 特征工程實施步驟
特征工程實施步驟
來源:Coggle數據科學
入門特征工程
1. 為什么特征工程很重要?
對于不同的數據科學家,特征工程可能呈現不同的意義。對于一些數據科學家,特征工程是我們如何縮減用于監督模型的特征(例如,試圖預測響應或結果變量)。
對于其他人,它是從非結構化數據中提取數值表示以供無監督模型使用的方法(例如,試圖從之前非結構化的數據集中提取結構)。特征工程包括這兩種情況,以及更多內容。數據從業者通常依賴ML和深度學習算法,即使所使用的數據格式不良且非最佳。如果我們不構建適當的特征,依賴復雜而耗時的ML模型來解決問題,我們可能會得到糟糕的ML模型。如果我們花時間了解我們的數據,并為我們的ML模型構建特征,使其能夠學習,那么我們最終可以得到更小、更快的模型,其性能可以與甚至優于復雜的模型相媲美。
2. 特征工程的局限性
特征工程并不是解決所有問題的靈丹妙藥。例如,在數據量過小的情況下,特征工程無法解決機器學習模型面臨的數據不足問題。對于包含少于1000行數據的數據集,在特征工程方面的努力有限,很難從這些數據觀察中提取更多信息。
特征工程也不能在特征和響應之間創建本來不存在的聯系。如果最初的特征在隱含上對于響應變量沒有任何預測能力,那么再多的特征工程也無法創造這種聯系。可以在性能上取得一些小幅度的提升,但不能指望特征工程或機器學習模型能夠奇跡般地在特征和響應之間創造關系。
3. 特征工程的步驟特征工程是指將原始數據轉化為機器學習模型能夠理解的數據表示的過程,它是整個ML流水線的關鍵一環。以下是文本中提到的主要概念和步驟:機器學習流水線的五個步驟:
定義問題領域(Defining the problem domain):這一步驟涉及明確我們想要通過機器學習解決的問題,同時考慮模型預測速度或可解釋性等特點。這些考慮將在模型評估階段起到關鍵作用。
獲取準確代表問題的數據(Obtaining data):考慮并實施數據收集方法,確保數據收集公平、安全,并尊重數據提供者的隱私。此時還可以進行探索性數據分析(EDA),以更好地了解正在處理的數據。
特征工程(Feature engineering):這是文本中重點介紹的部分。特征工程涵蓋了將數據轉化為適合輸入機器學習模型的最佳表示的所有工作。
模型選擇和訓練(Model selection and training):在這個階段,選擇適合數據和問題的模型,并進行仔細的訓練。如果在第一步中強調模型的可解釋性,可能會選擇基于樹的模型而不是深度學習模型。
模型部署和評估(Model deployment and evaluation):在這個階段,數據準備就緒,模型已經訓練完畢,可以將模型投入生產。同時需要考慮模型版本控制和預測速度等因素。必須部署評估過程,以跟蹤模型隨時間的性能變化,并注意模型的衰退情況。
概念漂移和數據漂移:
- 概念漂移(Concept Drift):這是指隨著時間推移,特征或響應的統計特性發生變化。模型訓練時的數據代表了某個時間點的快照,隨著時間的推移,數據所代表的環境可能會發生變化,導致我們對特征和響應的認識也發生變化。這可能需要更新模型以適應新的概念。
- 數據漂移(Data Drift):這是指數據的基礎分布因某種原因發生了變化,但我們對特征的解釋保持不變。例如,在全球大流行病爆發后,人們的觀影習慣發生了變化,觀影時間的分布可能會發生顯著變化。這需要我們調整模型以適應新的數據分布。
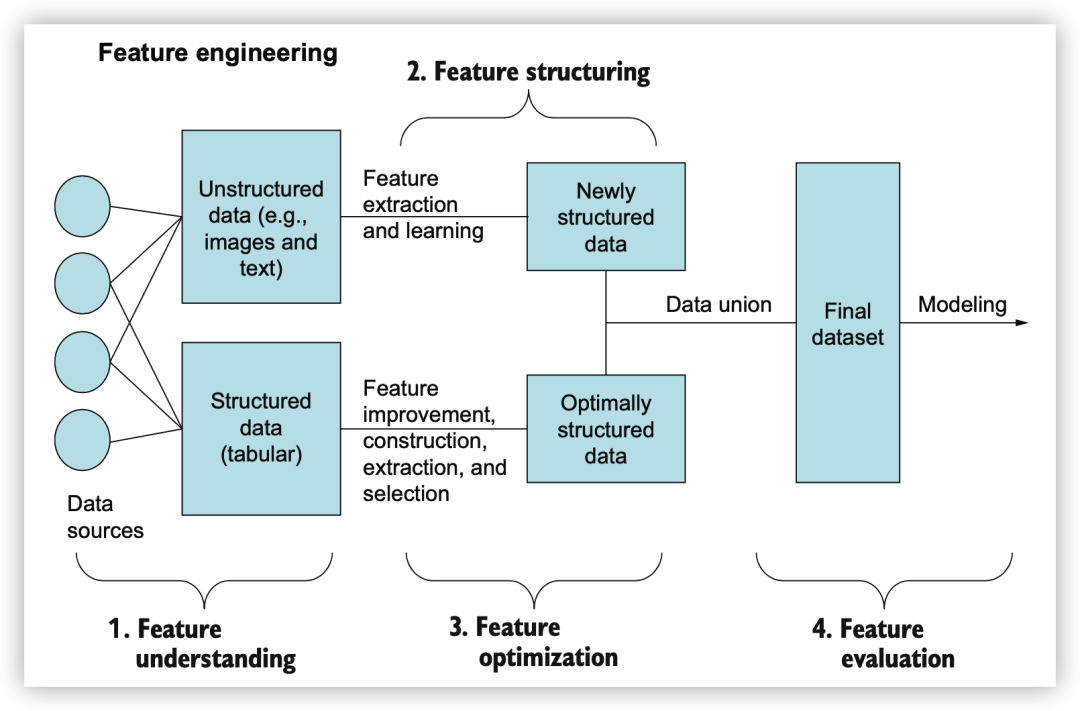
特征工程細分的步驟:
- 特征理解(Feature understanding):理解正在處理的數據的層級結構對選擇適當的特征工程方法至關重要。
- 特征結構化(Feature structuring):如果數據是非結構化的(如文本、圖像、視頻等),需要將其轉換為結構化格式,以便機器學習模型能夠理解。這可能需要應用特征提取或學習方法。
- 特征優化(Feature optimization):一旦數據被結構化,可以應用優化技術,如特征改進、提取、構建和選擇,以獲得最適合模型的數據表示。
- 特征評估(Feature evaluation):在嘗試不同特征工程方案時,可以選擇一個學習算法和一些參數選項進行快速調整,以評估應用不同特征工程技術的效果。
數據類型1. 結構化數據和非結構化數據結構化數據是按照嚴格的數據模型或設計組織起來的,通常以表格(行/列)格式表示,其中行代表個體觀察,列代表特征。

