打破CUDA壟斷”?“挖了NVLink的墻角”?“引發英偉達市值大跌”?“證明大模型算力建設浪費”?“算力霸權轉移”?“國運級的創新”?這些說法是否屬實?
本文是從V3到R1的架構創新與誤傳的萬字長文分析的下篇。下面我們繼續分析V3與R1的訓練和蒸餾,分層解讀DeepSeek的創新。
中場休息
4 V3的訓練流程
DeepSeek的R1是以V3為基礎構建的(冷啟動)。如果想深入理解R1的訓練,就要先看V3的訓練流程。V3的訓練包括預訓練(含基礎預訓練和上下文長度擴展)、后訓練三個階段。
在預訓練階段后,對DeepSeek-V3進行了兩次上下文長度擴展,第一階段將最大上下文長度擴展到32K,第二階段進一步擴展到128K。然后在 DeepSeek-V3的基礎模型上進行包括有監督精調 (SFT) 和強化學習(RL)在內的后訓練,使其更貼近人類的偏好。
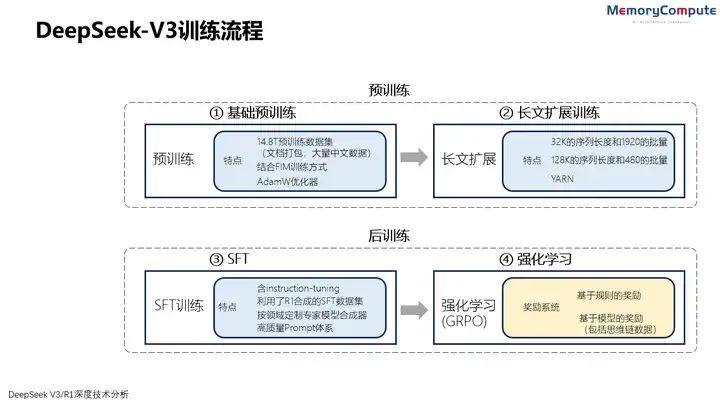
DeepSeek-V3訓練流程(來源:中存算)
4.1 V3的基礎預訓練
DeepSeek-V3 總共包含 671B參數,其中每個Token激活了37B。在路由專家中,每個Token激活8個專家,并確保每個Token最多發送到4個節點,以減小通信資源的浪費。多Token預測(MTP)深度設置為1,即除了下一個 Token之外,每個Token還將預測一個額外的Token。
在14.8T預訓練數據集結構上,V3采用了以下策略:
1)提高數學和編程樣本的比例來優化預訓練語料庫,以提升推理能力。
2)基于中國互聯網可用的語料庫整合了更多的中文數據。(這也是V3能玩中文梗的關鍵)
3)將多語言覆蓋范圍擴展到英文和中文之外。
4)優化數據處理/過濾算法,在保持語料庫多樣性的同時最大限度減少信息冗余。
過濾掉有爭議的內容,減少特定區域文化引入的數據偏差
5)通過文檔打包,減少在短文本塊的訓練浪費,同時在訓練過程中沒有使用交叉樣本注意力屏蔽。
高質量的數據結構與數據投喂順序,其實是大模型性能提升的關鍵。可惜DeepSeek并沒有給出預訓練數據更具體的構建方法。
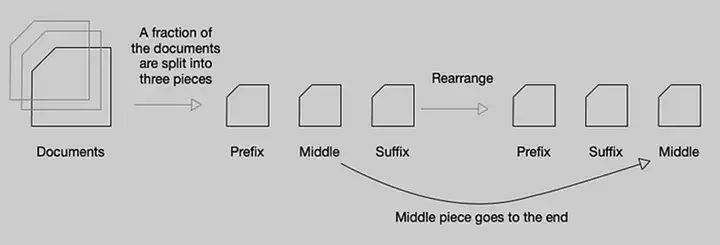
Fill-in-Middle方法(來源:互聯網)
V3的訓練采用前綴-后綴-中間(PSM)框架來構建FIM訓練數據。Fill-in-Middle(FIM,中間補全)是一種針對代碼補全能力的預訓練方式,模型在訓練過程中學習使用上下文的語境來預測文段中間缺失的部分。FIM策略不會損害下一Token預測(NTP)能力,同時可使模型能夠根據上下文線索準確預測中間文本。
V3使用AdamW 優化器來預訓練,同時避免過度擬合。
4.2 V3長文擴展訓練
在基礎預訓練后,V3使用YARN技術將上下文長度,按照兩階段訓練擴展到128K,每個階段包括1000步。在第一階段,使用32K的序列長度和1920的批量來執行1000步訓練。在第二階段,采用128K的序列長度和480個序列的批量大小執行1000步訓練。