而非結構化數據則沒有預定義的設計,不遵循特定的數據模型,例如客戶服務對話的轉錄、YouTube 視頻、播客音頻等。2. 數據的四個級別
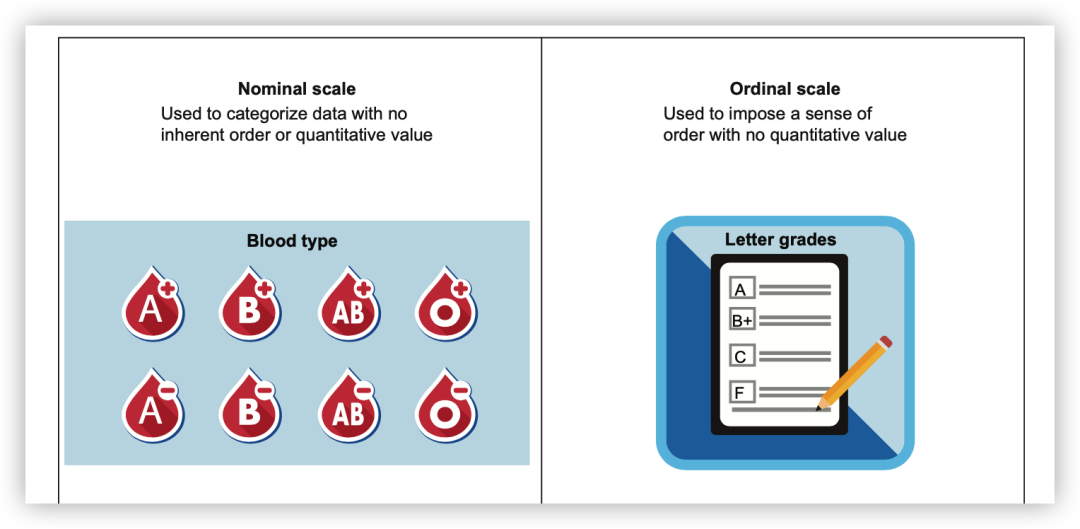
名義級別、序數級別、間隔級別和比例級別。名義級別是純粹的定性數據,沒有順序和數值含義。序數級別在定性數據中具有一定的順序,但值之間的差異沒有實際意義。間隔級別中,數據之間的差異有一致的意義,可以進行加法和減法操作。比例級別是最高級別,除了有一致的差異意義外,還存在真正的零點,允許進行乘法和除法操作。
特征工程的類型
特征工程是指在機器學習流程中對原始數據進行預處理和轉換,以便更好地適應模型的需求,提高模型的性能和效果。