4.3 V3的后訓練/精調
4.3.1 V3的有監督精調(SFT)
V3的有監督精調做了以下這些事:
1)梳理指令精調(instruction-tuning)數據集。該數據集包括1.5M個實例,跨多個域,每個域都量身定制的不同的數據合成方法。
2)利用DeepSeek-R1 模型合成與推理(Reasoning)相關的SFT數據集。這里很有意思,基于R1來SFT V3,再基于V3冷啟動R1。感覺上這里有關鍵的訓練信息沒有透露,DeepSeek應該還是留了一手。
3)為特定領域(例如代碼、數學或一般推理)構建量身定制的專家模型數據合成器。使用復合有監督精調和強化學習訓練該專家模型。訓練過程中為每個實例生成兩種不同類型的 SFT樣本:第一種將問題與其原始響應耦合,格式為
4)建立高質量提示(Prompt)體系,引導模型形成自身的反饋與驗證機制。同時整合了來自R1合成的數據,通過強化學習加強這一能力。
5)對于非推理數據(例如創意寫作、角色扮演和簡單的問答),利用 DeepSeek-V2.5生成數據,并通過人工注釋驗證數據的準確性。
4.3.2 V3的強化學習
V3的強化學習包括獎勵模型與組相對策略優化(GRPO)。
與GPT-4類似,V3中獎勵模型包括:
1)基于規則的獎勵模型
對于可以使用特定規則驗證的問題,采用基于規則的獎勵模型來提供訓練反饋。例如,對于LeetCode問題,可以利用編譯器根據測試用例生成反饋。基于規則的模型驗證,可以確保更高的生成可靠性。
2)基于模型的獎勵模型
對于不具有收斂性的問題,依靠模型判斷來確進行強化學習。V3訓練中構建了特殊的偏好數據,該數據同時包括提供最終獎勵結果和形成獎勵的思維鏈,以降低特定任務中的獎勵破解攻擊風險。
大模型的訓練通常用無監督或有監督進行預訓練,然后通過有監督精調(SFT)進一步學習。然而SFT有時難以將人類的偏好顯式地整合進去,這時就需要強化學習來進行精調。在以往的大模型訓練中一般使用PPO(Proximal Policy Optimization)來形成梯度策略。PPO的代價在于需要維護較大的價值網絡(也是一個神經網絡),需要占用較大的顯存與計算資源。
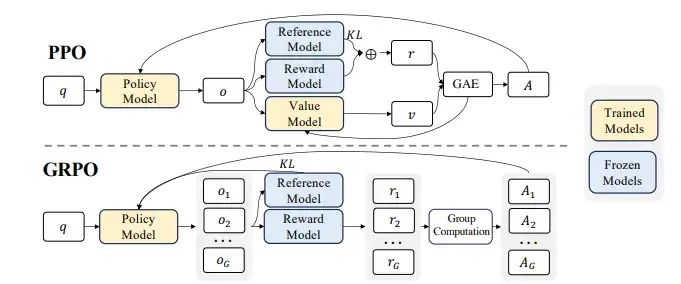
GRPO與PPO對比(來源:DeepSeek)
V3中則采用了DeepSeek提出的GRPO(Group Relative Policy Optimization)策略,只需要在一個分組內進行多個采樣輸出的比較,再根據比較結果選擇較優的策略。GRPO中不再需要一個顯式的價值網絡,從而降低了顯存占用并提高了訓練速度。
GRPO的計算流程包括:
1)采樣一組輸出并計算每個輸出的獎勵。
2)對組內獎勵進行歸一化處理。
3)使用歸一化后的獎勵計算優勢函數。
4)通過最大化目標函數更新策略模型。
5)迭代訓練,逐步優化策略模型。
5 R1的訓練流程
5.1 無SFT的R1-Zero訓練
DeepSeek-R1 建立在其基礎模型DeepSeek-V3的混合專家(MoE)架構之上,采用專家并行方式,對于任意輸入,只有部分參數處于活躍狀態。
作為R1的無SFT版本,R1-Zero使用 DeepSeek-V3-Base 作為基礎模型,直接使用 GRPO進行強化學習來提升模型的推理(Reasoning)性能, 根據準確度和格式進行訓練獎勵。
R1-Zero的訓練過程具有重要意義:
1)在大模型訓練領域,SFT 需要高質量的人工標注數據(標注過程一般需要很長周期、成本高,且可能因標記者的偏好而引入潛在偏差)。
2)復雜的推理任務可能超出了普通人類的能力。無SFT的純強化學習方法也許可以使模型能夠涌現出超越傳統人類思維上限的超級推理能力。
3)無SFT的純強化學習不依賴于顯式標注,允許模型使用非自然語言表征方法進行“思考”,從而具有超越自然語言進行邏輯推理的潛力。
獎勵的計算方式在很大程度上決定了強化學習訓練的效果。DeepSeek-R1-Zero 的基于規則的獎勵系統包括:
1)準確度獎勵(Accuracy rewards)。評估響應是否正確。
2)格式獎勵(Format rewards)。獎勵模型將其思考過程置于“

DeepSeek的準確度獎勵與格式獎勵(來源:互聯網)
通過強化學習訓練,R1-Zero 形成了復雜的推理能力,包括反思(模型重新審視并重新評估其先前的回答)以及探索解決問題的替代方法。這些能力并非通過常規編程或提示工程實現的,而是大模型在強化學習環境中自發產生的能力。
根據R1的論文,強化學習訓練中R1-Zero形成的另一個關鍵特征是頓悟時刻(Aha Moment)。R1-Zero 通過重新評估其初始方法學會為問題分配更多的思考時間(更長的推理)。無需明確的教模型如何解決問題,只需為其提供適當的激勵,模型就會自主形成解決問題的策略。這也說明強化學習有潛力解鎖新的智能水平,為未來更自主、更具適應性的模型鋪平道路,提供了形成超級智能的可能路線。
與OpenAI的GPT-4 相比,DeepSeek-R1-Zero在推理任務上表現出了顯著的改進。例如,在AIME2024 基準(推理能力測試)上,DeepSeek-R1-Zero的性能從15.6%躍升至71.0%,這表明R1-Zero的無SFT推理訓練方法是有效的。
5.2 DeepSeek-R1的訓練流程
DeepSeek-R1 的訓練過程分為4個階段,包括使用數千高質量CoT示例進行SFT的冷啟動,面向推理的強化學習,通過拒絕抽樣的SFT,面向全場景任務的強化學習與對齊。
兩個SFT階段進行推理和非推理能力的能力植入,兩個強化學習階段旨在泛化學習推理模式并與人類偏好保持一致。
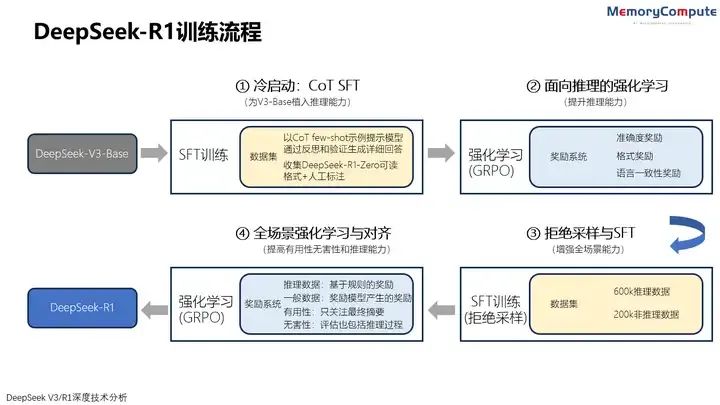