- 特征改進(Feature Improvement):特征改進技術通過各種數學轉換來增強現有的結構化特征。通常是對數值特征應用轉換,如填充缺失數據、標準化和歸一化。這可以包括應用z-score轉換、使用統計中位數來填充缺失值等。特征改進在早期的案例研究中扮演著重要角色。它適用于不同層級的數據,根據數據的層級可以選擇不同的改進方式。
- 特征構建(Feature Construction):特征構建是通過直接轉換現有特征或將原始數據與新數據源的數據進行連接,從而手動創建新特征的過程。這可以包括從新數據源中提取信息,創建新的特征。例如,從住房數據集中提取戶主總收入以及家庭人數作為新特征。特征構建可以涉及將分類特征轉換為數值特征,或者將數值特征通過分桶轉換為分類特征。
- 特征選擇(Feature Selection):特征選擇涉及從現有特征集中選擇最佳特征,以減少模型需要學習的特征數量,同時減少特征之間的依賴關系。這可以防止模型中出現特征之間的混淆,從而提高模型的性能。特征選擇適用于處理維度災難、特征之間存在依賴性以及需要提高模型速度的情況。
- 特征提取(Feature Extraction):特征提取是自動生成新特征的過程,基于對數據的潛在形狀做出假設。這可以涉及應用線性代數技術來執行主成分分析(PCA)和奇異值分解(SVD)等。在自然語言處理(NLP)案例研究中,可以通過學習詞匯并將原始文本轉換為詞頻向量來執行特征提取。
特征學習(Feature Learning):特征學習類似于特征提取,但不同之處在于它是通過應用非參數(不對原始數據的形狀做出假設)的深度學習模型來自動生成一組特征,從而自動發現原始數據的潛在表示。特征學習適用于處理非結構化數據,如文本、圖像和視頻。但它也可能需要更多的數據,并且生成的特征可能難以解釋。
特征工程的評估方法
在特征工程中,需要采用多種評估方法來確保模型的質量。以下將介紹幾種評估特征工程成果的指標。
1. 機器學習指標
與基準相比,機器學習指標可能是最直接的評估方法。這包括在應用特征工程方法之前和之后查看模型性能。具體步驟如下:
在應用任何特征工程之前,獲取計劃使用的機器學習模型的基準性能。
對數據進行特征工程處理。
從機器學習模型中獲取新的性能指標值,并將其與第一步得到的值進行比較。如果性能有所提升,并且超過了數據科學家定義的某個閾值,則表明特征工程取得了成功。
2. 解釋性指標
數據科學家和其他模型相關者應該深刻關注管道的可解釋性,因為它可能會影響業務和工程決策。可解釋性可以定義為我們能夠多好地詢問我們的模型“為什么”做出了特定的決策,并將該決策與用于做出模型決策的個別特征或特征組聯系起來。
3. 公平性和偏見評估指標為了確保模型不會根據數據中固有的偏見產生預測,必須根據公平性標準來評估模型。這在涉及個人高度影響的領域特別重要,比如金融貸款授予系統、識別算法、欺詐檢測和學術表現預測。在同一份2020年的數據科學調查中,超過一半的受訪者表示已經實施或計劃實施解釋性更強(可解釋性)的解決方案,而只有38%的受訪者表示對公平性和偏見緩解的情況也是如此。
4. 機器學習復雜性和速度評估指標機器學習流程的復雜性、規模和速度通常是一個被忽視的方面,但有時可能決定部署的成敗。正如之前提到的,有時數據科學家會轉向大型學習算法,例如神經網絡或集成模型,而不是進行適當的特征工程,希望模型能夠自己解決問題。