DeepSeek-R1訓練流程(來源:中存算)
5.2.1冷啟動(Cold Start):CoT SFT
與R1-Zero不同,R1首先基于DeepSeek-V3-Base進行有監督精調(SFT),以克服強化學習的早期不穩定。DeekSeek認為這種基于人類先驗知識冷啟動并進行迭代訓練的方式更適合推理模型。
由于這一訓練階段主要采用CoT數據,我們更喜歡將其稱為CoT SFT。
為構建少量的長CoT數據,DeepSeek探索了幾種合成方法:使用長CoT 的few-shot提示作為示例,直接提示模型通過反思和驗證生成詳細回答,以可讀格式收集DeepSeek-R1-Zero 輸出,并通過人工標注員的后處理來完善結果。在此步驟中收集了數千個冷啟動樣本以進行精調。
其中可讀模式指為每個回答在末尾包含一個摘要,并過濾掉不易閱讀的部分。其輸出格式為 |special_token|
5.2.2 面向推理的強化學習
在基于冷啟動數據對V3-Base 精調后,采用與R1-Zero相當的強化學習訓練流程,基于GRPO進行強化學習,根據準確度和格式進行訓練獎勵。為了解決語言混雜問題,還在強化學習訓練中引入了語言一致性獎勵,該獎勵以CoT中目標語言單詞的比例計算。
此階段主要提升模型的推理(Reasoning)性能,特別是在編碼、數學、科學和邏輯推理等推理密集型任務,這些任務涉及定義明確且解決方案明確的問題。
5.2.3 拒絕采樣與SFT
這是另一個使用標記數據的有監督精調 (SFT)訓練階段,分批進行了兩個epoch的精調,樣本量為800k。800k中包括600k推理數據和200k非推理數據。
與主要側重于推理的冷啟動數據不同,此階段結合了來自其他領域的數據,以增強模型在寫作、角色扮演和其他通用任務中的能力。
拒絕采樣(Rejection Sampling)提供了一種橋梁,使用易于采樣的分布來近似訓練真正感興趣的復雜分布。目標響應(ground-truth)從一組生成的回答經過拒絕采樣生成,其分數由獎勵系統確定。
| 拒絕采樣(Rejection Sampling)是一種蒙特卡洛方法,和重要性采樣一樣,都是在原始分布難以采樣時,用一個易于采樣的建議分布進行采樣,通過拒絕原始分布之外的采樣數據來獲得采樣結果。拒絕采樣只是為了解決目標分布采樣困難問題,該方法需要原始分布是已知的。 |
|---|
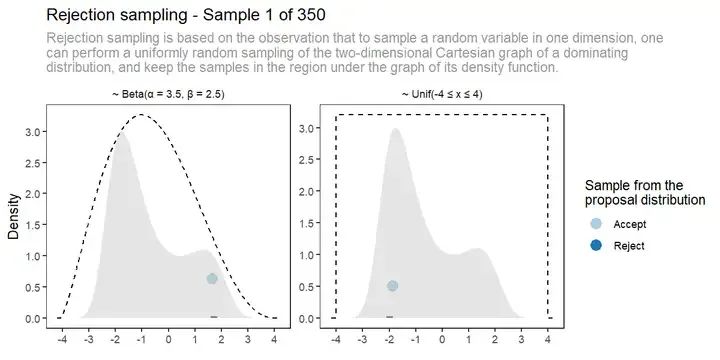
拒絕采樣示意(來源:互聯網)
600k推理數據的生成:
1)通過從上一輪強化學習訓練的檢查點進行拒絕抽樣,整理推理提示并生成推理軌跡(Reasoning Trajectories)。
2)除基于規則獎勵進行評估的數據外,還包括了基于獎勵模型的V3判斷生成數據。
3)過濾掉了混合語言、長段落和代碼塊的思路鏈數據。
4)對于每個提示(Prompt),會生成多個回答,然后并僅保留正確的響應。
200k非推理數據的生成(如寫作、事實問答、自我認知和翻譯等):
1)采用DeepSeek-V3流程并復用V3 的部分 SFT 數據集。
2)可調用V3生成潛在的思路鏈,再通過提示回答。
3)對于更簡單的查詢(例如“你好”),不提供CoT回答。
5.2.4 面向全場景的強化學習與對齊
最后,再次進行面向全場景的強化學習和人類偏好對齊,以提高模型的有用性和無害性,并完善推理能力。此階段還整合了來自不同管道的數據,將獎勵信號與不同的提示分布相結合。
1)使用獎勵信號和多種提示分布(Diverse Prompt Distributions)的組合來訓練模型。
2)對于推理數據,利用基于規則的獎勵來指導數學、代碼和邏輯推理領域的訓練過程。
3)對于一般數據,采用獎勵模型來捕捉復雜微妙場景中的人類偏好。即參考DeepSeek-V3 管訓練流程,采用類似的偏好對和訓練提示分布。
4)對于有用性,只關注最終摘要,以確保重點響應對用戶的實用性和相關性,最大限度減少對底層推理過程的干擾。
5)對于無害性,評估模型的整個響應,包括推理過程和摘要,以識別和減輕生成過程中可能出現的潛在風險、偏見或有害內容。
至此已完成R1的完整訓練過程,獲得了具備全場景推理能力的通用MoE模型,上下文長度均為128K。
| Model | #Total Params | #Activated Params | Context Length |
|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K |
| DeepSeek-R1 | 671B | 37B | 128K |
5.3 從MoE回歸Dense(蒸餾SFT)
盡管MoE架構有各種優點,特別是在通用的to C領域具備低成本的優勢。但是MoE的架構特點使得其可能不太適用于專業應用場景(例如單一專家場景)和資源限制場景(例如端側推理)。
| 蒸餾是將復雜的大型神經網絡壓縮為更小、更簡單的神經網絡,同時盡可能多的保留結果模型的性能的過程。此過程涉及訓練較小的“學生“神經網絡,通過其預測或內部表示的精調來學習模擬更大、更復雜的“教師”網絡的行為。 |
|---|
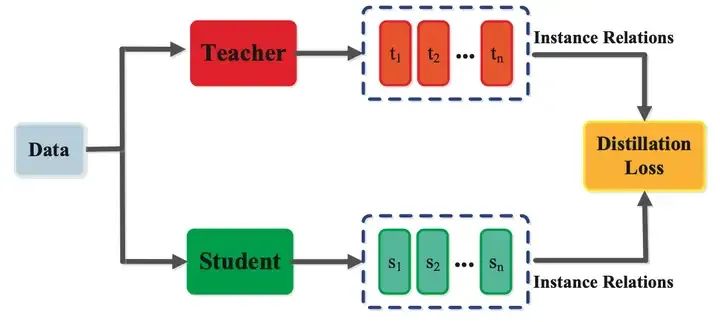
模型蒸餾方法(來源:互聯網)
為了能夠將推理能力遷移到MoE架構不適合的場景,DeepSeek選擇Llama和Qwen系列開源大模型進行蒸餾,使相應的Dense模型也能獲得推理能力。與使用強化學習相比,直接SFT更適合較小的大模型,蒸餾完成的Dense模型推理能力明顯好于原開源模型。
DeepSeek-R1-Distill模型(來源:DeepSeek)
| Model | Base Model |
|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct |
5.4 更大顯存容量顯得尤為重要?