建議1:結構化數據工程在結構化數據上進行特征工程是提高模型性能和泛化能力的關鍵步驟,在結構化數據上進行特征工程的步驟:
查看字段類型、確定字段的噪音和分布:
- 計算字段與標簽的相關性:
- 對字段進行編碼,找到新特征:
建議2:文本數據特征工程
將原始文本數據轉化為可供機器學習算法使用的特征,有多種方式:
1. 文本向量化:對于定量特征,可以考慮使用諸如TF-IDF(詞頻-逆文檔頻率)等技術將文本數據轉化為數值特征。TF-IDF可以將文本中的每個詞轉化為一個數值,表示該詞在文本中的重要性。
2. 清洗和分詞:對原始文本進行清洗,去除特殊字符、標點符號和無關信息。然后,將清洗后的文本進行分詞,將文本劃分為詞語或標記。可以使用各種文本處理庫(如NLTK、spaCy)來實現。
3. 特征提取:在深度學習方面,可以使用詞嵌入技術(如Word2Vec、GloVe)來將每個詞轉化為具有語義信息的向量表示。
4. 遷移學習:使用預訓練的大型模型(如BERT、T5、ChatGPT等)來進行遷移學習。這些模型在大規模文本數據上進行了預訓練,可以捕捉豐富的語義信息。
建議3:圖像數據特征工程
深度學習模型特別是卷積神經網絡(CNN),已經在圖像處理領域取得了顯著的成功。可以使用預訓練的深度學習模型(如VGG、ResNet、Inception等)作為特征提取器,通過去掉最后的分類層,將模型用作特征提取器。然后可以對這些提取的特征進行降維(如PCA或t-SNE)或直接用于機器學習模型。
建議4:時序數據特征工程
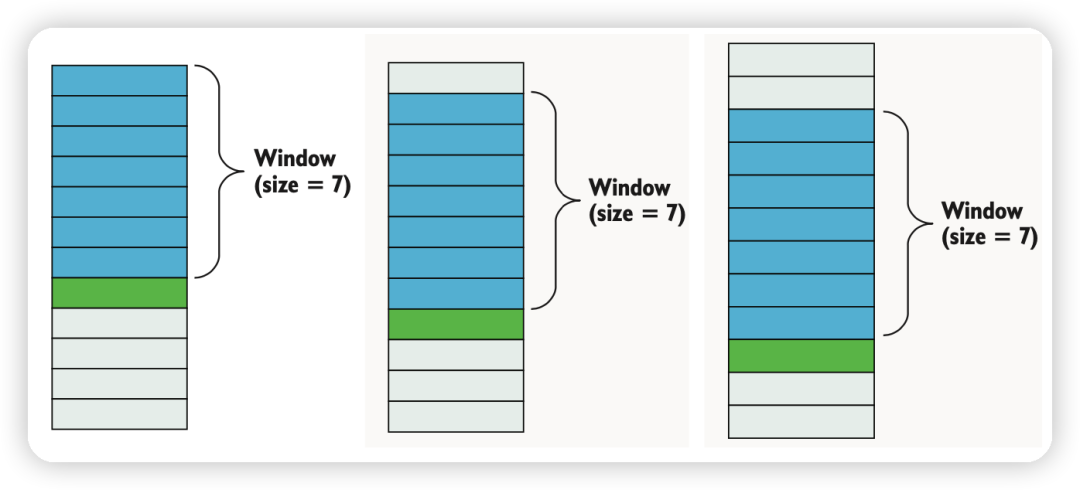
1. 理解時序數據:首先需要理解你的時序數據的特點。了解時間戳、觀測頻率、時間間隔等信息。
2. 構建自定義特征集和響應變量:根據問題的需求,你可能需要構建自定義的特征集和響應變量。這可能包括計算滾動統計量(如移動平均、滾動標準差)、創建時間窗口特征、構建滯后特征等。
3. 使用標準時序特征類型:在時序數據中,有一些常見的特征類型,如趨勢、季節性、周期性等。你可以嘗試提取這些特征,并將它們作為模型的輸入。
4. 添加領域特定的特征:在一些情況下,你可能有領域特定的知識,可以用于構建有用的特征。例如,在股票市場數據中,你可以添加技術指標(如移動平均線、相對強弱指標等)作為特征。
-
神經網絡
+關注
關注
42文章
4809瀏覽量
102827 -
ML
+關注
關注
0文章
150瀏覽量
34978 -
深度學習
+關注
關注
73文章
5555瀏覽量
122498
發布評論請先 登錄
企業與建筑防雷檢測及防雷接地工程實施指南

數字化車間中,如何有效實施數據中臺?
需求工程咨詢和實施服務

DCS控制系統的配置與實施流程
使用機器學習改善庫特征提取的質量和運行時間
半導體輔助設備如何實施品牌定位?

TMS系統的實施步驟與注意事項
智慧能源管理系統如何實施?

數據準備指南:10種基礎特征工程方法的實戰教程

ECRS工時分析軟件如何實施精益生產??
LIMS實驗室管理平臺的實施步驟
使用語義線索增強局部特征匹配

在生產中實施MES的步驟
機器學習中的數據預處理與特征工程
特征工程與數據預處理全解析:基礎技術和代碼示例





 工商網監
工商網監
評論