隨著MoE架構大模型的快速推廣,產業界也有看法認為在單塊GPU上集成更大的超過對等算力的顯存或擴展存儲顯得尤為重要。
我們對此持不同看法,首先要看產品應用場景占有率,其次要看實際的部署方案,最后要看成本比較:
1)根據前面分析,目前主力的專業行業應用仍是使用Dense模型,能部署MoE模型的通用AI巨頭早已下場完成部署,從目前的應用比例來看,使用Dense模型的依然占據應用主體。對于Dense模型(實際上是單專家的特例),超過對等算力的單卡大顯存或擴展存儲容易形成浪費。
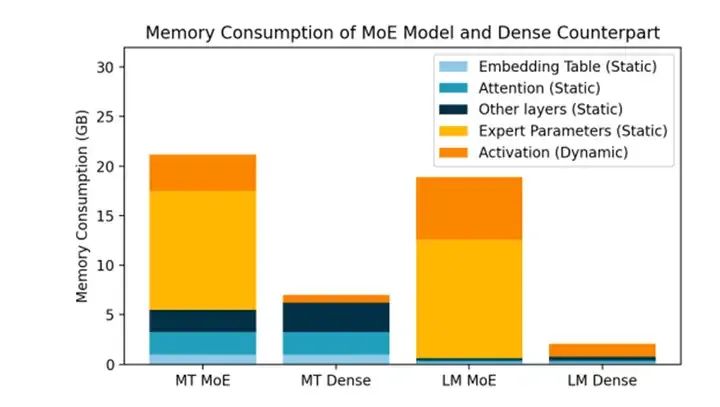
同樣模型性能下MoE模型需要更大的顯存(來源:Meta)
2)根據從廠商和V3論文獲得的實際部署方案,為保證MoE部分不同專家之間的負載均衡,會將共享專家和高負載的細粒度專家在集群的不同GPU做多個復制,讓GPU把更多的熱數據(發給共享專家的)跑起來,V3部署中每個GPU大概托管9個專家。如果考慮這9個專家中有一個是參數最多的共享專家,那么事實上每塊GPU上的空閑細粒度專家占據的參數總和可能不超過單塊GPU上總參數量的1/3。
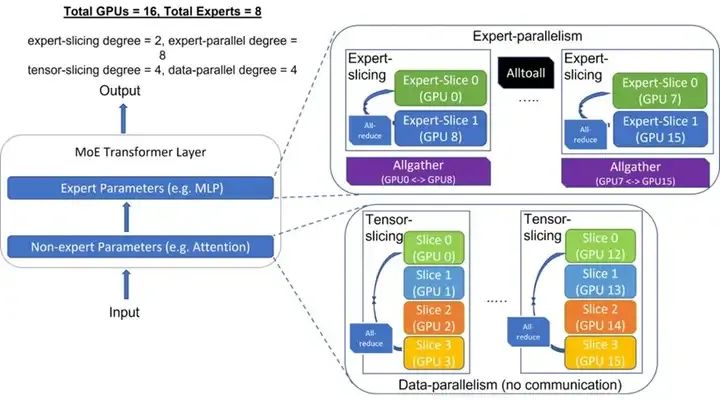
MoE的跨GPU部署模式(來源:微軟)
3)從成本上看,可能把一部分專家放到CPU上更劃算。我們認為MoE上的專家可以分為高頻專家、中頻專家,低頻專家。高頻專家和中頻專家搭配部署在GPU上比較合適,低頻專家調度很少,更適合放在服務器上已有的閑置CPU的內存上(CPU上的標準內存比GPU的HBM便宜很多,擴展性更好),以充分利用全服務器的算力降低綜合成本。
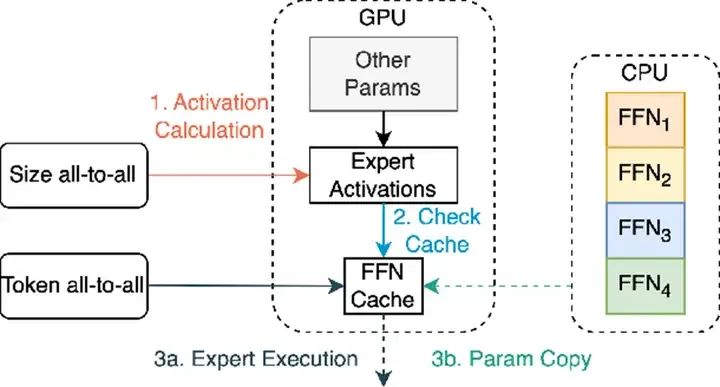
MoE模型的GPU+CPU混合部署(來源:Meta)
另外,R1自己都做Dense模型的蒸餾版本了,我們為何還要糾結于高于對等算力帶寬的超大顯存?
6 結語
6.1 DeepSeek的關鍵貢獻
DeepSeek由梁文鋒于2023 年5月創立,公司獨立運營,并由幻方支持研發資金。這種獨特的模式使DeepSeek能夠在沒有外部投資者壓力的情況下開展跨越式的人工智能研發,優先考慮長期研發和價值。
成立6個月后,DeepSeek于2023年11月發布的DeepSeek Coder,隨后是 DeepSeek LLM 67B,DeepSeek逐漸踏上了基礎大模型的競爭賽道。2024年5月推出的DeepSeek-V2就呈現出MLA和AI Infra技術的明顯領先優勢,極具性價比,引發了中國大模型市場的價格跳水和血拼。
在V2發布后,我們就已經關注到DeepSeek在算法-硬件協同優化方面的出色表現。主編作者在2024年6月,為前來咨詢的投資人推薦DeepSeek的高性價比路線。
V3和R1發布并開源后,DeepSeek進一步鞏固了其在MoE性價比和AI Infra的地位,并以開源模型中幾乎最出色的推理性能,贏得社會的廣泛關注。
對于R1/V3的主要創新,可以參考下表:
DeepSeek-R1/V3的主要創新(來源:中存算)
| R1/V3的優化 | R1/V3的創新與價值(實現了與 OpenAI-o1-1217 相當的性能) | 其他開源大模型(相當于Llama3.3的性能) |
|---|---|---|
| 軟硬件結合,提高模型計算效率降低成本 | 提出MLA,通過將鍵值 (KV) 緩存顯著壓縮為潛在向量來保證高效推理 | 采用GQA或MHA,占用KV緩存比MLA大一個數量級 |
| 減少冗余,提高模型計算效率降低成本 | 提出DeepSeekMoE,采用細粒度專家分割和共享專家隔離,減少冗余的專家參數 | 采用粗粒度專家,模型參數冗余大 |
| 改進算法,提高訓練效率 | 提出無輔助損失策略 ,改善MoE模型訓練 | 采用常規輔助損失策略,容易訓練失敗 |
| 簡化算法,提高訓練效率 | 采用GRPO進一步使模型與人類偏好對齊,提高訓練效率 | 采用PPO,訓練效率不高 |
| 軟硬件結合,提高訓練效率 | 基于開源代碼開發自有的FP8混合精度訓練框架,提升訓練效率 | 傳統開源訓練框架,以BF16或FP32為主,顯存占用超過FP8,訓練速度較慢 |
| 軟硬件結合,提高訓練效率 | DualPipe算法來實現高效的流水線并行 | 默認流水線并行算法,氣泡較多 |
| 軟硬件結合,提高訓練效率 | 跨節點All-to-All通信內核,使用PTX編程以充分利用InfiniBand(IB)和NVLink帶寬 | 默認通信內核, |
| 改進數據,提高模型性能 | 使用長思維鏈(CoT)數據進行模型訓練,提升模型能力 | 幾乎無長思維鏈訓練 |
我們經過分析,認為DeepSeek的算法架構能力已經達到國際一線水平(例如MLA和GRPO算法),而其AI Infra團隊的軟硬件協同設計水平(例如FP8訓練框架和基于PTX進行All-to-All通信內核優化)和自由探索,可能已暫時超越大部分國際大模型企業。基本上DeepSeek團隊對GPU的性能使用率已接近技術上限,實現了在現有GPU體系內的軟件Sacle-up。
如果有這樣超越其他大廠一個數量級的訓練效率提升,估計很多大模型煉丹師夢里都要樂開花了。
6.2 R1的出現是國運級的貢獻嗎?
有人提出DeepSeek所作的工作可能是一種國運級別的科技成果。
作為本文的主編作者,我個人只在小時候看過一點點梅花易數的介紹,對于推算國運的太乙神數一直沒有機會了解和獲得傳承,不好隨意講這是不是國運級的成果。
我對最近DeekSeek的影響力傳播看法如下:
1)對DeepSeek的成果,特別是V3/R1開源,應有產業的高度肯定。但過度褒揚對DeekSeek大概率是不利的甚至是極為有害的,會導致專心做事的人要疲于應付各種俗務,也大概率導致DeepSeek招致美國商務部的打壓。
2)梁文鋒本人一貫低調,在創立幻方后那么多年,幾乎沒有出來宣傳或炒作。媒體和社會如能參考DeepSeek創始人的個人行事風格,給更多類似DeepSeek的本土人才和企業予以支持,會更有利于國運。
3)脫離實際技術分析的對DeepSeek的評判多數是霧里看花,少一些人與亦云的評判,多一些實干,對所有心懷理想的人都是好事。
4)會有比R1更顛覆性的先進大模型出現。如同前幾年的熱炒OpenAI和Kimi,技術總會不斷進步,對于DeepSeek來說,還有更加重要的目標和星辰大海,R1僅僅是海邊新發現的璀璨貝殼。
5)是否是對OpenAI模型的蒸餾根本不重要。學習和參考是人類社會進步的階梯,開源更是對大模型技術進步的頭號貢獻。一兩家閉源巨頭大概率沒有足夠的資源儲備來推動人類AGI的顛覆式發展,只有更多的DeepSeek這樣的力量貢獻到開源社區,才能形成合力實現超級人工智能。
6.3 對于國產AI芯片的啟示
DeepSeek的進步和成果,也給國產AI芯片的發展提供了一些啟示。
一方面,一級市場需要升級投資邏輯,不用再崇洋媚外。事實證明純本土的研發團隊,甚至是純本土新人團隊,完全由能力做出有國際影響力的成果和產品。國內算法不再死跟著老美屁股后面,國內的AI芯片也大可不必死跟著英偉達做傳統GPU。新的架構AI芯片,新的GPU架構,跨領域的技術融合,正形成新的產業窗口。
另一方面,DeepSeek的技術成果,事實也凸顯出算力對模型進步的重要性。DeepSeek的算法進步速度之快,與其算力使用效率比其他團隊高約一個數量級有非常密切的關系。(當然DeepSeek可使用的算力總量也不低)在這樣的一個算法大發展契機,盡快發展新架構AI芯片,發展3D封裝集成,發展高速互連,發展開源編譯生態,搶占MoE模型發展期的技術紅利,對中國的芯片產業就顯得尤為重要。
-
DeepSeek
+關注
關注
1文章
777瀏覽量
1363
原文標題:陳巍:DeepSeek是否有國運級的創新?2萬字解讀與硬核分析DeepSeek V3/R1的架構
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
DeepSeek開源新版R1 媲美OpenAI o3
科大訊飛深度解析DeepSeek-V3/R1推理系統成本
RK3588開發板上部署DeepSeek-R1大模型的完整指南
OpenAI O3與DeepSeek R1:推理模型性能深度分析
IBM在watsonx.ai平臺推出DeepSeek R1蒸餾模型
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
超星未來驚蟄R1芯片適配DeepSeek-R1模型
DeepSeek V3/R1滿血版登陸華為云
Deepseek R1大模型離線部署教程

扣子平臺支持DeepSeek R1與V3模型
瀚博完成DeepSeek全版本訓推適配
Krea發布Deepseek R1驅動的Chat功能
云天勵飛上線DeepSeek R1系列模型






 工商網監
工商網監
評論